
Go学习之路:更多类型:struct、slice 和映射(DAY 2)
文章目录
- 前引
- 更多类型:struct、slice 和映射
- 1、指针
- 2.1、结构体/结构体命名(一)
- 2.2、结构体/对象访问、指针访问、初始化规则(二)
- 3、数组
- 4.1、切片/初始化切片
- 4.2、切片/切片引用数组
- 4.3、切片/切片的length和capacity
- 4.4、切片/Nil切片
- 4.5、切片/设置为二维切片/切片添加元素
- 5、Range
- 6.1、映射/map的初始化
- 6.2、映射/映射的基本操作
- 7.1、函数/函数值
- 7.2、函数/函数闭包
前引
周天辣 昨天全员核酸没有阳性 如果再有两天阴性的话 就有机会楼栋能解封啦 最好的情况希望能出现 周二能回去!
在寝室里闲着也是闲着 还是学一下go吧 把剩下的基础的给学完
希望好运伴随!
希望未来顺利
更多类型:struct、slice 和映射
1、指针
go语言中仍旧保持了有指针的特性 这个还是非常欣慰的
准确来说应该和c/c++差别并不大 唯一的差别是不能进行指针运算
下面是例子
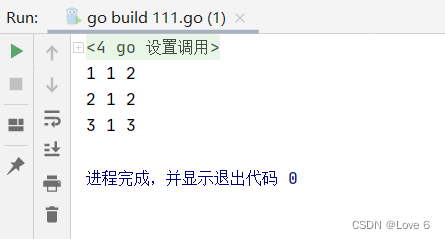
111.go
package mainimport "fmt"func main() {i, j := 1, 2p := &ifmt.Println(*p, i, j)p = &jfmt.Println(*p, i, j)*p = 3fmt.Println(*p, i, j)
}
运行效果
2.1、结构体/结构体命名(一)
命名方式相比于c语言有所不一样 其他的基本大致相同
type name struct
然后从这里我自己去搜了10分钟的资料
发现go语言的内存分配和c++ 完全不一样
第一点 c++需要自己手动解决内存分配问题 而go语言是自动回收
第二点 go语言会自动分析该对象是否是需要分配内存 决定于内存逃逸行为 go语言的内存分析我刚刚又花了20分钟看了一下 发现不像是c++那样 什么对象是动态分配的 什么是静态分配(在栈中)定义的时候 自己都清楚 而是取决于当前对象是否能被外部引用 go语言还是偏向于分配栈对象的 但是对于没有办法确认是否会被外部引用时 只能放于堆中 用GC来管理
关于内存分配问题 这个后面还要花很多事情去研究研究 下面写了很多 来看究竟结构体的内存分配情况 以及结构体的初始化
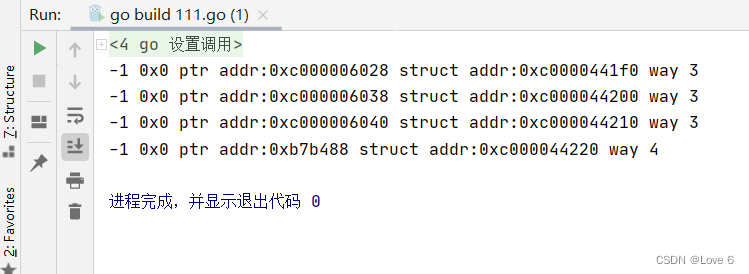
111.go
package mainimport "fmt"type Node struct {val intnext *Node
}var global_ptr *Nodefunc PtrGo() {global_ptr = &Node{}global_ptr.val = -1
}func main() {// 初始化1var dummynode1 Nodedummynode1.val = -1 //初始化为0后 再赋值ptr1 := &dummynode1fmt.Printf("%d %p %s%p %s%p %s\n", dummynode1.val, dummynode1.next, "ptr addr:", &ptr1, "struct addr:", ptr1 , "way 3")//初始化2dummynode2 := Node{-1, nil}ptr2 := &dummynode2fmt.Printf("%d %p %s%p %s%p %s\n", dummynode2.val, dummynode2.next, "ptr addr:", &ptr2, "struct addr:", ptr2, "way 3")//初始化3dummynode3 := new(Node)dummynode3.val = -1ptr3 := dummynode3fmt.Printf("%d %p %s%p %s%p %s\n", dummynode3.val, dummynode3.next, "ptr addr:", &ptr3, "struct addr:", ptr3, "way 3")//初始化4PtrGo()fmt.Printf("%d %p %s%p %s%p %s\n", global_ptr.val, global_ptr.next, "ptr addr:", &global_ptr, "struct addr:", global_ptr, "way 4")
}
运行效果
2.2、结构体/对象访问、指针访问、初始化规则(二)
结构体不管是指针还是直接对象访问结构体内部值 都是通过.符号来访问 不用指针->来访问了
第二个 初始化规则 上面的方式已经写完了初始化的方式
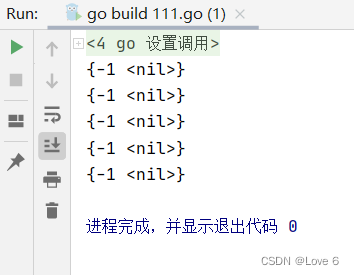
111.go
package mainimport "fmt"type Node struct {val intnext *Node
}func main() {var dummynode1 = Node{-1, nil}fmt.Println(dummynode1)var dummynode2 = Node{val : -1}fmt.Println(dummynode2)var dummynode3 = Node{next : nil}dummynode3.val = -1fmt.Println(dummynode3)dummynode4 := Node{-1, nil}fmt.Println(dummynode4)dummynode5 := new(Node)dummynode5.val = -1fmt.Println(*dummynode5)
}
运行效果
3、数组
构造方式和c语言类似 声明方式仍旧是golang化
简单的例子应用
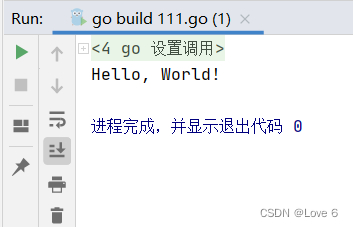
package mainimport "fmt"func main() {var strs [2]stringstrs[0] = "Hello,"strs[1] = "World!"fmt.Println(strs[0], strs[1])
}
运行效果
数组的初始化办法
下面有这几种
111.go
package mainimport ("fmt"
)func main() {var nums1 [10]int = [10]int {1, 2, 3}for i := 0; i < 10; i++ {fmt.Printf("%d ", nums1[i])}fmt.Println()var nums2 = [10]int{1, 2, 3}for _, num := range nums2 {fmt.Printf("%d ", num)}fmt.Println()nums3 := [...]int{1, 2, 3}for _, num := range nums3 {fmt.Printf("%d ", num)}fmt.Println()nums4 := [10]int{0:1, 1:2, 2:3}for _, num := range nums4 {fmt.Printf("%d ", num)}fmt.Println()var nums5 [10]intnums5[0] = 1nums5[1] = 2nums5[2] = 3for _, num := range nums5 {fmt.Printf("%d ", num)}fmt.Println()
}
运行效果
4.1、切片/初始化切片
切片在还没有学习Go语言的时候就听说了其鼎鼎大名
所以我们还是来接触一下
slice的底层实现 本质还是根据的数组的底层 可以说用指针来表示数组的开始位置
三个数据结构支持slice 指针 size capacity
我认为如果是从数组切分出来的切片 不扩容 此时开销是最小的
但是如果要append元素 此时可以将其看作是c++ vector 本质上扩容的机制还是另外申请容量
切片初始化的方法很多 为了后面使用起来更得心应手 还是挨个挨个列出来吧
111.go
package mainimport ("fmt"
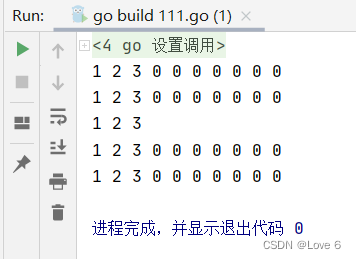
)func main() {//初始化1 刚开始为空切片nilslice1 := []int{}fmt.Println("before append, length:", len(slice1), ", capacity:", cap(slice1))for i := 0; i < 10; i++ {slice1 = append(slice1, i)}fmt.Println("after append 10 elems, length:", len(slice1), ", capacity:", cap(slice1))for _, num := range slice1 {fmt.Printf("%d ", num)}fmt.Println("\n")nums2 := [10]int {1, 2, 3, 4, 5}slice2 := nums2[:4] //初始化2 左闭右开 0 - 3 size 4 cap 10slice3 := nums2[1:] //初始化3 左闭右开 1 - 10 size 9 cap 9slice4 := nums2[0:4:5] //初始化4 左闭右开 0 - 3 size 4 cap 5(5 - 0)slice5 := nums2[:] //初始化5 左闭右开 0 - 10 size 10 cap 10fmt.Println("slice2 length:", len(slice2), ", capacity:", cap(slice2))fmt.Println("slice3 length:", len(slice3), ", capacity:", cap(slice3))fmt.Println("slice4 length:", len(slice4), ", capacity:", cap(slice4))fmt.Println("slice5 length:", len(slice5), ", capacity:", cap(slice5))slice6 := make([]int, 0, 10) //初始化6 size 0 cap 10var slice7 = make([]int, 0, 10) // 初始化7 size 0 cap 10var slice8[]int = make([]int, 0, 10) // 初始化8 size 0 cap 10fmt.Println("slice6 length:", len(slice6), ", capacity:", cap(slice6))fmt.Println("slice7 length:", len(slice7), ", capacity:", cap(slice7))fmt.Println("slice8 length:", len(slice8), ", capacity:", cap(slice8))
}
运行效果

4.2、切片/切片引用数组
切片本质上就是指向底层的数组 可以是一开始就生成切片对象 也可以是生成了数组后 再在切片上面切
如果刚开始切片是基于数组 那么修改切片 本质就是修改数组 数组和切片共享的是同一块内存
而如果当切片append扩容后 超过了之前的切片的capacity 此时就会像vector一样 另外找一块内存地址 并且将当前的内容复制过去 此时切片其实本质和之前的数组就已经没关系了 下面例子可以很清晰的表示
111.go
package mainimport ("fmt"
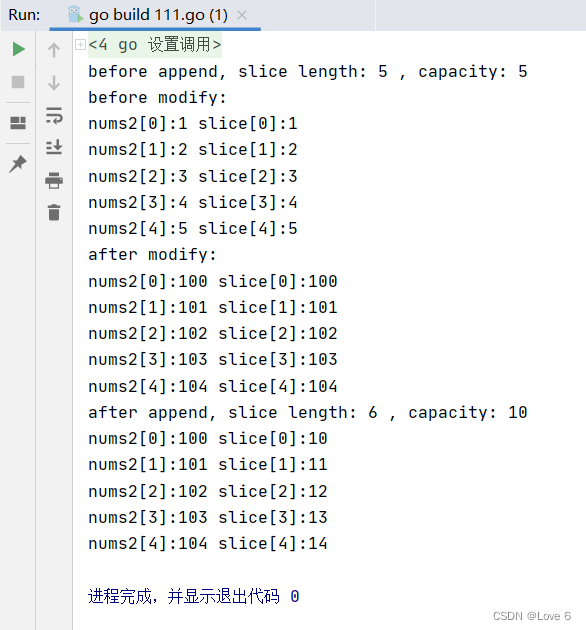
)func main() {nums := [...]int {1, 2, 3, 4, 5}slice := nums[:]fmt.Println("before append, slice length:", len(slice), ", capacity:", cap(slice))fmt.Println("before modify:")for index, num := range nums {fmt.Printf("nums2[%d]:%d slice[%d]:%d\n", index, num, index, slice[index])}for i := 0; i < len(nums); i++ {slice[i] = i + 100}fmt.Println("after modify:")for index, num := range nums {fmt.Printf("nums2[%d]:%d slice[%d]:%d\n", index, num, index, slice[index])}slice = append(slice, 0)fmt.Println("after append, slice length:", len(slice), ", capacity:", cap(slice))for i := 0; i < 5; i++ {slice[i] = i + 10}for index, num := range nums {fmt.Printf("nums2[%d]:%d slice[%d]:%d\n", index, num, index, slice[index])}
}运行效果
4.3、切片/切片的length和capacity
切片的length表示 当前切片中实际存在的长度
切片的cap表示 当前切片可扩容的长度
切片如果基于 cap 可以扩容 当length == cap时 扩容则是2倍扩容
扩容底层有机制 后面我再详细看看
但是如果切片基于其他切片 则cap最大只能是其他切片的cap 无法额外分配内存扩容
获取切片的length是由len()获取 capacity是由cap()获取
4.4、切片/Nil切片
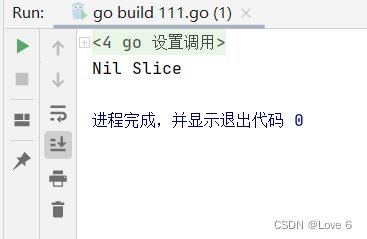
如果是空切片 例如用var slice1 []int生成切片
则为Nil切片 切片仅仅能和Nil切片作比较 不能与其他切片做比较
111.go
package mainimport "fmt"func main() {var slice1 []intif slice1 == nil {fmt.Println("Nil Slice")} else {fmt.Println("Non-Nil Slice")}
}
运行效果
4.5、切片/设置为二维切片/切片添加元素
切片使用范围更多 当作vector
append 添加元素
二维切片 [][]string{}
slice := [][]string{}slice = append(slice, []string{})fmt.Println(len(slice[0]), cap(slice[0]))
5、Range
对于切片或者有序序列
可以Range 用法如下 可用_代替range不用的值
package mainimport "fmt"func main() {slice := [][]string{}slice = append(slice, []string{})for index, str := range slice {fmt.Println(index, str)}for _, str := range slice {fmt.Println(str)}for index, _ := range slice {fmt.Println(index)}
}6.1、映射/map的初始化
就像是c++中的map 底层是用红黑树实现的
初始化map的方式 map[key_type]value_type
111.go
package mainimport "fmt"func main() {map_ := map[string]int{}var m = make(map[string]int)map_["gogo"] = 1map_["thanks"] = 2m["gogo"] = 1m["thanks"] = 2fmt.Println(map_["gogo"], map_["thanks"])fmt.Println(m["gogo"], m["thanks"])
}
6.2、映射/映射的基本操作
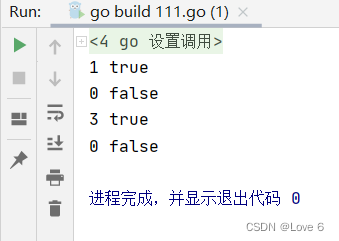
下面的操作包括 插入值 删除值 查找值
package mainimport "fmt"func main() {map_ := map[string]int{}map_["gogo"] = 1map_["thanks"] = 2elem, ok := map_["gogo"]fmt.Println(elem, ok)elem, ok = map_["go"]fmt.Println(elem, ok)map_["gogo"] = 3elem, ok = map_["gogo"]fmt.Println(elem, ok)delete(map_, "gogo")elem, ok = map_["gogo"]fmt.Println(elem, ok)
}
运行效果
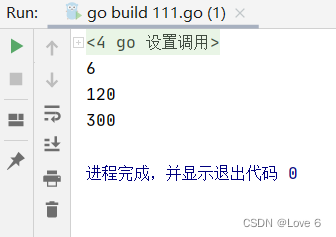
7.1、函数/函数值
函数可以生成为类似于c++的可执行函数对象 或者可以捆绑的执行函数对象
package mainimport "fmt"func mul(x int, z int) int {return x * z
}func mulfunc(func_ func(int, int) int, z int) int {return func_(3, 5) * z
}func main() {funcobj := func(x, y int) int {return x * y}fmt.Println(funcobj(2, 3))fmt.Println(mul(funcobj(2, 3), 20))fmt.Println(mulfunc(funcobj, 20))
}
运行效果
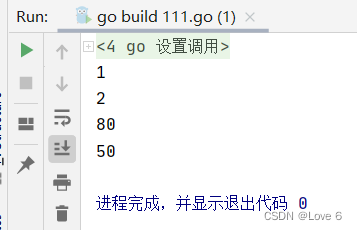
7.2、函数/函数闭包
刚刚仔细去看了一下 发现并没有那么好理解
用我的话来解释一下 闭包内部声明的参数 其参数的声明期是和函数闭包对象的生命期一样的
并且返回一个匿名函数 之后匿名函数也可以使用之前声明的函数对象
下面是简单的使用例子 后续复杂的使用还要再琢磨琢磨
111.go
package mainimport "fmt"func add() func() int {i := 0return func() int {i += 1return i}
}func deleter(x int) func(x int) int {i := 100return func(x int) int {i -= xreturn i}
}func main() {Adder := add()fmt.Println(Adder())fmt.Println(Adder())Deleter := deleter(10)fmt.Println(Deleter(20))fmt.Println(Deleter(30))
}运行效果
上一篇:离别的经典赠言
下一篇:形容微小的成语有哪些