
记一次InputStream流读取不完整留下的惨痛教训
前言
首先,问问大家下面这段流读取的代码是否存在问题呢?
inputStream = ....
try {// 根据inputStream的长度创建字节数组byte[] arrayOfByte = new byte[inputStream.available()];// 调用read 读取字节数组inputStream.read(arrayOfByte, 0, arrayOfByte.length);return new String(arrayOfByte);
}catch (Exception e){e.printStackTrace();
}
实际上的确是有问题的,而且在线上环境结结实实的坑了我们一把。
问题回溯
- 在xx银行项目上,报了下面的一个错误信息,数组越界,如下图所示:
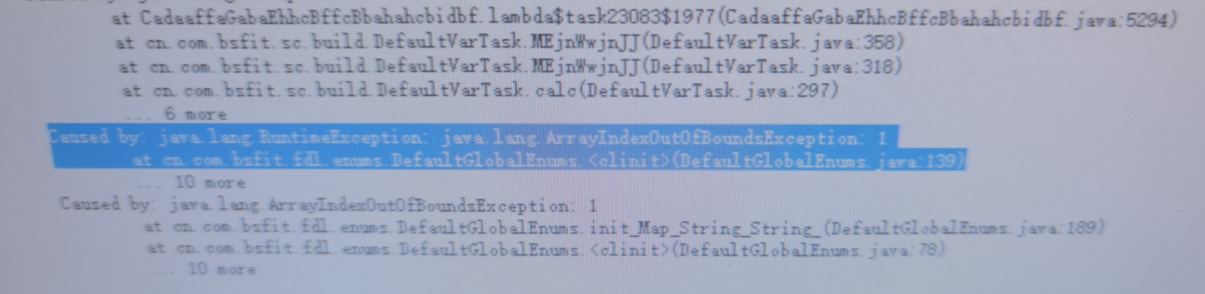
- 反编译jar包的代码,在如下位置用到了数组读取,根据=号切割为组数,如下图所示:
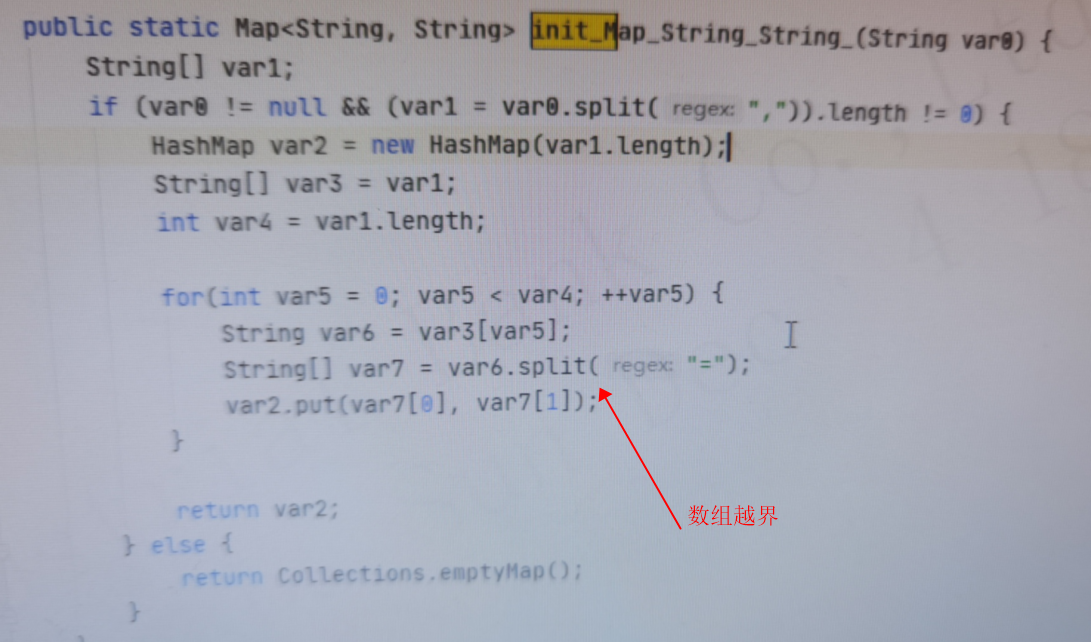
- 而这个切割的字符串,是调用
loadResource方法加载ORG_PATH_MAP得到,如下图所示:

- 我们再来看下
loadResource的代码:
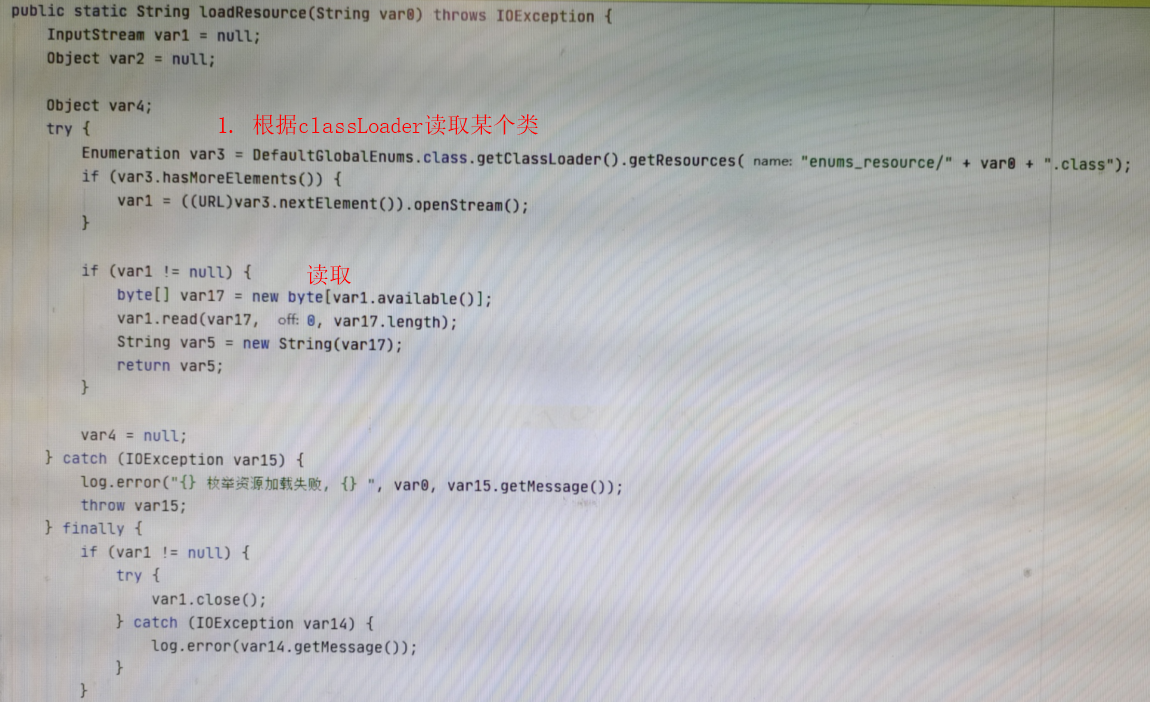
- 这里的是加载
ORG_PATH_MAP.class文件的内容,这个文件虽然class,但是里面存储内容的格式如下:
zj=浙江分公司,sh=上海分公司,fz=福州分公司
在我们多次确认数据格式也没有问题以后,就陷入了沉思,大家有发现什么问题呢?
原因分析
我们就怀疑读取的时候是不是有问题,是不是读取得不完整导致得。
我们看了下InputStream类的javadoc:
available()
返回可以从此输入流读取(或跳过)的字节数的估计值 ,返回的不是整个数据的长度, 是这次read可读的长度。
InputStream的不同子类对InputStream.available()可能会有不同的实现,一些实现会返回当前可一次无阻塞读入的字节数,另一些实现会返回这个输入流可读入的字节总数, 因此应尽量避免使用该返回值作为开辟能容纳该输入流所有数据的缓冲大小依据。
int read(byte b[], int off, int len)
从输入流中读取最多len字节的数据到字节数组中。尝试读取最多len字节,但可能会读取更小的数字。实际读取的字节数以整数形式返回。
所以做了一个demo试了一下:
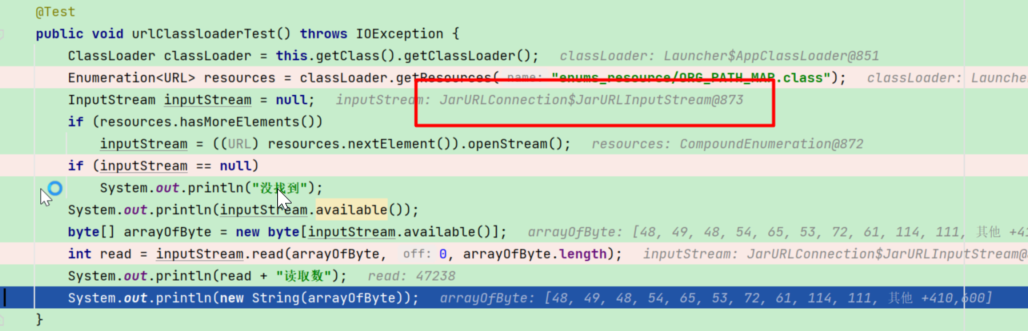
- 有问题的这个项目是用
AppClassLoader加载当前路径下的类,可以发现InputStream的实现类是JarURLInputStream
运行结果如下图,可能确实发现读少了。

小结: 在读物流时调用的是available方法,点击进入其源码发现其返回的是当前流可用长度(估计值),不是流的总长度。而在read方法读取流中数据到buffer中,但读取长度为1至buffer.length,若流结束或遇到异常则返回-1。也就是说当实际文件的长度超过此估计可用长度时也不会继续读,而是结束读取。从而导致读取的流并不完整。这很大程度取决于不同的实现。
解决方案
方案一:
public static byte[] streamToByteArray(InputStream in) throws IOException {ByteArrayOutputStream output = new ByteArrayOutputStream();byte[] buffer = new byte[4096];int n;while (-1 != (n = in.read(buffer))) {output.write(buffer, 0, n);}return output.toByteArray();}
借助ByteArrayOutputStream,通过循环去读取流,直到读取完成,如果返回-1,表示全部读取完成。
方案二:
public static byte[] streamToByteArray(InputStream in) throws IOException {byte[] bytes = new byte[bufferlength];BufferedInputStream bis = new BufferedInputStream(is);int length = bis.read(bytes, 0, bufferlength)return bytes;}
采用BufferedInputStream,它底层其实也是循环读取。
为什么测试没发现?
实际情况是我们这是一个公共jar,被不同的组件下载,有的组件放到classpath下通过AppClassloader加载,有的组件通过自定义的classLoader加载,开发测试我们都是用的自定义DynamicClassloader加载,它的InputStream的实现类是ByteInputStream,是没有发现问题的。
而本次是另外一个spark组件, 他们把jar 放到了classpath下 也就是用AppClassloader,最终用了JarURLInputStream读取,出现问题。
总结
- 在代码编写过程中,available()方法仅用于估算接收数据的总长度或数据块的长度,不要用于任何需要准确计算的场合,更不要用于开辟一个可以刚好容纳所有数据的缓冲区。
- 对于调用InputStream.read(…),务必进行循环调用,直至返回-1,无论输入数据源是网络数据还是本地文件。
在平时的开发过程中,还是需要注重细节,不然会出现意料不到的问题。
如果本文对你有帮助的话,请留下一个赞吧
更多技术干活欢迎关注公众号——JAVA旭阳
