
爬虫基础知识
一、Scrapy
1、cookie设置
目前cookie的设置不支持在headers进行设置, 需要通过以下三种方式进行设置:
第一种:setting文件中设置cookie
- 当
COOKIES_ENABLED是注释的时候,scrapy默认没有开启cookie。 - 当
COOKIES_ENABLED没有注释设置为False的时候,scrapy默认使用了settings里面的cookie。 - 当
COOKIES_ENABLED设置为True的时候,scrapy就会把settings的cookie关掉,使用自定义cookie。
注意:
- 当使用settings的cookie的时候,又把
COOKIES_ENABLED设置为True,scrapy就会把settings的cookie关闭,而且也没使用自定义的cookie,会导致整个请求没有cookie,导致获取数据失败。- 如果使用自定义cookie就把
COOKIES_ENABLED设置为True- 如果使用settings的cookie就把
COOKIES_ENABLED设置为False
第二种:middlewares中设置cookie
在middlewares中的downloadermiddleware中的process_request中配置cookie,配置如下:
request.cookies=
{'Hm_lvt_a448cb27ae2acb9cdb5f92e1f0b454f3': '1665643660',
' _ga': 'GA1.1.755852642.1665643660'
}
注意:cookie内容要以键值对的形式存在
第三种:在spider爬虫主文件中,重写start_request方法,在scrapy的Request函数的参数中传递cookies
重载start_requests方法
def start_requests(self):headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) Gecko/20100101 Firefox/44.0"}# 指定cookiescookies = {'Hm_lvt_a448cb27ae2acb9cdb5f92e1f0b454f3': '1665643660', ' _ga': 'GA1.1.755852642.1665643660'}
2、Get请求带参数
yield scrapy.FormRequest(url=url,method='GET',formdata=params,callback=self.parse_result
)
3、 item数据只有最后一条
只显示主页数据中爬到的最后一条数据,其他都正常
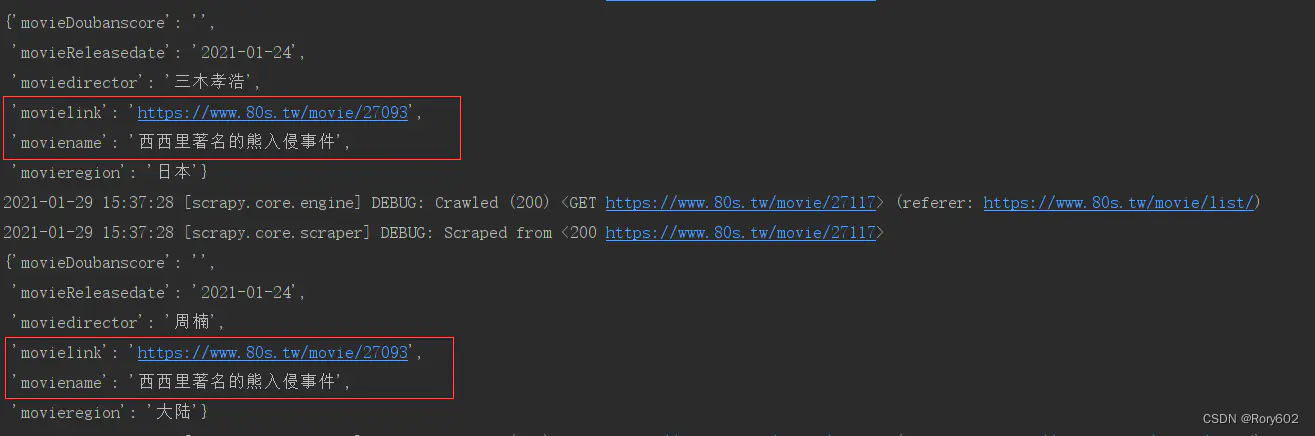
这是我对标签进行遍历时,将item对象放置在了for循环的外部。修改代码就好
修改前:
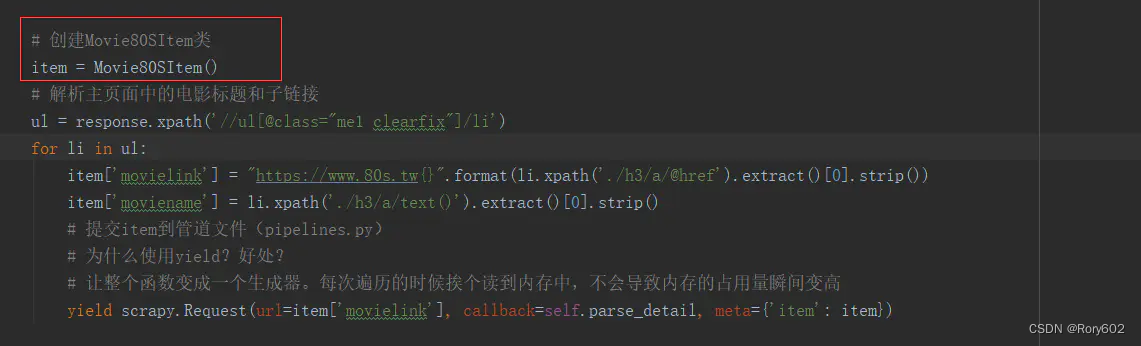
修改后:
成功
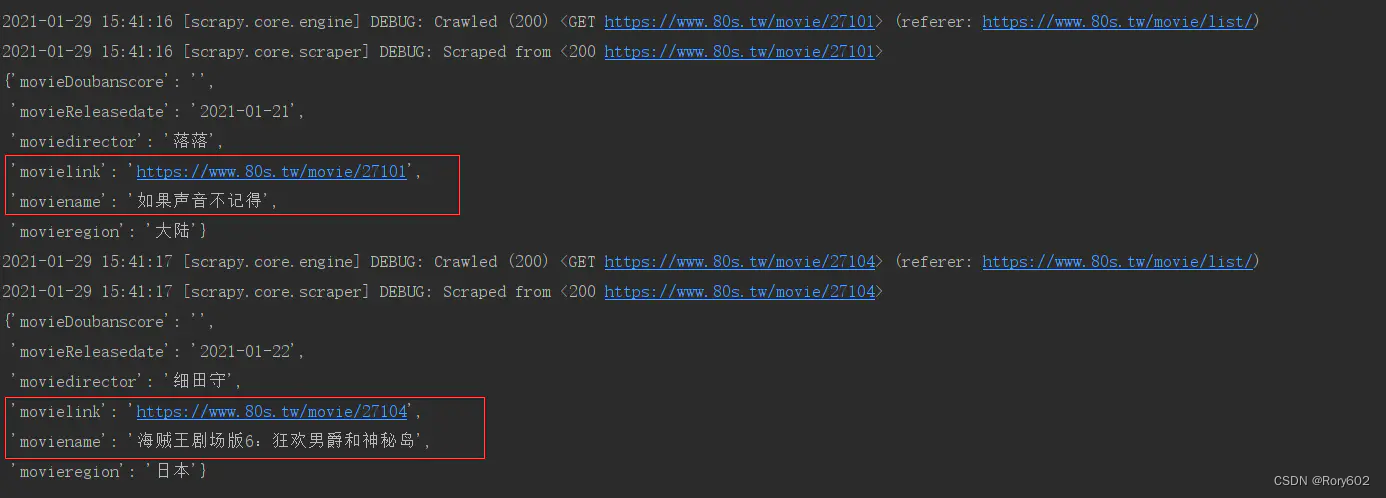
scrapy中的yield scrapy.Request 在传递item 的注意点, 或者使用deepcopy
4、start_requests或者start_urls多个请求只请求第一个
默认情况下,scrapy防止重复请求。由于在起始url中只有参数不同,scrapy会将起始url中的其余url视为第一个url的重复请求。这就是为什么你的spider在获取第一个url后停止。为了解析其余的url,我们在scrapy请求中启用了dont_filter标志。
修改前:
def start_requests(self):for i in range(10):yield scrapy.Request('https://baidu.com', self.parse, meta={"seq": i})
修改后:
def start_requests(self):for i in range(10):yield scrapy.Request('https://baidu.com', self.parse, meta={"seq": i}, dont_filter=True)
5、数据流
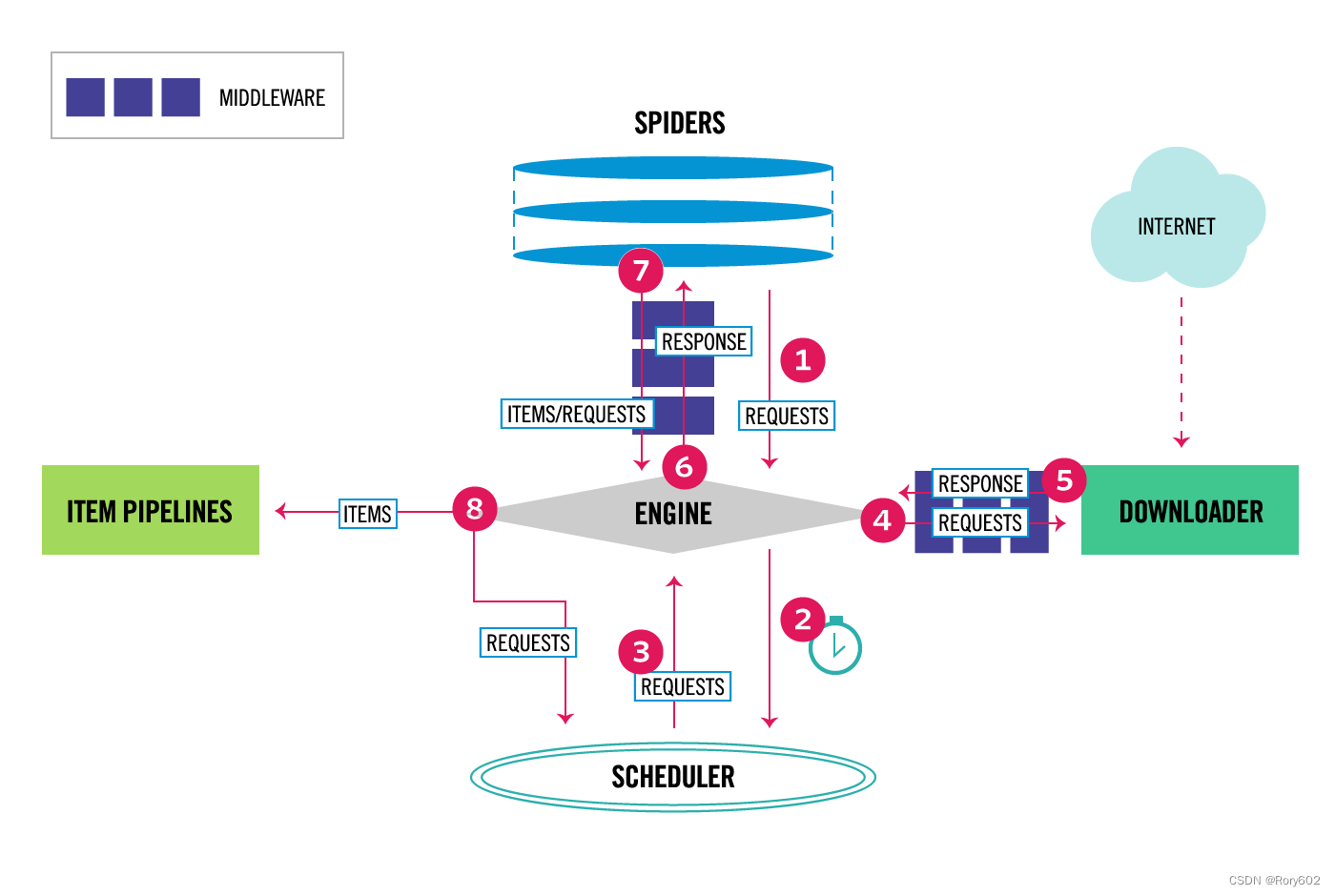
Scrapy中的数据流是由执行引擎控制的,它是这样的:
Engine方法获取要来自Spider爬取的初始请求。Engine将请求交给Scheduler调度,并向Scheduler索取下一个抓取请求。Scheduler从队列中返回下一个请求给Engine。Engine通过Downloader middleware将请求发送给 Downloader。- 一旦页面完成下载,
Downloader生成一个响应(带有该页面)并将其发送给引擎,传递给Downloader middleware。 Engine从Downloader接收响应,并将其通过Spider Middleware发送到 Spider进行处理。Spider处理响应,并通过Spider Middleware向 Engine返回抓取items和新请求。Engine将已处理的items发送到Item pipeline,然后将已处理的请求发送到Scheduler,并请求可能的下一个请求进行爬取。- 该过程重复(从步骤3开始),直到不再有来自
Scheduler的请求。
6、组件
Scrapy Engine
引擎负责控制系统所有组件之间的数据流,并在某些操作发生时触发事件。
Scheduler
scheduler 从引擎接收请求,并将它们入队列,以便在引擎请求它们时稍后提供它们(也提供给引擎)。
Downloader
Downloader负责获取网页并将其提供给引擎,而引擎又将其提供给spiders。
Spiders
spider是由Scrapy用户编写的自定义类,用于解析响应并从中提取items 或要发送的其他请求。
Item Pipeline
The Item Pipeline负责处理被spiders提取(或刮取)的items。典型的任务包括清理、验证和持久化(比如将items存储在数据库中)。
Downloader middlewares
下载器中间件是位于引擎和下载器之间的特定钩子,当请求从引擎传递到下载器时处理请求,并处理从下载器传递到引擎的响应。
如果需要执行以下操作之一,请使用Downloader中间件:
- 在请求被发送到Downloader之前处理它(即在Scrapy将请求发送到网站之前)。
- 发送给
spider之前更改响应。 - 发送一个新的Request,而不是将收到的响应传递给
spider。 - 在不获取网页的情况下将响应传递给爬行器
- 默默地放弃一些请求。
Spider middlewares
Spider middlewares是位于引擎和Spiders之间的特定钩子,能够处理spider输入(responses)和输出(items 和 requests)。
如果有以下需要,可以使用Spider中间件:
- spider回调输出的后处理,更改、增加、删除请求或items。
- start_requests的后处理。
- spider的异常处理。
- 根据响应内容为某些请求调用errback而不是回调。
参考资料
https://www.jianshu.com/p/de3e0ed0c26b
https://blog.csdn.net/holmes369/article/details/104477183/
https://github.com/scrapy/scrapy/blob/master/docs/topics/architecture.rst
https://www.jianshu.com/p/8824623b551c