
大数据技术基础实验十五:Storm实验——实时WordCountTopology
大数据技术基础实验十五:Storm实验——实时WordCountTopology
文章目录
- 大数据技术基础实验十五:Storm实验——实时WordCountTopology
- 一、前言
- 二、实验目的
- 三、实验要求
- 四、实验原理
- 1、Topologies
- 2、Spouts
- 3、Bolts
- 五、实验步骤
- 1、导入依赖jar包
- 2、编写代码
- 3、打包上传并运行
- 六、最后我想说
一、前言
本期实验我们将使用上期部署的Storm集群来进行一个任务实现——实时WordCountTopology。
二、实验目的
掌握如何用Java代码来实现Storm任务的拓扑,掌握一个拓扑中Spout和Bolt的关系及如何组织它们之间的关系,掌握如何将Storm任务提交到集群。
三、实验要求
编写一个Storm拓扑,一个Spout每个一秒钟随机生成一个单词并发射给Bolt,Bolt统计接收到的每个单词出现的频率并每隔一秒钟实时打印一次统计结果,最后将任务提交到集群运行,并通过日志查看任务运行结果。
四、实验原理
Storm集群和Hadoop集群表面上看很类似。但是Hadoop上运行的是MapReduce jobs,而在Storm上运行的是拓扑(topology),这两者之间是非常不一样的。一个关键的区别是: 一个MapReduce job最终会结束, 而一个topology永远会运行(除非你手动kill掉)。
1、Topologies
一个topology是spouts和bolts组成的图,通过stream groupings将图中的spouts和bolts连接起来,如下图所示。
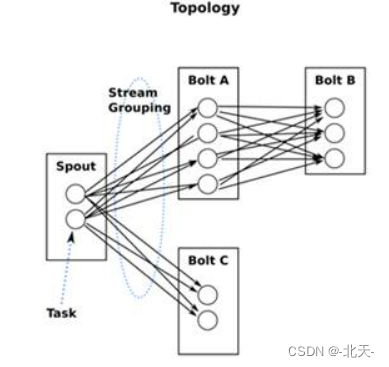
一个topology会一直运行直到你手动kill掉,Storm自动重新分配执行失败的任务, 并且Storm可以保证你不会有数据丢失(如果开启了高可靠性的话)。如果一些机器意外停机它上面的所有任务会被转移到其他机器上。
运行一个topology很简单。首先,把你所有的代码以及所依赖的jar打进一个jar包。然后运行类似下面的这个命令:
storm jar all-my-code.jar backtype.storm.MyTopology arg1 arg2
这个命令会运行主类: backtype.strom.MyTopology, 参数是arg1, arg2。这个类的main函数定义这个topology并且把它提交给Nimbus。storm jar负责连接到Nimbus并且上传jar包。
Topology的定义是一个Thrift结构,并且Nimbus就是一个Thrift服务, 你可以提交由任何语言创建的topology。上面的方面是用JVM-based语言提交的最简单的方法。
2、Spouts
消息源spout是Storm里面一个topology里面的消息生产者。一般来说消息源会从一个外部源读取数据并且向topology里面发出消息:tuple。Spout可以是可靠的也可以是不可靠的。如果这个tuple没有被storm成功处理,可靠的消息源spouts可以重新发射一个tuple, 但是不可靠的消息源spouts一旦发出一个tuple就不能重发了。
消息源可以发射多条消息流stream。使用OutputFieldsDeclarer.declareStream来定义多个stream,然后使用SpoutOutputCollector来发射指定的stream。
Spout类里面最重要的方法是nextTuple。要么发射一个新的tuple到topology里面或者简单的返回如果已经没有新的tuple。要注意的是nextTuple方法不能阻塞,因为storm在同一个线程上面调用所有消息源spout的方法。
另外两个比较重要的spout方法是ack和fail。storm在检测到一个tuple被整个topology成功处理的时候调用ack,否则调用fail。storm只对可靠的spout调用ack和fail。
3、Bolts
所有的消息处理逻辑被封装在bolts里面。Bolts可以做很多事情:过滤,聚合,查询数据库等等。
Bolts可以简单的做消息流的传递。复杂的消息流处理往往需要很多步骤,从而也就需要经过很多bolts。比如算出一堆图片里面被转发最多的图片就至少需要两步:第一步算出每个图片的转发数量。第二步找出转发最多的前10个图片。(如果要把这个过程做得更具有扩展性那么可能需要更多的步骤)。
Bolts可以发射多条消息流, 使用OutputFieldsDeclarer.declareStream定义stream,使用OutputCollector.emit来选择要发射的stream。
Bolts的主要方法是execute, 它以一个tuple作为输入,bolts使用OutputCollector来发射tuple,bolts必须要为它处理的每一个tuple调用OutputCollector的ack方法,以通知Storm这个tuple被处理完成了,从而通知这个tuple的发射者spouts。 一般的流程是: bolts处理一个输入tuple, 发射0个或者多个tuple, 然后调用ack通知storm自己已经处理过这个tuple了。storm提供了一个IBasicBolt会自动调用ack。
五、实验步骤
1、导入依赖jar包
我们首先在Eclipse中创建一个StormTest项目,然后在项目中创建一个lib包,然后我们利用xftp登录到master虚拟机上,进入我们所需jar包的目录中:
cd /usr/cstor/storm/lib
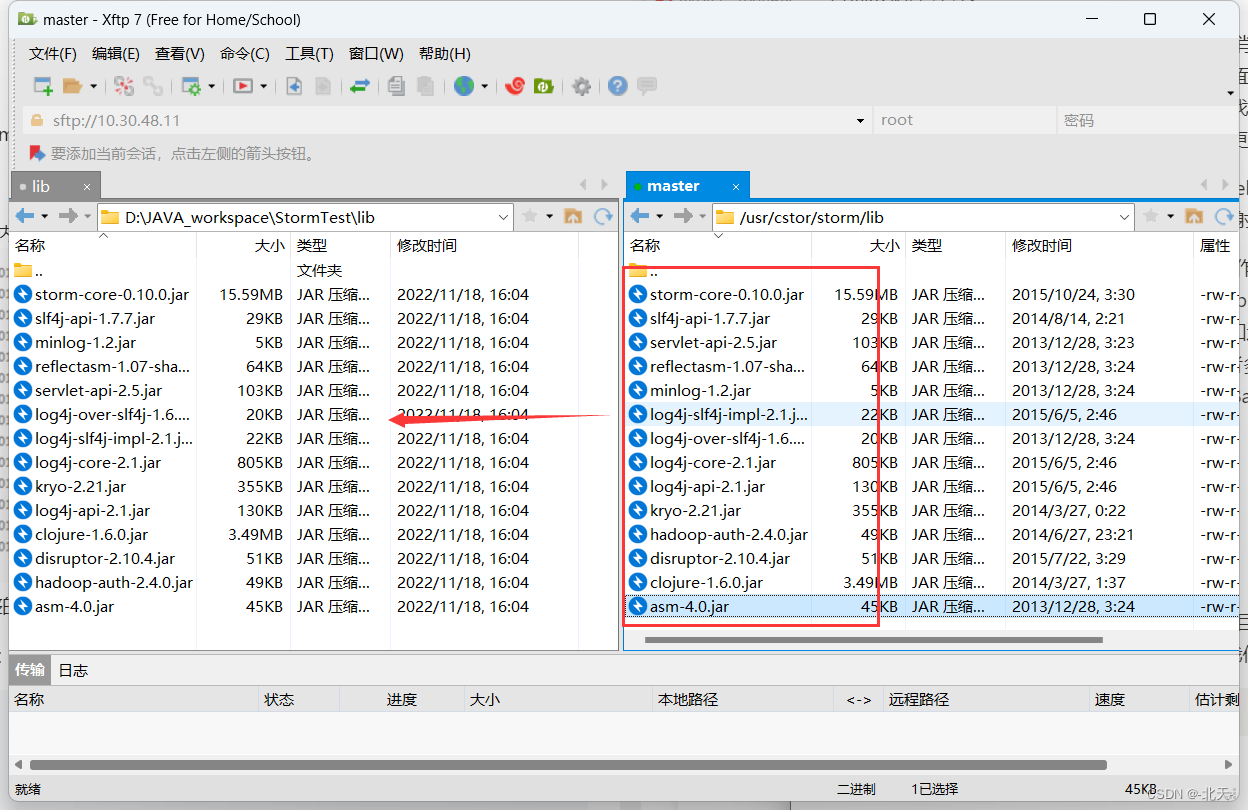
将其全部的jar包导入到本地项目的lib包内。
然后再在Eclipse中对每个jar执行如下操作进行添加配置:
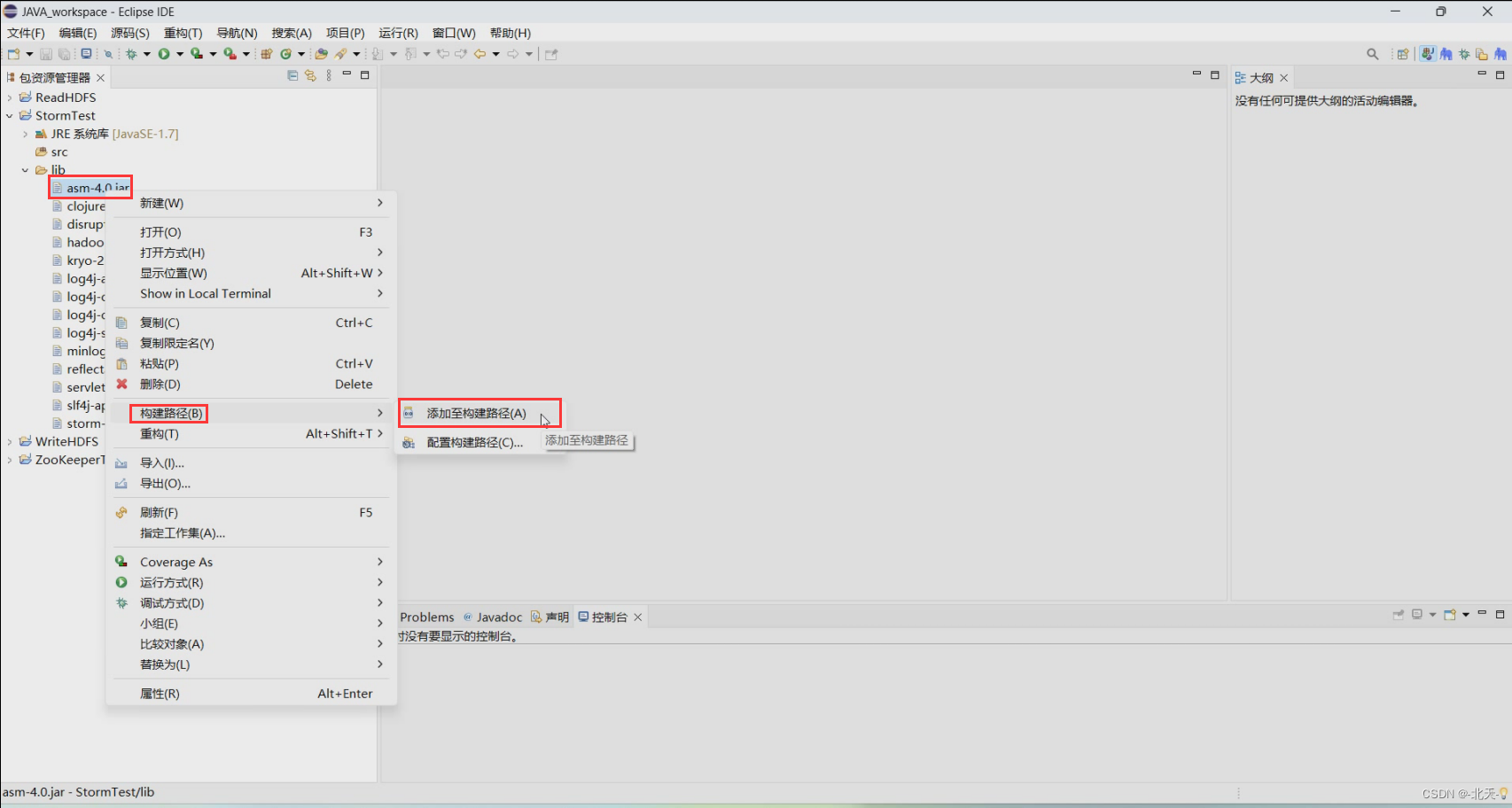
出现这样即可:
2、编写代码
然后我们在项目的src中首先创建一个cproc.word包。
然后我们再在包内创建三个java类并填入对应代码,用于实现一个完整的Topology。
Spout随机发送单词,代码实现:
package cproc.word;import java.util.Map;
import java.util.Random;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;public class WordReaderSpout extends BaseRichSpout {private SpoutOutputCollector collector;@Overridepublic void open(Map conf, TopologyContext context, SpoutOutputCollector collector){this.collector = collector;}@Overridepublic void nextTuple() {//这个方法会不断被调用,为了降低它对CPU的消耗,让它sleep一下Utils.sleep(1000);final String[] words = new String[] {"nathan", "mike", "jackson", "golda", "bertels"};Random rand = new Random();String word = words[rand.nextInt(words.length)];collector.emit(new Values(word));}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {declarer.declare(new Fields("word"));}
}
Bolt单词计数,并每隔一秒打印一次,代码实现:
package cproc.word;import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;public class WordCounterBolt extends BaseBasicBolt {private static final long serialVersionUID = 5683648523524179434L;private HashMap counters = new HashMap();private volatile boolean edit = false;@Overridepublic void prepare(Map stormConf, TopologyContext context) {//定义一个线程1秒钟打印一次统计的信息new Thread(new Runnable() {public void run() {while (true) {if (edit) {for (Entry entry : counters.entrySet()){System.out.println(entry.getKey() + " : " + entry.getValue());}edit = false;}try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}}).start();}@Overridepublic void execute(Tuple input, BasicOutputCollector collector) {String str = input.getString(0);if (!counters.containsKey(str)) {counters.put(str, 1);} else {Integer c = counters.get(str) + 1;counters.put(str, c);}edit = true;}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {}
}
构建Topology并提交到集群主函数,代码实现:
package cproc.word;import backtype.storm.Config;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.AuthorizationException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.topology.TopologyBuilder;public class WordCountTopo {public static void main(String[] args) throws Exception{//构建TopologyTopologyBuilder builder = new TopologyBuilder();builder.setSpout("word-reader", new WordReaderSpout());builder.setBolt("word-counter", new WordCounterBolt()).shuffleGrouping("word-reader");Config conf = new Config();//集群方式提交StormSubmitter.submitTopologyWithProgressBar("wordCount", conf,builder.createTopology());}
}
3、打包上传并运行
我们将Storm代码打成wordCount-Storm.jar(打包的时候不要包含storm中的jar,不然会报错的,将无法运行,即:wordCount-Storm.jar中只包含上面三个类的代码)上传到主节点。
这里需要注意的是我们不勾选上图框选的选项,这样就不会打包项目中的jar包。
然后我们打开xftp软件,将我们打包好的jar上传到master虚拟机的/usr/cstor/storm/bin目录下并在主节点进入Storm安装目录的bin下面用以下命令提交任务:
cd /usr/cstor/storm/bin/
./storm jar wordCount-Storm.jar cproc.word.WordCountTopo wordCount
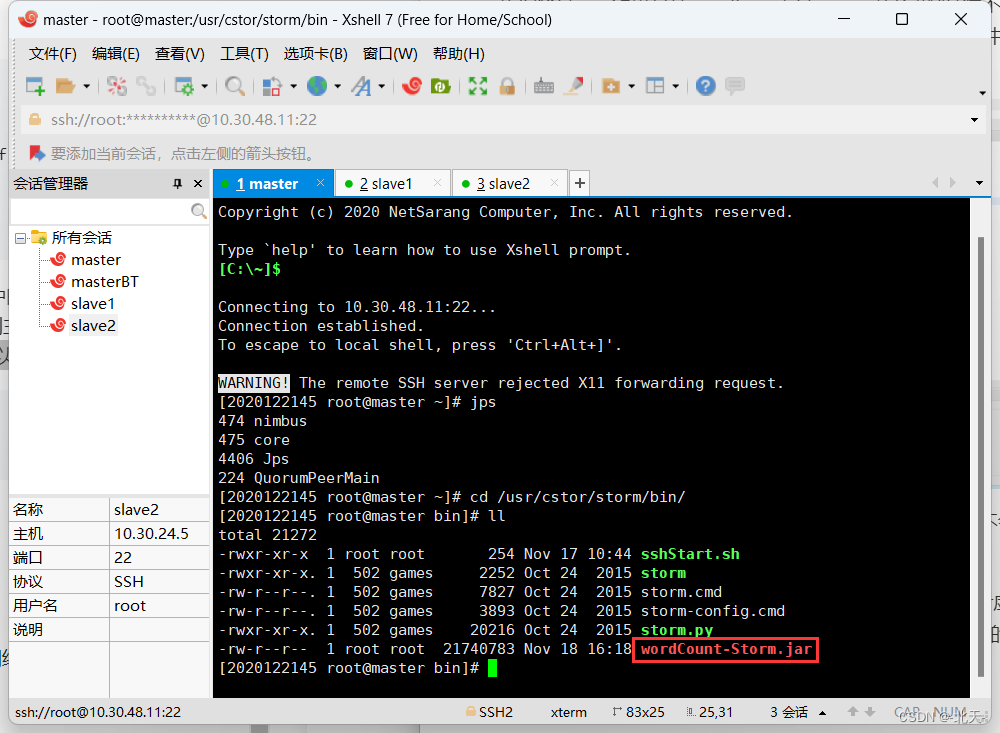
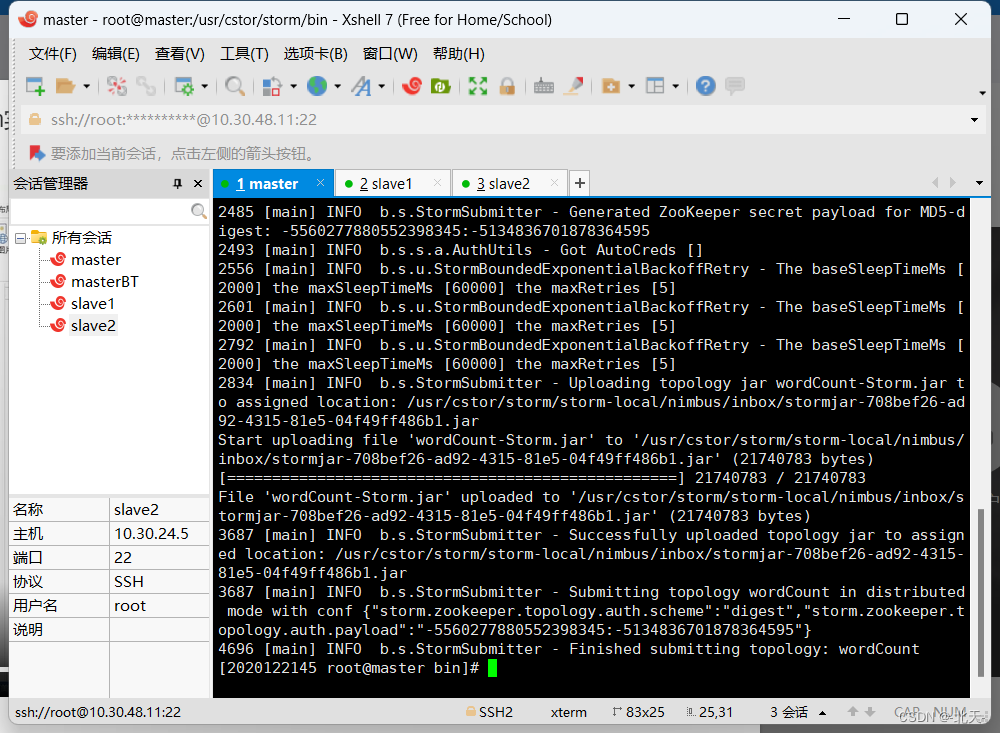
出现如下情况就代表我们已经运行成功了。
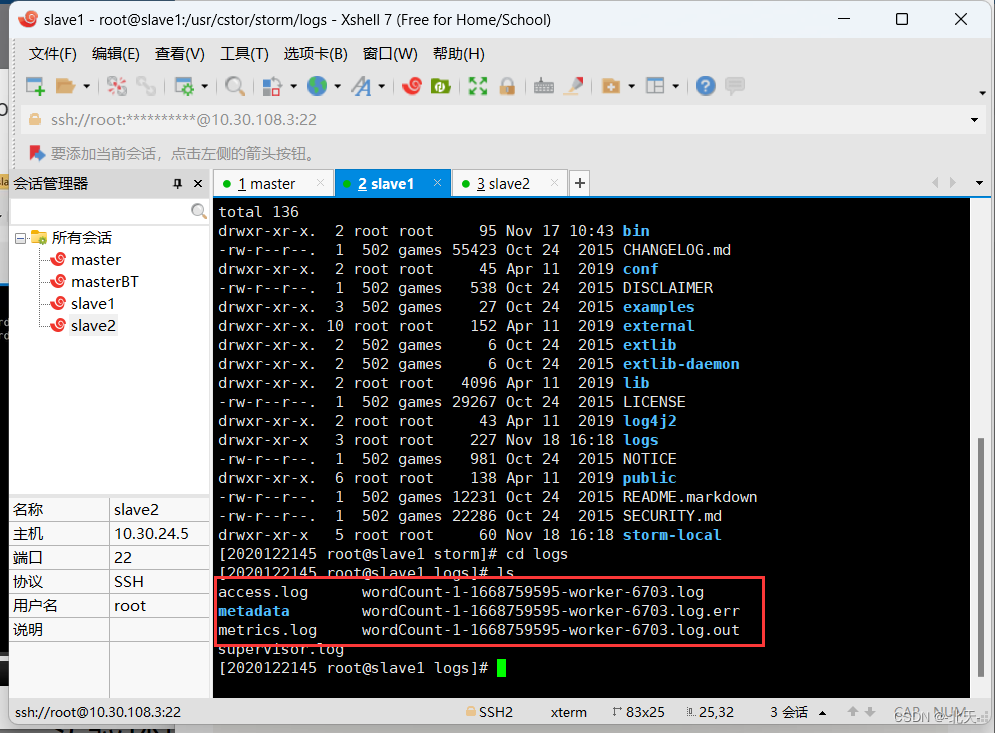
然后我们来通过查看Storm的日志文件来查看我们的运行结果,我们需要进入slave1的下的storm的logs目录中找到有关wordcount的文件:
cd /usr/cstor/storm/logs/
ls
然后我们使用如下命令查看运行结果:
cat wordCount-1-1668759595-worker-6703.log
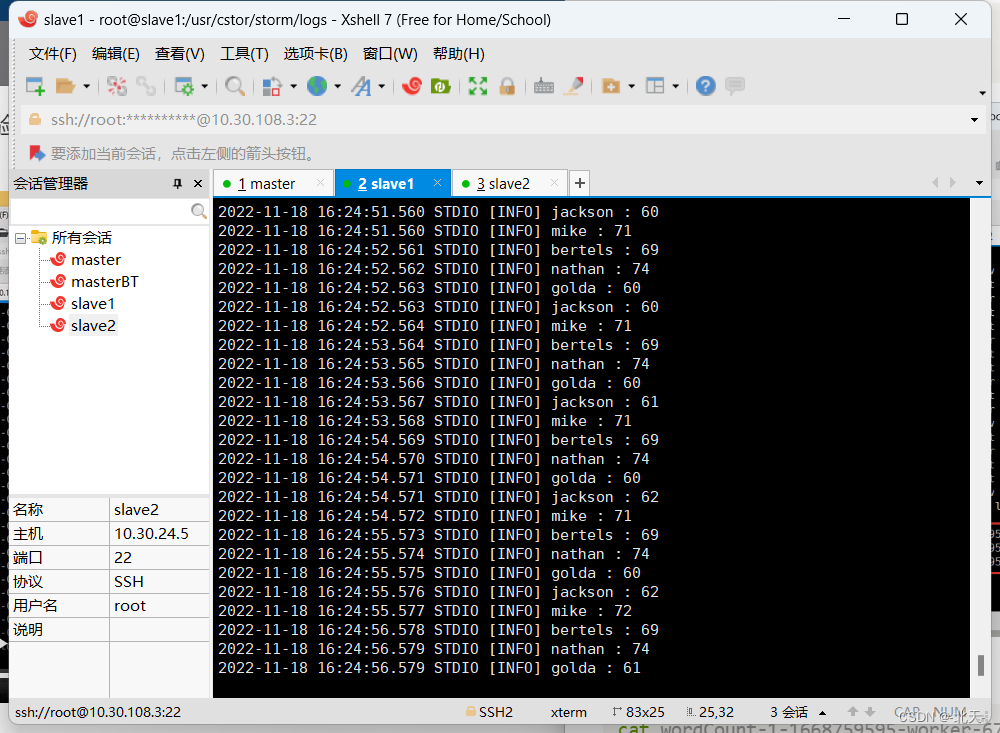
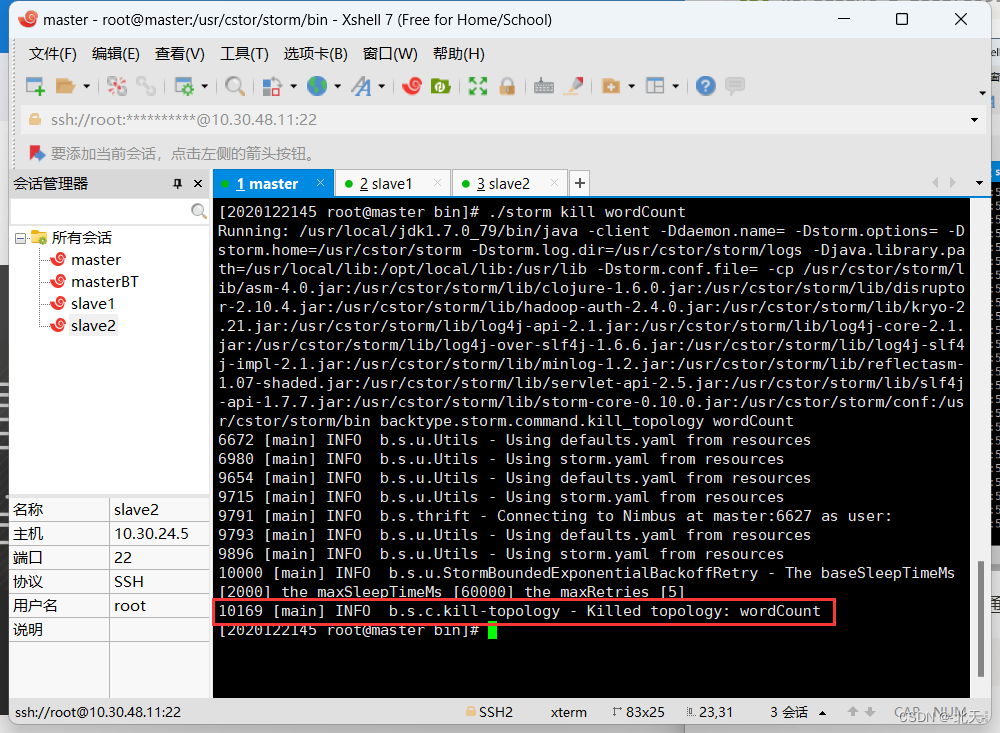
然后我们可以在master上通过如下命令来结束我们的任务:
./storm kill wordCount
六、最后我想说
本期的Storm实验到这里就结束了,学校大数据平台上面的基础实验还剩下几个没有更新,后续我会慢慢全部更新的。
上一篇:基于分组码的消息验证码的程序实现
下一篇:Java接口