【rpc】超详细介绍
文章目录
- rpc通信流程
- rpc是什么
- 通信流程
- 协议
- 序列化
- 网络通信
- 常见的网络IO模型
- 同步阻塞IO
- IO多路复用
- 同步阻塞IO和IO多路复用最常用
- 零拷贝
- Netty的零拷贝
- 动态代理: 面向接口编程, 屏蔽rpc处理流程
- grpc原理
- 服务发现
- zk
- 基于`消息总线`的`最终一致性`的`注册中心`
- 健康检测
- 路由策略
- 负载均衡
- 异常重试
- 时钟轮
只要设计到网络通信, 就可能用到rpc, 其是解决分布式系统通信的利器, rpc对网络用心细节做了包装, 让应用开发更简单, 也让网络更安全可靠.
rpc有多种实现, grpc,brpc,thrift,dubbo
rpc通信流程
rpc是什么
rpc是remote procedure call, 即远程过程调用
- 背景: 单体拆分为微服务(因为单体耦合太重,牵一发而动全身), 那微服务之间就需要通信, 就需要rpc
- 其功能如下
- 帮我们屏蔽网络编程细节
- 屏蔽远程调用和本地调用的区别, 感觉是调用项目内的function
通信流程
默认用tcp传输
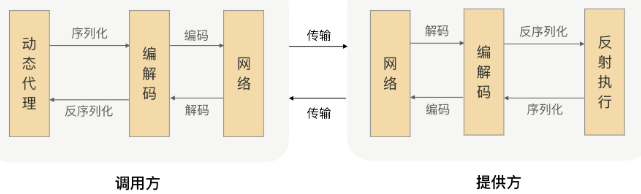
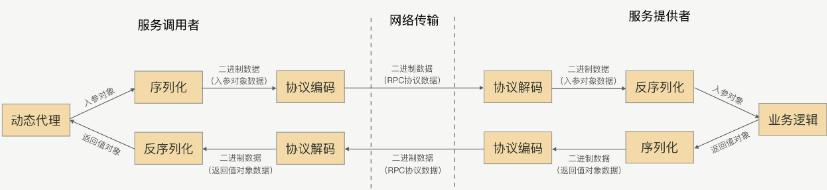
序列化: 网络中传输的都是二进制数据, 但调用方function的入参出参都是对象, 需转为二进制
协议: 约定消息头/消息体的格式.消息头包括协议标识,数据大小,数据类型,序列化类型等; 用于是接收方可正确截断消息
由服务提供者给出业务接口声明, 在调用方的程序里, rpc框架根据接口, 提前生成动态代理实现类, 通过依赖注入注入到声明了该接口的业务逻辑里. 此代理类会拦截所有方法, 在提供的方法处理逻辑里完成一整套远程调用, 把结果返回给调用方.
协议
二进制数据, 被拆分为各个包, 各包需要根据协议截断内容(类似根据标点符号,对一段文字断句,如将ABCDEF解析为AB,CD,EF还是解析为ABC,DEF)
为什么不能用HTTP协议,而单独弄一个新的RPC协议呢?
因为HTTP数据包更大,包含更多无用内容(如换行符,回车符); HTTP1协议无状态(每次请求都需要重新建立连接,响应完毕后再关闭连接)
序列化
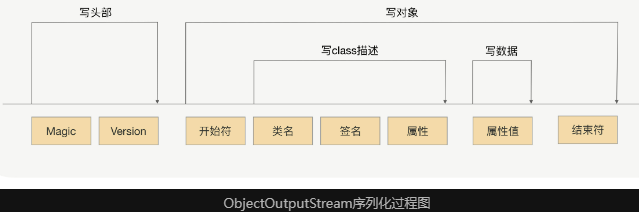
序列化的过程, 就是在读取数据对象时, 不断加入一些特殊分隔符, 其在反序列化时用于截断.
- 头部数据: 声明序列化协议, 序列化版本
- 数据对象: 类名,属性名,属性类型,属性值
有如下常见序列化类型 - JDK原生序列化
- JSON
空间开销大(内存和硬盘)
没有类型, 性能不太好 - Hession
动态类型,二进制,紧凑,可跨语言移植; 但对一些常见的java数据类型不支持 - protobuf
序列化后体积小,序列化/反序列化速度快(无需通过反射),用IDL定义
网络通信
常见的网络IO模型
同步阻塞IO
应用程序发起IO调用, 应用进程被阻塞, 转到内核空间处理.
之后内核等待数据, 等待到数据之后, 再将内核的数据拷贝到用户内存中.
整个IO处理完毕后, 返回应用进程, 最后应用进程解除阻塞状态, 继续运行后续业务逻辑.
去餐厅吃饭(一个人去的),到餐厅向服务员点餐后,一直在餐厅等饭做好,才能吃
IO多路复用
高并发场景常用, 如java的NIO,Redis,Nginx,Reactor模型
- 流程: 将多个
网络连接的IO,注册到一个复用器(select)上,当用户进程调用了select时整个进程会被阻塞.此时内核会监视所有select负责的socket. 当任何一个socket中的数据准备完毕时, select就会返回. 此时用户进程再调用read来把数据从内核拷贝到用户进程. - 特点: 当用户发起select调用,进程会被阻塞,当该select负责的sockrt有准备好的数据时才返回,之后才发起1次read,珍格格了流程比阻塞IO复杂,更浪费性能.但好处是可在1个线程内同时处理多个socket的IO请求.
用户可以注册多个socket, 然后不断地调用select读取被激活的socket, 达到在同一个线程内同时处理多个IO请求的目的.
去餐厅吃饭(很多人一起去), 我们专门留一个人在餐厅排号等位, 其他人去逛街, 当排号的朋友通知我们, 我们再去吃.
同步阻塞IO和IO多路复用最常用
需要os内核支持,和编程语言的支持
因为多数os都有同步阻塞IO,非阻塞IO,IO多路复用; 但只有高版本的Linux才有信号驱动IO,异步IO
无论C++还是Java的网络框架,都基于Reactor模式,而Reactor模式是基于IO多路复用的
这两种网络IO模型, 可满足绝大多数场景
对比如下
- IO多路复用: 适合高并发, 用较少的用户进程(线程), 处理较多的socket的IO请求, 但使用难度高. 而Java的很多框架对Java原生API做了封装(如Netty); Go官方就封装了, 用起来很简洁.
- 阻塞IO: 适合低并发和简单场景. 没处理1个socket的IO请求, 都会阻塞IO进程(线程), 使用难度低, 开销少.
一般rpc框架是高并发场景, 故选多路复用方式. Java则选Netty, Linux需开启epoll提升系统性能.
零拷贝
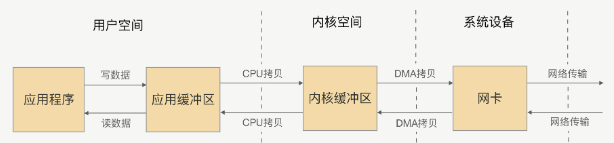
避免数据从用户空间到内核空间的拷贝, 而是将用户空间和内核空间的数据都写到同一个地方(即虚拟内存)
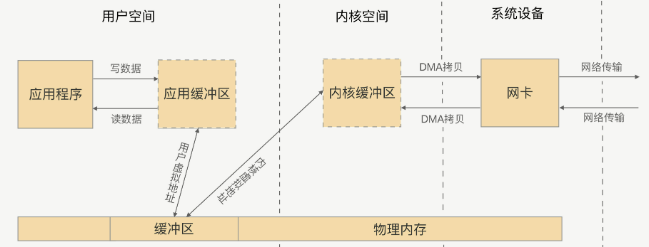
有2种方式: mmap+write方式,和sendfile方式, 核心都是通过虚拟内存解决的
Netty的零拷贝
Netty是完全在用户空间上(即JVM上), 主要是数据操作的优化.
因为二进制数据很多,需要发送端拆为多个包,接收端再合并. 这个过程都在用户空间完成(因为是应用程序处理的), 处理过程会存在用户空间到用户空间的拷贝.

动态代理: 面向接口编程, 屏蔽rpc处理流程
rpc会自动为接口生成代理类,在项目中注入接口后,运行过程中实际绑定的是这个接口生成的代理类.当接口方法被调用时,会被生成代理类拦截,这样我们可在生成的代理类中加入远程调用逻辑.
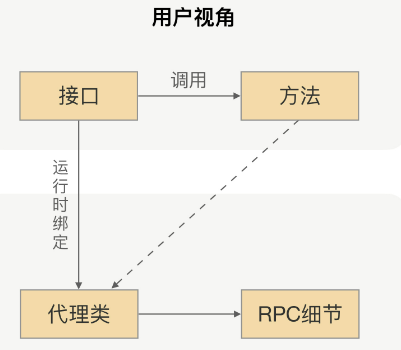
下文以java的实现为例
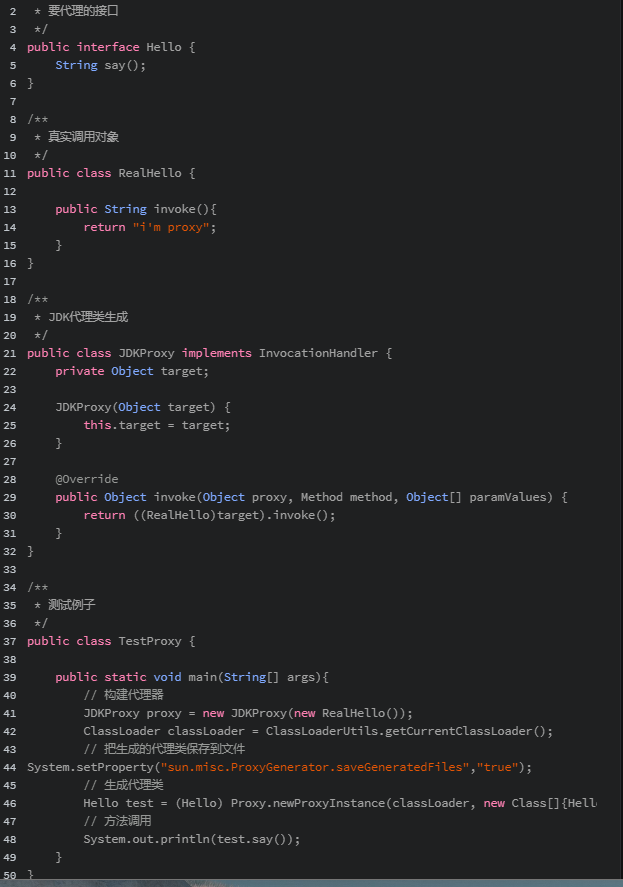
我们给Hello接口生成一个动态代理类, 调用其say()方法, 真实返回的值却是来自RealHello类里定义的invoke()方法

将字节码反编译后如下, 当我们调用Hello.say()时,其实被转发到了JDKProxy.invoke()
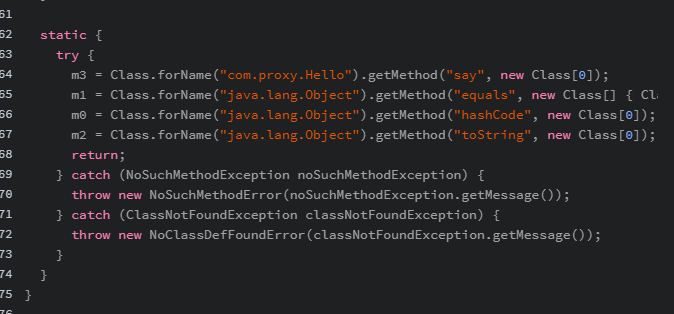
grpc原理
grpc协议是http/2,序列化支持pb和json

Http/2协议是双向的,如下
server端实现代码如下
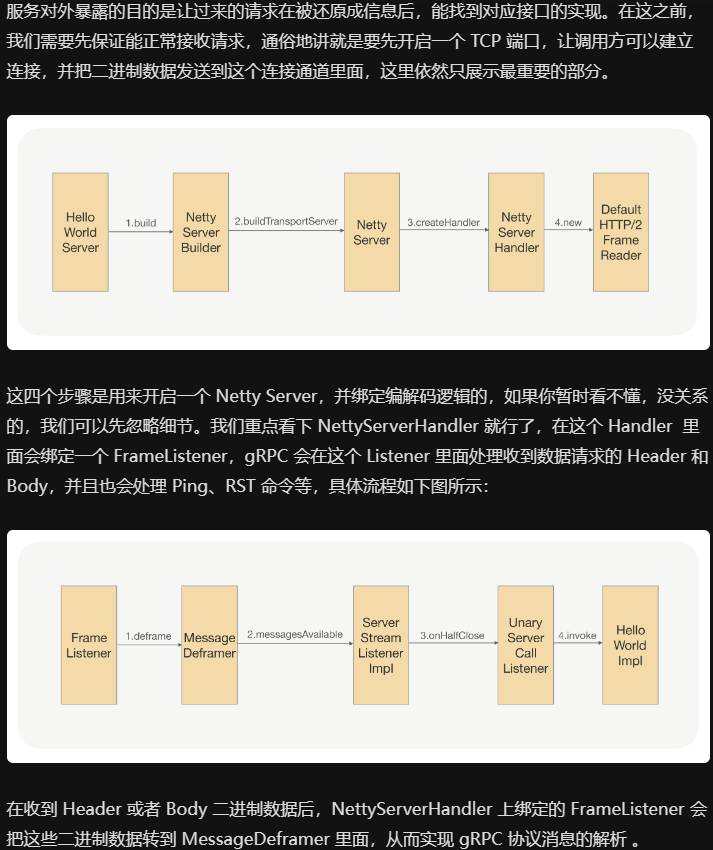
服务发现
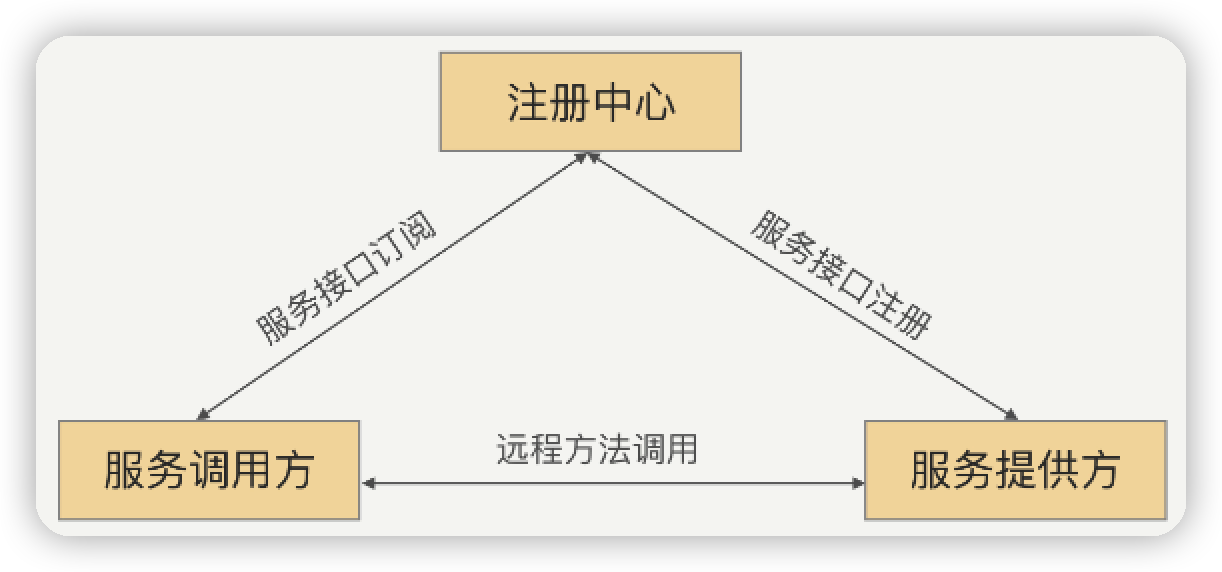
因为集群的IP可能随时变化, 故各服务间需要通讯录, 其记录服务和IP的映射关系
服务注册: server启动时, 将对外暴露的接口注册到注册中心
服务订阅: client启动时, 去注册中心查server的IP, 自己缓存一份
- 注册中心不能用
DNS代替
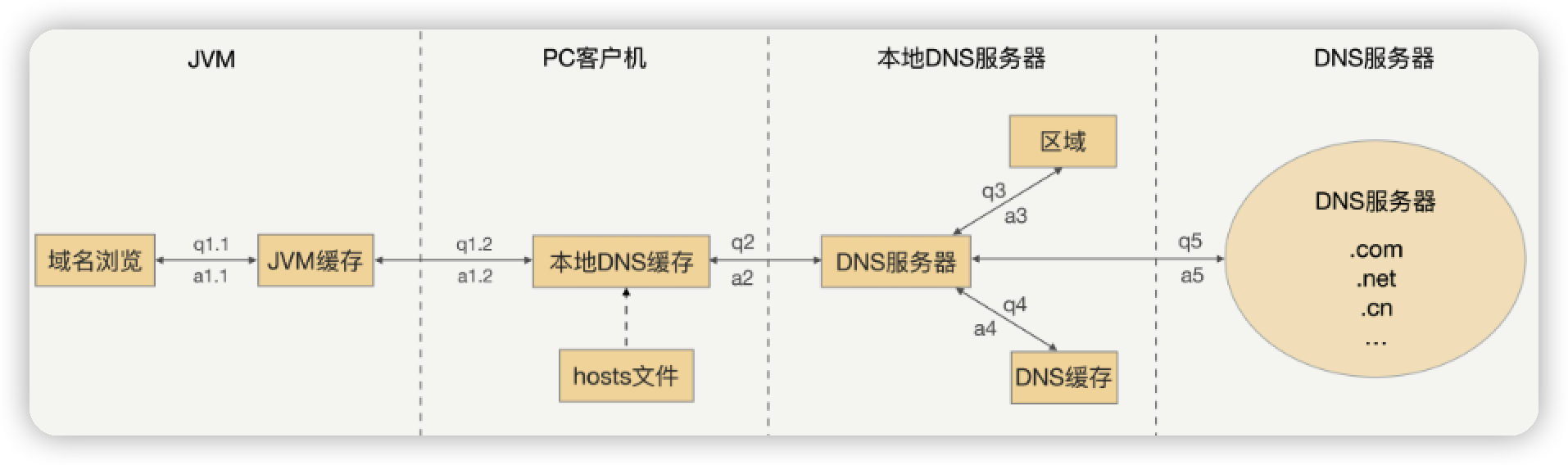
因为为了性能需减少DNS服务器的压力, DNS有多层缓存(且缓存时间较长), 若某节点下线或上线, 并不能让client及时感知到
zk
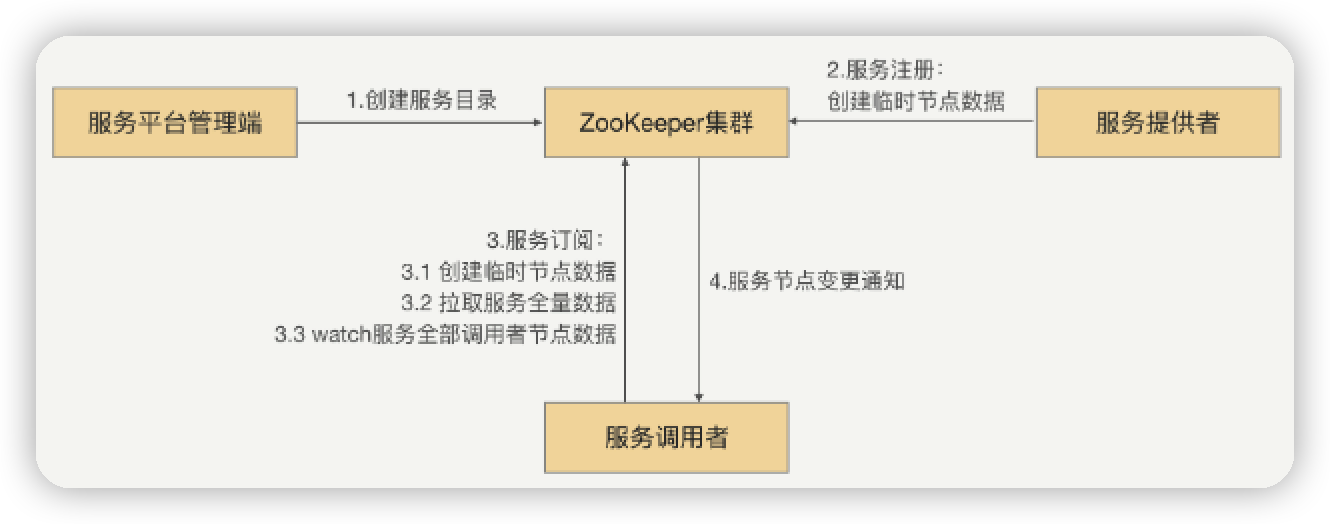
- 系统启动时, 在zk建立一个服务根路径, 根据接口名命名(如/service/com.demo.xxService), 再在此路径下为server建立provider文件夹存其节点信息, 为client建立consumer文件夹存其节点信息
- 当provider发起注册时, 在provier目录中建立一个临时节点, 其中存该注册信息
- 当consumer发起订阅时, 在consumer目录中建立一个临时节点, 其中存该调用信息; 并watch
对应的provider目录(/service/com.demo.xxService/provider)中各节点的数据 - 当provider目录下, 有节点数据变更时, zk通知所有的consumer
当各种服务集中上线时, zk或有cpu压力, 导致zk不能正常工作: 当连接到zk的节点很多时, zk读写频繁; 当zk目录数量太多事, zk的cpu飙升, 最终宕机
zk是强一致性的, 相当于几个人玩传递东西的游戏, 必须等这一轮所有人都拿到东西之后, 所有人才能开始下一轮; 而不是只要我拿到我的东西后, 就可以直接下一轮了.
基于消息总线的最终一致性的注册中心
最终一致性指: 希望某server上线后, 几秒钟时间内, 其他client可感知到, 而不要求立刻. 即牺牲CP强一致性, 选择AP最终一致性.
可基于消息总线实现此方案
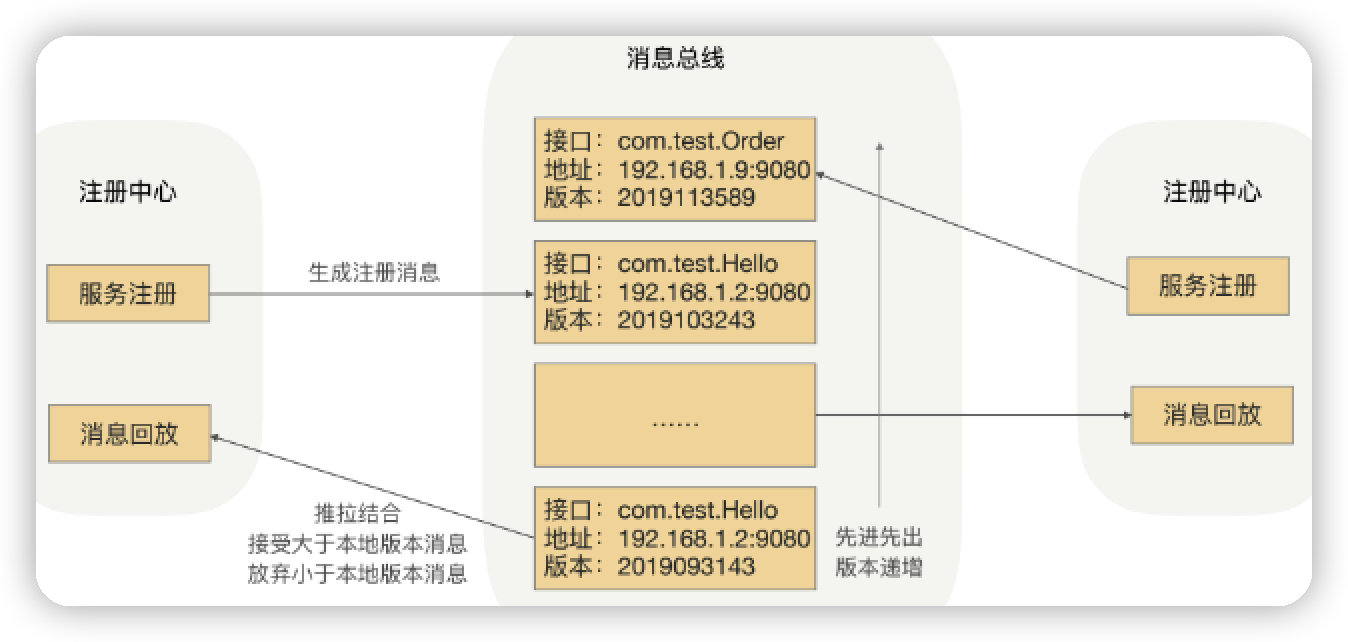
每当provier上线时, 向消息总线发一个msg(时间作为版本号)
消息总线会主动push消息到各node, 各node也会定时pull消息; 若msg.Version>自己.Version则更新
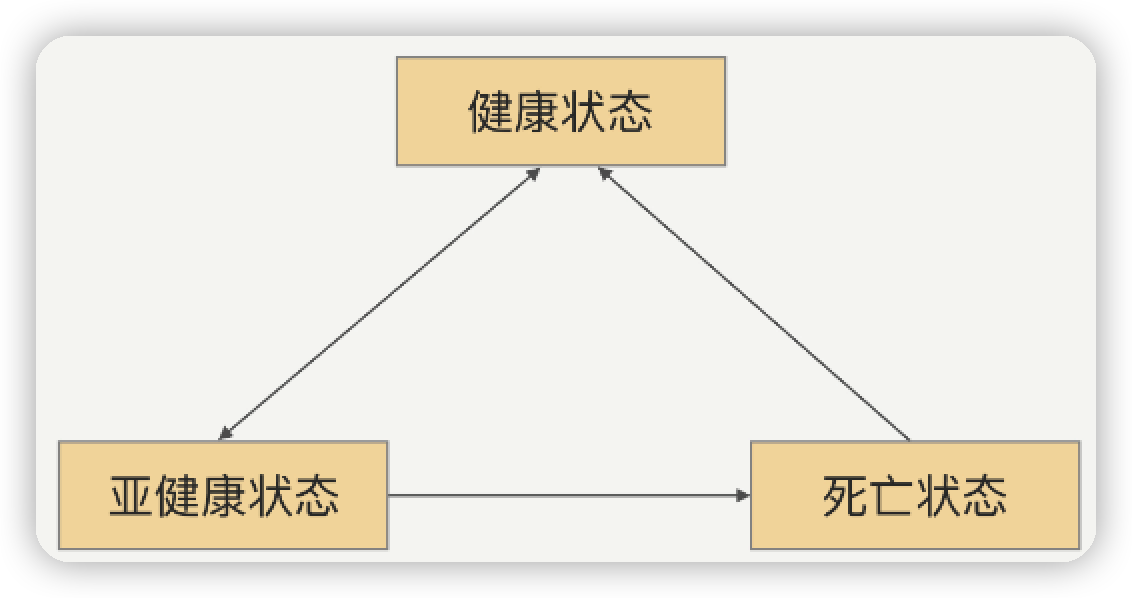
健康检测
为了检测到除了tcp网络断开之外, 应用程序业务的正常, 用心跳机制, 让各应用程序对外暴露http接口
用可用率(即某时间窗口内, 接口调用成功的次数/总调用次数)衡量如下3种健康状态
- 健康: 建立连接成功, 且心跳探活一直成功
- 亚健康: 建立连接成功, 但心跳探活连续失败
- 死亡: 建立连接失败
路由策略
灰度发布: 让小部分流量经过新上线的服务, 大部分仍经过原服务
负载均衡
rpc框架, 根据各node请求耗时, 判断各node压力(可能各node的配置性能不同), 对压力大的node调低权重, 对压力小的node调高权重, 最终使得各node负载均衡
异常重试
使用rpc框架时, 要确保业务逻辑是幂等的, 这样重试才不会影响业务
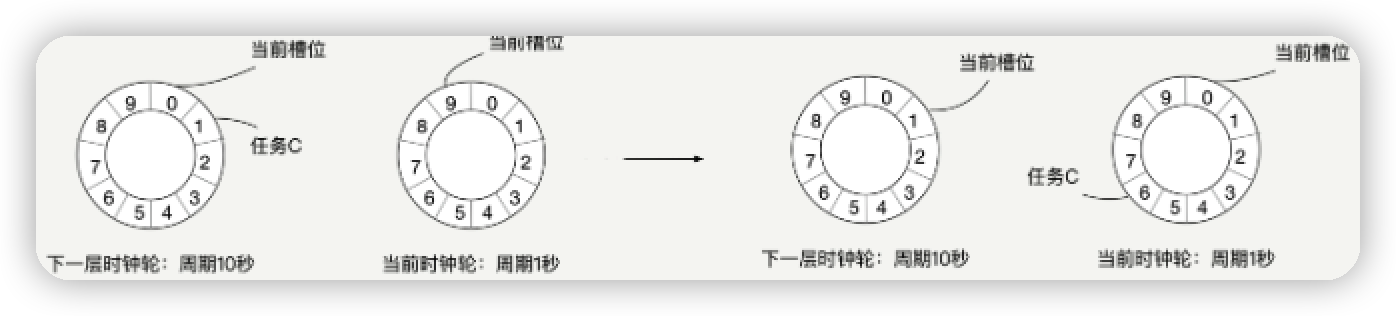
时钟轮
各种粒度的时钟(如秒,分,小时), 启动一个检测线程, 每走一个刻度后, 检测落在此刻度内的任务是否超时, 而不是每次判断所有任务, 节省CPU.