
进程创建进程终止进程等待
目录
- 前言
- 一、进程创建
- 1.fork()函数
- (1)fork()函数的基本认识
- 进程调用fork()函数之后,控制权转移到内核中的fork()代码之后,内核做了啥?
- (2)实验:使用fork()函数创建进程
- (3)实验:验证子进程的存在
- (4)实验:演示使用fork()函数创建进程失败的现象
- (5)关于fork()函数需要知道的点
- (6)fork()函数执行之后,操作系统做了什么?
- 2.写时拷贝
- (1)写时拷贝的具体过程分析
- (2)为什么要采取写时拷贝?创建子进程的时候就将数据分开不行吗?
- (3)写时拷贝的意义
- 二、进程终止
- 1.main函数的返回值
- 2. 进程终止的三种常见情况
- 3.进程终止的常见做法
- 4.exit()和_exit()的使用
- (1)实验:验证exit()和_exit()的区别
- (2)exit()和_exit()的区别
- 5.关于终止,内核做了啥?
- 三、进程等待
- 1.进程等待的原因
- 2.进程等待的方法
- (1)wait()函数
- (2)waitpid()函数
- 总结
前言
在这篇文章中我们学习了进程创建,进程终止,进程等待三个内容,首先学习使用fork()函数来创建一个子进程和创建子进程之后使用写时拷贝技术解决父子进程数据问题,然后就是进程终止和进程等待,进程终止主要是讲了使用exit()函数来终止一个进程,进程等待主要是为了解决僵尸进程的问题,回收僵尸进程的退出信息
一、进程创建
1.fork()函数
(1)fork()函数的基本认识
- 使用man手册查看fork()函数的使用方法
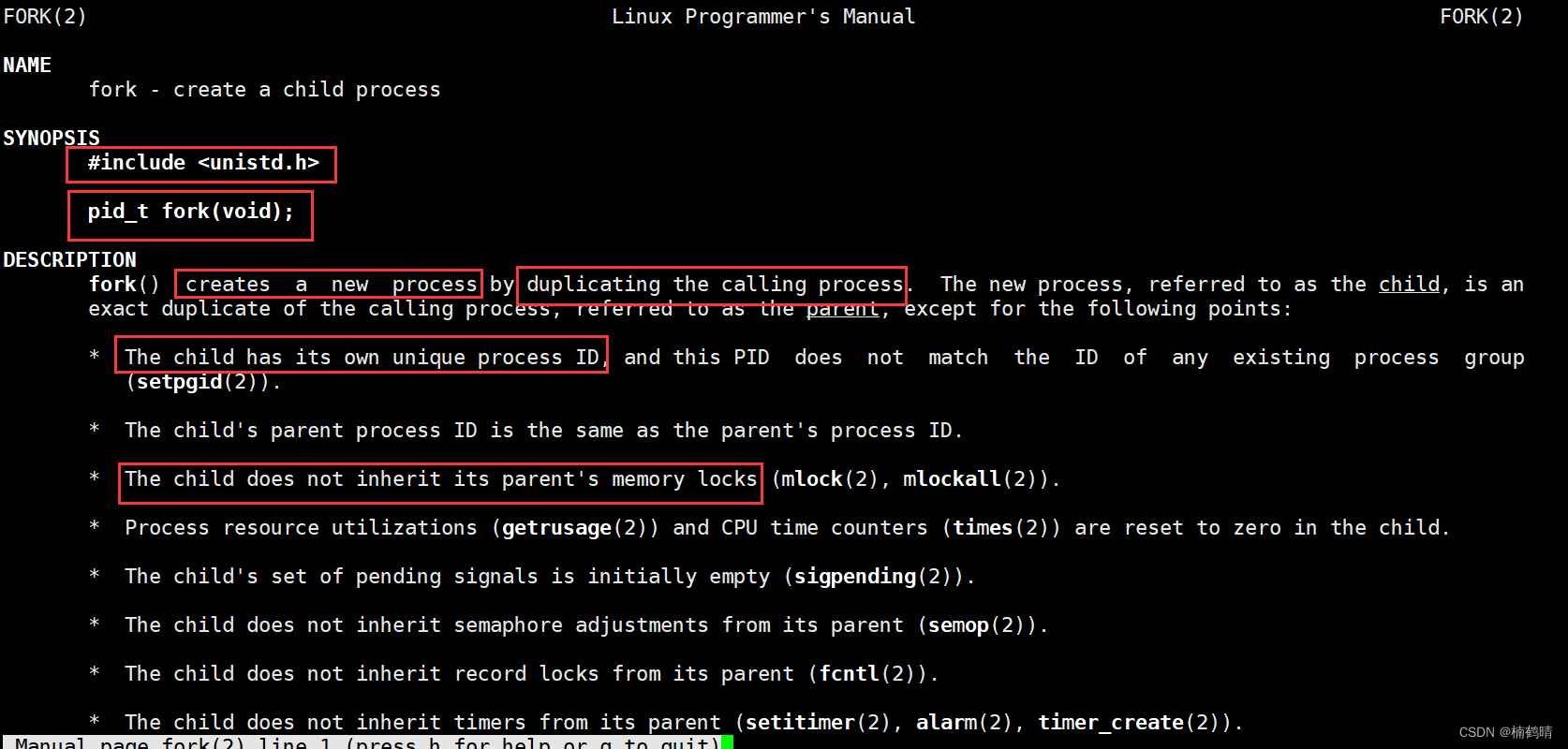
- 基本使用方法:
pid_t fork(void); - 返回值:
- 如果创建成功:给父进程返回子进程的pid,给子进程返回0
- 如果创建失败,给父进程返回-1
- 功能:父进程调用fork()函数创建一个子进程
进程调用fork()函数之后,控制权转移到内核中的fork()代码之后,内核做了啥?
- 分配内存块和内核数据结构给子进程
- 将父进程部分数据结构内容拷贝给子进程
- 添加子进程到系统的进程列表
- fork()返回之后,开始调度器调度
(2)实验:使用fork()函数创建进程
- 构建项目
- 创建fork.c和makefile文件
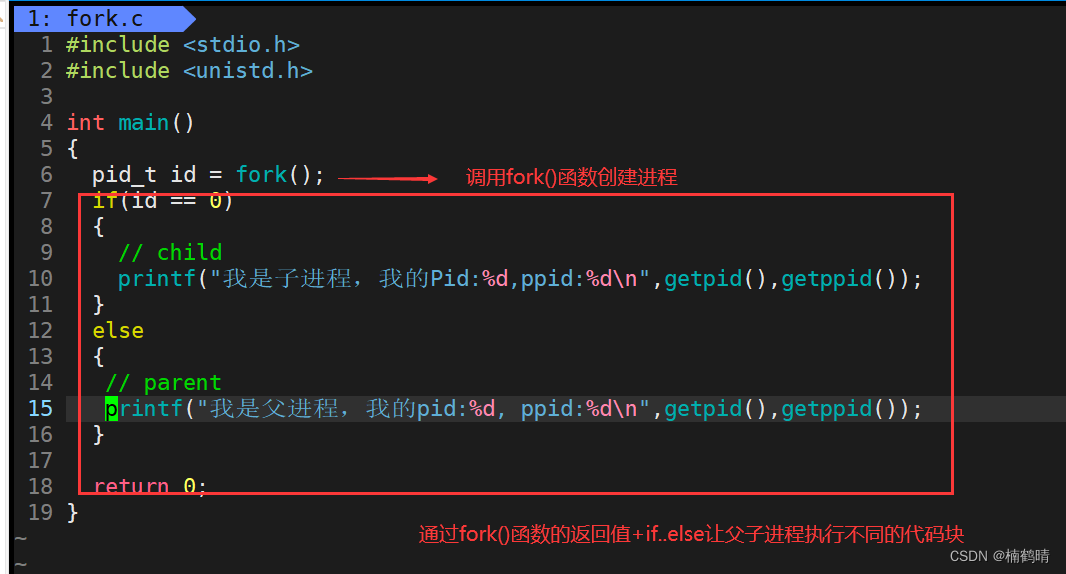
- 实验结果

(3)实验:验证子进程的存在
- 构建项目
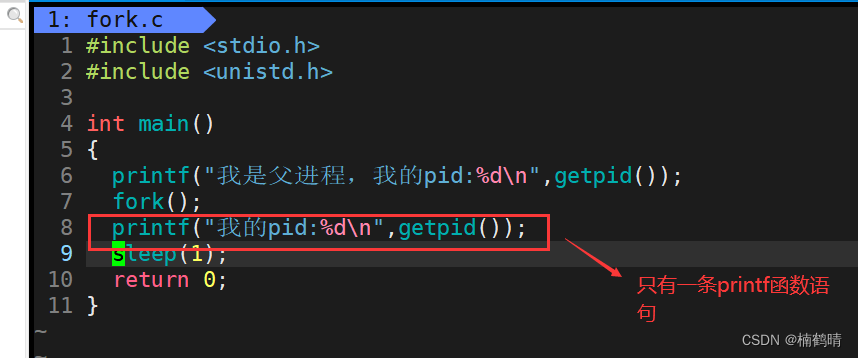
- 实验结果

显然就是两个进程去调用printf函数,从而出现两条结果

(4)实验:演示使用fork()函数创建进程失败的现象
- 构建项目
- 创建fork_err项目(其中包含fork.c文件和makefile文件)
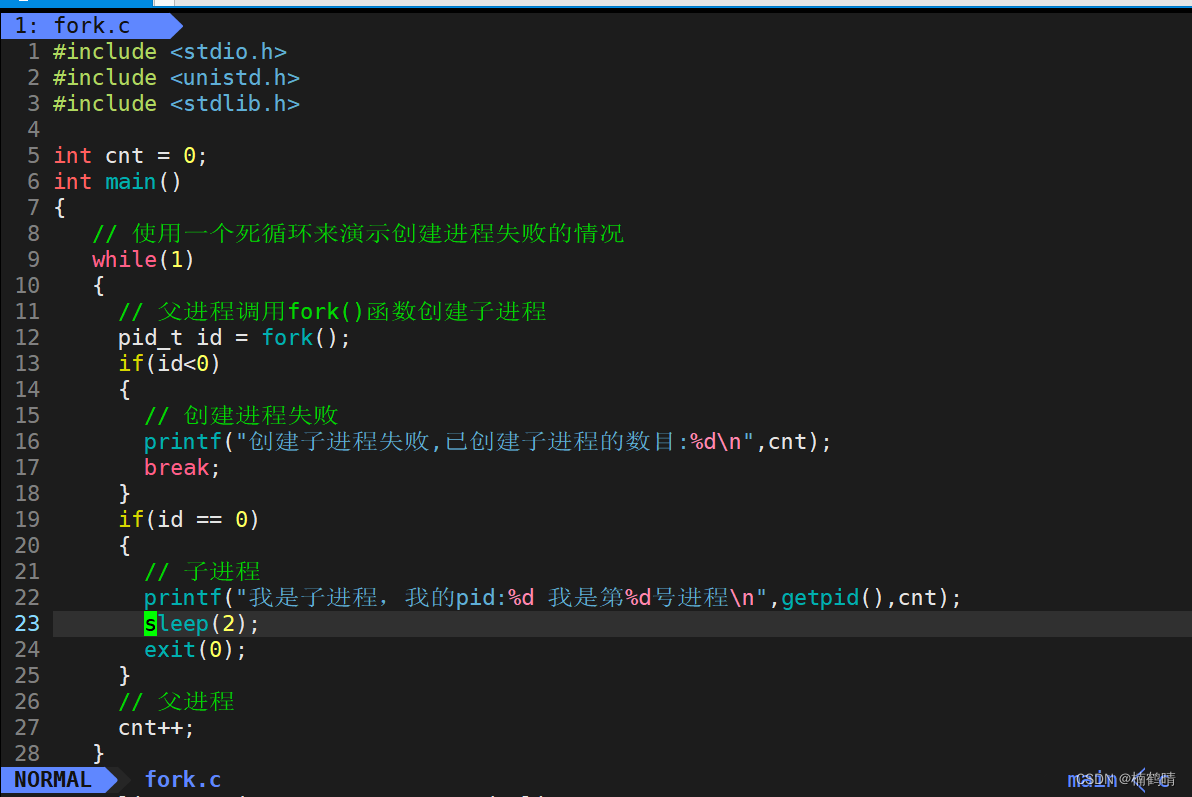
- 编译形成可执行程序并查看实验结果
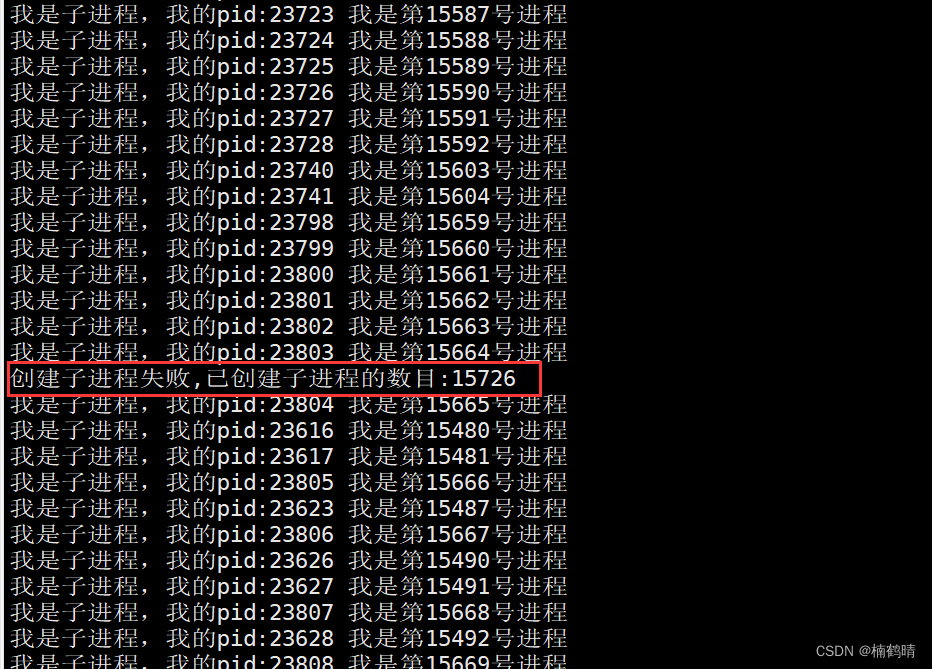
- fork()函数创建进程失败的原因
- 系统中有太多的进程
- 实际用户的进程数超过了限制
- 内存不够
(5)关于fork()函数需要知道的点
- 共享代码:fork()函数创建子进程之后,父子进程共享同一份代码,代码一般都是只读的,所以父子进程无法对代码做出修改,但是数据可能会被修改,因此,在父子进程没有修改数据的情况下,父子进程可以共享同一份数据,但是如果父子进程其中一者对数据做出修改,那么此时将会发生写时拷贝
- eip程序计数器(pc指针):在CPU中有一个寄存器叫程序计数器(eip),这个寄存器可以保存当前正在执行的指令的下一条指令,当创建子进程之后,程序计数器会将其内容拷贝给子进程,因此,子进程便知道父进程上次执行到哪个地方,从而便从eip指向的地方继续向下执行,这就是子进程创建之后是从fork()函数之后的代码继续执行,而不是从头开始执行的原因
(6)fork()函数执行之后,操作系统做了什么?
我们都知道,进程是由内核的进程数据结构和进程的代码和数据组成的,内核的数据结构我们现在所知道的有两个:task_struct+mm_struct,所以此过程操作系统会创建子进程的内核数据结构和页表,然后子进程的代码继承自父进程,数据通过写时拷贝的方式进行共享
2.写时拷贝
写时拷贝是维护进程独立性的一个非常重要的手段,其通常是指在系统识别到有人要更改数据时,会在系统的内存中为该数据再开辟一个空间,然后将该数据的值拷贝过去,最后在新空间上进行修改,从而实现两个进程的数据的分离,两个进程对该数据的修改互不影响,从而维护了进程的独立性
(1)写时拷贝的具体过程分析
- 修改内容前
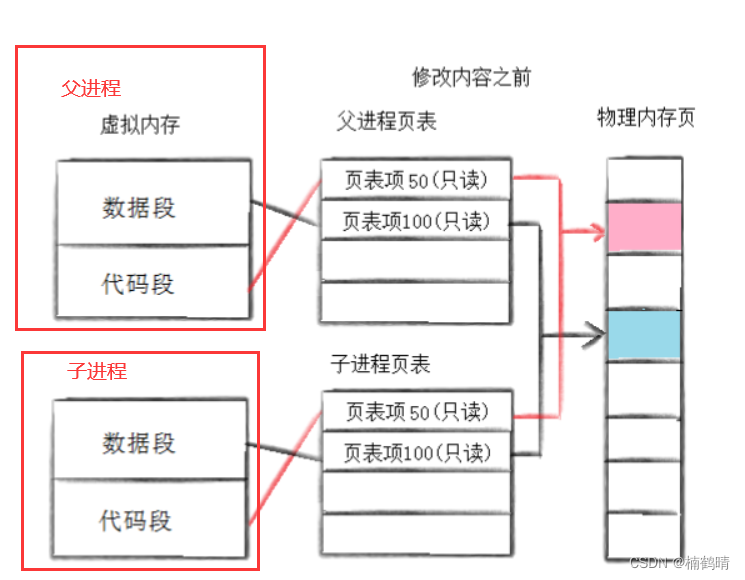
父进程和子进程使用的代码段是只读的,因此代码段的内容进行共享即可,在修改之前,因为没有进程对数据内容做修改,因此,此时父子进程共享同一份数据(映射的物理空间是同一块空间) - 修改数据
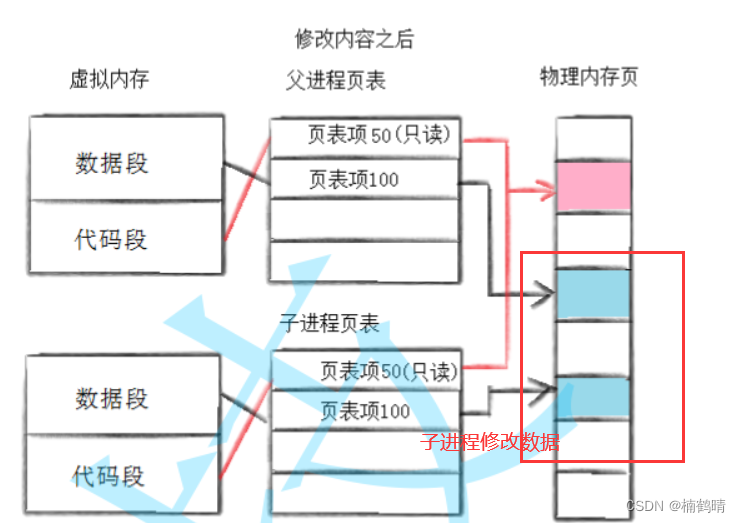
当操作系统识别到子进程想要修改该数据,便在内存中的另一个地方为该数据再分配一块新的空间,这个空间只属于子进程的,此时再将该数据原来的值拷贝放到该空间,然后再在该空间对该数据进行修改,同时操作系统会更新子进程中的页表映射关系,修改的主要该数据映射的物理空间,虚拟空间不需要做修改,物理地址修改为后面分配的物理地址,此时父子进程对该数据的虚拟地址是一样的,但是通过页表映射之后的物理地址是不一样的,属于两块不同的空间
(2)为什么要采取写时拷贝?创建子进程的时候就将数据分开不行吗?
- 父进程的数据子进程不一定都要用到,即使都要用到也不一定都要写入(修改),这样就会有浪费空间的嫌疑
- 最理想的情况是只有被父子进程修改的数据才需要进行分离拷贝,不需要修改的数据共享即可
- 如果在fork的时候就无脑进行拷贝数据分离给子进程会增加fork的成本(内存和时间上)
(3)写时拷贝的意义
写时拷贝是一种延迟拷贝的策略,只有真正使用的时候才进行拷贝分离,暂时不使用但是想要的空间不会进行写时拷贝,此时该空间可以先分配给其他进程进行使用,这样就变向提高了内存的利用率
二、进程终止
1.main函数的返回值
在我们的C语言或者C++语言中,我们通常会写main函数,这个main函数我们知道是程序的入口,通常我们会在最后写上return 0;
那么这个return 0;中的0到底是什么意思?
其实,这个0代表的是进程的退出码,0表示的是进程正常结束,运行结果正确非零表示进程运行结束,运行结果不正确,其中退出码的非零就是代表结果运行不正确的原因,退出码是返回给当前进程的父进程进行接收的
- 怎么查看进程的退出码呢?
使用echo $?命令
演示:
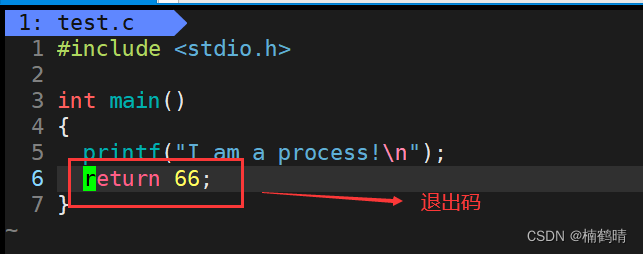
使用echo $?查看退出码
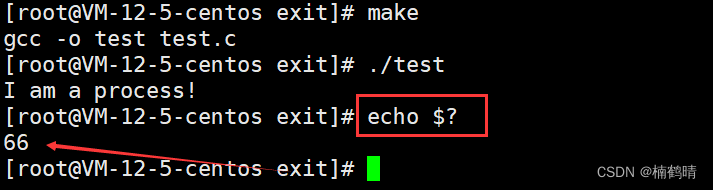
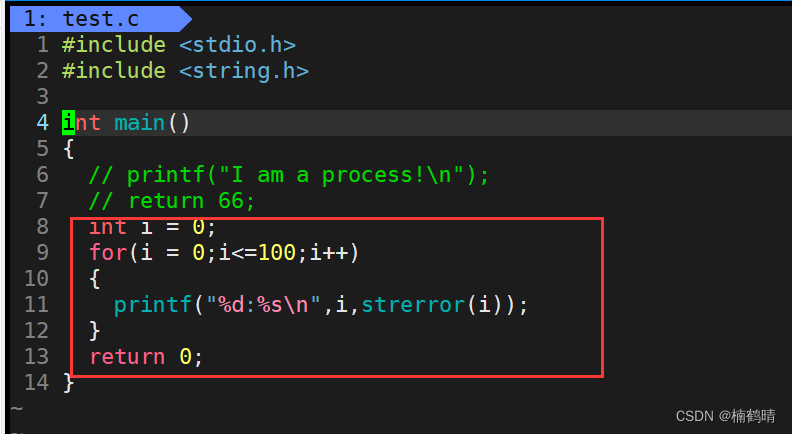
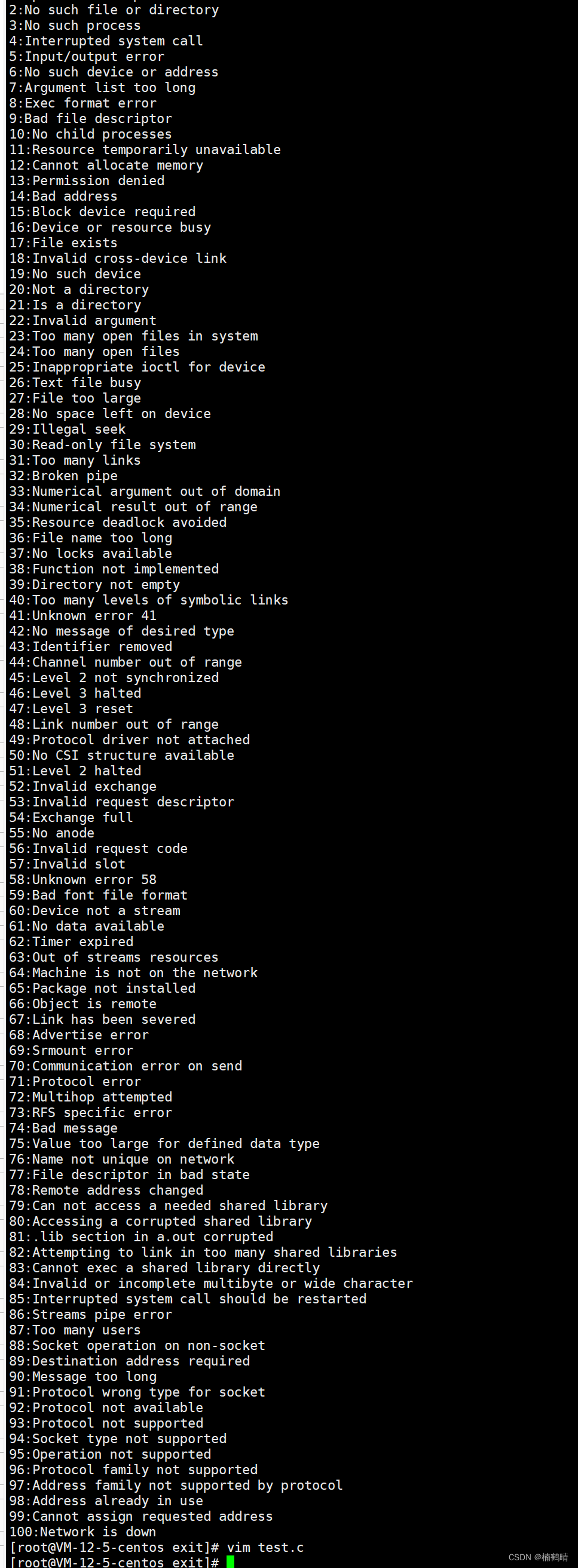
此时该进程的父进程是bash进程,而echo $?表示的是bash最近一次执行完毕对应进程的退出码 - 查看1-100对应的错误(退出)信息
- 源代码
- 运行结果
2. 进程终止的三种常见情况
- 代码跑完,运行结果正确
- 代码跑完,运行结果不正确
- 代码没跑完,异常退出
3.进程终止的常见做法
- 在main函数中使用reutrn语句
main函数是程序的入口,在main函数中使用return语句表示程序的结束,此时需要注意的是,在非main函数中使用return语句不代表程序的结束,只能代表函数的调用结束
演示:
- 源代码
- 实验结果

- 在程序中的任何地方使用
exit()函数
exit()函数表示终止程序,在程序的任何位置调用exit()函数都可以使程序马上停下来
演示:
- 源代码
- 实验结果
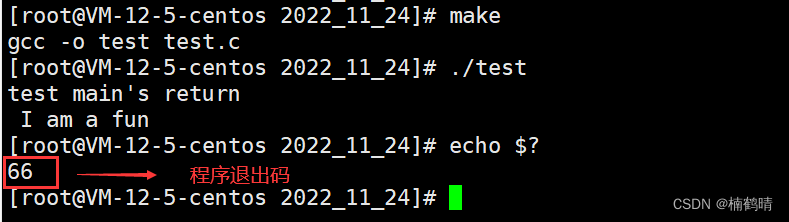
4.exit()和_exit()的使用
- 使用man手册查看:man 2 exit
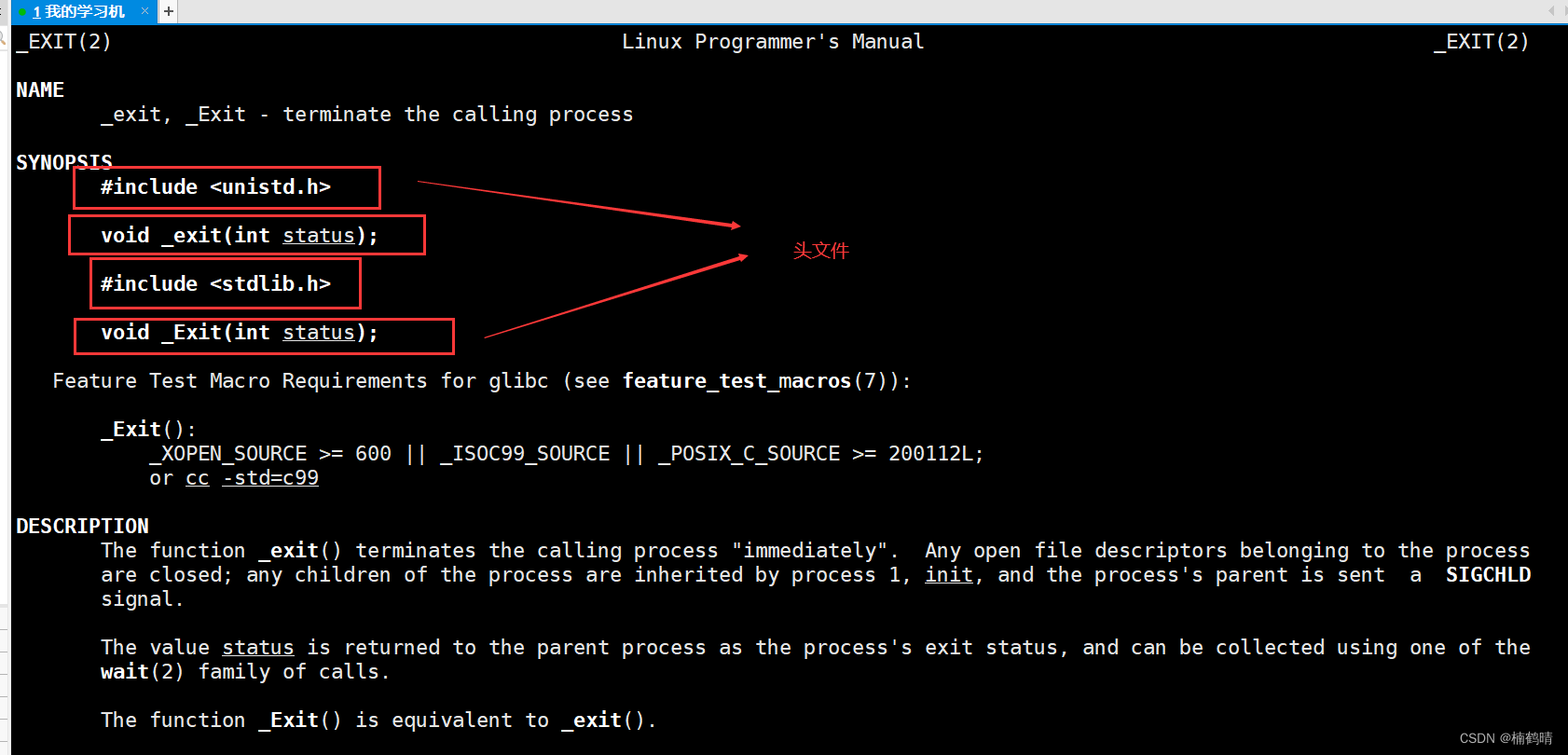
(1)实验:验证exit()和_exit()的区别
- 使用exit()
- 源代码
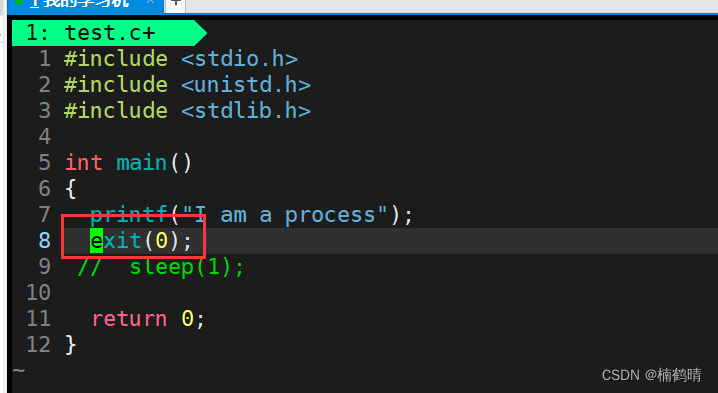
- 实验结果

- 使用_exit()
- 源代码
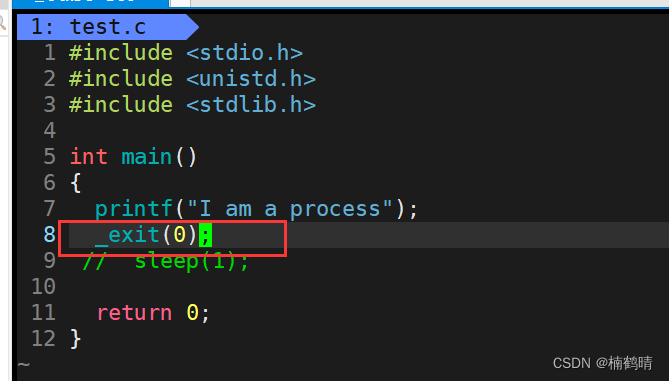
- 实验结果

结论:我们知道,我们使用printf语句进行打印的时候,打印的内容首先是会暂存在缓冲区,不会马上就刷新到外设上的,上面的两个实验分别使用exit()函数和_exit()函数操作这段代码,结果我们发现,当我们使用exit()函数的时候,缓冲区的东西能够刷新到显示屏上,而当我们使用_exit()函数的时候,缓冲区的内容无法刷新到显示屏上,从而我们会发现,exit()函数在终止程序的时候会刷新缓冲区,_exit()函数在终止程序的时候不会刷新缓冲区
(2)exit()和_exit()的区别
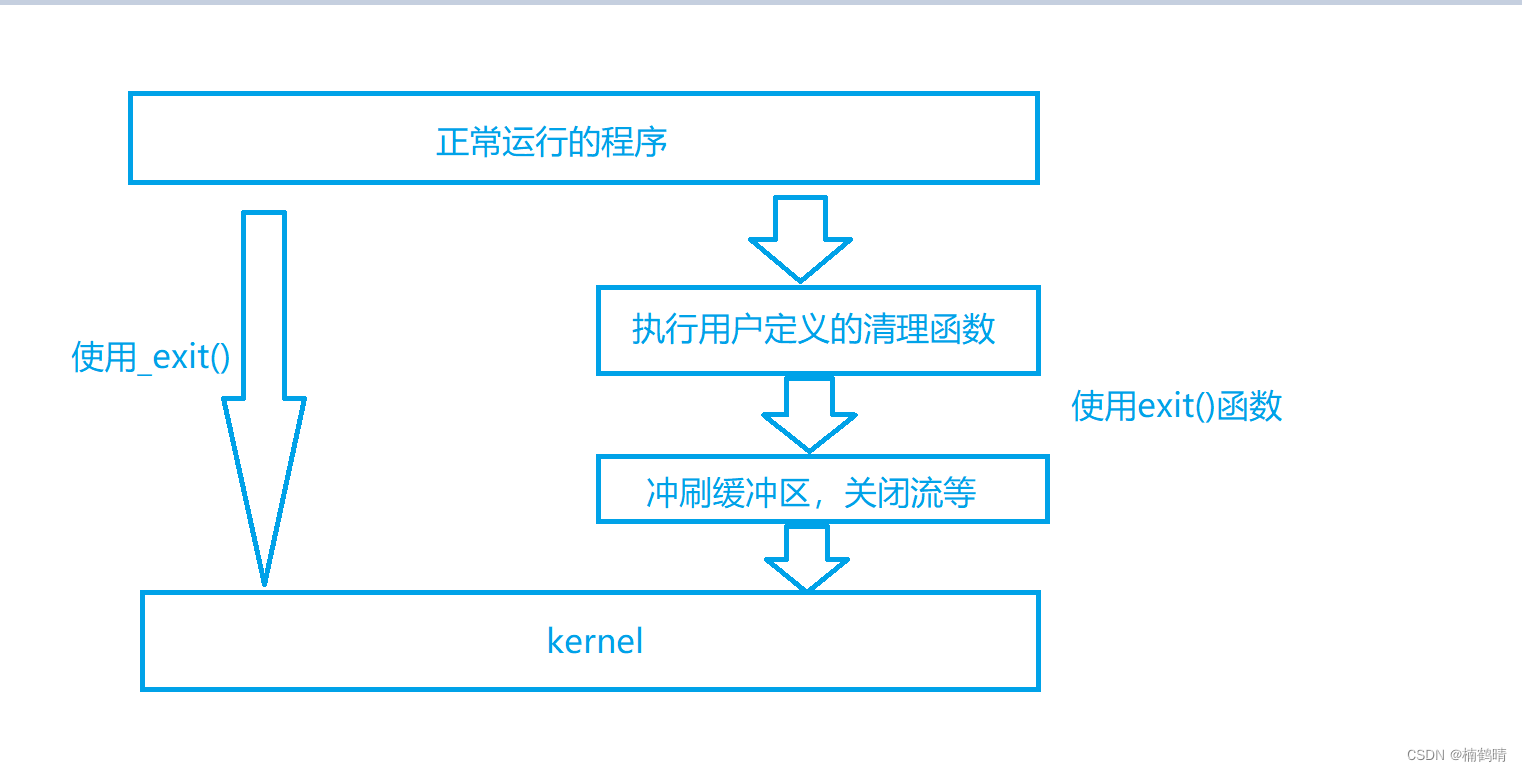
通过上图我们会发现,调用_exit()函数时,只会直接终止程序,不会做任何事情,调用exit()时,会执行用户定义的清理函数和刷新缓冲区和关闭对应的流,因此,一般情况下,我们常用的是exit()函数
5.关于终止,内核做了啥?
我们知道,一个进程是由自己的内核数据结构和进程代码和数据组成的,当一个进程退出的时候,首先自己的进程状态会变成Z状态,也就是所谓的僵尸状态,此时需要等其父进程对其进程回收,由终止我们知道其需要给其父进程返回退出码,这个进程的状态马上变成X状态,其父进程的相关代码会回收(释放)其数据和相关代码,因为当该进程终止的时候,其数据和代码已经没有任何意义了,但是需要注意的是管理这个进程的内核数据结构可能不会被释放,这个内核数据结构在系统内存充足的时候会被加入一个链表,这个链表叫做废弃数据结构链表,专门收集终止的进程的内核数据结构,也叫数据结构缓冲池,或者slap分派器
三、进程等待
1.进程等待的原因
- 解决进程僵尸的问题
一个进程退出的时候会进入僵尸状态,处于僵尸状态的进程无法再次被杀掉,但是其自身的代码和数据以及相关的内核数据结构仍然会占用系统的内存资源,如果进程长期处于僵尸状态,则会长期占用系统内存中的相关资源进而导致内存泄露 - 获取进程的退出信息(退出码和异常信号)
我们学习进程终止的时候知道,进程在退出的时候会有相关的退出码或者异常信号,一个进程创建了子进程是为了完成相关事情的,一个进程在其终止时理应当告诉其父进程自己的工作完成地怎么样了,是成功还是失败,进程就是通过退出码或者异常信号告诉其父进程这些信息的
2.进程等待的方法
(1)wait()函数
- 使用man手册查看wait()的使用方法
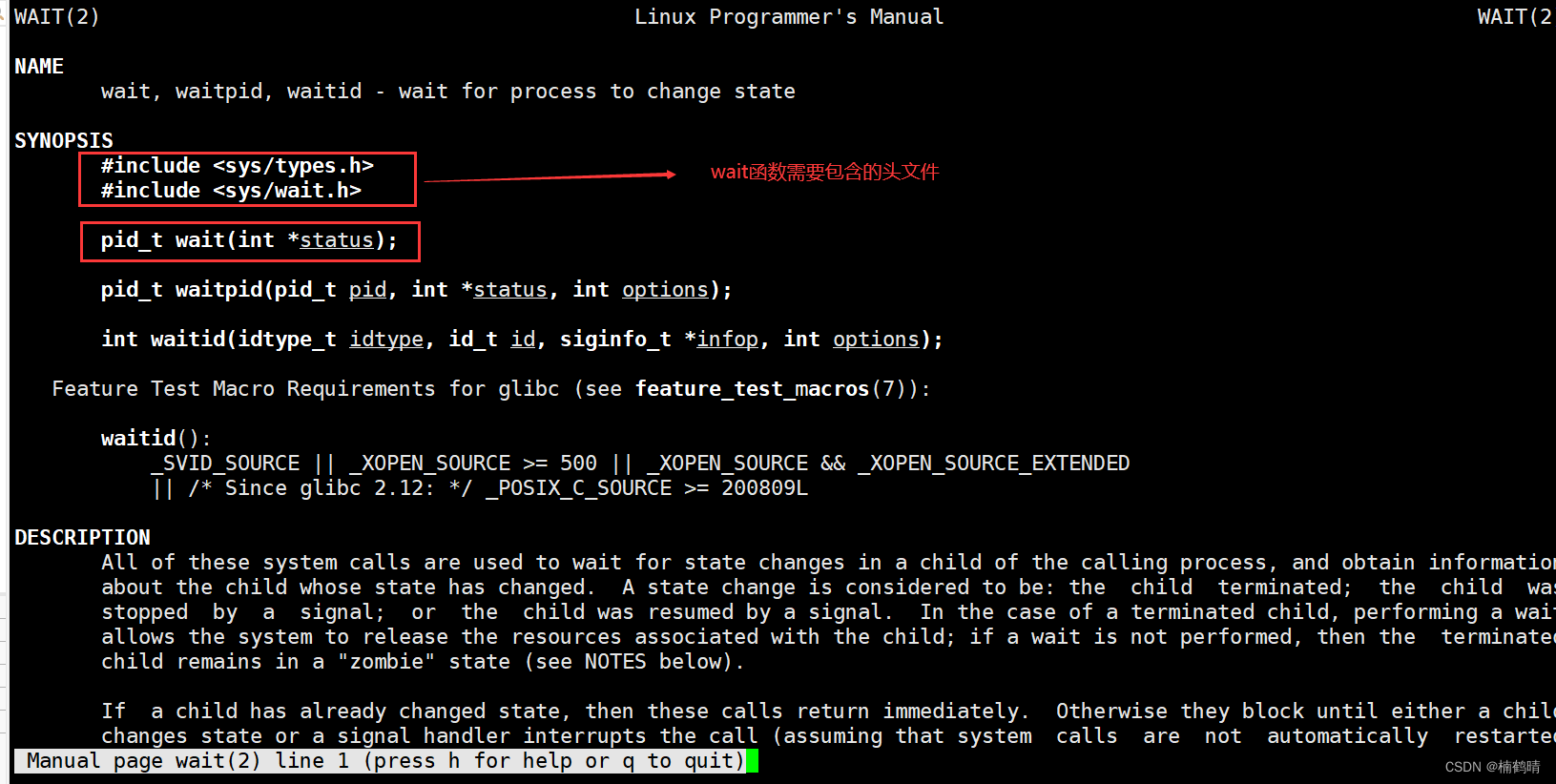
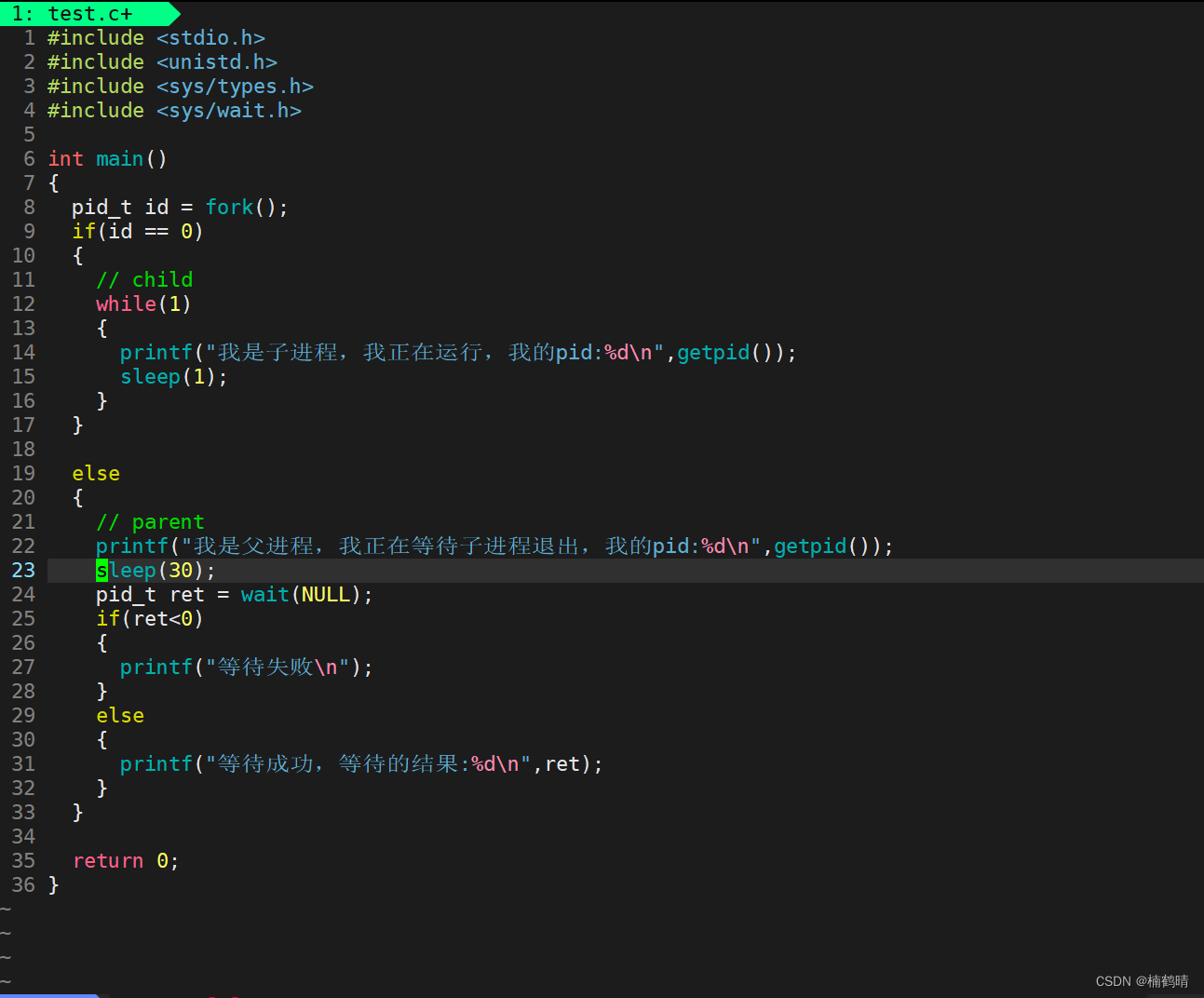
wait()函数有一个参数是int* status;当我们的参数传成NULL的时候,那么这个调用这个函数的进程就可以等待任何进程了,wait函数的返回值是等待的进程的pid,如果等待成功,那么会返回等待进程的Pid,如果等待失败,则会返回-1
上面的代码的逻辑很简单:首先使用原来的进程创建一个子进程,然后我们明确,在成功创建子进程后两个进程是同时存在的,同时在执行程序中的代码,其意思就是要在子进程被杀死的时候父进程要调用wait函数来等待子进程,那么当子进程被杀死的时候,子进程的状态马上就会变成僵尸状态,那么此时父进程就会回收子进程的退出信息,回收之后,子进程就会消失,父进程正常执行其后面的代码,直至退出
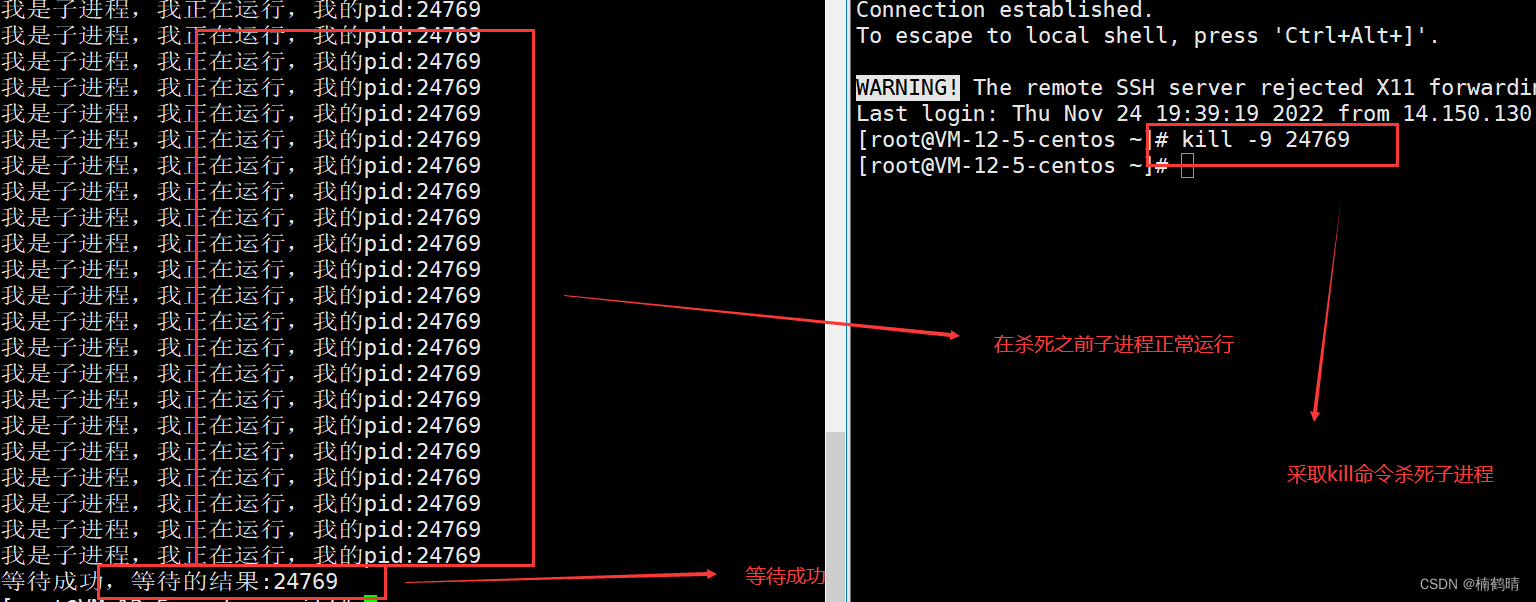
(2)waitpid()函数
-
使用man手册查看使用方法
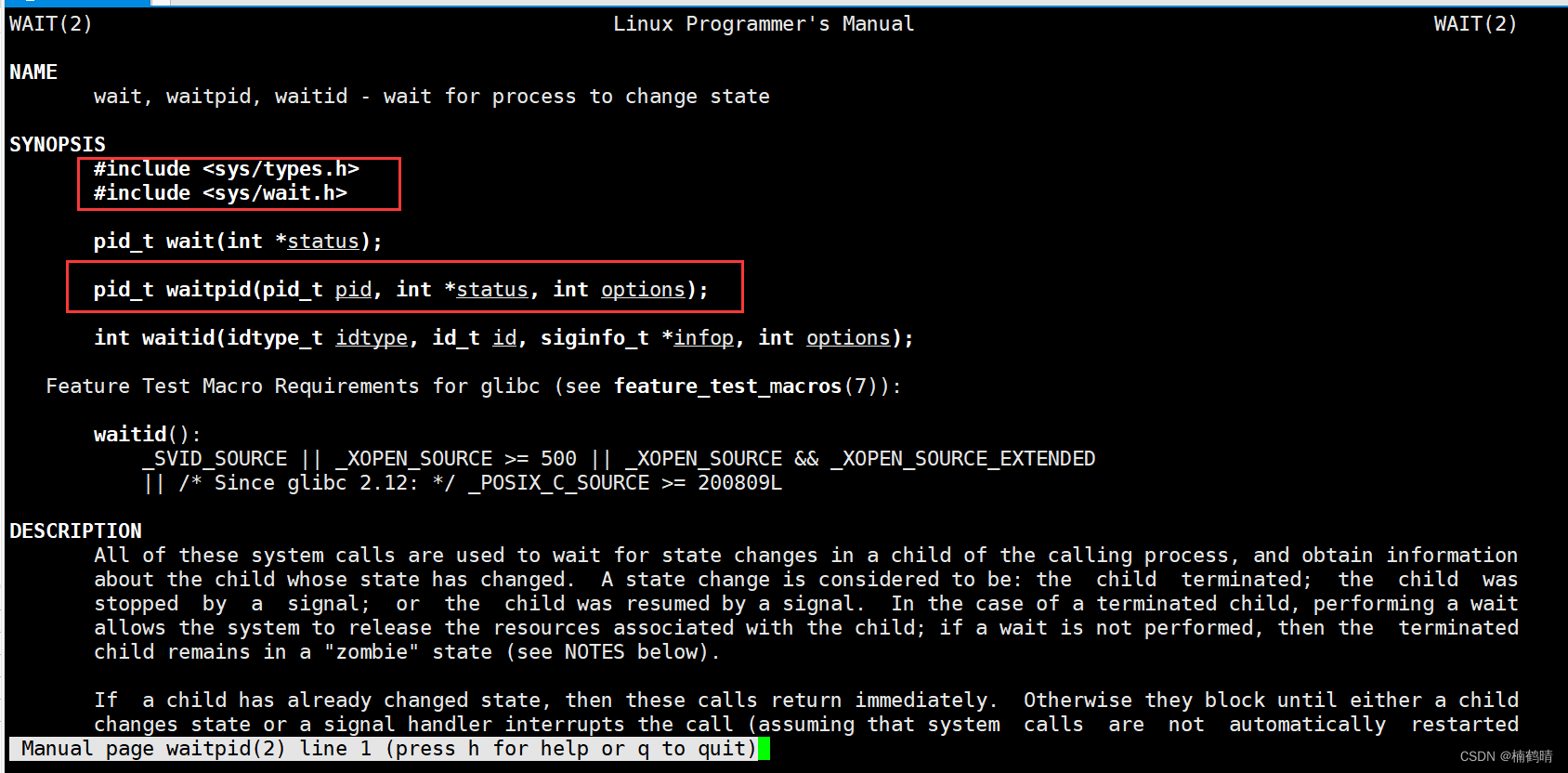
-
返回值:如果返回值的结果大于0,则说明等待成功,返回值为等待的进程的pid,如果返回值的结果小于0,则说明等待失败
-
参数pid_t pid:等待的进程的pid
-
参数int status*:这个参数是一个输出型参数,可以将系统中的一些数据带出来,通常包含等待进程的退出码或者是异常信号
-
参数int option:现在先写0,表示阻塞等待,现在先不考虑非阻塞等待
-
waitpid()函数的使用
- 构建项目
- 创建test.c和makefile文件
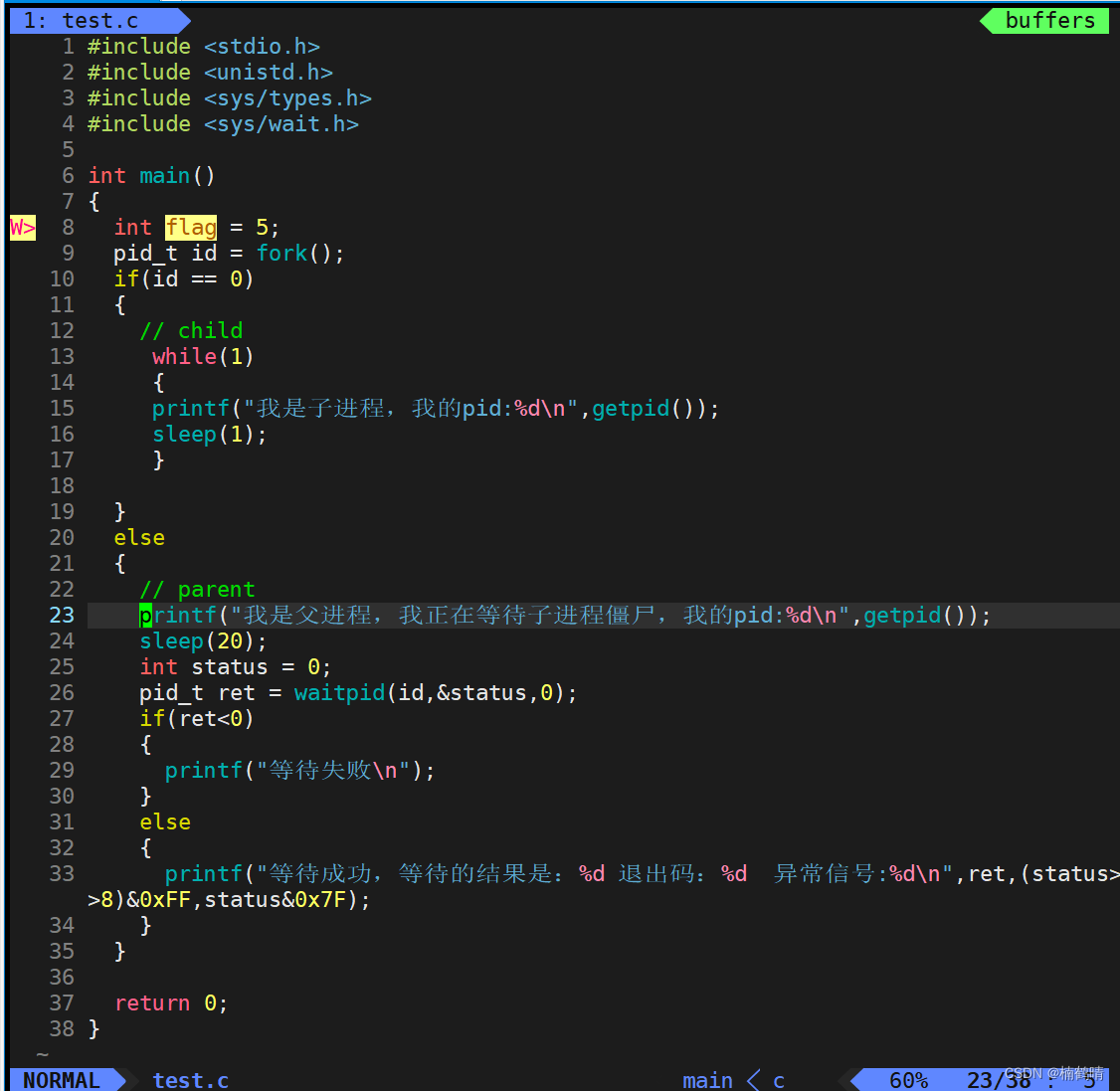
- 实验结果
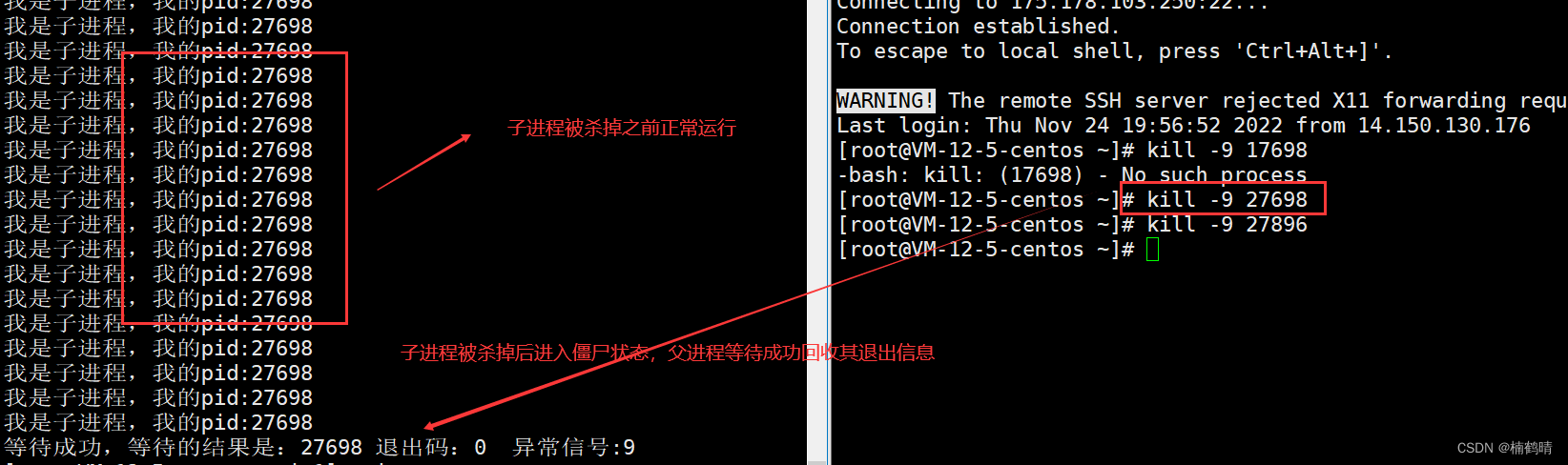
实验思路:利用一个进程创建一个子进程,这个实验中,因为在子进程中有睡眠1秒,所以在子进程正常运行的过程中,子进程的状态为S状态,此时父进程正在等待子进程被杀掉,当子进程被kill命令杀掉的时候,那么父进程此时就会回收子进程的退出信息,子进程再正常释放,父进程继续执行后面的代码
注意:关于子进程的退出码和异常信号现在先记住写法:退出码就是(status>>8)&0xFF,异常信号是status&0x7F
总结
在这篇文章中首先我们学习了使用fork()函数来创建一个子进程和写时拷贝技术解决父子进程数据问题,然后就是进程终止和进程等待,进程终止主要是讲了使用exit()函数来终止一个进程,进程等待主要是为了解决僵尸进程的问题,回收僵尸进程的退出信息