
鸢尾花数据种类预测、分析与处理、scikit-learn数据集使用、seaborn作图及数据集的划分
创始人
2024-03-21 06:13:22
一、鸢尾花种类预测
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理,Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集
鸢尾花数据集包含了
- 4个属性(特征值)
- Sepal.Length(花萼长度),单位是cm
- Sepal.Width(花萼宽度),单位是cm
- Petal.Length(花瓣长度),单位是cm
- Petal.Width(花瓣宽度),单位是cm
- 3个种类(目标值):
- Iris Setosa(山鸢尾)
- Iris Versicolour(杂色鸢尾)
- Iris Virginica(维吉尼亚鸢尾)
该虹膜数据集包含150行数据,包括来自每个的三个相关鸢尾种类50个样品:又称为山鸢尾,虹膜锦葵和变色鸢尾

从左到右,Iris setosa (由 Radomil, CC BY-SA3.0),Iris versicolor (由Dlanglois, CC BY-SA 3.0)和lris virginica(由Frank Mayfield, CC BY-SA 2.0) )
二、scikit-learn中数据集介绍
scikit-learn数据集API介绍
- sklearn.datasets:加载获取流行数据集
- datasets.load_*():获取小规模数据集,数据包含在datasets里,安装sciki-learn时已下载,直接调用
- datasets.fetch_*(data_home=None):获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
- sklearn小数据集
- sklearn.datasets.load_iris():加载并返回鸢尾花数据集
- sklearn大数据集(以下为新闻数据集)
- sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
- subset:'train'或者'test','all',可选,选择要加载的数据集,训练集的“训练”,测试集的“测试”,两者的“全部”
- sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
- sklearn数据集返回值:load和fetch返回的数据类型datasets.base.Bunch(字典格式)
- data:特征数据数组,是 [n_samples * n_features] 的二维 numpy.ndarray 数组
- target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
- DESCR:数据描述
- feature_names:特征名,新闻数据,手写数字、回归数据集没有
- target_names:标签名
代码如下
from sklearn.datasets import load_iris, fetch_20newsgroups
# 数据集获取
iris = load_iris() # 小数据集获取# news = fetch_20newsgroups() # 大数据集获取
# print(news)# print("鸢尾花数据集的返回值:\n", iris)
# 返回值是一个继承自字典的Bench
print("鸢尾花的特征值:\n", iris["data"])
print("鸢尾花的目标值:\n", iris.target)
print("鸢尾花特征的名字:\n", iris.feature_names)
print("鸢尾花目标值的名字:\n", iris.target_names)
print("鸢尾花数据集的描述:\n", iris.DESCR)
------------------------------------------------------------
输出:
鸢尾花的特征值:[[5.1 3.5 1.4 0.2][4.9 3. 1.4 0.2][4.7 3.2 1.3 0.2]…… # 省略,共150行[6.5 3. 5.2 2. ][6.2 3.4 5.4 2.3][5.9 3. 5.1 1.8]]
鸢尾花的目标值:[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 11 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 22 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 22 2]
鸢尾花特征的名字:['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
鸢尾花目标值的名字:['setosa' 'versicolor' 'virginica']
鸢尾花的描述:.. _iris_dataset:Iris plants dataset
--------------------**Data Set Characteristics:**:Number of Instances: 150 (50 in each of three classes):Number of Attributes: 4 numeric, predictive attributes and the class:Attribute Information:- sepal length in cm- sepal width in cm- petal length in cm- petal width in cm- class:- Iris-Setosa- Iris-Versicolour- Iris-Virginica:Summary Statistics:============== ==== ==== ======= ===== ====================Min Max Mean SD Class Correlation============== ==== ==== ======= ===== ====================sepal length: 4.3 7.9 5.84 0.83 0.7826sepal width: 2.0 4.4 3.05 0.43 -0.4194petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)============== ==== ==== ======= ===== ====================:Missing Attribute Values: None:Class Distribution: 33.3% for each of 3 classes.:Creator: R.A. Fisher:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov):Date: July, 1988The famous Iris database, first used by Sir R.A. Fisher. The dataset is taken
from Fisher's paper. Note that it's the same as in R, but not as in the UCI
Machine Learning Repository, which has two wrong data points.This is perhaps the best known database to be found in the
pattern recognition literature. Fisher's paper is a classic in the field and
is referenced frequently to this day. (See Duda & Hart, for example.) The
data set contains 3 classes of 50 instances each, where each class refers to a
type of iris plant. One class is linearly separable from the other 2; the
latter are NOT linearly separable from each other... topic:: References- Fisher, R.A. "The use of multiple measurements in taxonomic problems"Annual Eugenics, 7, Part II, 179-188 (1936); also in "Contributions toMathematical Statistics" (John Wiley, NY, 1950).- Duda, R.O., & Hart, P.E. (1973) Pattern Classification and Scene Analysis.(Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218.- Dasarathy, B.V. (1980) "Nosing Around the Neighborhood: A New SystemStructure and Classification Rule for Recognition in Partially ExposedEnvironments". IEEE Transactions on Pattern Analysis and MachineIntelligence, Vol. PAMI-2, No. 1, 67-71.- Gates, G.W. (1972) "The Reduced Nearest Neighbor Rule". IEEE Transactionson Information Theory, May 1972, 431-433.- See also: 1988 MLC Proceedings, 54-64. Cheeseman et al"s AUTOCLASS IIconceptual clustering system finds 3 classes in the data.- Many, many more ...Process finished with exit code 0三、查看数据分布
通过图像,以查看不同类别是如何通过特征来区分的。 在理想情况下,标签类将由一个或多个特征对完美分隔。 在现实世界中,这种理想情况很少会发生
- seaborn介绍:Seaborn 是基于 Matplotlib 核心库进行了更高级的 API 封装,可以轻松地画出更漂亮的图形。而 Seaborn 的漂亮主要体现在配色更加舒服、以及图形元素的样式更加细腻
- 安装:pip install seaborn
-
seaborn.lmplot() 是一个非常有用的方法,它会在绘制二维散点图时,自动完成回归拟合
- sns.lmplot(x, y):x, y 分别代表横纵坐标的列名
- data=: 是关联到数据集,
- hue=*:代表按照 species即花的类别分类显示
- fit_reg=:是否进行线性拟合
使用代码如下
from sklearn.datasets import load_iris, fetch_20newsgroups
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"] # 设置显示中文字体
mpl.rcParams["axes.unicode_minus"] = False # 设置正常显示符号
# 数据集获取
iris = load_iris() # 小数据集获取
# 数据可视化,将数据转换成dataframe的格式存储
iris_data = pd.DataFrame(data=iris.data, columns=['Sepal_Length', 'Sepal_Width', 'Petal_Length', 'Petal_Width'])
iris_data['target'] = iris.target # 新增target目标值一列
print(iris_data)def plot_iris(iris, col1, col2):sns.lmplot(x=col1, y=col2, data=iris, hue="target", fit_reg=False) # fit_reg为是否进行线性拟合plt.xlabel(col1)plt.ylabel(col2)plt.title('鸢尾花种类分布图')plt.show()plot_iris(iris_data, 'Sepal_Width', 'Petal_Length')
------------------------------------------------------------------------------
输出:Sepal_Length Sepal_Width Petal_Length Petal_Width target
0 5.1 3.5 1.4 0.2 0
1 4.9 3.0 1.4 0.2 0
2 4.7 3.2 1.3 0.2 0
3 4.6 3.1 1.5 0.2 0
4 5.0 3.6 1.4 0.2 0
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 2
146 6.3 2.5 5.0 1.9 2
147 6.5 3.0 5.2 2.0 2
148 6.2 3.4 5.4 2.3 2
149 5.9 3.0 5.1 1.8 2[150 rows x 5 columns]生成图像如下
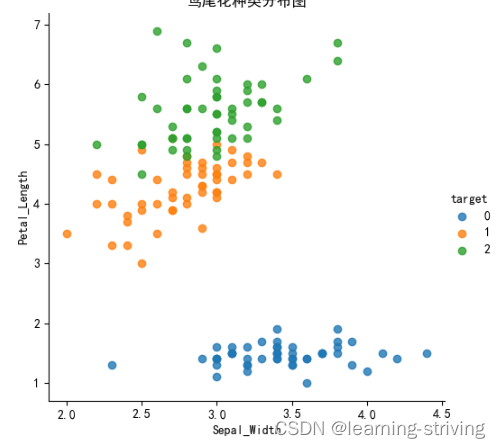
四、数据集的划分
机器学习一般的数据集会划分为两个部分
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例
- 训练集:70% 80% 75%
- 测试集:30% 20% 25%
- 数据集划分api:sklearn.model_selection.train_test_split(arrays, *options)
- x:数据集的特征值
- y:数据集的标签值(目标值)
- test_size:测试集的大小,一般为float
- random_state:随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同
- return:测试集特征训练集特征值值,训练标签,测试标签(默认随机取)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris() # 获取鸢尾花数据集
# 对鸢尾花数据集进行分割
# x_train:训练集的特征值
# x_test:测试集的特征值
# y_train:训练集的目标值
# y_test:测试集的目标值
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
print('训练集特征值x_train为:\n', x_train)
print('测试集特征值x_test为:\n', x_test)
print('训练集目标值y_train为:\n', y_train)
print('测试集目标值y_test为:\n', y_test)
print("训练集特征值x_train的形状为:", x_train.shape)
print("测试集特征值x_test的形状为:", x_test.shape)
print("训练集目标值y_train的形状为:", y_train.shape)
print("测试集目标值y_test的形状为:", y_test.shape)
# 随机数种子
print('-------------------验证random_state的不同----------------------')
x_train1, x_test1, y_train1, y_test1 = train_test_split(iris.data, iris.target, test_size=0.2, random_state=6)
x_train2, x_test2, y_train2, y_test2 = train_test_split(iris.data, iris.target, test_size=0.2, random_state=6)
print("训练集特征值x_train1的形状为:", x_train1.shape)
print("测试集特征值x_test1的形状为:", x_test1.shape)
print('-----------------------------------------')
print('测试集目标值y_test为:\n', y_test)
print('测试集目标值y_test1为:\n', y_test1)
print('测试集目标值y_test2为:\n', y_test2)
--------------------------------------------------------------------------
--------------------------------------------------------------------------
输出:
训练集特征值x_train为:[[4.8 3.1 1.6 0.2][5.4 3.4 1.5 0.4]…… # 省略,共120条[6.4 2.8 5.6 2.2][7.7 3.8 6.7 2.2]]
测试集特征值x_test为:[[5.4 3.7 1.5 0.2]…… # 省略,共30条[6.2 2.8 4.8 1.8]]
训练集目标值y_train为:[0 0 1 1 1 0 0 0 2 2 1 1 0 0 1 1 2 2 0 1 1 2 0 0 0 0 0 0 2 1 1 2 0 0 0 0 10 1 1 1 1 1 0 1 2 0 2 1 2 1 1 1 0 0 2 1 0 1 1 2 2 0 2 0 2 0 1 0 2 1 2 1 20 1 1 1 1 2 0 0 2 1 1 0 1 0 2 2 2 2 0 2 2 0 1 1 0 2 0 1 0 2 0 2 2 0 2 0 10 0 2 1 2 2 0 2 2]
测试集目标值y_test为:[0 2 1 2 1 1 1 2 1 0 2 1 2 2 0 2 1 1 2 1 0 2 0 1 2 0 2 2 2 2]
训练集特征值x_train的形状为: (120, 4)
测试集特征值x_test的形状为: (30, 4)
训练集目标值y_train的形状为: (120,)
测试集目标值y_test的形状为: (30,)
-------------------验证random_state的不同----------------------
训练集特征值x_train1的形状为: (120, 4)
测试集特征值x_test1的形状为: (30, 4)
-----------------------------------------
测试集目标值y_test为:[0 2 1 2 1 1 1 2 1 0 2 1 2 2 0 2 1 1 2 1 0 2 0 1 2 0 2 2 2 2]
测试集目标值y_test1为:[0 2 0 0 2 1 2 0 2 1 2 1 2 2 1 2 2 1 1 0 0 2 0 0 1 1 1 2 0 1]
测试集目标值y_test2为:[0 2 0 0 2 1 2 0 2 1 2 1 2 2 1 2 2 1 1 0 0 2 0 0 1 1 1 2 0 1]学习导航:http://xqnav.top/
相关内容
热门资讯
埃菲尔铁塔在哪 中国仿建埃菲尔...
2019年4月26日,广西南宁市,街头惊现一座巨型山寨版埃菲尔铁塔,高约20米,白色塔身,造型逼真,...
世界上最漂亮的人 世界上最漂亮...
此前在某网上,选出了全球265万颜值姣好的女性。从这些数量庞大的女性群体中,人们投票选出了心目中最美...
北京的名胜古迹 北京最著名的景...
北京从元代开始,逐渐走上帝国首都的道路,先是成为大辽朝五大首都之一的南京城,随着金灭辽,金代从海陵王...
苗族的传统节日 贵州苗族节日有...
【岜沙苗族芦笙节】岜沙,苗语叫“分送”,距从江县城7.5公里,是世界上最崇拜树木并以树为神的枪手部落...
应用未安装解决办法 平板应用未...
---IT小技术,每天Get一个小技能!一、前言描述苹果IPad2居然不能安装怎么办?与此IPad不...
脚上的穴位图 脚面经络图对应的...
人体穴位作用图解大全更清晰直观的标注了各个人体穴位的作用,包括头部穴位图、胸部穴位图、背部穴位图、胳...
长白山自助游攻略 吉林长白山游...
昨天介绍了西坡的景点详细请看链接:一个人的旅行,据说能看到长白山天池全凭运气,您的运气如何?今日介绍...
demo什么意思 demo版本...
618快到了,各位的小金库大概也在准备开闸放水了吧。没有小金库的,也该向老婆撒娇卖萌服个软了,一切只...
猫咪吃了塑料袋怎么办 猫咪误食...
你知道吗?塑料袋放久了会长猫哦!要说猫咪对塑料袋的喜爱程度完完全全可以媲美纸箱家里只要一有塑料袋的响...
埃菲尔铁塔在哪 中国仿建埃菲尔...
2019年4月26日,广西南宁市,街头惊现一座巨型山寨版埃菲尔铁塔,高约20米,白色塔身,造型逼真,...
苗族的传统节日 贵州苗族节日有...
【岜沙苗族芦笙节】岜沙,苗语叫“分送”,距从江县城7.5公里,是世界上最崇拜树木并以树为神的枪手部落...
长白山自助游攻略 吉林长白山游...
昨天介绍了西坡的景点详细请看链接:一个人的旅行,据说能看到长白山天池全凭运气,您的运气如何?今日介绍...
北京的名胜古迹 北京最著名的景...
北京从元代开始,逐渐走上帝国首都的道路,先是成为大辽朝五大首都之一的南京城,随着金灭辽,金代从海陵王...