
NLP学习之:Bert 模型复现(1)任务分析 + 训练数据集构造
创始人
2024-01-12 22:01:26
文章目录
- 代码资源
- 原理
- 学习任务
- 代码讲解
- 代码重写
- 说明
代码资源
Bert-pytorch
原理
学习任务
-
Bert 本质上是 Transformer 的 Encoder 端,Bert 在预训练时最基本的任务就是:
- 判断输入的两个句子是否真的相邻
- 预测被 [MASK] 掉的单词
-
通过这两种任务的约束,可以让 Bert 真正学到:
- 上下句子之间的语义关系的关联关系,
- 一个句子中不同单词之间的上下文关系
-
所以通过 BERT 在大量文本中有针对的学习之后,BERT 可以真正做到对给定的句子进行语义层面的编码,所以他才能被广泛用于下游任务。
BERT 是 不需要大量人工标注数据的 ,这也是为什么他可以大规模训练预训练模型。- 对于第一种训练任务,我们只需要在给定的段落中随机挑选两句相邻的句子就可以组成正样本,而随机挑选两个不相邻的句子就可以组成负样本。
- 对于第二种训练任务,只需要对于给定的句子语料,对其中的单词按照一定比例的 mask 操作即可,因为 mask 的部分只是模型不知道其存在,但是我们还是知道 mask 的部分的真实标签的,所以还是可以做监督学习的任务,而且还是自监督。
代码讲解
from torch.utils.data import Dataset
import tqdm
import torch
import randomclass BERTDataset(Dataset):def __init__(self, corpus_path, vocab, seq_len, encoding="utf-8", corpus_lines=None, on_memory=True):# 构建词表self.vocab = vocab# 当前句子的长度self.seq_len = seq_lenself.on_memory = on_memory# 语料库长度self.corpus_lines = corpus_lines# 语料库路径 self.corpus_path = corpus_path# 编码方式self.encoding = encodingwith open(corpus_path, "r", encoding=encoding) as f:if self.corpus_lines is None and not on_memory:for _ in tqdm.tqdm(f, desc="Loading Dataset", total=corpus_lines):self.corpus_lines += 1if on_memory:self.lines = [line[:-1].split("\t")for line in tqdm.tqdm(f, desc="Loading Dataset", total=corpus_lines)]self.corpus_lines = len(self.lines)if not on_memory:self.file = open(corpus_path, "r", encoding=encoding)self.random_file = open(corpus_path, "r", encoding=encoding)for _ in range(random.randint(self.corpus_lines if self.corpus_lines < 1000 else 1000)):self.random_file.__next__()def __len__(self):return self.corpus_linesdef __getitem__(self, item):# item 是 index # random_sent 就是根据 index 获取两个句子:t1,t2,并给出这两个句子是否是相邻的(标签),这个过程中我们要保证用于训练的数据集中相邻和不相邻的句子 1:1 也就是正负样本要均衡t1, t2, is_next_label = self.random_sent(item)# 当选出 t1 和 t2 之后,在这两个句子中按照一定的比例进行 MASK,而且同时将他们转换成数值型变量 t1_random 和 t2_random; t1 label 和 t2 label 则是那些被 MASK 的值真正的标签。具体的逻辑下面的函数再讲t1_random, t1_label = self.random_word(t1)t2_random, t2_label = self.random_word(t2)# SOS 就是 start of the sentence 句子开始符号,这里是用 [CLS] 放在句子开头# EOS 就是 end of the sentences 句子结束符号在,这里用 [EOS] 放在句尾# [CLS] tag = SOS tag, [SEP] tag = EOS tag# 得到 t1 和 t2 的数字化向量表示之后,需要人为地给他们加上 [CLS], [SEP] 标签:[CLS] 句子1 [SEP] 句子2 [SEP]t1 = [self.vocab.sos_index] + t1_random + [self.vocab.eos_index]t2 = t2_random + [self.vocab.eos_index]# 同样的,t1_label 和 t2_label 也需要相应的填充,但这个的目的不是为了分隔,而是为了保持和 t1 t2 的序列一样的长度t1_label = [self.vocab.pad_index] + t1_label + [self.vocab.pad_index]t2_label = t2_label + [self.vocab.pad_index]# segment label 表示当前的句子属于第一个句子还是第二个句子,长度也和 t1+t2 长度一致;# 由于模型训练的时候可能会限制输入的最大长度,所以对以下三种输入数据进行长度限制segment_label = ([1 for _ in range(len(t1))] + [2 for _ in range(len(t2))])[:self.seq_len]bert_input = (t1 + t2)[:self.seq_len]bert_label = (t1_label + t2_label)[:self.seq_len]# 如果输入的句子并没有达到最大长度,那么就通过 pad 符号补全到最大长度;bert input, bert label 和 segment label 的长度是一致的padding = [self.vocab.pad_index for _ in range(self.seq_len - len(bert_input))]bert_input.extend(padding), bert_label.extend(padding), segment_label.extend(padding)output = {"bert_input": bert_input,"bert_label": bert_label,"segment_label": segment_label,"is_next": is_next_label} # isNext 表示当前的 t1, t2 是否是相邻的句子# 转成张量return {key: torch.tensor(value) for key, value in output.items()}def random_word(self, sentence):# 因为这里是英文任务,所以 sentence.split 是将一个句子切成单个的 token;汉语任务需要另外的处理方式tokens = sentence.split()output_label = []for i, token in enumerate(tokens):# 随机一个 0-1 之间的值,如果这个值 < 0.15 那么执行下面操作,这句话的本质就是我们选择 15% 的词进行 MASKprob = random.random()if prob < 0.15:prob /= 0.15# 在选出的 15% mask 的词中使用 80% 进行真正的 mask# 80% randomly change token to mask tokenif prob < 0.8:tokens[i] = self.vocab.mask_index# 10% 随机选择一个 word 进行替换(引入噪声,故意错误的答案)# 10% randomly change token to random tokenelif prob < 0.9:tokens[i] = random.randrange(len(self.vocab))# 最后 10%,就是什么也不做,相当于考试填空题直接给你把答案写在卷面上# 10% randomly change token to current tokenelse:tokens[i] = self.vocab.stoi.get(token, self.vocab.unk_index)# 这些是上面被 mask 的词对应的 label 标签output_label.append(self.vocab.stoi.get(token, self.vocab.unk_index))else:# 剩余的 85% 的内容不做遮掩tokens[i] = self.vocab.stoi.get(token, self.vocab.unk_index)# 这个 output_label 自然也毫无意义,因此全给 0 即可output_label.append(0)# 假设目前这句话是 '[CLS]我喜欢吃青菜,[SEP]你呢?[SEP]' """如果在那 15% 要被 mask 且在 80% 真正被 mask 的概率中,那么进行 mask 之后变成 -> '[CLS]我[MASK]欢吃青菜,[SEP]你呢?[SEP]' 假设 token 经过查找 vocab 之后的向量是 [0,2769,1,3614,1391,7471,5831,8024,2,872,1450,8043,2]; output_label 应该是 [0,0,1599, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] """"""如果在那 15% 要被 mask 但是在 10% 掺杂噪声的概率中,那么 mask 之后可能变成 -> '[CLS]我喜欢吃毛菜,[SEP]你呢?[SEP]' 假设 token 经过查找 vocab 之后的向量是 [0,2769,1599,3614,1391, 581,5831,8024,2,872,1450,8043,2]; output_label 应该是 [0,0,0, 0, 0, 7471, 0, 0, 0, 0, 0, 0, 0] """"""如果在那 15% 要被 mask 但是在最后 10% 的概率中,那么 mask 之后可能变成 -> '[CLS]我喜欢吃毛菜,[SEP]你呢?[SEP]' 假设 token 经过查找 vocab 之后的向量是 [0,2769,1599,3614,1391, 581,5831,8024,2,872,1450,8043,2]; (假设被选中的词是 “你”)output_label 应该是 [0,0, 0, 0, 0, 0, 0, 0, 0, 0, 1450, 0, 0] """return tokens, output_labeldef random_sent(self, index):t1, t2 = self.get_corpus_line(index)# output_text, label(isNotNext:0, isNext:1)# 0.5 的概率获得两个相邻的句子if random.random() > 0.5:return t1, t2, 1else:# 另外 0.5 的概率获得不相邻的句子return t1, self.get_random_line(), 0def get_corpus_line(self, item):# 根据 index (item)返回一对相邻的句子if self.on_memory:return self.lines[item][0], self.lines[item][1]else:line = self.file.__next__()if line is None:self.file.close()self.file = open(self.corpus_path, "r", encoding=self.encoding)line = self.file.__next__()t1, t2 = line[:-1].split("\t")return t1, t2def get_random_line(self):# 随机返回一个句子if self.on_memory:return self.lines[random.randrange(len(self.lines))][1]line = self.file.__next__()if line is None:self.file.close()self.file = open(self.corpus_path, "r", encoding=self.encoding)for _ in range(random.randint(self.corpus_lines if self.corpus_lines < 1000 else 1000)):self.random_file.__next__()line = self.random_file.__next__()return line[:-1].split("\t")[1]
代码重写
- 因为原作者的代码是通过自己构建了一个
vocab词表;而我想的是,使用一个预训练 Bert 模型的 tokenizer 直接用来准备数据集,可能更加方便快捷。 所以我把相关部分的代码更改了一下:
"""@Time : 2022/10/22@Author : Peinuan qin"""from torch.utils.data import Dataset, DataLoader
import torch
import random
import tqdm
import re
from transformers import BertTokenizer,BertModel, BertConfig
from utils import generate_randomclass BERTDataset(Dataset):def __init__(self, corpus_path, tokenizer=None, seq_len=10, encoding='utf-8', lang='cn', corpus_lines=None):""":param corpus_path::param vocab::param seq_len::param encoding::param lang::param corpus_lines::param tokenizer:"""assert tokenizer is not None, "please give a tokenizer"self.corpus_path = corpus_pathself.tokenizer = tokenizerself.seq_len = seq_lenself.vocab = self.tokenizer.vocabself.encoding = encodingself.lang = langself.corpus_lines = corpus_linesif tokenizer:self.id2word = {k: v for v, k in tokenizer.vocab.items()}self.get_sentences()def __len__(self):return self.corpus_linesdef __getitem__(self, index):t1, t2, isNext = self.get_two_sentence(index)t1, t1_mask_labels = self.mask_word(t1)t2, t2_mask_labels = self.mask_word(t2)# concate the t1 t2 with [CLS], [SEP], etc. special words,# convert all tokens to number values# padding the whole vector to fixed sequence lengthoutputs = self.process(t1, t2, t1_mask_labels, t2_mask_labels)outputs['is_next'] = torch.tensor(isNext)return outputsdef get_sentences(self):if self.lang == 'cn':with open("./corpus_chinese.txt", 'r', encoding='utf-8') as f:sentences = f.readlines()self.lines = [re.split('。|!|\!|\.|?|\?|,|,', sentence)for sentence in (sentences)]# delete the spaces, such as [a, b, c, ""] -> [a, b, c]for i in range(len(self.lines)):self.lines[i] = [sep for sep in self.lines[i] if sep.strip() != '']self.corpus_lines = len(self.lines)if self.lang == 'en':with open(self.corpus_path, "r", encoding=self.encoding) as f:self.lines = [line[:-1].split("\t") for line in f]self.corpus_lines = len(self.lines)print(f"data lines are: \n {self.lines}")print(f"The number of data lines is: \n {self.corpus_lines}")def get_two_sentence(self, index):t1, t2 = self.lines[index]if random.random() > 0.5:return t1, t2, 1else:t2 = self.get_random_sentence(index)return t1, t2, 0def get_random_sentence(self, index):random_index = random.randrange(self.corpus_lines)# cannot select the sentence in the t1's linewhile (random_index == index):random_index = random.randrange(self.corpus_lines)t2 = self.lines[random_index][1]return t2def mask_word(self, sentence: str):if self.lang == 'en':tokens = sentence.split()if self.lang == 'cn':tokens = list(sentence)mask_labels = []for i, token in enumerate(tokens):prob = generate_random()if prob < 0.15:new_prob = generate_random()if new_prob < 0.8:tokens[i] = self.tokenizer.mask_tokenelif new_prob < 0.9:tokens[i] = self.id2word[random.randrange(len(self.vocab))]else:passmask_labels.append(tokens[i])else:mask_labels.append(self.tokenizer.pad_token)return tokens, mask_labelsdef process(self, t1, t2, mask_labels_1, mask_labels_2):data = self.tokenizer.encode_plus(t1, t2, add_special_tokens=True)PAD = self.tokenizer.pad_tokenlabel = [PAD] + mask_labels_1 + [PAD] + mask_labels_2 + [PAD]data_ = {k: v for k, v in data.items()}label_ = self.tokenizer.encode(label)segment_labels = data_['token_type_ids']input_ids = data_['input_ids']mask_labels = label_assert (len(segment_labels)== len(input_ids)== len(mask_labels))if self.seq_len:# if the setence is longer than sequence length, truncate itpaddings = [self.tokenizer.pad_token for _ in range(self.seq_len)]input_ids = (input_ids + paddings)[:self.seq_len]segment_labels = (segment_labels + paddings)[:self.seq_len]mask_labels = (mask_labels + paddings)[:self.seq_len]# if it is shorter than the sequence length, pad itpaddings = [self.tokenizer.pad_token for _ in range(self.seq_len - len(input_ids))]input_ids.extend(paddings)segment_labels.extend(paddings)mask_labels.extend(paddings)output = {'input_ids': input_ids,'mask_labels': mask_labels,'segment_labels': segment_labels}return {k: torch.tensor(v) for k, v in output.items()}if __name__ == '__main__':corpus_path = "./corpus.txt"model_name = '../bert_pretrain_base/'config = BertConfig.from_pretrained(model_name)tokenizer = BertTokenizer.from_pretrained(model_name)model = BertModel.from_pretrained(model_name)dataset = BERTDataset(corpus_path=corpus_path, seq_len=None, tokenizer=tokenizer, lang='cn')print(dataset[0])说明
- 因为我使用了
huggingface平台提供的bert预训练模型和他附带的tokenizer,因此大家只需要去下载相关的文件使用就行
- 任意选择一个点进去
- 在 Files 中
- 把这几个文件下载下来,放到一个文件夹里,取个名字,比如我的文件夹名字就是 bert_pretrain
- 按照代码中的方式调用即可

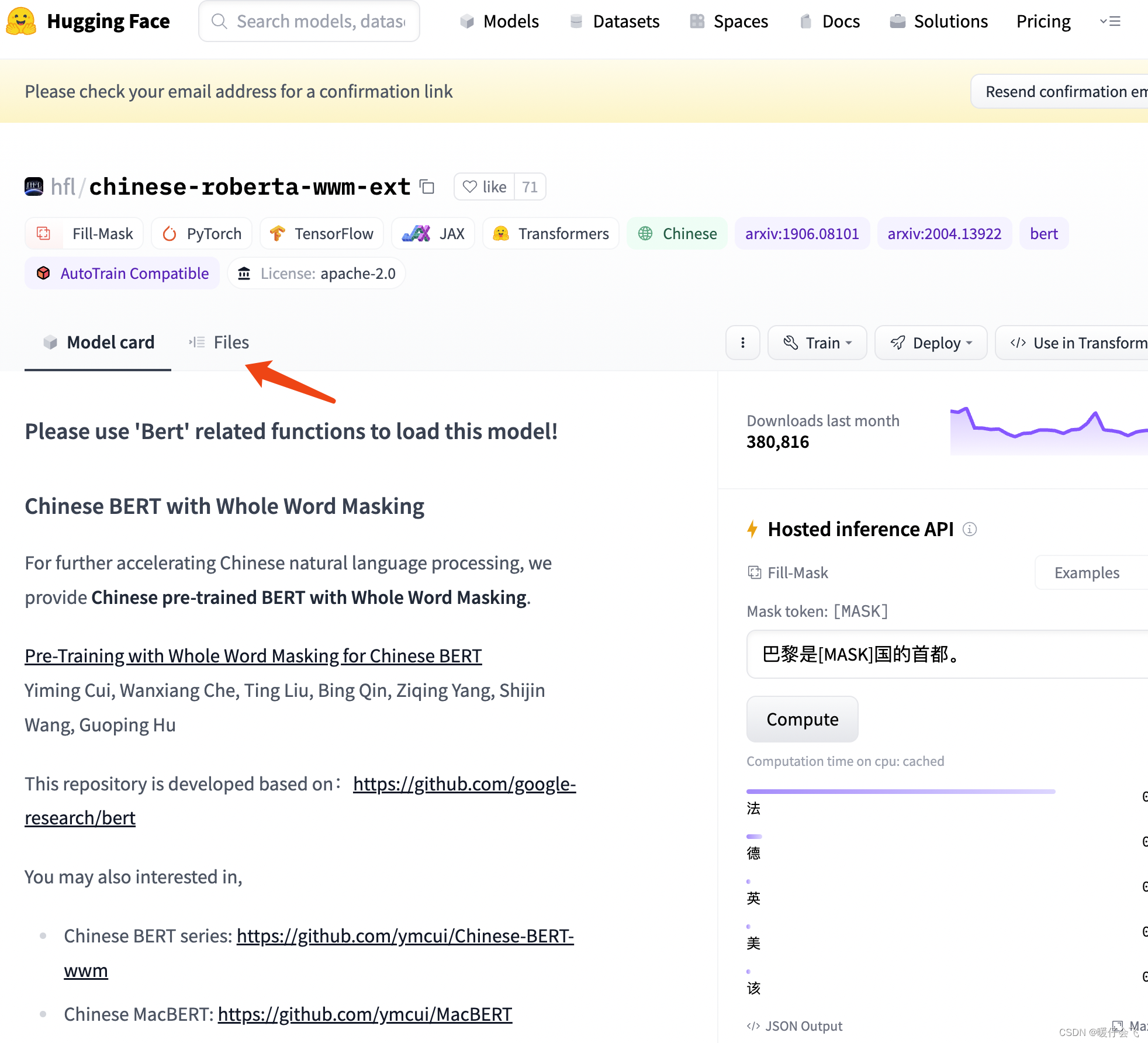
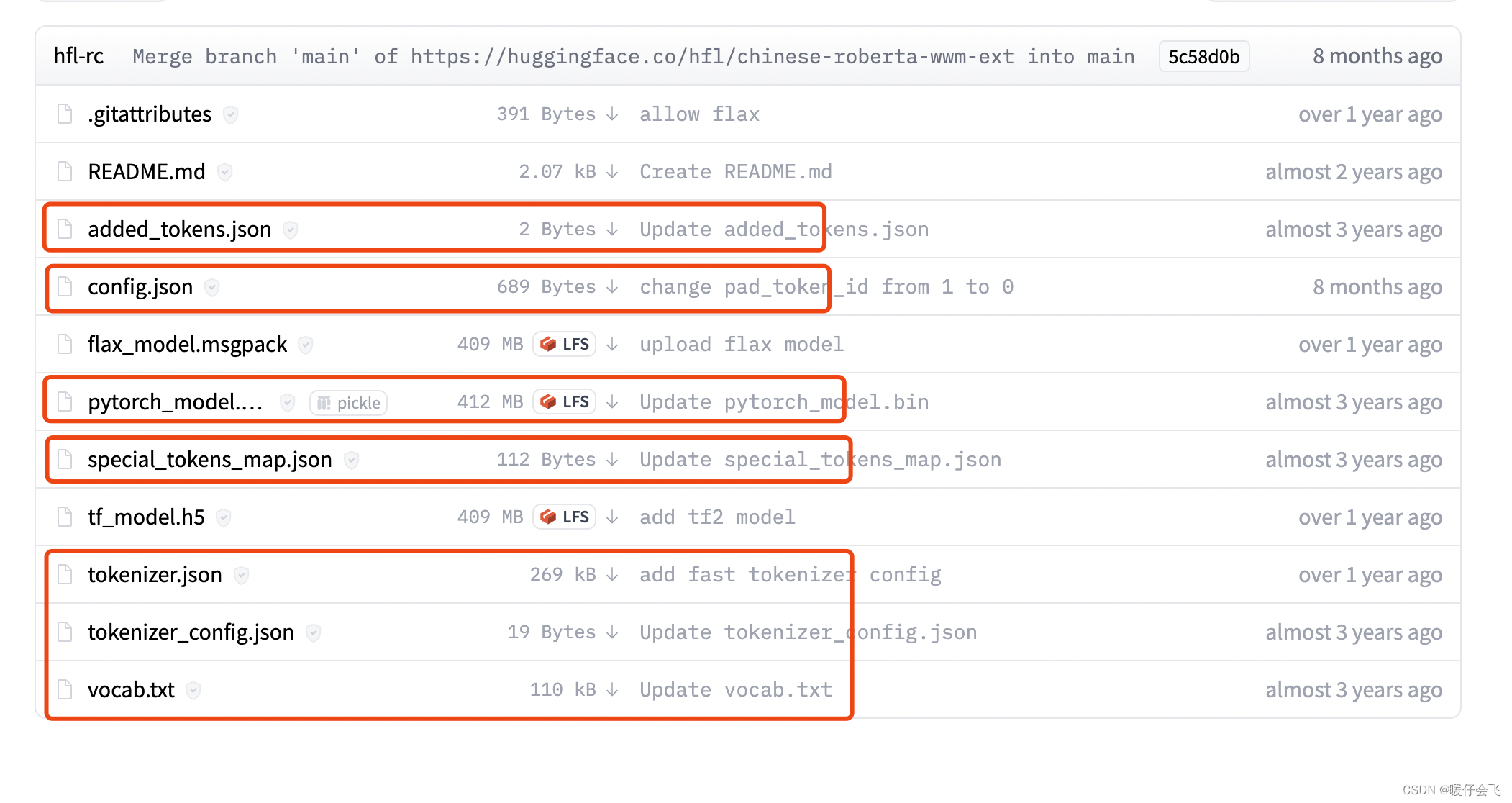
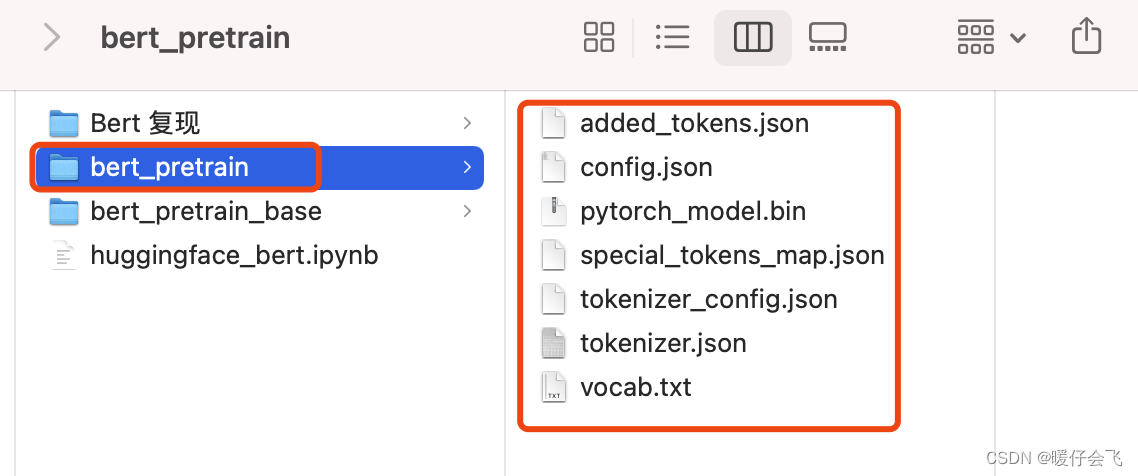
corpus_chinese.txt文件是我自己写的测试文件,截图放在这里帮助大家了解数据集的构造

相关内容
热门资讯
埃菲尔铁塔在哪 中国仿建埃菲尔...
2019年4月26日,广西南宁市,街头惊现一座巨型山寨版埃菲尔铁塔,高约20米,白色塔身,造型逼真,...
尤克里里小星星指法图 尤克里里...
午后阳光和煦,空气格外清新,大好日子宅在家里没事做,不如学点乐器吧。但大部分人没有什么音乐基础,小时...
苗族的传统节日 贵州苗族节日有...
【岜沙苗族芦笙节】岜沙,苗语叫“分送”,距从江县城7.5公里,是世界上最崇拜树木并以树为神的枪手部落...
北京的名胜古迹 北京最著名的景...
北京从元代开始,逐渐走上帝国首都的道路,先是成为大辽朝五大首都之一的南京城,随着金灭辽,金代从海陵王...
应用未安装解决办法 平板应用未...
---IT小技术,每天Get一个小技能!一、前言描述苹果IPad2居然不能安装怎么办?与此IPad不...
脚上的穴位图 脚面经络图对应的...
人体穴位作用图解大全更清晰直观的标注了各个人体穴位的作用,包括头部穴位图、胸部穴位图、背部穴位图、胳...
长白山自助游攻略 吉林长白山游...
昨天介绍了西坡的景点详细请看链接:一个人的旅行,据说能看到长白山天池全凭运气,您的运气如何?今日介绍...
猫咪吃了塑料袋怎么办 猫咪误食...
你知道吗?塑料袋放久了会长猫哦!要说猫咪对塑料袋的喜爱程度完完全全可以媲美纸箱家里只要一有塑料袋的响...
世界上最漂亮的人 世界上最漂亮...
此前在某网上,选出了全球265万颜值姣好的女性。从这些数量庞大的女性群体中,人们投票选出了心目中最美...
埃菲尔铁塔在哪 中国仿建埃菲尔...
2019年4月26日,广西南宁市,街头惊现一座巨型山寨版埃菲尔铁塔,高约20米,白色塔身,造型逼真,...
怎么样消灭臭虫 臭虫用什么药消...
奔奔虫控|被吸血臭虫骚扰的滋味,你体会过吗?相信被臭虫骚扰过的人都不想再体验一次了吧?那么臭虫应该怎...
苗族的传统节日 贵州苗族节日有...
【岜沙苗族芦笙节】岜沙,苗语叫“分送”,距从江县城7.5公里,是世界上最崇拜树木并以树为神的枪手部落...
北京的名胜古迹 北京最著名的景...
北京从元代开始,逐渐走上帝国首都的道路,先是成为大辽朝五大首都之一的南京城,随着金灭辽,金代从海陵王...
应用未安装解决办法 平板应用未...
---IT小技术,每天Get一个小技能!一、前言描述苹果IPad2居然不能安装怎么办?与此IPad不...