
图解系统:
1.硬件结构
1.1.存储器的层次关系
每个存储器只和相邻的一层存储器设备打交道,并且存储设备为了追求更快的速度,所需的材料成本必然也是更高,也正因为成本太高,所以 CPU 内部的寄存器、L1\L2\L3 Cache 只好用较小的容量,相反内存、硬盘则可用更大的容量,这就我们今天所说的存储器层次结构。
另外,当 CPU 需要访问内存中某个数据的时候,如果寄存器有这个数据,CPU 就直接从寄存器取数据即可,如果寄存器没有这个数据,CPU 就会查询 L1 高速缓存,如果 L1 没有,则查询 L2 高速缓存,L2 还是没有的话就查询 L3 高速缓存,L3 依然没有的话,才去内存中取数据。
1.2.CPU
1.2.1.CPU缓存结构
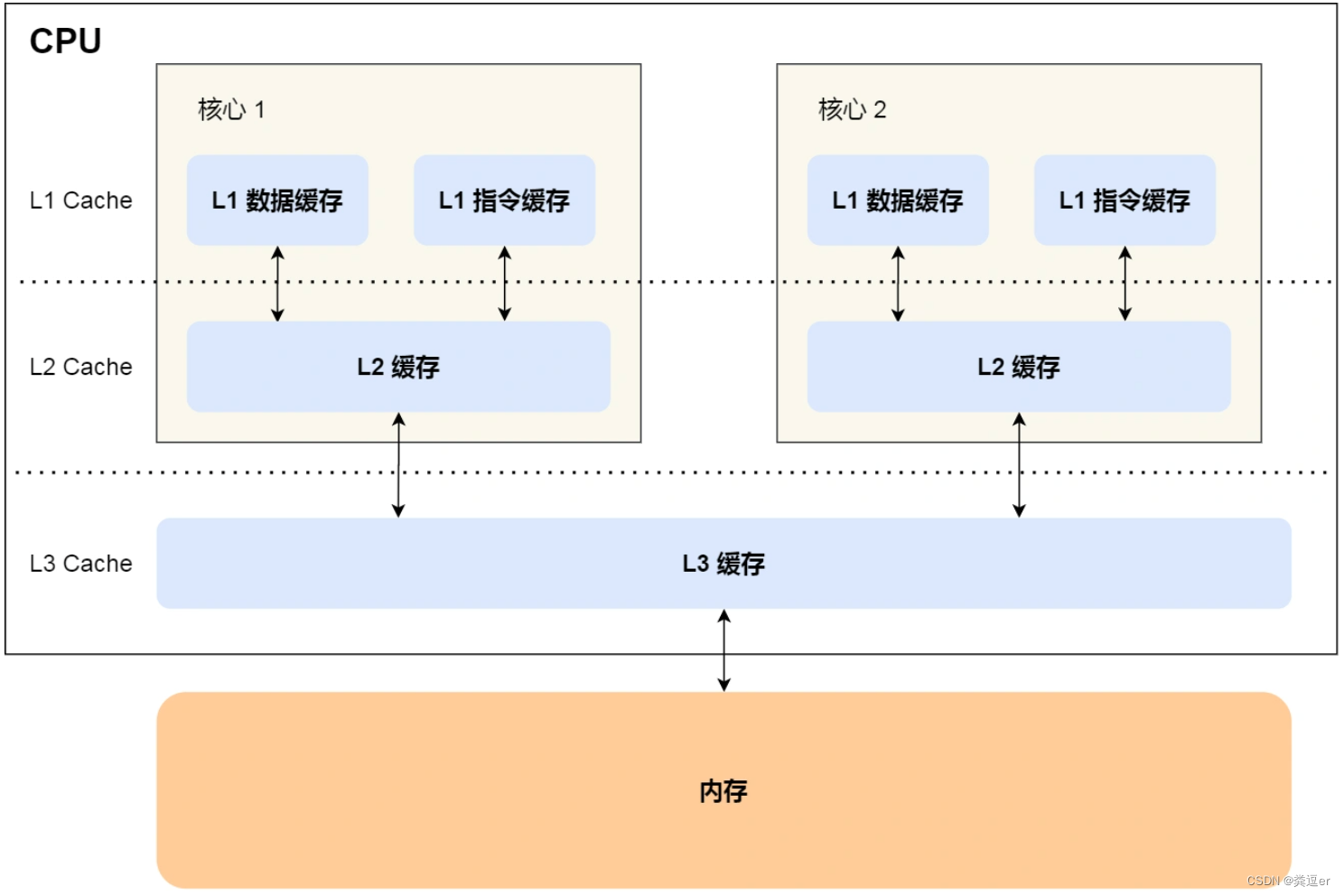
L1高速缓存
- L1高速缓存的访问速度几乎和寄存器一样快,通常只需要2~4个时钟周期,而大小在几十KB到几百KB不等。
- 每个 CPU 核心都有一块属于自己的 L1 高速缓存,指令和数据在 L1 是分开存放的,所以 L1 高速缓存通常分成指令缓存和数据缓存。
L2高速缓存
- L2高速缓存,L2 高速缓存同样每个 CPU 核心都有,但是 L2 高速缓存位置比 L1 高速缓存距离 CPU 核心 更远,它大小比 L1 高速缓存更大,CPU 型号不同大小也就不同,通常大小在几百 KB 到几 MB 不等,访问速度则更慢,速度在
10~20个时钟周期
L3高速缓存
- L3 高速缓存通常是多个 CPU 核心共用的,位置比 L2 高速缓存距离 CPU 核心 更远,大小也会更大些,通常大小在几 MB 到几十 MB 不等,具体值根据 CPU 型号而定。
- 访问速度相对也比较慢一些,访问速度在
20~60个时钟周期。
1.2.2.CPU Cache的数据结构和读取过程是什么样的?
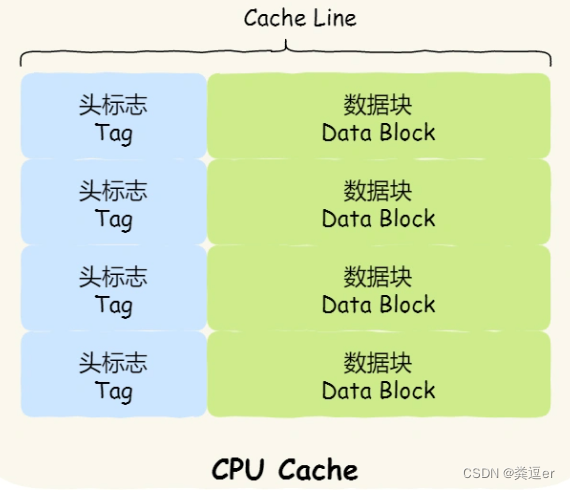
CPU Cache结构
- Cpu Cache是由很多Cache Line组成的
- Cache Line是CPU从内存读取数据的基本单位:CPU每次从内存中读取数据的最小单位
- 服务器的 L1 Cache Line 大小是 64 字节,也就意味着 L1 Cache 一次载入数据的大小是 64 字节
- Cache Line是由各种标志Tag+数据块Data Block组成
1.2.3.如何写出让CPU跑的更快的代码?
「如何写出让 CPU 跑得更快的代码?」这个问题,等价于「如何写出 CPU 缓存命中率高的代码?」
在前面我也提到, L1 Cache 通常分为「数据缓存」和「指令缓存」,这是因为 CPU 会分别处理数据和指令,比如 1+1=2 这个运算,+ 就是指令,会被放在「指令缓存」中,而输入数字 1 则会被放在「数据缓存」里。
因此,我们要分开来看「数据缓存」和「指令缓存」的缓存命中率
① 如何提升数据缓存的命中率?
遍历二维数组,有2种形式
array[i][j]访问数组元素的顺序,正是和内存中数组元素存放的顺序一致array[j][i]来访问,则访问的顺序就是跳跃式
因此,遇到这种遍历数组的情况时,按照内存布局顺序访问,将可以有效的利用 CPU Cache 带来的好处,这样我们代码的性能就会得到很大的提升
② 如何提升指令缓存的命中率?
- 第一个操作,循环遍历数组,把小于 50 的数组元素置为 0;
- 第二个操作,将数组排序
实际上,CPU 自身的动态分支预测已经是比较准的了,所以只有当非常确信 CPU 预测的不准,且能够知道实际的概率情况时,才建议使用这两种宏。
1.2.4.如何提升多核 CPU 的缓存命中率?
比如在 C/C++ 语言中编译器提供了 likely 和 unlikely 这两种宏,如果 if 条件为 ture 的概率大,则可以用 likely 宏把 if 里的表达式包裹起来,反之用 unlikely 宏。
实际上,CPU 自身的动态分支预测已经是比较准的了,所以只有当非常确信 CPU 预测的不准,且能够知道实际的概率情况时,才建议使用这两种宏。
1.2.5.如何提升多个CPU的缓存命中率?
现代 CPU 都是多核心的,线程可能在不同 CPU 核心来回切换执行,这对 CPU Cache 不是有利的,虽然 L3 Cache 是多核心之间共享的,但是 L1 和 L2 Cache 都是每个核心独有的,如果一个线程在不同核心来回切换,各个核心的缓存命中率就会受到影响,相反,如果线程都在同一个核心上执行,那么其数据的 L1 和 L2 Cache 的缓存命中率可以得到有效提高,缓存命中率高就意味着 CPU 可以减少访问 内存的频率。
当有多个同时执行「计算密集型」的线程,为了防止因为切换到不同的核心,而导致缓存命中率下降的问题,我们可以把线程绑定在某一个 CPU 核心上,这样性能可以得到非常可观的提升。
实现方式:在 Linux 上提供了 sched_setaffinity 方法,来实现将线程绑定到某个 CPU 核心这一功能。
2.CPU缓存一致性
2.1.CPU Cache 的数据写入
数据不光是只有读操作,还有写操作,那么如果数据写入 Cache 之后,内存与 Cache 相对应的数据将会不同,这种情况下 Cache 和内存数据都不一致了,于是我们肯定是要把 Cache 中的数据同步到内存里的。