Towards Class-Oriented Poisoning Attacks Against Neural Networks 论文笔记
#论文笔记#
1. 论文信息
| 论文名称 | Towards Class-Oriented Poisoning Attacks Against Neural Networks |
|---|---|
| 作者 | Bingyin Zhao |
| 会议/出版社 | WACV 2022 |
| 📄在线pdf | |
| 代码 | 无 |
基于类别的 availability attacks,不同于原本的 availability attacks 只考虑降低模型的整体准确率,本文还考虑了降低特定类的准确率或迫使模型将其他类都预测为目标类。
2. introduction
本文提出了面向类别的 availability attacks,通过梯度优化的方法生成 posion data。使用该 posion data 训练出的模型在特定类别上的准确率发生异常。
-
availability attacks 的优化目标,bi-level optimization problem
argmaxDp∑(x,y)∈Dval L[Fθ∗(x),y,θ∗]\underset{\mathcal{D}_{p}}{\arg \max } \sum_{(\boldsymbol{x}, y) \in \mathcal{D}_{\text {val }}} L\left[\mathcal{F}_{\theta^{*}}(\boldsymbol{x}), y, \theta^{*}\right]Dpargmax∑(x,y)∈Dval L[Fθ∗(x),y,θ∗]
S.t. θ∗∈argminθ∗∈Θ∑(x,y)∈Dtr∪DpL[Fθ∗(x),y,θ]\theta^{*} \in \underset{\theta^{*} \in \Theta}{\arg \min } \sum_{(\boldsymbol{x}, y) \in \mathcal{D}_{t r} \cup \mathcal{D}_{p}} L\left[\mathcal{F}_{\theta^{*}}(\boldsymbol{x}), y, \theta\right]θ∗∈θ∗∈Θargmin∑(x,y)∈Dtr∪DpL[Fθ∗(x),y,θ], -
威胁模型
- 攻击者知道,算法结构,超参数以及训练数据集
- 攻击者可以对训练数据集注入有毒数据并且修改标签
3. method
两种攻击方式:
Class-Oriented availability attacks 可以为两种:
COEG class-oriented error-generic
目标:让模型将所有的输入都分类成目标类(supplanter class)
目标函数:argmaxDp∑(x,y)∈Dval L[Fθ∗(x),y,θ∗]\underset{\mathcal{D}_{p}}{\arg \max } \sum_{(\boldsymbol{x}, y) \in \mathcal{D}_{\text {val }}} L\left[\mathcal{F}_{\theta^{*}}(\boldsymbol{x}), y, \theta^{*}\right]Dpargmax∑(x,y)∈Dval L[Fθ∗(x),y,θ∗]
s.t. θ∗∈argminθ∗∈Θ∑(x,y)∈Dtr∪DpL[Fθ∗(x),ys,θ]\quad \theta^{*} \in \underset{\theta^{*} \in \Theta}{\arg \min } \sum_{(\boldsymbol{x}, y) \in \mathcal{D}_{t r} \cup \mathcal{D}_{p}} L\left[\mathcal{F}_{\theta^{*}}(\boldsymbol{x}), y_{s}, \theta\right]θ∗∈θ∗∈Θargmin∑(x,y)∈Dtr∪DpL[Fθ∗(x),ys,θ],
ysy_sys 表示目标类
COES class-oriented error-specific
目标:降低 victim classes 的准确率,保持 non-victim classes(其他类) 的准确率不变
目标函数:argmaxDp∑(x,y)∈DvalL[Fθ∗(x),yv,θ∗]\underset{\mathcal{D}_{p}}{\arg \max } \sum_{(\boldsymbol{x}, y) \in \mathcal{D}_{v a l}} L\left[\mathcal{F}_{\theta^{*}}(\boldsymbol{x}), y_{v}, \theta^{*}\right]Dpargmax∑(x,y)∈DvalL[Fθ∗(x),yv,θ∗]
s.t. θ∗∈argminθ∗∈Θ∑(x,y)∈Dtr∪DpL[Fθ∗(x),yvˉ,θ]\quad \theta^{*} \in \underset{\theta^{*} \in \Theta}{\arg \min } \sum_{(\boldsymbol{x}, y) \in \mathcal{D}_{t r \cup \mathcal{D}_{p}}} L\left[\mathcal{F}_{\theta^{*}}(\boldsymbol{x}), y_{\bar{v}}, \theta\right]θ∗∈θ∗∈Θargmin∑(x,y)∈Dtr∪DpL[Fθ∗(x),yvˉ,θ],
yvy_vyv 表示 victim classes,yvˉy_{\bar{v}}yvˉ 表示 non-victim classes
两种攻击方式的训练方法
-
COEG Attack
目标函数:
- L=λ⋅Lfys−LfyoL=\lambda \cdot L_{f_{y_{s}}}-L_{f_{y_{o}}}L=λ⋅Lfys−Lfyo
- Lfys=fys(x)L_{f_{y_{s}}}=f_{y_{s}}(\boldsymbol{x})Lfys=fys(x)
- fykf_{y_k}fyk as the corresponding logit to the categorical label yky_kyk
- fyo(x)f_{y_{o}}(\boldsymbol{x})fyo(x) is the logit output of the groundtruth class
poisoned image xpx_{p}xp
xp=xo−ϵ⋅sign(∇xo(λ⋅Lfys−Lfyo))\boldsymbol{x}_{\boldsymbol{p}}=\boldsymbol{x}_{\boldsymbol{o}}-\epsilon \cdot \operatorname{sign}\left(\nabla_{\boldsymbol{x}_{o}}\left(\lambda \cdot L_{f_{y_{s}}}-L_{f_{y_{o}}}\right)\right)xp=xo−ϵ⋅sign(∇xo(λ⋅Lfys−Lfyo))
算法流程

-
COES Attack
COES 既要降低目标类的准确率,又要保持其他类的准确率。
加毒的过程分为:
- 在每一类中选取相同的数量的图片
- 通过算法2提升或者减少每幅图像与 label 信息对应的特征信息
- 改变目标类的标签
目标函数:
L={λ⋅Lfys−Lfyo,if xo∈CvLfyo,otherwise L= \begin{cases}\lambda \cdot L_{f_{y_{s}}}-L_{f_{y_{o}}}, & \text { if } x_{o} \in \mathcal{C}_{v} \\ L_{f_{y_{o}}}, & \text { otherwise }\end{cases}L={λ⋅Lfys−Lfyo,Lfyo, if xo∈Cv otherwise
poisoned image xpx_{p}xp
{xo−ϵ⋅sign(∇xo(λ⋅Lfys−Lfyo)),if xo∈Cvxo+ϵ⋅sign(∇xo(Lfyo)),otherwise \begin{cases}x_{o}-\epsilon \cdot \operatorname{sign}\left(\nabla_{x_{o}}\left(\lambda \cdot L_{f_{y_{s}}}-L_{f_{y_{o}}}\right)\right), & \text { if } x_{o} \in \mathcal{C}_{v} \\ x_{o}+\epsilon \cdot \operatorname{sign}\left(\nabla_{x_{o}}\left(L_{f_{y_{o}}}\right)\right), & \text { otherwise }\end{cases}{xo−ϵ⋅sign(∇xo(λ⋅Lfys−Lfyo)),xo+ϵ⋅sign(∇xo(Lfyo)), if xo∈Cv otherwise
算法2:

4. experiments
评价指标:
- Change-to-Target (CTT):其他类被分到目标类的比例
- Change-from-Target (CFT) :目标类被错误分类的比例
🟠数据集一
MNIST
🟠数据集二
CIFAR-10
🟠数据集三
ImageNet-ILSVRC2012
-
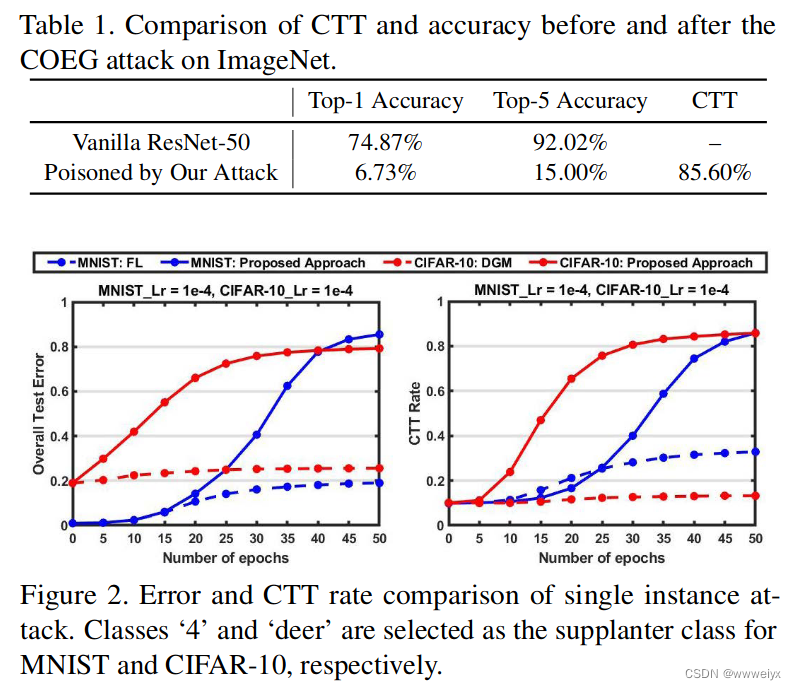
COEG 在三个数据集上的实验结果:
-
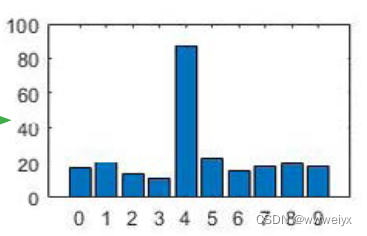
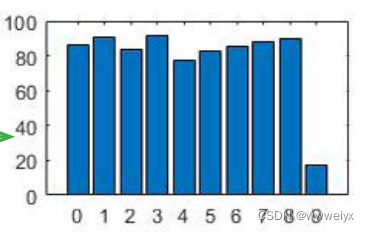
COES 在 cifar10 上的实验结果: