
多线程高并发笔记
一、基础知识
1. 线程打断的三种方法
- interrupt()
打断某个线程(其实只是设置一个标志位) - isInterrupted()
查询某线程是否被打断过(查询是否设置了标志位) - static interrupted()
查询当前线程是否被打断过,并重置打断标志(静态方法,重置标志位)
当线程 sleep、wait 或者 join 时,使用 interrupt() 会抛出 InterruptedException 异常
2. 结束线程
使用 volatile
这种方法可以在特定环境下使用,因为无法控制线程结束的时间。另外,如果在 while 循环中有 sleep 或者 wait 方法,线程会阻塞。
private static volatile boolean r = true;Thread t = new Thread(()->{long i = 0L;while(r){i++}
});t.start();
r = false;
使用 interrupt()
这种方式比 volatile 更优雅一点,在 sleep 或者 volatile 中处理好 InterruptException 异常就可以忽略阻塞问题。但,同样无法精确控制线程结束时间
Thread t = new Thread(() ->{while(!Thread.interrupted()){}
})
t.start();
t.interrupt();
二、并发编程三大特性
1. 可见性
使用 volatile 保障线程可见性,
缓存
缓存有三级,一级二级缓存在寄存器里,三级缓存在内存中,读取数据的时候,先在一级缓存中查找,没有的话再去二级缓存。二级缓存没有的话去三级缓存,三级缓存是缓存行,有64个字节。
缓存之间有缓存一致性协议
volatile 与缓存行没有任何关系
缓存行 64 个字节,是工业实践出的结果
2. 有序性
as-if-serial
操作系统中,在不影响 单线程 最终一致性的情况下,语句可能不会按顺序执行
不要在构造方法里面调用 start() 方法
happends-before原则,JVM 规定重排序必须遵守的原则
使用内存屏障阻止乱序执行
内存屏障是特殊指令:看到这种指令,前面的必须执行完,后面的才能执行
Intel:Ifence 、sfence 、mfence (这三个是CPU特有指令)
JVM的内存屏障
所有实现 JVM 规范的虚拟机,必须实现四个屏障:
LoadLoad 、 LoadStore 、 StoreLoad 、StoreStore
(Load:读;Store:写)
LoadLoad屏障:
对于这样的语句Load1; LoadLoad; Load2,
在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障:
对于这样的语句Store1; StoreStore; Store2,
在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
LoadStore屏障:
对于这样的语句Load1; LoadStore; Store2,
在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障:
对于这样的语句Store1; StoreLoad; Load2,
在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
volatile 在 JVM 层面的实现细节
volatile 通过内存屏障实现有序性,通过缓存一致性协议保证可见性

在 hotspot 中,底层通过 lock 指令实现
LOCK 用于在多处理器中执行指令时对共享内存的独占使用。
它的作用是能够将当前处理器对应缓存的内容刷新到内存,并使其他处理器对应的缓存失效。
另外还提供了有序的指令无法越过这个内存屏障的作用。
inline void OrderAccess::fence() {if (os::is_MP()) {// always use locked addl since mfence is sometimes expensive
#ifdef AMD64__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif}
}
DCL 需不需要加 volatile?
需要,new 一个对象有三步,一、开辟内存空间给属性赋初始值,二、给属性赋上真正的值,三、建立连接。为了防止指令重排序,把没有初始化的对象放入程序中。
3. 原子性
基本概念
race condition => 竞争条件 , 指的是多个线程访问共享数据的时候产生竞争
数据的不一致(unconsistency),并发访问之下产生的不期望出现的结果
如何保障数据一致呢?–> 线程同步(线程执行的顺序安排好),
monitor (管程) —> 锁
critical section -> 临界区(锁定一段代码不允许被打断)
如果临界区执行时间长,语句多,叫做 锁的粒度比较粗,反之,就是锁的粒度比较细
保障原子性
-
悲观的认为这个操作会被别的线程打断(悲观锁) ------> synchronized
-
乐观的认为这个做不会被别的线程打断(乐观锁 自旋锁 无锁) ------> cas操作
CAS = Compare And Set/Swap/Exchange
我们平时所说的"上锁",一般指的是悲观锁
CAS
CAS的ABA问题解决方案 - Version
CAS操作本身的原子性保障 :
在汇编指令层级,有一个 lock cmpxchg 指令。也就是说,操作系统本身就支持 CAS 。为了保障原子性,需要配合 lock 指令。lock指令在执行的时候视情况采用缓存锁或者总线锁。也就是说,CAS 操作不会被打断。
lock 指令只有在多核的时候才用
总线锁:两颗CPU访问内存,总线锁把总线锁住,只允许一颗CPU访问内存
缓存锁:锁住缓存行
乐观锁和悲观锁的效率
悲观锁:临界区执行时间较长,等的线程多,悲观锁是与配合的,等待的过程中不消耗系统资源
乐观锁(自旋锁):时间短,线程少。等待的过程中为了维持线程的活性和线程切换会消耗系统资源。
synchronized
synchronized 可以保证可见性 ,但不保证有序性
synchronized 解锁后会对内存的状态和本地缓存进行刷新对比,以此保证可见性
内核态:执行在内核空间中,可以访问所有操作指令
用户态:只能访问用户能访问的指令
比如想把硬盘干掉,用户没有权限向硬盘直接发送指令,必须向操作系统申请,操作系统再向硬盘发送指令
在 JDK 早期,synchronized 叫重量级锁,因为 JVM 处于用户态,锁需要向操作系统申请,由用户态到内核态转化,申请到锁再由内核态转换为用户态。
内存布局:
一个对象在 hotspot 中,前8个字节叫做 markword ,接下来4个字节叫类型指针,通过这个指针可以找到对象的 class 类,之后是成员变量。
hotspot 中要求对象 8 字节对齐,字节数必须是 8 的整数倍。
以 T.class 为例,里面有一个 long 属性,它的内存布局如下:
锁的信息就存在 markword 中,详细信息如下
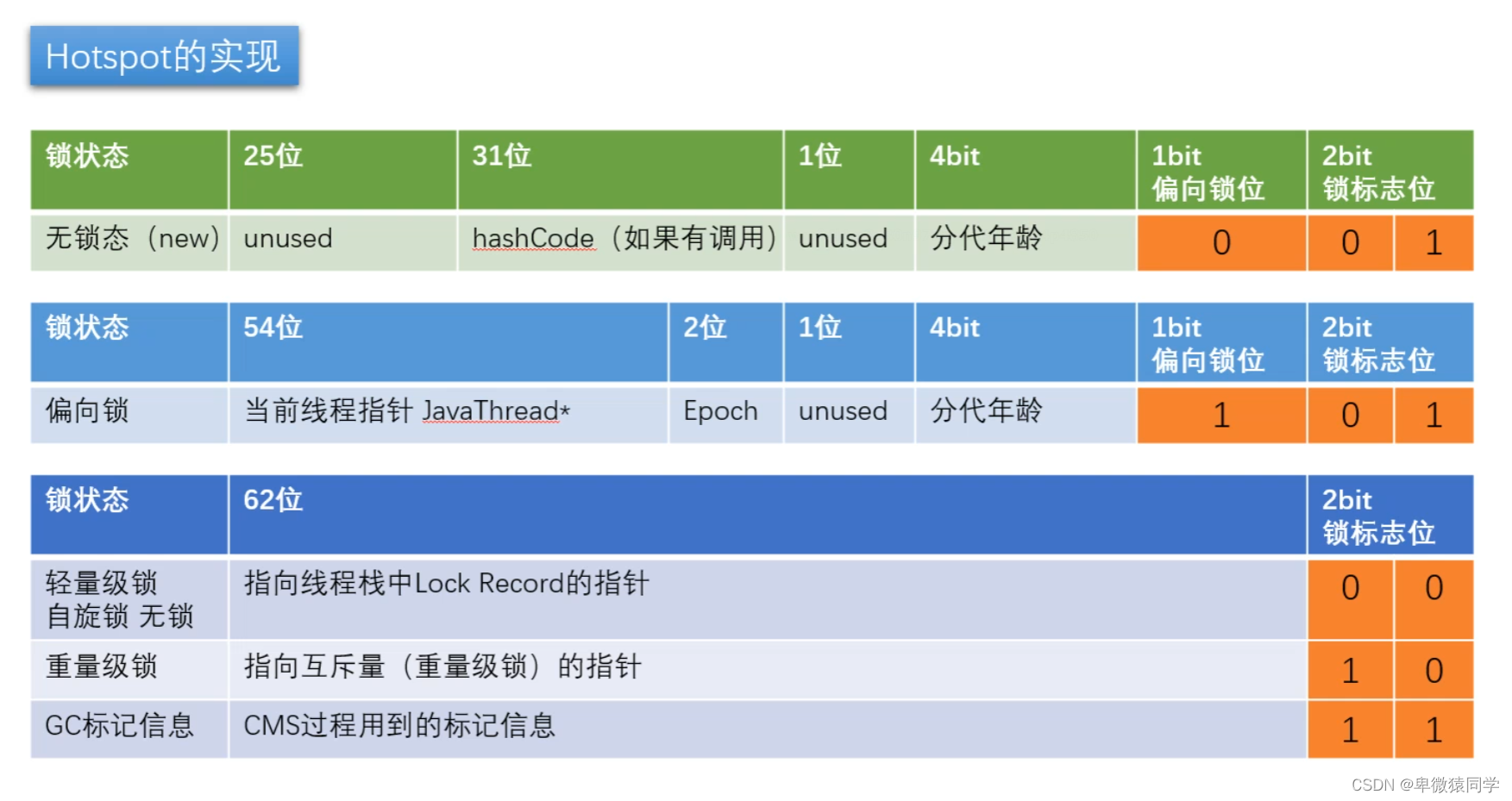
锁的信息通过锁标志位判断,01 有两种状态,再通过前一位的偏向锁位判断
锁升级
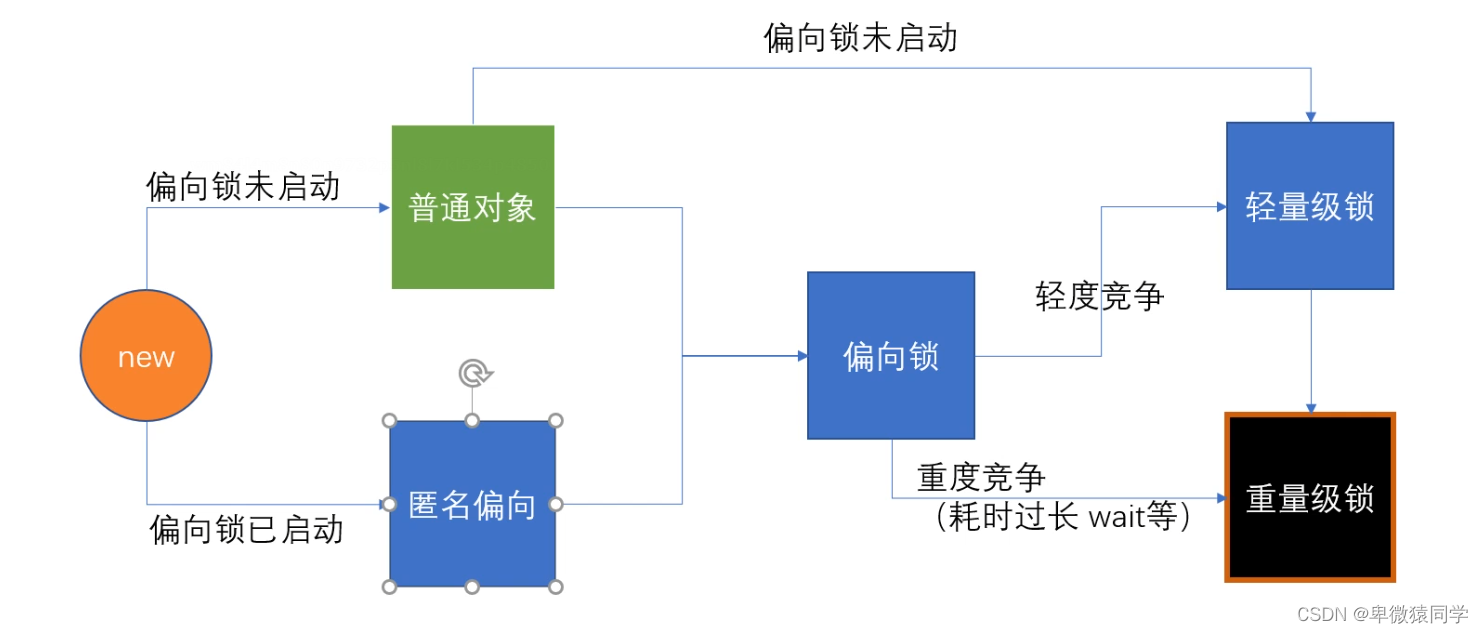
偏向锁 、自旋锁 ,都是用户空间完成,不需要向操作系统申请
重量级锁是需要向内核申请的
自旋锁什么时候升级为重量级锁?
1.6之前,线程超过10次自旋或者自旋线程超过CPU核数一半
1.6之后,JVM 自己控制(加入自适应自旋 Adapative Self Spinning)
偏向锁是否一定比自旋锁效率高?
不一定,在明确知道会有多线程竞争的情况下,偏向锁肯定会涉及锁撤销,这时候直接使用自旋锁
JVM 启动过程,会有很多线程竞争,所以默认情况启动时不打开偏向锁,过一段时间再打开,默认4秒
锁重入
synchronized 是可重入锁,重入次数必须记录,因为要解锁几次必须对应
偏向锁 、 自旋锁 —> 线程栈 ----> LR +1
三、AtomicXXX
1. AtomicInteger
AtomicInteger 提供了无所得CAS操作,保证原子性
AtomicInteger count = new AtomicInteger(0);
count.incrementAndGet(); // 相当于count++,不需要加锁
四、JUC 同步锁
公平锁:线程抢锁先排队
非公平锁:线程到了就插队抢
1. ReentrantLock 可重入锁
ReentrantLock 部分场合可以替换 Synchronized,Synchronized 是自动解锁,ReentrantLock 是需要手动解锁的。
可以是公平锁
ReentrantLock 底层是 CAS
Lock lock = new ReentrantLock();
try{lock.lock(); // synchronized(this)
}finally{lock.unlock; // 解锁
}
public class T02_ReentrantLock2 {Lock lock = new ReentrantLock();void m1() {try {lock.lock(); //synchronized(this)for (int i = 0; i < 10; i++) {TimeUnit.SECONDS.sleep(1);System.out.println(i);}} catch (InterruptedException e) {e.printStackTrace();} finally {lock.unlock();}}void m2() {try {lock.lock();System.out.println("m2 ...");} finally {lock.unlock();}}public static void main(String[] args) {T02_ReentrantLock2 rl = new T02_ReentrantLock2();new Thread(rl::m1).start();try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}new Thread(rl::m2).start();}
}tryLock() 尝试上锁
- 使用 tryLock 进行尝试锁定,不管锁定与否,方法都将继续执行。
- 可以根据 tryLock 的返回值来判定是否锁定
- 也可以指定 tryLock 的时间,由于 tryLock(time) 抛出异常,所以要注意 unlock
boolean locked = false;
try{locked = lock.tryLock(5,TimeUnit.SECONDS);
}catch(InterruptedException e){e.printStackTrace();
}finally{if(locked) lock.unlock();
}
lockInterruptibly()
可以对 interrupt() 方法做出响应,也就是可以响应被打断
new ReentrantLock(true) 公平锁
谁等在前面谁先执行,但是不完全公平。公平锁是指后来的线程会先检查等待队列中是否有值,有就进行排队。非公平锁是不检查等待队列,直接争抢。
private static ReentrantLock lock = new ReentrantLock(true);
2. CountDownLatch 门栓
CountDownLatch的作用很简单,就是一个或者一组线程在开始执行操作之前,必须要等到其他线程执行完才可以。
latch.await(),它的意思是说给我看住门,给我插住不要动。每个线程执行到latch.await()的时候这个门栓就在这里等着
CountDown是在原来的基础上减1,一直到这个数字变成0的时候门栓就会被打开,这就是它的概念,它是用来等着线程结束的。
public class T06_TestCountDownLatch {public static void main(String[] args) {//usingJoin();usingCountDownLatch();}private static void usingCountDownLatch() {Thread[] threads = new Thread[100];CountDownLatch latch = new CountDownLatch(threads.length);for(int i=0; ithreads[i] = new Thread(()->{int result = 0;for(int j=0; j<10000; j++) result += j;latch.countDown();});}for (int i = 0; i < threads.length; i++) {threads[i].start();}try {latch.await();} catch (InterruptedException e) {e.printStackTrace();}System.out.println("end latch");}
/*private static void usingJoin() {Thread[] threads = new Thread[100];for(int i=0; i{int result = 0;for(int j=0; j<10000; j++) result += j;});}for (int i = 0; i < threads.length; i++) {threads[i].start();}for (int i = 0; i < threads.length; i++) {try {threads[i].join();} catch (InterruptedException e) {e.printStackTrace();}}System.out.println("end join");}
*/
}
3. CyclicBarrier 栅栏
Cyclic意为循环,也就是说这个计数器可以反复使用。比如,我们将计数器设置为10,那么凑齐第一批10个线程后,计数器就会归零,接着凑齐下一批10个线程,这就是循环栅栏内的含义。
CyclicBarrier barrier = new CyclicBarrier(20,{@Overridepublic void run(){ System.out.println("满人,发车");}
});
for(int i = 0; i < 100 ; i++){new Thread(() -> {try{barrier.await();}catch(InterruptedException e){}catch(BrokenBarrierException e){}}).start();
}
4. ReadWriteLock 读写锁
共享锁(读锁)
排他锁(写锁)
public class T10_TestReadWriteLock {static Lock lock = new ReentrantLock();private static int value;static ReadWriteLock readWriteLock = new ReentrantReadWriteLock();static Lock readLock = readWriteLock.readLock();static Lock writeLock = readWriteLock.writeLock();public static void read(Lock lock) {try {lock.lock();Thread.sleep(1000);System.out.println("read over!");//模拟读取操作} catch (InterruptedException e) {e.printStackTrace();} finally {lock.unlock();}}public static void write(Lock lock, int v) {try {lock.lock();Thread.sleep(1000);value = v;System.out.println("write over!");//模拟写操作} catch (InterruptedException e) {e.printStackTrace();} finally {lock.unlock();}}public static void main(String[] args) {//Runnable readR = ()-> read(lock);Runnable readR = ()-> read(readLock);//Runnable writeR = ()->write(lock, new Random().nextInt());Runnable writeR = ()->write(writeLock, new Random().nextInt());for(int i=0; i<18; i++) new Thread(readR).start();for(int i=0; i<2; i++) new Thread(writeR).start();}
}
5. Phsaer 分阶段执行
多用在计算机模拟达尔文进化论的遗传算法。
arriveAndAwaitAdvance() 拦截住
arriveAndDeregister() 放行
public class T09_TestPhaser2 {static Random r = new Random();static MarriagePhaser phaser = new MarriagePhaser();static void milliSleep(int milli) {try {TimeUnit.MILLISECONDS.sleep(milli);} catch (InterruptedException e) {e.printStackTrace();}}public static void main(String[] args) {phaser.bulkRegister(7);for(int i=0; i<5; i++) {new Thread(new Person("p" + i)).start();}new Thread(new Person("新郎")).start();new Thread(new Person("新娘")).start();}static class MarriagePhaser extends Phaser {@Overrideprotected boolean onAdvance(int phase, int registeredParties) {switch (phase) {case 0:System.out.println("所有人到齐了!" + registeredParties);System.out.println();return false;case 1:System.out.println("所有人吃完了!" + registeredParties);System.out.println();return false;case 2:System.out.println("所有人离开了!" + registeredParties);System.out.println();return false;case 3:System.out.println("婚礼结束!新郎新娘抱抱!" + registeredParties);return true;default:return true;}}}static class Person implements Runnable {String name;public Person(String name) {this.name = name;}public void arrive() {milliSleep(r.nextInt(1000));System.out.printf("%s 到达现场!\n", name);phaser.arriveAndAwaitAdvance();}public void eat() {milliSleep(r.nextInt(1000));System.out.printf("%s 吃完!\n", name);phaser.arriveAndAwaitAdvance();}public void leave() {milliSleep(r.nextInt(1000));System.out.printf("%s 离开!\n", name);phaser.arriveAndAwaitAdvance();}private void hug() {if(name.equals("新郎") || name.equals("新娘")) {milliSleep(r.nextInt(1000));System.out.printf("%s 洞房!\n", name);phaser.arriveAndAwaitAdvance();} else {phaser.arriveAndDeregister();//phaser.register()}}@Overridepublic void run() {arrive();eat();leave();hug();}}
}
6. Semaphroe 信号
限流,限制最多有多少个线程在同时运行
public class T11_TestSemaphore {public static void main(String[] args) {//默认不公平,true为公平//Semaphore s = new Semaphore(2, true);//允许一个线程同时执行Semaphore s = new Semaphore(1);new Thread(()->{try {s.acquire(); // 申请锁System.out.println("T1 running...");Thread.sleep(200);System.out.println("T1 running...");} catch (InterruptedException e) {e.printStackTrace();} finally {s.release();}}).start();new Thread(()->{try {s.acquire();System.out.println("T2 running...");Thread.sleep(200);System.out.println("T2 running...");} catch (InterruptedException e) {e.printStackTrace();}finally {s.release();}}).start();}
}
7. Exchanger 交换器
只用于两个线程之间交换
exchange() 为阻塞方法,线程一执行到exchange()时阻塞,将数据放入Exchanger,线程二执行到 exchange() 时阻塞,将数据放入 Exchanger,两个数据交换后两个线程继续执行。如果只有一个线程,那么这个线程就会一直阻塞。
public class T12_TestExchanger {static Exchanger exchanger = new Exchanger<>();public static void main(String[] args) {new Thread(()->{String s = "T1";try {s = exchanger.exchange(s);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread().getName() + " " + s);}, "t1").start();new Thread(()->{String s = "T2";try {s = exchanger.exchange(s);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread().getName() + " " + s);}, "t2").start();}
}
T1 t2
T2 t1
8. LockSupport
1. LockSupport 不需要 synchornized 加锁 就可以实现线程的阻塞和唤醒
2. LockSupport.unpartk()可以先于LockSupport.park()执行,并且线程不会阻塞
3. 如果一个线程处于等待状态,连续调用了两次park()方法,就会使该线程永远无法被唤醒
public class T13_TestLockSupport {public static void main(String[] args) {Thread t = new Thread(()->{for (int i = 0; i < 10; i++) {System.out.println(i);if(i == 5) {LockSupport.park(); //当前线程停止,阻塞}try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}}});t.start();LockSupport.unpark(t);/*try {TimeUnit.SECONDS.sleep(8);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("after 8 senconds!");LockSupport.unpark(t);*/}
}
9. 练习题
例题1:
实现一个容器,提供两个方法add、size,写两个线程:
线程1,添加10个元素到容器中
线程2,实时监控元素个数,当个数到5个时,线程2给出提示并结束
解法一(失败) :
public class T03_NotifyHoldingLock { //wait notify//添加volatile,使t2能够得到通知volatile List lists = new ArrayList();public void add(Object o) {lists.add(o);}public int size() {return lists.size();}public static void main(String[] args) {T03_NotifyHoldingLock c = new T03_NotifyHoldingLock();final Object lock = new Object();//需要注意先启动t2再启动t1new Thread(() -> {synchronized(lock) {System.out.println("t2 启动");if(c.size() != 5) {try {lock.wait();} catch (InterruptedException e) {e.printStackTrace();}}System.out.println("t2 结束");}}, "t2").start();try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e1) {e1.printStackTrace();}new Thread(() -> {System.out.println("t1 启动");synchronized(lock) {for(int i=0; i<10; i++) {c.add(new Object());System.out.println("add " + i);if(c.size() == 5) {lock.notify();}try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}}}}, "t1").start();}
}
失败原因:notify()或者notifyAll()调用时并不会真正释放对象锁, 必须等到synchronized方法或者语法块执行完才真正释放锁.
解法二(成功,由一改造):
首先t2线程执行,判断到list集合里的对象数量没有5个,t2线程被阻塞了,接下来t1线程开始执行,当循环添加了5个对象后,唤醒了t2线程,重点在于notify()方法是不会释放锁的,所以在notify()以后,又紧接着调用了wait()方法阻塞了t1线程,实现了t2线程的实时监控,t2线程执行结束,打印出相应提示,最后调用notify()方法唤醒t1线程,让t1线程完成执行。
public class T03_NotifyHoldingLock { //wait notify//添加volatile,使t2能够得到通知volatile List lists = new ArrayList();public void add(Object o) {lists.add(o);}public int size() {return lists.size();}public static void main(String[] args) {T03_NotifyHoldingLock c = new T03_NotifyHoldingLock();final Object lock = new Object();//需要注意先启动t2再启动t1new Thread(() -> {synchronized(lock) {System.out.println("t2 启动");if(c.size() != 5) {try {lock.wait();} catch (InterruptedException e) {e.printStackTrace();}}System.out.println("t2 结束");}//通知t1继续执行lock.notify()。}, "t2").start();try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e1) {e1.printStackTrace();}new Thread(() -> {System.out.println("t1 启动");synchronized(lock) {for(int i=0; i<10; i++) {c.add(new Object());System.out.println("add " + i);if(c.size() == 5) {lock.notify();//释放锁,让t2得以执行try{lock.wait();}catch(InterruptedException e){e.printStackTrace();}}try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}}}}, "t1").start();}
}
解法三(门栓,失败):
public class T05_CountDownLatch {//添加volatile,使t2能够得到通知volatile List lists = new ArrayList();public void add(Object o) {lists.add(o);}public int size() {return lists.size();}public static void main(String[] args) {T05_CountDownLatch c = new T05_CountDownLatch();//需要注意先启动t2再启动t1CountDownLatch latch = new CountDownLatch(1);new Thread(() -> {System.out.println("t2 启动");if (c.size() != 5) {try {latch.await();} catch (InterruptedException e) {e.printStackTrace();}}System.out.println("t2 结束");}, "t2").start();try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e1) {e1.printStackTrace();}new Thread(() -> {System.out.println("t1 启动");for (int i = 0; i < 10; i++) {c.add(new Object());System.out.println("add " + i);if (c.size() == 5) {// 暂停t1线程latch.countDown();}/*try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}*/}}, "t1").start();}
}
失败原因:当我们把休眠1秒这段带代码,从t1线程里注释掉以后,会发现出错了,原因是在t1线程里,对象增加到5个时,t2线程的门闩确实被打开了,但是t1线程马上又会接着执行,之前是t1会休眠1秒,给t2线程执行时间,但当注释掉休眠1秒这段带代码,t2就没有机会去实时监控了,所以这种方案来使用门闩是不可行的。
解法四(门栓,成功):
在t1线程打开t2线程门闩的时候,让他再给自己加一个门闩就可以了。
public class T05_CountDownLatch {//添加volatile,使t2能够得到通知volatile List lists = new ArrayList();public void add(Object o) {lists.add(o);}public int size() {return lists.size();}public static void main(String[] args) {T05_CountDownLatch c = new T05_CountDownLatch();CountDownLatch latch = new CountDownLatch(1);//需要注意先启动t2再启动t1new Thread(() -> {System.out.println("t2 启动");if (c.size() != 5) {try {latch.await();} catch (InterruptedException e) {e.printStackTrace();}}System.out.println("t2 结束");}, "t2").start();try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e1) {e1.printStackTrace();}new Thread(() -> {System.out.println("t1 启动");for (int i = 0; i < 10; i++) {c.add(new Object());System.out.println("add " + i);if (c.size() == 5) {//打开门闩,让t2得以执行latch.countDown();//给t1上门闩,让t2有机会执行try {latch.await();} catch (InterruptedException e) {e.printStackTrace();}}try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}}}, "t1").start();}
}
解法五(LockSupport,成功):
我们在类的成员变量里定义了静态的线程对象t1和t2,然后在main方法里创建了t1线程和t2线程,t2线程中判断了list集合中对象的数量,然后t2线程阻塞,t1线程开始执行添加对象,对象达到5个时,打开t2线程阻塞t1线程,至此程序结束,运行成功。
public class T07_LockSupport_WithoutSleep {// 添加volatile,使t2能够得到通知volatile List lists = new ArrayList();public void add(Object o) {lists.add(o);}public int size() {return lists.size();}static Thread t1 = null, t2 = null;public static void main(String[] args) {T06_LockSupport c = new T06_LockSupport();CountDownLatch latch = new CountDownLatch(1);t2 = new Thread(() -> {System.out.println("t2 启动");if (c.size() != 5) {LockSupport.park();}System.out.println("t2 结束");LockSupport.unpark(t1);}, "t2");try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e1) {e1.printStackTrace();}t1 = new Thread(() -> {System.out.println("t1 启动");for (int i = 0; i < 10; i++) {c.add(new Object());System.out.println("add " + i);if (c.size() == 5) {LockSupport.unpark(t2);LockSupport.park();}try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}}}, "t1");//需要注意先启动t2再启动t1t2.start();t1.start();}
}
解法六(Semaphore,成功):
创建一个Semaphore对象,设置只能有1一个线程可以运行,首先线程1开始启动,调用acquire()方法限制其他线程运行,在for循环添加了4个对象以后,调用s.release()表示其他线程可以运行,这个时候t1线程启动t2线程,调用join()把CPU的控制权交给t2线程,t2线程打印出提示信息,并继续输出后来的对象添加信息,
public class T08_Semaphore {// 添加volatile,使t2能够得到通知volatile List lists = new ArrayList();public void add(Object o) {lists.add(o);}public int size() {return lists.size();}static Thread t1 = null, t2 = null;public static void main(String[] args) {T08_Semaphore c = new T08_Semaphore();Semaphore s = new Semaphore(1);t1 = new Thread(() -> {try {s.acquire();for (int i = 0; i < 5; i++) {c.add(new Object());System.out.println("add " + i);}s.release();t2.start();t2.join();s.acquire();for (int i = 5; i < 10; i++) {c.add(new Object());System.out.println("add"+i);}s.release();} catch (InterruptedException e) {e.printStackTrace();}}, "t1");t2 = new Thread(() -> {try {s.acquire();System.out.println("t2 结束");s.release();} catch (InterruptedException e) {e.printStackTrace();}}, "t2");t1.start();}
}
例题2:
写一个固定容量同步容器,拥有put和get方法,以及getCount方法,能够支持2个生产者线程以及10个消费者线程的阻塞调用。
生产者生产对象放入容器,容器满了停止。消费者拿取对象,容器空了停止
解法1(有问题):
public class MyContainer1 {final private LinkedList lists = new LinkedList<>();final private int MAX = 10; //最多10个元素private int count = 0;//生产者public synchronized void put(T t) {while(lists.size() == MAX) { //想想为什么用while而不是if?try {this.wait(); //effective java} catch (InterruptedException e) {e.printStackTrace();}}lists.add(t);++count;this.notifyAll(); //֪ͨ通知消费者线程进行消费}//消费者public synchronized T get() {T t = null;while(lists.size() == 0) {try {this.wait();} catch (InterruptedException e) {e.printStackTrace();}}t = lists.removeFirst();count --;this.notifyAll(); //通知生产者线程进行生产return t;}public static void main(String[] args) {MyContainer1 c = new MyContainer1<>();//启动消费者线程for(int i=0; i<10; i++) {new Thread(()->{for(int j=0; j<5; j++) System.out.println(c.get());}, "c" + i).start();}try {TimeUnit.SECONDS.sleep(2);} catch (InterruptedException e) {e.printStackTrace();}//启动生产者线程for(int i=0; i<2; i++) {new Thread(()->{for(int j=0; j<25; j++) c.put(Thread.currentThread().getName() + " " + j);}, "p" + i).start();}}
}
notifyAll 会叫醒所有生产者和消费者线程,如果生产者已经生产满了,下一次有可能还是生产者抢到锁。
解法二:
public class MyContainer2 {final private LinkedList lists = new LinkedList<>();final private int MAX = 10; //最多10个元素private int count = 0;private Lock lock = new ReentrantLock();private Condition producer = lock.newCondition();private Condition consumer = lock.newCondition();public void put(T t) {try {lock.lock();while(lists.size() == MAX) { //想想为什么用while而不是用if?producer.await();}lists.add(t);++count;consumer.signalAll(); //通知消费者线程进行消费} catch (InterruptedException e) {e.printStackTrace();} finally {lock.unlock();}}public T get() {T t = null;try {lock.lock();while(lists.size() == 0) {consumer.await();}t = lists.removeFirst();count --;producer.signalAll(); //通知生产者进行生产} catch (InterruptedException e) {e.printStackTrace();} finally {lock.unlock();}return t;}public static void main(String[] args) {MyContainer2 c = new MyContainer2<>();//启动消费者线程for(int i=0; i<10; i++) {new Thread(()->{for(int j=0; j<5; j++) System.out.println(c.get());}, "c" + i).start();}try {TimeUnit.SECONDS.sleep(2);} catch (InterruptedException e) {e.printStackTrace();}//启动生产者线程for(int i=0; i<2; i++) {new Thread(()->{for(int j=0; j<25; j++) c.put(Thread.currentThread().getName() + " " + j);}, "p" + i).start();}}
}
五、Java的四种引用
其实java有4种引用,4种可分为强、软、弱、虚
1. 强引用
普通引用就是强引用 Object o = new Object();
2. 弱引用
SoftReference
当有一个对象(字节数组)被一个软引用所指向的时候,只有系统内存不够用的时候,才会回收它(字节数组)
举个例子你从内存里边读一个大图片,特别的图片出来,然你用完了之后就没什么用了,你可以放在内存里边缓存在那里,要用的时候直接从内存里边拿,但是由于这个大图片占的空间比较大,如果不用的话,那别人也要用这块空间,那就把它干掉,这个时候就用到了软引用
//软引用非常适合缓存使用
public class T02_SoftReference {public static void main(String[] args) {SoftReference m = new SoftReference<>(new byte[1024*1024*10]);//m = null;System.out.println(m.get());System.gc();try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(m.get());//再分配一个数组,heap将装不下,这时候系统会垃圾回收,先回收一次,如果不够,会 //把软引用干掉byte[] b = new byte[1024*1024*15];System.out.println(m.get());}
}
3. 弱引用
WeakReference
只要遭遇到gc就会回收
public class T03_WeakReference {public static void main(String[] args) {WeakReference m = new WeakReference<>(new M());System.out.println(m.get());System.gc();System.out.println(m.get());ThreadLocal tl = new ThreadLocal<>();tl.set(new M());tl.remove();}
}
这个东西作用就在于,如果有另外一个强引用指向了这个弱引用之后,只要这个强引用消失掉,这个弱引用就应该去被回收,我就不用管了,只要这个强引用消失掉,我就不用管这个弱引用了,这个弱引用也一定是被回收了,这个东西用在什么地方呢?一般用在容器里
4. 虚引用
它就是管理堆外内存的,首先第一点,这个虚引用的构造方法至少都是两个参数的,第二个参数还必须是一个队列,这个虚引用基本没用,是给写JVM(虚拟机)的人用的
public class T04_PhantomReference {private static final List六、并发容器
容器分两大类 Collection、Map 。
Collection又分三大类List、Set、Queue队列
Set:没有重复元素。
Queue:这里面最重要的就是阻塞队列,它实现的初衷就是为了线程池、高并发做准备的。
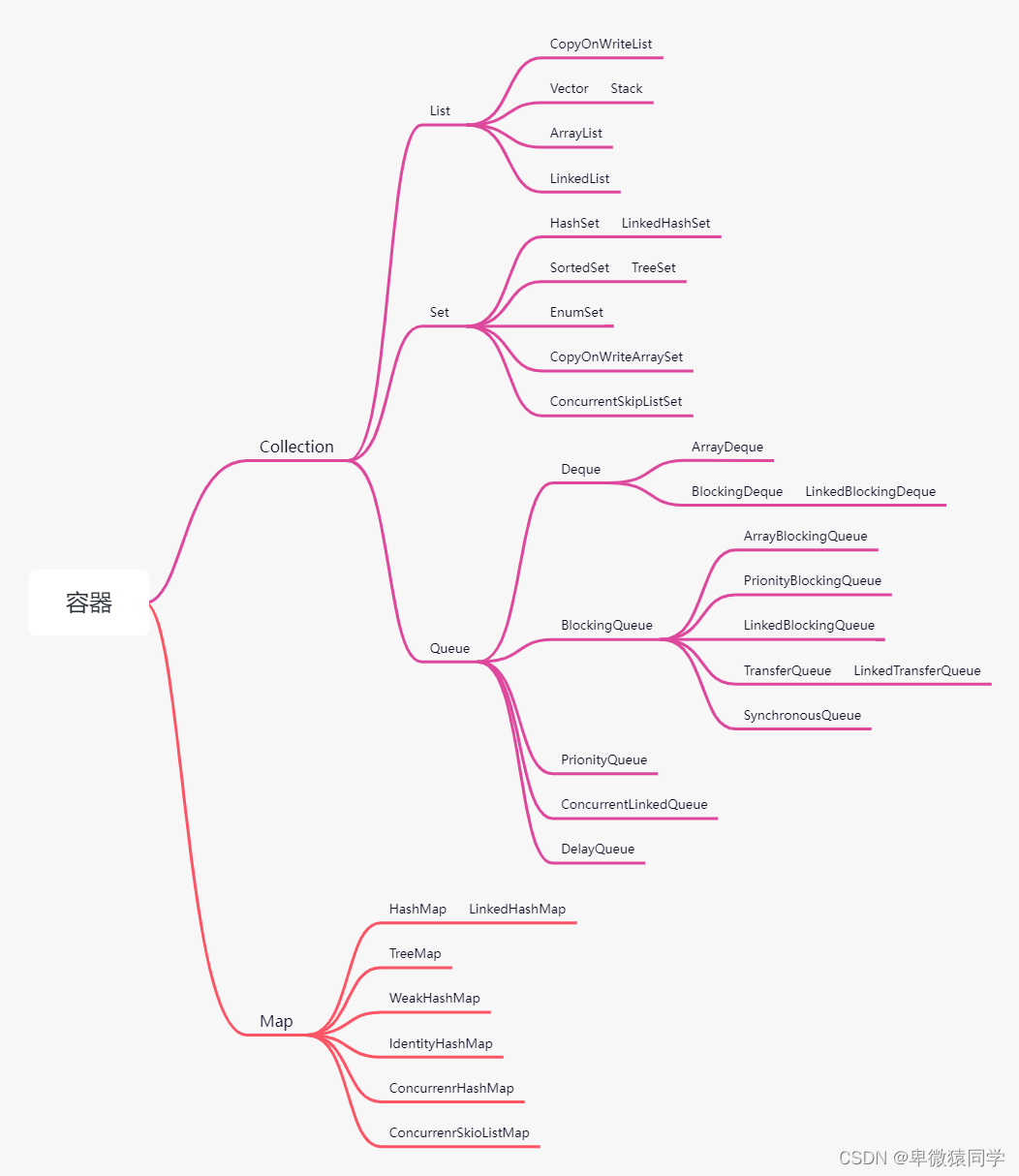
ConcurrentHashMap
ConcurrentHashMap 是多线程里面真正用的,以后我们多线程用的基本就是它
ConcurrentHashMap 提高效率主要提高在读上面,由于它往里插的时候内部又做了各种各样的判断,本来是链表的,到8之后又变成了红黑树,然后里面又做了各种各样的cas的判断,所以他往里插的数据是要更低一些的。HashMap和Hashtable虽然说读的效率会稍微低一些,但是它往里插的时候检查的东西特别的少,就加个锁然后往里一插。所以,关于效率,还是看你实际当中的需求。
ConcurrentSkipListMap
通过跳表来实现的高并发容器并且这个Map是有排序的;
Vector
内部是自带锁的,读它的时候就会看到很多方法二话不说先加上锁(synchronized)在说,所以它一定是线程安全的。
CopyOnWrite
再来说一个在并发的时候经常使用的一个类,这个类叫CopyOnWrite。CopyOnWriteList、CopyOnWriteSet有两个。CopyOnWrite的意思叫写时复制。
用 CopyOnWriteList 读的时候不加锁,写的时候会在原来的基础上拷贝一个,拷贝的时候扩展出一个新元素来,然后把你新添加的这个扔到这个元素扔到最后这个位置上,于此同时把指向老的容器的一个引用指向新的,这个写法就是写时复制。
在读比较多写比较少的情况下使用CopyOnWrite。
BlockingQueue
Blocking阻塞,Queue队列,是阻塞队列。他提供了一系列的方法,我们可以在这些方法的基础之上做到让线程实现自动的阻塞。
offer():添加,返回布尔值
peek():取值,不删除
poll():取值,并删除
offer(E e, long timeout, TimeUnit unit):将给定元素在给定的时间内设置到队列中,如果设置成功返回true, 否则返回false.
put():添加,如果满了的话线程会阻塞住
take():往外取,如果空了的话线程会阻塞住
LinkedBlockingQueue
LinkedBlockingQueue,用链表实现的BlockingQueue,是一个无界队列。就是它可以一直装到你内存满了为止,一直添加。
public class T05_LinkedBlockingQueue {static BlockingQueue strs = new LinkedBlockingQueue<>();static Random r = new Random();public static void main(String[] args) {new Thread(() -> {for (int i = 0; i < 100; i++) {try {strs.put("a" + i); //如果满了,就会等待TimeUnit.MILLISECONDS.sleep(r.nextInt(1000));} catch (InterruptedException e) {e.printStackTrace();}}}, "p1").start();for (int i = 0; i < 5; i++) {new Thread(() -> {for (;;) {try {System.out.println(Thread.currentThread().getName() + " take -" + strs.take()); //如果空了,就会等待} catch (InterruptedException e) {e.printStackTrace();}}}, "c" + i).start();}}
}
ArrayBlockingQueue
ArrayBlockingQueue是有界的,你可以指定它一个固定的值10,它容器就是10,那么当你往里面扔容器的时候,一旦他满了这个put方法就会阻塞住。
然后你可以看看用add方法满了之后他会报异常。offer用返回值来判断到底加没加成功.
public class T06_ArrayBlockingQueue {static BlockingQueue strs = new ArrayBlockingQueue<>(10);static Random r = new Random();public static void main(String[] args) throws InterruptedException {for (int i = 0; i < 10; i++) {strs.put("a" + i);}//strs.put("aaa"); //满了就会等待,程序阻塞//strs.add("aaa");//strs.offer("aaa");strs.offer("aaa", 1, TimeUnit.SECONDS);System.out.println(strs);}
}
DelayQueue
DelayQueue可以实现在时间上的排序,能实现按照在里面等待的时间来进行排序。
他是BlockingQueue的一种也是用于阻塞的队列,这个阻塞队列装任务的时候要求必须实现Delayed接口,Delayed往后拖延推迟,Delayed需要做一个比较compareTo,最后这个队列的实现,这个时间等待越短的就会有优先的得到运行,所以你需要做一个比较 ,这里面他就有一个排序了,这个排序是按时间来排的,所以去做好,哪个时间返回什么样的值,不同的内容比较的时候可以按照时间来排序。
总而言之,你要实现Comparable接口重写 compareTo方法来确定你这个任务之间是怎么排序的。getDelay去拿到你Delay多长时间了。往里头装任务的时候首先拿到当前时间,在当前时间的基础之上指定在多长时间之后这个任务要运行,添加顺序参看代码,但是当我们去拿的时候,一般的队列是先加那个先往外拿那个,先进先出。这个队列是不一样的,按时间进行排序(按紧迫程度进行排序)。DelayQueue就是按照时间进行任务调度。
public class T07_DelayQueue {static BlockingQueue tasks = new DelayQueue<>();static Random r = new Random();static class MyTask implements Delayed {String name;long runningTime;MyTask(String name, long rt) {this.name = name;this.runningTime = rt;}@Overridepublic int compareTo(Delayed o) {if(this.getDelay(TimeUnit.MILLISECONDS) < o.getDelay(TimeUnit.MILLISECONDS))return -1;else if(this.getDelay(TimeUnit.MILLISECONDS) > o.getDelay(TimeUnit.MILLISECONDS)) return 1;else return 0;}@Overridepublic long getDelay(TimeUnit unit) {return unit.convert(runningTime - System.currentTimeMillis(), TimeUnit.MILLISECONDS);}@Overridepublic String toString() {return name + " " + runningTime;}}public static void main(String[] args) throws InterruptedException {long now = System.currentTimeMillis();MyTask t1 = new MyTask("t1", now + 1000);MyTask t2 = new MyTask("t2", now + 2000);MyTask t3 = new MyTask("t3", now + 1500);MyTask t4 = new MyTask("t4", now + 2500);MyTask t5 = new MyTask("t5", now + 500);tasks.put(t1);tasks.put(t2);tasks.put(t3);tasks.put(t4);tasks.put(t5);System.out.println(tasks);for(int i=0; i<5; i++) {System.out.println(tasks.take());}}
}
PriorityQueue
DelayQueue本质上用的是一个PriorityQueue,PriorityQueue是从AbstractQueue继承的。PriorityQueue特点是它内部你往里装的时候并不是按顺序往里装的,而是内部进行了一个排序。按照优先级,最小的优先。它内部实现的结构是一个二叉树,这个二叉树可以认为是堆排序里面的那个最小堆值排在最上面。
public class T07_01_PriorityQueque {public static void main(String[] args) {PriorityQueue q = new PriorityQueue<>();q.add("c");q.add("e");q.add("a");q.add("d");q.add("z");for (int i = 0; i < 5; i++) {System.out.println(q.poll());}}
}
SynchronousQueue
SynchronousQueue容量为0,就是这个东西它不是用来装内容的,SynchronousQueue是专门用来两个线程之间传内容的,给线程下达任务的
SynchronousQueue在线程池里用处特别大,很多的线程取任务,互相之间进行任务的一个调度的时候用的都是它。
看下面代码,有一个线程起来等着take,里面没有值一定是take不到的,然后就等着。然后当put的时候能取出来,take到了之后能打印出来,最后打印这个容器的size一定是0,打印出aaa来这个没问题。那当把线程注释掉,在运行一下程序就会在这阻塞,永远等着。如果add方法直接就报错,原因是满了,这个容器为0,你不可以往里面扔东西。这个Queue和其他的很重要的区别就是你不能往里头装东西,只能用来阻塞式的put调用,要求是前面得有人等着拿这个东西的时候你才可以往里装,但容量为0,其实说白了就是我要递到另外一个的手里才可以。
package com.mashibing.juc.c_025;import java.util.concurrent.BlockingQueue;
import java.util.concurrent.SynchronousQueue;public class T08_SynchronusQueue { //容量为0public static void main(String[] args) throws InterruptedException {BlockingQueue strs = new SynchronousQueue<>();new Thread(()->{try {System.out.println(strs.take());} catch (InterruptedException e) {e.printStackTrace();}}).start();strs.put("aaa"); //阻塞等待消费者消费//strs.put("bbb");//strs.add("aaa");System.out.println(strs.size());}
} TransferQueue
TransferQueue传递,实际上是前面这各种各样Queue的一个组合,它可以给线程来传递任务,以此同时不像是SynchronousQueue只能传递一个,TransferQueue做成列表可以传好多个。比较牛X的是它添加了一个方法叫transfer,如果我们用put就相当于一个线程来了往里一装它就走了。transfer就是装完在这等着,阻塞等有人把它取走我这个线程才回去干我自己的事情。一般使用场景:是我做了一件事情,我这个事情要求有一个结果,有了这个结果之后我可以继续进行我下面的这个事情的时候,比方说我付了钱,这个订单我付账完成了,但是我一直要等这个付账的结果完成才可以给客户反馈。
public class T09_TransferQueue {public static void main(String[] args) throws InterruptedException {LinkedTransferQueue strs = new LinkedTransferQueue<>();new Thread(() -> {try {System.out.println(strs.take());} catch (InterruptedException e) {e.printStackTrace();}}).start();strs.transfer("aaa");//strs.put("aaa");/*new Thread(() -> {try {System.out.println(strs.take());} catch (InterruptedException e) {e.printStackTrace();}}).start();*/}
} Queue和List的区别到底在哪里?
主要就 Queue 添加了offer、peek、poll、put、take这些个对线程友好的或者阻塞,或者等待方法。
七、线程池
线程池他维护这两个集合,第一个是线程的集合,里面是一个一个的线程。第二个是任务的集合,里面是一个一个的任务这叫一个完整的线程池。
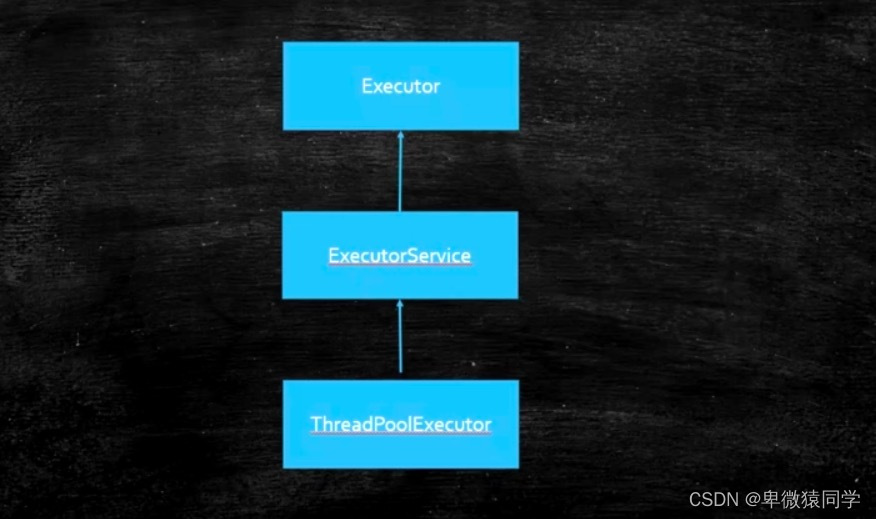
JDK提供了两种线程池类型,第一种就是普通的线程池ThreadPoolExecutor,第二种是ForkJoinPool,这两种是不同类型的线程池,能干的事儿不太一样。Fork分叉,分叉完再分叉,最后的结果汇总这叫join。
ThreadPoolExecutor
定义了一个任务Task,这个任务是实现Runnable接口,就是一个普通的任务了,每一个任务里有一个编号i,然后打印这个编号,打印完后阻塞System.in.read(),每个任务都是阻塞的,toString方法就不说了,定义一个线程池最长的有七个参数,
public class T05_00_HelloThreadPool {static class Task implements Runnable {private int i;public Task(int i) {this.i = i;}@Overridepublic void run() {System.out.println(Thread.currentThread().getName() + " Task " + i);try {System.in.read();} catch (IOException e) {e.printStackTrace();}}@Overridepublic String toString() {return "Task{" +"i=" + i +'}';}}public static void main(String[] args) {ThreadPoolExecutor tpe = new ThreadPoolExecutor(2, 4,60, TimeUnit.SECONDS,new ArrayBlockingQueue(4),Executors.defaultThreadFactory(),new ThreadPoolExecutor.CallerRunsPolicy());for (int i = 0; i < 8; i++) {tpe.execute(new Task(i));}System.out.println(tpe.getQueue());tpe.execute(new Task(100));System.out.println(tpe.getQueue());tpe.shutdown();}
}
线程池的七个参数:
- corePoolSoze:核心线程数,最开始的时候是有这个线程池里面是有一定的核心线程数的;
- maximumPoolSize:最大线程数,线程数不够了,能扩展到最大线程是多少;
- keepAliveTime:生存时间,意思是这个线程有很长时间没干活了请你把它归还给操作系统;
- TimeUnit.SECONDS:生存时间的单位到底是毫秒纳秒还是秒自己去定义;
- 任务队列,就是我们上节课讲的BlockingQueue,各种各样的BlockingQueue你都可以往里面扔,我们这用的是ArrayBlockingQueue,参数最多可以装四个任务;
- 线程工厂defaultThreadFactory,他返回的是一个enw DefaultThreadFactory,它要去你去实现ThreadFactory的接口,这个接口只有一个方法叫newThread,所以就是产生线程的,可以通过这种方式产生自定义的线程,默认产生的是defaultThreadFactory,而defaultThreadFactory产生线程的时候有几个特点:new出来的时候指定了group制定了线程名字,然后指定的这个线程绝对不是守护线程,设定好你线程的优先级。自己可以定义产生的到底是什么样的线程,指定线程名叫什么(为什么要指定线程名称,有什么意义,就是可以方便出错是回溯);
- 拒绝策略:,指的是线程池忙,而且任务队列满这种情况下我们就要执行各种各样的拒绝策略,jdk默认提供了四种拒绝策略,也是可以自定义的。
1:Abort:抛异常
2:Discard:扔掉,不抛异常
3:DiscardOldest:扔掉排队时间最久的
4:CallerRuns:调用者处理服务
以下整理了4个数据库连接池:
SingleThreadPool只有一个线程的线程池;FixedThreadPool固定多少个线程的线程池;CachedPool有弹性的线程池,来一个启动一个,只要没闲着就启动新的来执行;ScheduledPool定时任务来执行线程池;这几个线程池底层全都是用的ThreadPoolExecutor。
SingleThreadPool
看名字就知道这个线程池里面只有一个线程,这个一个线程的线程池可以保证我们扔进去的任务是顺序执行的。
肯定会有人问这样一个问题,为什么会有单线程的线程池?第一个线程池是有任务队列的;生命周期管理线程池是能帮你提供的;
package com.mashibing.juc.c_026_01_ThreadPool;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class T07_SingleThreadPool {public static void main(String[] args) {ExecutorService service = Executors.newSingleThreadExecutor();for(int i=0; i<5; i++) {final int j = i;service.execute(()->{System.out.println(j + " " + Thread.currentThread().getName());});}}
}
CachedPool
他的源码实际上是new了一个ThreadPoolExecutor,他没有核心线程,最大线程可以有好多好多线程,然后60秒钟没有人理他,就回收了,他的任务队列用的是SynchronousQueue,没有指定他的线程工厂他是用的默认线程工厂的,也没有指定拒绝策略,他是默认拒绝策略的。
我们能够看出CachedThreadPool的特点,就是你来一个任务我给你启动一个线程,当然前提是我的线程池里面有线程存在而且他还没有到达60秒钟的回收时间的时候,来一个任务,如果有线程存在我就用现有的线程池,但是在有新的任务来的时候,如果其他线程忙我就启动一个新的。
大家分析一下我们这个CachedThreadPool他用的任务队列是synchronousQueue,它是一个手递手容量为空的Queue,就是你来一个东西必须得有一个线程把他拿走,不然我提交任务的线程从这阻塞住了。synchronousQueue还可以扩展为多个线程的手递手,多个生产者多个消费者都需要手递手叫TransferQueue。这个CachedThreadPool就是这样一个线程池,来一个新的任务就必须马上执行,没有线程空着我就new一个线程。那么阿里是不会推荐使用这中线程池的,原因是线程会启动的特别多,基本接近于没有上限的。
来看这个小程序,首先将这个service打印出来,最后在把service打印出来,我们的任务是睡500个毫秒,然后打印线程池,打印他的名字。运行一下,通过打印线程池的toString的输出能看到线程池的一些状态。
//源码
public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue());
}package com.mashibing.juc.c_026_01_ThreadPool;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;public class T08_CachedPool {public static void main(String[] args) throws InterruptedException {ExecutorService service = Executors.newCachedThreadPool();System.out.println(service);for (int i = 0; i < 2; i++) {service.execute(() -> {try {TimeUnit.MILLISECONDS.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread().getName());});}System.out.println(service);TimeUnit.SECONDS.sleep(80);System.out.println(service);}
}
FixedThreadPool
并行和并发有什么区别concurrent vs parallel:并发是指任务提交,并行指任务执行;并行是并发的子集。并行是多个cpu可以同时进行处理,并发是多个任务同时过来。
你看他的名称,fixed是固定的含义,就是固定的一个线程数,FixedThreadPool指定一个参数,到底有多少个线程,你看他的核心线程和最大线程都是固定的,因为他的最大线程和核心线程都是固定的就没有回收之说所以把他指定成0,这里用的是LinkedBlockingQueue(如果在阿里工作看到LinkedBlockingQueue一定要小心,他是不建议用的)
我们来看一下这个FixedThreadPool的小例子,用一个固定的线程池有一个好处是什么呢,就是你可以进行并行的计算。FixedThreadPool是确实可以让你的任务来并行处理的,那么并行处理的时候就可以真真正正的提高效率。
看这个方法isPrime判断一个数是不是质数,然后写了另外一个getPrime方法,指定一个其实的位置,一个结束的位置将中间的质数拿出来一部分,主要是为了把任务给切分开。计算从1一直到200000这么一些数里面有多少个数是质数getPrime,计算了一下时间,只有我们一个main线程来运行,不过我们既然学了多线程就完全可以这个任务切分成好多好多子任务让多线程来共同运行,我有多少cpu,我的机器是4核的,这个取决你的机器数,在启动了一个固定大小的线程池,然后在分别来计算,分别把不同的阶段交给不同的任务,扔进去submit他是异步的,拿到get的时候才知道里面到底有多少个,全部get完了之后相当于所有的线程都知道结果了,最后我们计算一下时间,用这两种计算方式就能比较出来到底是并行的方式快还是串行的方式快。 拿大腿想一想也能知道肯定是利用线程池速度要快的多。因此呢,这也是线程池使用的一种方式。
//源码public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue());}/*** 线程池的概念* nasa*/
package com.mashibing.juc.c_026_01_ThreadPool;import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;public class T09_FixedThreadPool {public static void main(String[] args) throws InterruptedException, ExecutionException {long start = System.currentTimeMillis();getPrime(1, 200000); long end = System.currentTimeMillis();System.out.println(end - start);final int cpuCoreNum = 4;ExecutorService service = Executors.newFixedThreadPool(cpuCoreNum);MyTask t1 = new MyTask(1, 80000); //1-5 5-10 10-15 15-20MyTask t2 = new MyTask(80001, 130000);MyTask t3 = new MyTask(130001, 170000);MyTask t4 = new MyTask(170001, 200000);Future> f1 = service.submit(t1);Future> f2 = service.submit(t2);Future> f3 = service.submit(t3);Future> f4 = service.submit(t4);start = System.currentTimeMillis();f1.get();f2.get();f3.get();f4.get();end = System.currentTimeMillis();System.out.println(end - start);}static class MyTask implements Callable> {int startPos, endPos;MyTask(int s, int e) {this.startPos = s;this.endPos = e;}@Overridepublic List call() throws Exception {List r = getPrime(startPos, endPos);return r;}}static boolean isPrime(int num) {for(int i=2; i<=num/2; i++) {if(num % i == 0) return false;}return true;}static List getPrime(int start, int end) {List results = new ArrayList<>();for(int i=start; i<=end; i++) {if(isPrime(i)) results.add(i);}return results;}
}
Cache vs Fixed
什么时候用Cache什么时候用Fixed,你得精确的控制你有多少个线程数,控制数量问题多数情况下你得预估并发量。如果线程池中的数量过多,最终他们会竞争稀缺的处理器和内存资源,浪费大量的时间在上下文切换上,反之,如果线程的数目过少,正如你的应用所面临的情况,处理器的一些核可能就无法充分利用。Brian Goetz建议,线程池大小与处理器的利用率之比可以使用公式来进行计算估算:线程池=你有多少个cpu 乘以 cpu期望利用率 乘以 (1+ W/C)。W除以C是等待时间与计算时间的比率。
假如你这个任务并不确定他的量平稳与否,就像是任务来的时候他可能忽高忽低,但是我要保证这个任务来时有人做这个事儿,那么我们可以用Cache,当然你要保证这个任务不会堆积。那Fixed的话就是这个任务来的比较平稳,我们大概的估算了一个值,就是这个值完全可以处理他,我就直接new这个值的线程来扔在这就ok了。(阿里是都不用,自己估算,进行精确定义)
ScheduledPool
ScheduledPool定时任务线程池,就是我们原来学过一个定时器任务,隔一段时间之后这个任务会执行。这个就是我们专门用来执行定时任务的一个线程池。看源码,我们newScheduledThreadPool的时候他返回的是ScheduledThreadPoolExecutor,然后在ScheduledThreadPoolExecutor里面他调用了super,他的super又是ThreadPoolExecutor,它本质上还是ThreadPoolExecutor,所以并不是别的,参数还是ThreadPool的七个参数。这是专门给定时任务用的这样的一个线程池,了解就可以了。
看程序,newScheduledThreadPool核心线程是4,其实他这里面有一些好用的方法比如是scheduleAtFixedRate间隔多长时间在一个固定的频率上来执行一次这个任务,可以通过这样的方式灵活的对于时间上的一个控制,第一个参数(Delay)第一个任务执行之前需要往后面推多长时间;第二个(period)间隔多长时间;第三个参数是时间单位;
//源码
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {return new ScheduledThreadPoolExecutor(corePoolSize);
}package com.mashibing.juc.c_026_01_ThreadPool;
import java.util.Random;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;public class T10_ScheduledPool {public static void main(String[] args) {ScheduledExecutorService service = Executors.newScheduledThreadPool(4);service.scheduleAtFixedRate(()->{try {TimeUnit.MILLISECONDS.sleep(new Random().nextInt(1000));} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread().getName());}, 0, 500, TimeUnit.MILLISECONDS);}
}
给大家分享一道阿里的面试题:假如提供一个闹钟服务,订阅这个服务的人特别多,10亿人,就意味着在每天早上七点钟的时候会有10亿的并发量涌向你这的服务器,问你怎么优化?
思想是把这个定时的任务分发到很多很多的边缘的服务器上去,一台服务器不够啊,在一台服务器上有一个队列存着这些任务,然后线程去消费,也是要用到线程池的,大的结构上用分而治之的思想,主服务器把这些同步到边缘服务器,在每台服务器上用线程池加任务队列。
到现在我们学习了四种线程池了,我们来稍微回顾一下:
1:SingleThreadPool只有一个线程的线程池;
2:FixedThreadPool固定多少个线程的线程池;
3:CachedPool有弹性的线程池,来一个启动一个,只要没闲着就启动新的来执行;
4:ScheduledPool定时任务来执行线程池;
这几个线程池底层全都是用的ThreadPoolExecutor。
自定义一个拒绝策略的例子,代码演示如下:
package com.mashibing.juc.c_026_01_ThreadPool;
import java.util.concurrent.*;
public class T14_MyRejectedHandler {public static void main(String[] args) {ExecutorService service = new ThreadPoolExecutor(4, 4,0, TimeUnit.SECONDS, new ArrayBlockingQueue<>(6),Executors.defaultThreadFactory(),new MyHandler());}static class MyHandler implements RejectedExecutionHandler {@Overridepublic void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {//log("r rejected")//save r kafka mysql redis//try 3 timesif(executor.getQueue().size() < 10000) {//try put again();}}}
}
下一篇:C语言文件操作