
【AI】Python 实现粒子群算法
粒子群算法
1. 题目介绍
粒子群算法,其全称为粒子群优化算法 (Particle Swarm Optimization, PSO) 。它是通过模拟鸟群觅食行为而发展起来的一种基于群体协作的搜索算法。粒子群算法属于启发式算法也叫智能优化算法,其基本思想在于通过群体中个体之间的协作和信息共享来寻找最优解。
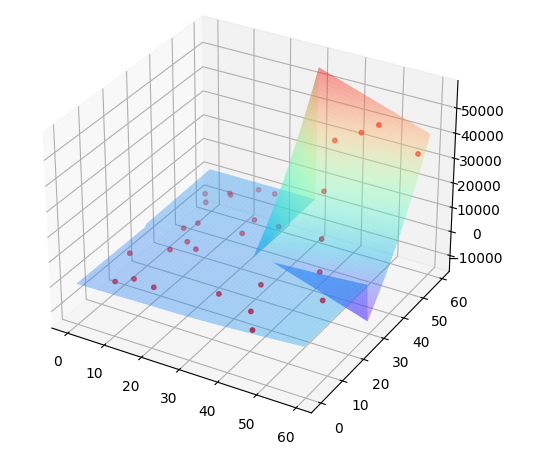
我们的目标是寻找一个函数的全局最小值或最大值,这个函数可以是二维或三维的,也可以是多维的。为了方便理解,下面通过一张图来直观地理解这个算法(也是本实验的结果):
可以看到,一开始图中有很多点,它们随机地分布在三维图像中,随着算法的进行,这些点会逐渐往全局最小值的方向靠拢,这个过程就像鸟类觅食一样,找到食物的鸟会带着其它鸟往食物靠拢。有的点移动得快,到达全局最小值后就不怎么动了;有些点移动得慢,会在局部来回震荡,始终也无法到达目标位置。但是不管怎样,只要有一个点到达了最优位置,就可以认为算法已经成功找到了最优解。
上图中这个三维函数的定义为:
f(x,y)={30x−y;x
在后续的迭代过程中,每个粒子会不断向更优的位置靠拢。对于第 iii 个粒子,这个过程可以很容易地表示成:xik+1=xik+offsetx_{i}^{k+1}=x_i^k+offsetxik+1=xik+offset。其中,k+1k+1k+1 表示当前轮次,kkk表示上一轮。
从上述表达式可以看出,要不断优化迭代方向,最重要的操作就是在每一轮中都找一个最合适的 offsetoffsetoffset 值。聪明的计算机科学家们在穷举了无数条件后,最终想到了offsetoffsetoffset 主要受三个值的影响:粒子上一轮移动所产生的惯性 vikv_i^{k}vik;粒子搜索过程中局部最优值与当前位置的差 pi−xikp_i-x_i^kpi−xik;所有粒子当前的全局最优值与当前位置的差 pg−xikp_g-x_i^kpg−xik。
想象一下,你是一只鸟儿,和别的鸟儿在一片很大的森林中找一个食物最多的位置,根据可靠消息,食物最多的位置,周围那一片的食物也非常多。你每到一个位置都会记录一下这个地方有多少食物,现在已经找过了 20 个地方,其中 15 号位置的食物是最多的,有 10 斤虫子!但是根据别的鸟儿提供的信息,位置 243 的食物是最多的,足足有 100 斤虫子!一方面,你很想往 243 号位置飞,另一方面,你又不能轻易放弃之前的努力,所以你也不能偏离 15 号位置太远,同时,你因为一直在飞,最好不要突然掉头,所以你还受到惯性方向的影响!所以,最终你做出了一个艰难的决策:你会将 15 号位置的方向、243 号位置的方向、你本身飞行的方向做一个矢量叠加,最终得出了你下一步要飞行的方向。
因此,offsetoffsetoffset 的值实际上就可以用 vvv 来表示,它可以理解为 “速度”,因为每个点位置更新是使用矢量的加和来表示的,“速度” 一词非常恰当地形容了这层意思。不失一般性,下面的公式给出了粒子群位置坐标的更新公式:
vik+1=w⋅vik+c1⋅rand()⋅(pi−xik)+c2⋅rand()⋅(pg−xik)xik+1=xik+vik+1v_{i}^{k+1}=w·v_{i}^{k}+c_1·rand()·(p_{i}-x_{i}^k)+c_2·rand()·(p_{g}-x_i^k) \\ x_i^{k+1}=x_i^k+v_i^{k+1} vik+1=w⋅vik+c1⋅rand()⋅(pi−xik)+c2⋅rand()⋅(pg−xik)xik+1=xik+vik+1
2. 代码实现
2.1 粒子的表示
每一个粒子需要记录当前点的坐标和前进速度,以及历史走过的最优位置。表示为:
class Particle:def __init__(self):# 当前点的坐标self.x = np.random.uniform(x_min, x_max)self.y = np.random.uniform(y_min, y_max)# 记录局部最优点和最优值self.x_local_best = self.xself.y_local_best = self.yself.f_local_best = function(self.x, self.y)# 当前点的前进速度self.vx = np.random.uniform(v_min, v_max)self.vy = np.random.uniform(v_min, v_max)
2.2 粒子群的表示
粒子群需要记录每一个点的信息,以及所有点经过的全局最优位置。同时它还要提供粒子群更新的方法,我们将它划分为两个部分的更新:速度 vvv 的更新和坐标 (x,y)(x, y)(x,y) 的更新,然后再用一个总的更新函数将这两个部分连接起来。代码如下:
class PSO:def __init__(self, iter_num, size):# size个点self.particles = [Particle() for _ in range(size)]# 记录全局最优点和最优值self.x_global_best = 20self.y_global_best = 20self.f_global_best = function(self.x_global_best, self.y_global_best)# 迭代轮数self.iter_num = iter_num# 用来作图self.f_global_best_records = []def update_v(self, particle):vx_new = w * particle.vx + \c1 * np.random.rand() * (particle.x_local_best - particle.x) + \c2 * np.random.rand() * (self.x_global_best - particle.x)vy_new = w * particle.vy + \c1 * np.random.rand() * (particle.y_local_best - particle.y) + \c2 * np.random.rand() * (self.y_global_best - particle.y)particle.vx = max(min(vx_new, v_max), v_min)particle.vy = max(min(vy_new, v_max), v_min)def update_xy(self, particle):x_new, y_new = particle.x + particle.vx, particle.y + particle.vyx_new, y_new = max(min(x_new, x_max), x_min), max(min(y_new, y_max), y_min)f_new = function(x_new, y_new)particle.x, particle.y = x_new, y_newif f_new < particle.f_local_best:particle.x_local_best = particle.xparticle.y_local_best = particle.yparticle.f_local_best = f_newif f_new < self.f_global_best:self.x_global_best = particle.xself.y_global_best = particle.yself.f_global_best = f_newdef update(self):for _ in range(self.iter_num):x, y, f = [], [], []for particle in self.particles:self.update_v(particle)self.update_xy(particle)x.append(particle.x)y.append(particle.y)f.append(function(particle.x, particle.y))yield x, y, fself.f_global_best_records.append(self.f_global_best)
2.3 函数定义
函数的定义如下,它接受一个坐标 (x,y)(x, y)(x,y) 并返回函数值 zzz:
def function(x, y):m = 30if x < m and y < m:return 30 * x - yelif x < m <= y:return 30 * y - xelif x >= m > y:return x ** 2 - y / 2elif x >= m and y >= m:return 20 * (y ** 2) - 500 * x
2.4 参数设置
总的来说,参数的设置如下:
iter_num, size = 100, 30
x_min, y_min, x_max, y_max = 0, 0, 60, 60
v_min, v_max = -1, 1
w, c1, c2 = 0.4, 0.2, 3
其中需要注意的是,速度范围 (vmin,vmax)(v_{min}, v_{max})(vmin,vmax) 必须互为相反数,而且不能过大;如果不互为相反数,例如为 (−1,2)(-1, 2)(−1,2),那么速度更容易为正数,粒子前进方向更容易往 >0> 0>0 的趋势走;反之若为 (−2,1)(-2, 1)(−2,1),粒子前进方向更容易往 <0< 0<0 的趋势走。如果速度上下限过大,粒子容易发生跳跃,突然前进一大步到达定义域边界,反复震荡,最终导致粒子不往最优方向收敛。
参数 c1c_1c1 控制粒子往局部最优值靠拢的趋势,c2c_2c2 控制粒子往全局最优值靠拢的趋势。我们希望粒子往全局最优值靠一些,所以最好把 c2c_2c2 设置得比 c1c_1c1 大一些。
其它参数可以自行更改。
2.5 作图演示
为了直观地演示粒子的收敛过程,在每一轮迭代过程中都在三维函数中绘制一遍散点图,下面的代码展示了这个逻辑,这种流程对于其它需求也是很有借鉴意义的:
pso = PSO(iter_num, size)
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
for x, y, f in pso.update():ax.clear()ax.plot_surface(X, Y, Z, cmap='rainbow', alpha=0.4, rstride=1, cstride=1)ax.scatter(x, y, f, s=10, c='r', label='顺序点')plt.ion()plt.pause(0.1)plt.ioff()
print('result coordinate: ', pso.x_global_best, ' ', pso.y_global_best, ' ', pso.f_global_best)
plt.show()
plt.plot(range(len(pso.f_global_best_records)), pso.f_global_best_records, alpha=1)
plt.show()
2.6 完整代码
import numpy as np
import matplotlib.pyplot as plt
import timedef function(x, y):m = 30if x < m and y < m:return 30 * x - yelif x < m <= y:return 30 * y - xelif x >= m > y:return x ** 2 - y / 2elif x >= m and y >= m:return 20 * (y ** 2) - 500 * xx_min, y_min, x_max, y_max = 0, 0, 60, 60
# 速度上下限必须互为相反数,保证方向的随机性
v_min, v_max = -1, 1
# c2越大越容易收敛
w, c1, c2 = 0.4, 0.2, 3
t = np.arange(x_min, x_max, 0.5)
X, Y = np.meshgrid(t, t)
Z = np.zeros(shape=X.shape)
for i in range(len(t)):for j in range(len(t)):Z[i][j] = function(X[i][j], Y[i][j])class Particle:def __init__(self):# 当前点的坐标self.x = np.random.uniform(x_min, x_max)self.y = np.random.uniform(y_min, y_max)# 记录局部最优点和最优值self.x_local_best = self.xself.y_local_best = self.yself.f_local_best = function(self.x, self.y)# 当前点的前进速度self.vx = np.random.uniform(v_min, v_max)self.vy = np.random.uniform(v_min, v_max)class PSO:def __init__(self, iter_num, size):# size个点self.particles = [Particle() for _ in range(size)]# 记录全局最优点和最优值self.x_global_best = 20self.y_global_best = 20self.f_global_best = function(self.x_global_best, self.y_global_best)# 迭代轮数self.iter_num = iter_num# 用来作图self.f_global_best_records = []def update_v(self, particle):vx_new = w * particle.vx + \c1 * np.random.rand() * (particle.x_local_best - particle.x) + \c2 * np.random.rand() * (self.x_global_best - particle.x)vy_new = w * particle.vy + \c1 * np.random.rand() * (particle.y_local_best - particle.y) + \c2 * np.random.rand() * (self.y_global_best - particle.y)particle.vx = max(min(vx_new, v_max), v_min)particle.vy = max(min(vy_new, v_max), v_min)def update_xy(self, particle):x_new, y_new = particle.x + particle.vx, particle.y + particle.vyx_new, y_new = max(min(x_new, x_max), x_min), max(min(y_new, y_max), y_min)f_new = function(x_new, y_new)particle.x, particle.y = x_new, y_newif f_new < particle.f_local_best:particle.x_local_best = particle.xparticle.y_local_best = particle.yparticle.f_local_best = f_newif f_new < self.f_global_best:self.x_global_best = particle.xself.y_global_best = particle.yself.f_global_best = f_newdef update(self):for _ in range(self.iter_num):x, y, f = [], [], []for particle in self.particles:self.update_v(particle)self.update_xy(particle)x.append(particle.x)y.append(particle.y)f.append(function(particle.x, particle.y))yield x, y, fself.f_global_best_records.append(self.f_global_best)def main():iter_num, size = 100, 30pso = PSO(iter_num, size)fig = plt.figure(figsize=(8, 6))ax = fig.add_subplot(111, projection='3d')for x, y, f in pso.update():ax.clear()ax.plot_surface(X, Y, Z, cmap='rainbow', alpha=0.4, rstride=1, cstride=1)ax.scatter(x, y, f, s=10, c='r', label='顺序点')plt.ion()plt.pause(0.1)plt.ioff()print('result coordinate: ', pso.x_global_best, ' ', pso.y_global_best, ' ', pso.f_global_best)plt.show()plt.plot(range(len(pso.f_global_best_records)), pso.f_global_best_records, alpha=1)plt.show()if __name__ == '__main__':main()3. 结果演示
运行上面给出的完整代码,程序结果为:
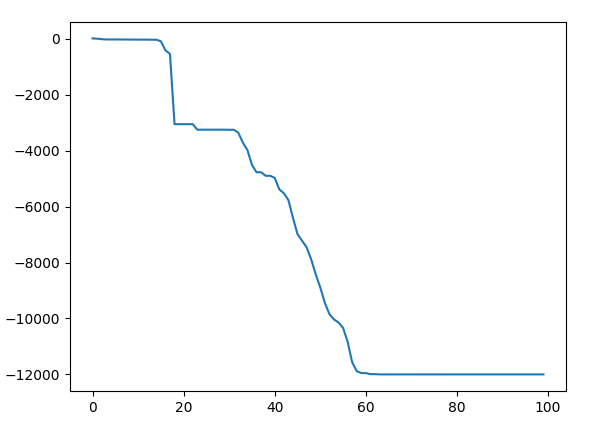

可以看出,在迭代 606060 轮时 fff 就开始收敛了,这说明有粒子已经找到了近似的全局最优值,之后的所有操作都是为了进一步逼近这个最优值。
上一篇:决策树-相关作业