【论文阅读】SimGNN:A Neural Network Approach to Fast Graph Similarity Computation
文章目录
- 一、摘要
- 二、要完成的任务分析
- 三、图模型提取全局与局部特征
- 四、NTN模块的作用与效果
- 五、点之间的对应关系计算
论文来源:SimGNN:A Neural Network Approach to Fast Graph Similarity Computation
一、摘要
- 图形相似性搜索是最重要的基于图形的应用程序之一,例如查找与查询化合物最相似的化合物。
- 图相似性距离计算,如图编辑距离(GED)和最大公共子图(MCS),是图相似性搜索和许多其他应用程序的核心操作,但实际计算成本很高。
- 受神经网络方法最近成功应用于若干图形应用(如节点或图形分类)的启发,我们提出了一种新的基于神经网络的方法来解决这一经典但具有挑战性的图形问题,旨在减轻计算负担,同时保持良好的性能。
- 提出的方法称为SimGNN,它结合了两种策略。
- 首先,我们设计了一个可学习的嵌入函数,将每个图映射到一个嵌入向量中,从而提供图的全局摘要。提出了一种新的注意机制,以相对于特定的相似性度量来强调重要节点。
- 其次,我们设计了一种成对节点比较方法,用细粒度节点级信息补充图级嵌入。我们的模型在看不见的图上实现了更好的泛化,在最坏的情况下,两个图中的节点数以二次时间运行。
- 以GED计算为例,在三个真实图形数据集上的实验结果证明了该方法的有效性和有效性。具体而言,与一系列基线相比,我们的模型实现了更小的错误率和更大的时间减少,包括GED计算的几种近似算法,以及许多现有的基于图神经网络的模型。
- 我们的研究表明,SimGNN为图相似性计算和图相似性搜索的未来研究提供了一个新的方向
二、要完成的任务分析
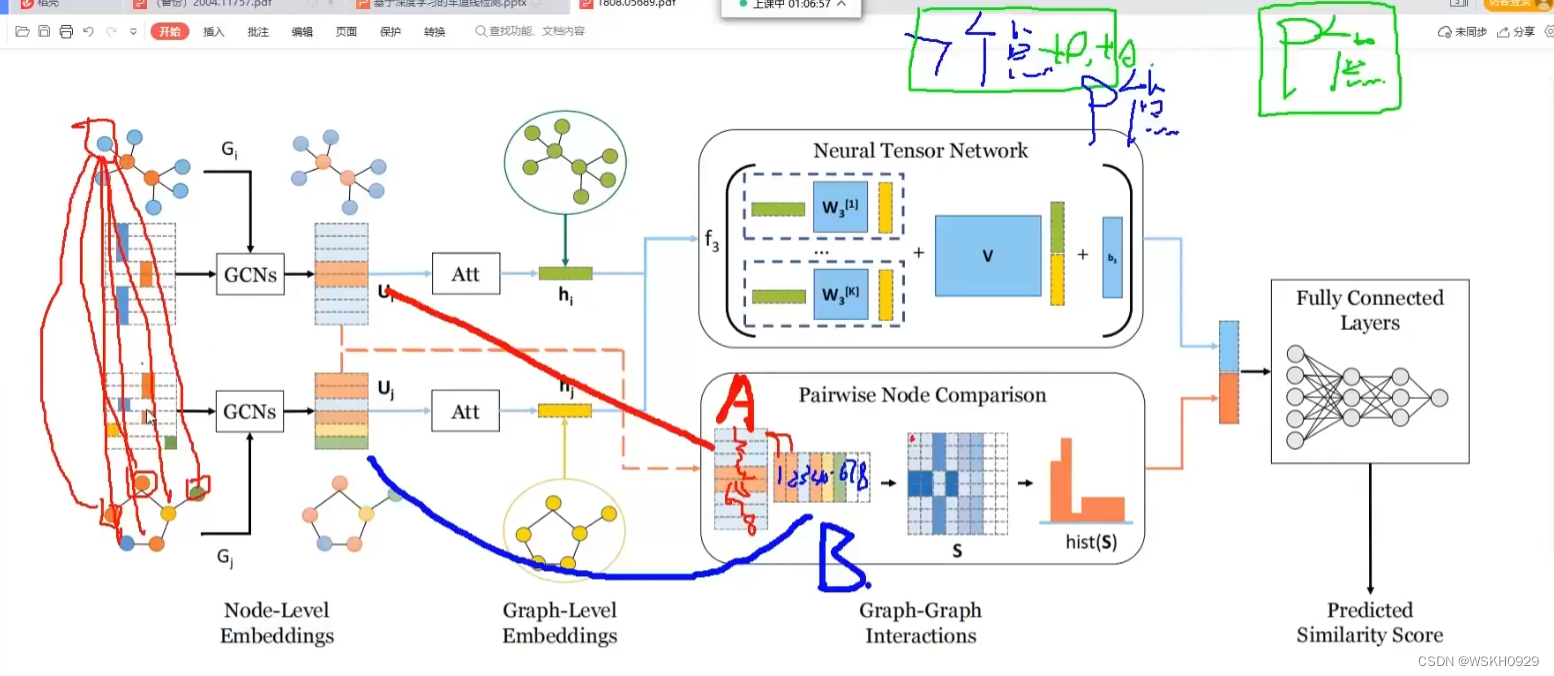
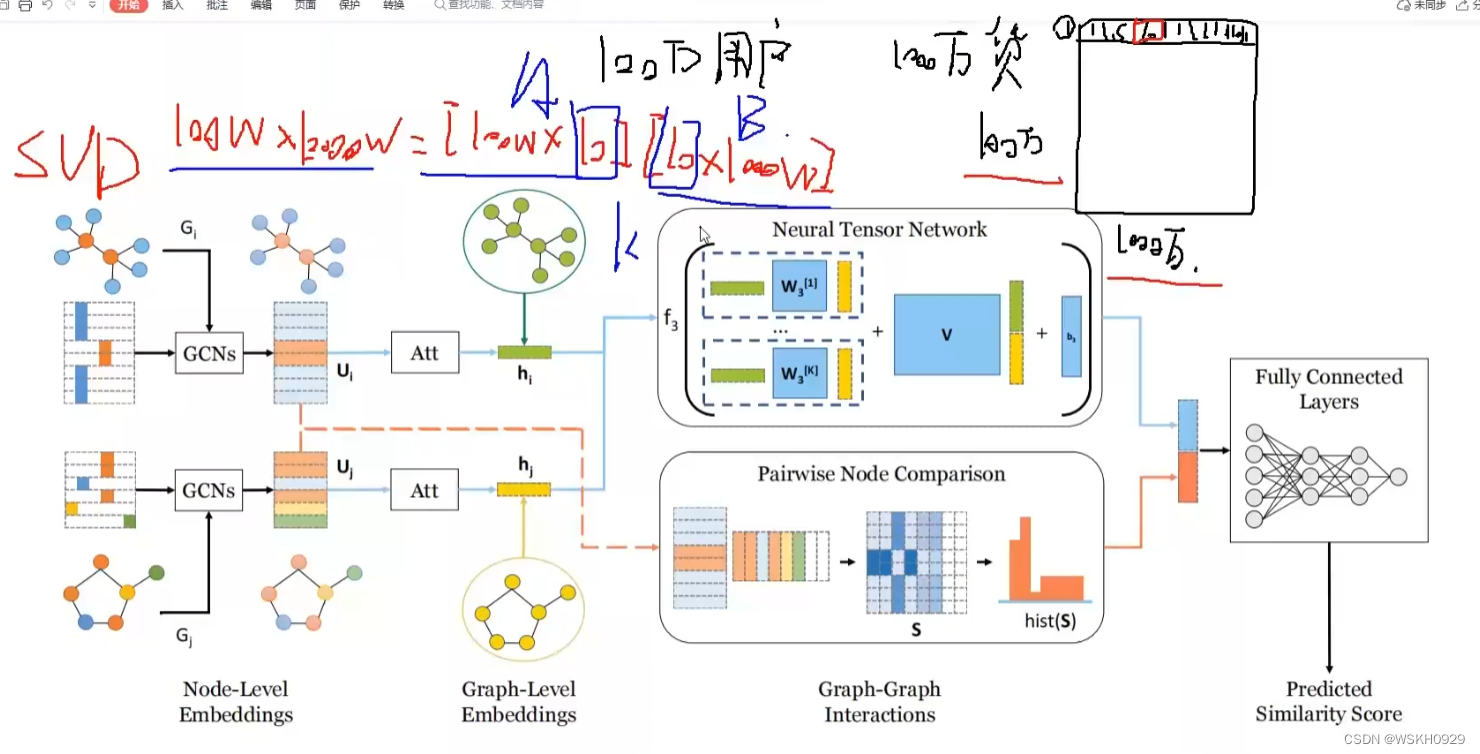
首先看看SimGNN的整体结构框图
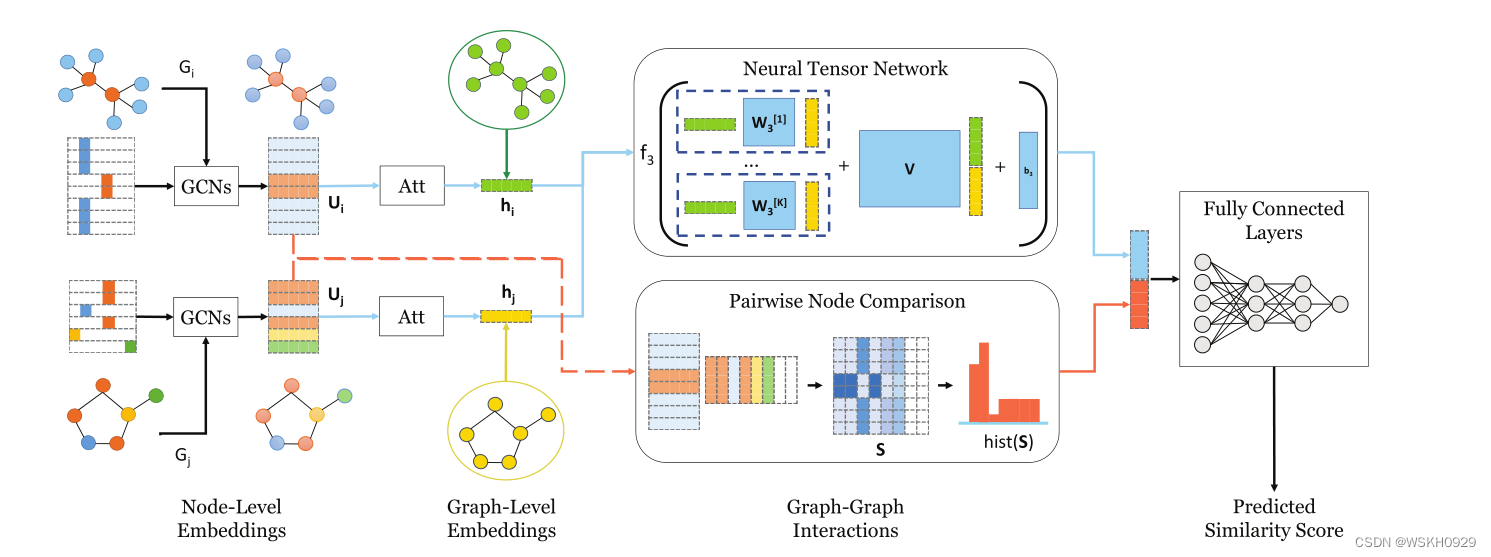
使用图神经网络,对图的相似度进行快速预测

任务分析
- 将图信息编译为一个向量(一个可学习的Embedding)
- 将点信息编译为一个向量(一个可学习的Embedding)

- 端到端的网络(end to end),即给定输入,返回输出,中间过程全部可计算梯度,可微
- 给定一对图(输入),返回他们的相似度得分(输出)
 、
、
- 采用基于注意力机制的聚合方法

三、图模型提取全局与局部特征
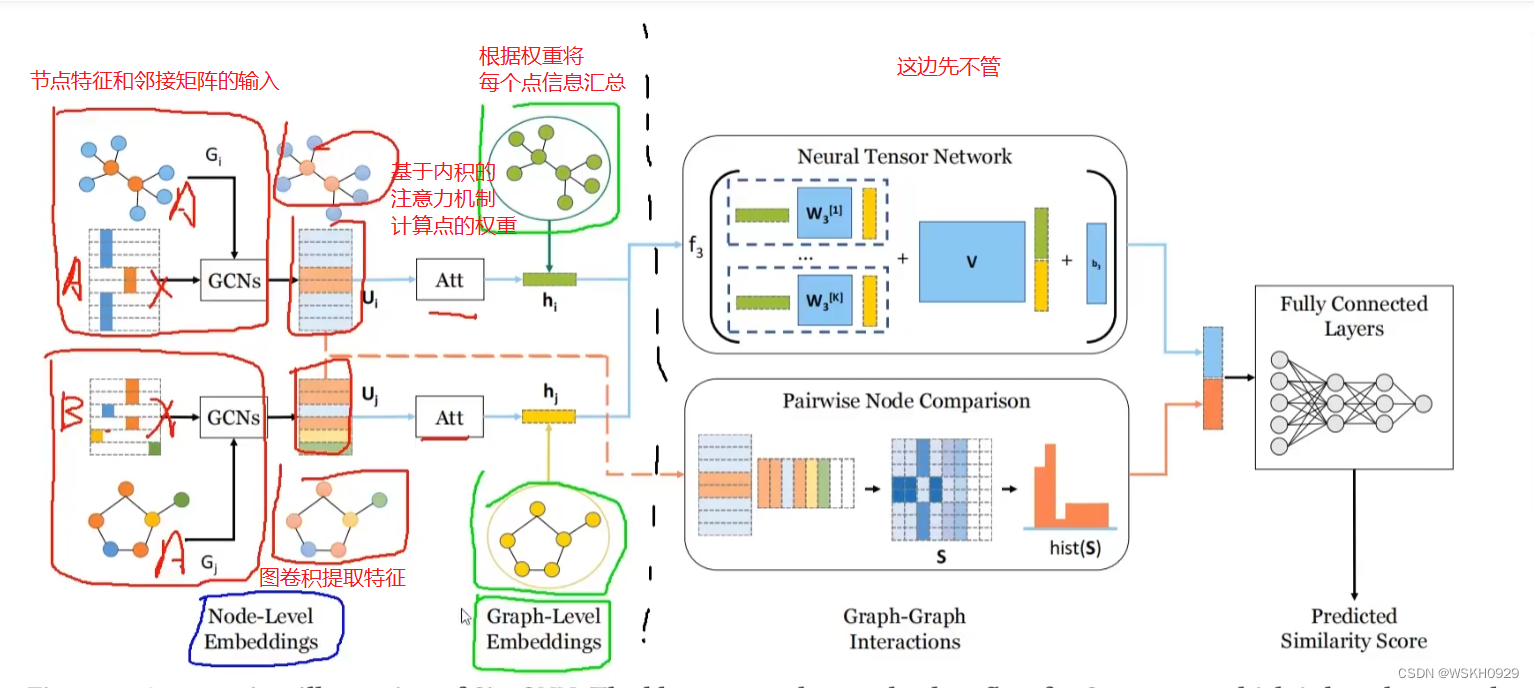
第一步:对点做编码(图卷积GCN)

第二步:对图编码
论文中说:“常规的对图编码是对图中每个点的Embedding做平均或者做加权平均(权重一般由点的度决定,度越大权重越大),但是现实中,有一些点的重要程度不是由它的度或者结构所能轻易决定的。”
所以作者采用了注意力机制进行权重的计算

作者采用的权重计算:点的特征与全局特征(由GCN提取)做内积,内积值越大权重越大(最后对内积结果做SoftMax归一化即可)

思路回顾
四、NTN模块的作用与效果
先用SVD矩阵分解做个简单的例子
假设有一个大矩阵 : 100w * 1000w ,如果我们直接对其作计算会非常慢
SVD矩阵分解:将其分解为 [100w * k] [k * 1000w] 两个小矩阵,中间的k就是他们之间的桥梁,我们可以通过计算两个小矩阵,不断迭代找到最合适的k,比较高效
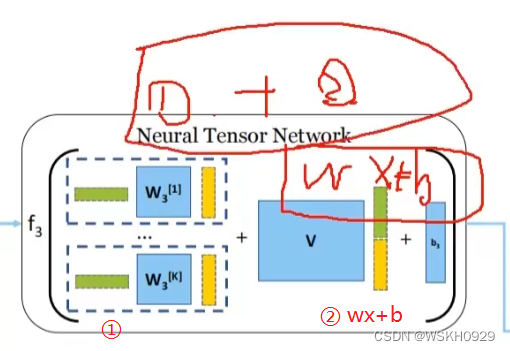
综上所述,再来看NTN模块,可以将其分为两个部分。
①:可以将可学习参数W理解为绿色向量和黄色向量的桥梁,去学习怎么将他们联系起来(即得到绿色向量和黄色向量的相同的关键特征)
②:将黄色和绿色向量拼接在一起,左乘一个矩阵再+上一个向量,相当于WX+B
①+②:将①和②两种方法提取的特征加在一起,进行特征融合,作为最后的结果输出
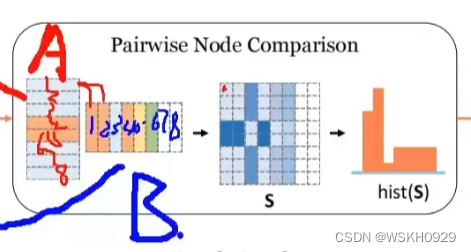
五、点之间的对应关系计算
评估两个图的相似度光靠全局特征肯定是不够的,例如两个班的平均分相同,但是具体哪个班的高分多却很难预测。所以,作者还考虑了两个图的点之间的对应关系计算。
如下图所示,A图中有8个点,B图中只有6个点。这可怎么办呢?作者的做法是,将点数量较少的用0向量进行填充,填充后的A的点矩阵和B的点矩阵就可以进行矩阵乘法了