
【C++】stack/queue/list
文章目录
- 注意事项
- 1 emplace 与 push 的区别
- 一、stack(栈)(先进后出、【头部插入、删除】、不许遍历)
- 1 基本概念(栈是自顶向下(top在下),堆是向上)
- 2 stack 常用接口(构造函数、赋值操作、数据存储、empty、size)
- 二、queue (队列)(先进先出、【头部删除、尾部插入】、不许遍历)
- 1 queue 基本概念[kju:]
- 2 queue 常用接口(构造函数、赋值操作、数据存储、empty、size)
- 3 priority_queue
- 3.1 用pair<int,int>建立优先队列(小根堆)
- 三、list(最常用)(双向迭代器、单向链表/双向循环链表、可以遍历)
- 1 list基本概念(插入删除效率高,随机存储不行)
- 2 list构造函数(默认构造、区间拷贝、n个元素拷贝、拷贝)
- 3 list 赋值和交换(operator=、assign、swap)
- 4 list 大小操作 (size、emply、resize) (无容量capacity)
- 5 list 插入和删除 (insert、erase、remove(移除指定数据)、clear)(迭代器找位置)
- 6 list 数据存取(front、back、不支持[ ]和at的方式)(迭代器找位置)
- 7 list 反转和排序(L.reverse()(反转)、L.sort()(排序,链表内部提供))
注意事项
注意:
- 所有不支持随机访问迭代器的容器,不可以用标准算法(自带的全局函数)(
eg. sort()) - stack 和 queue(priority_queue) 不支持 clear() 函数
while (!que.empty()) // 有clear()功能
{ que.pop();
}
1 emplace 与 push 的区别
1.直接传入对象(int, double 或者 构造好了的对象)
//假设栈内的数据类型是data
class data {int a;int b;
public:data(int x, int y):a(x), b(y) {}
};
//push
data d(1,2);
stack S;
S.push(d) 或 S.emplace(d);
2.在传入时候构造对象
S.push(data(1,2));
S.emplce(data(1,2));
3.emplace可以直接传入构造对象需要的元素,然后自己调用其构造函数!
S.emplace(1,2)
意思是,emplace这样接受新对象的时候,自己会调用其构造函数生成对象然后放在容器内(比如这里传入了1,2,它则会自动调用一次data(1,2)),而push,只能让其构造函数构造好了对象之后,再使用拷贝构造函数!相当于emplace直接把原料拿进家,造了一个。而push是造好了之后,再复制到自己家里,多了复制这一步。所以emplace相对于push,使用第三种方法会更节省内存。
注意:
emplace_back(type) 对应 push_back(type)
emplace(i, type) 对应于 insert(type, i)
emplace_front(type) 对应于 push_front()
一、stack(栈)(先进后出、【头部插入、删除】、不许遍历)
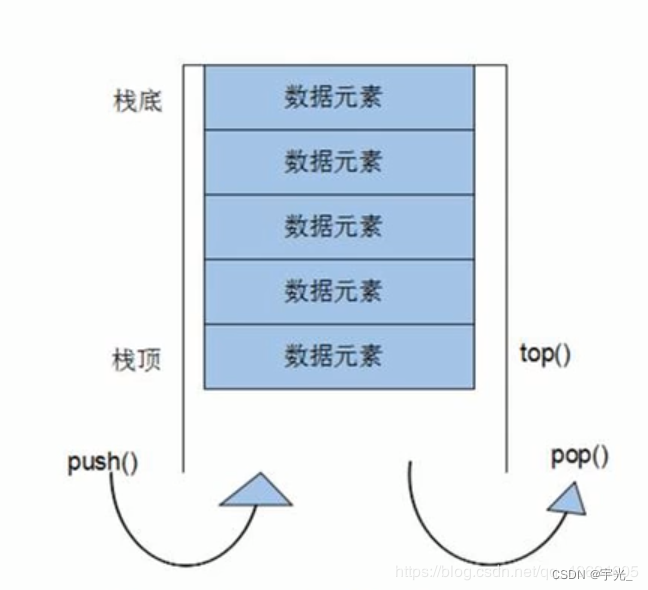
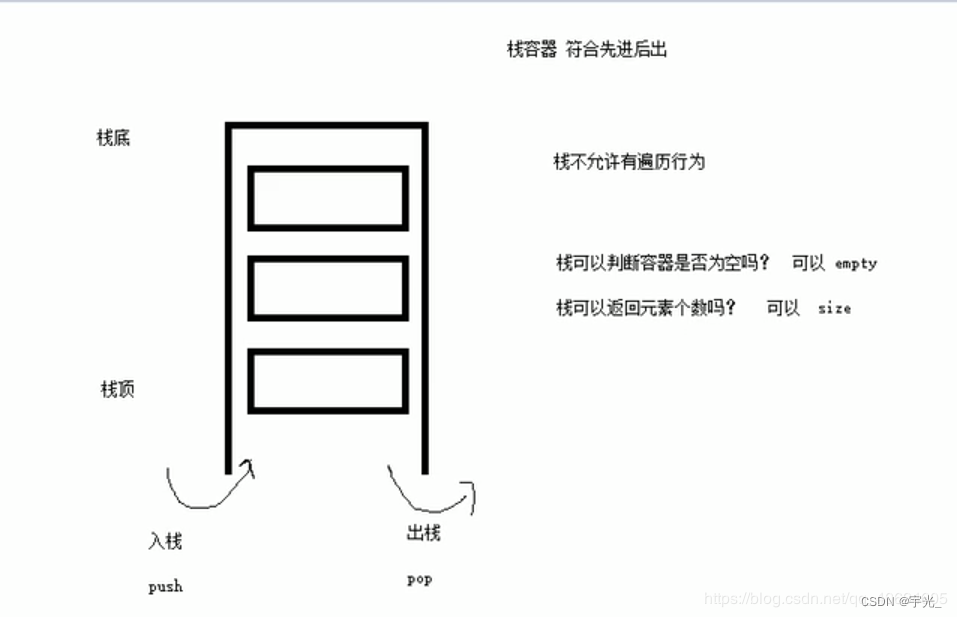
1 基本概念(栈是自顶向下(top在下),堆是向上)
- stack是一种先进后出(First In Last Out,FILO)的数据结构,它只有一个出口(栈容器)
- 栈中只有顶端向下的元素才可以被外界使用,因此栈不允许有遍历行为
栈中进入数据称为 ——入栈 s.push()
栈中弹出数据称为 ——出栈 s.pop()
2 stack 常用接口(构造函数、赋值操作、数据存储、empty、size)
//构造函数
stack s; //stack采用类模板实现, stack对象的默认构造形式
stack s1(s); //拷贝构造函数
//赋值操作
s=s1; //重载等号操作符
//数据存取
s.push(40); //向栈顶添加元素
s.pop(); //从栈顶移除第一个元素
s.top() //返回栈顶元素值
//大小操作
s.empty() //判断堆栈是否为空
s.size() //返回栈的大小(元素个数)
#include //栈容器常用接口
void test01()
{//特点:符合先进后出数据结构stack s;//向栈中添加元素,叫做 压栈 入栈s.push(10);s.push(20);s.push(30);s.push(40);cout << "栈的大小为:" << s.size() << endl;//只要栈不为空,查看栈顶,并且执行出栈操作while (!s.empty()) {//输出栈顶元素cout << "栈顶元素为: " << s.top() << endl;//弹出栈顶元素s.pop();}cout << "栈的大小为:" << s.size() << endl;}int main() {test01();system("pause");return 0;
}
二、queue (队列)(先进先出、【头部删除、尾部插入】、不许遍历)
1 queue 基本概念[kju:]
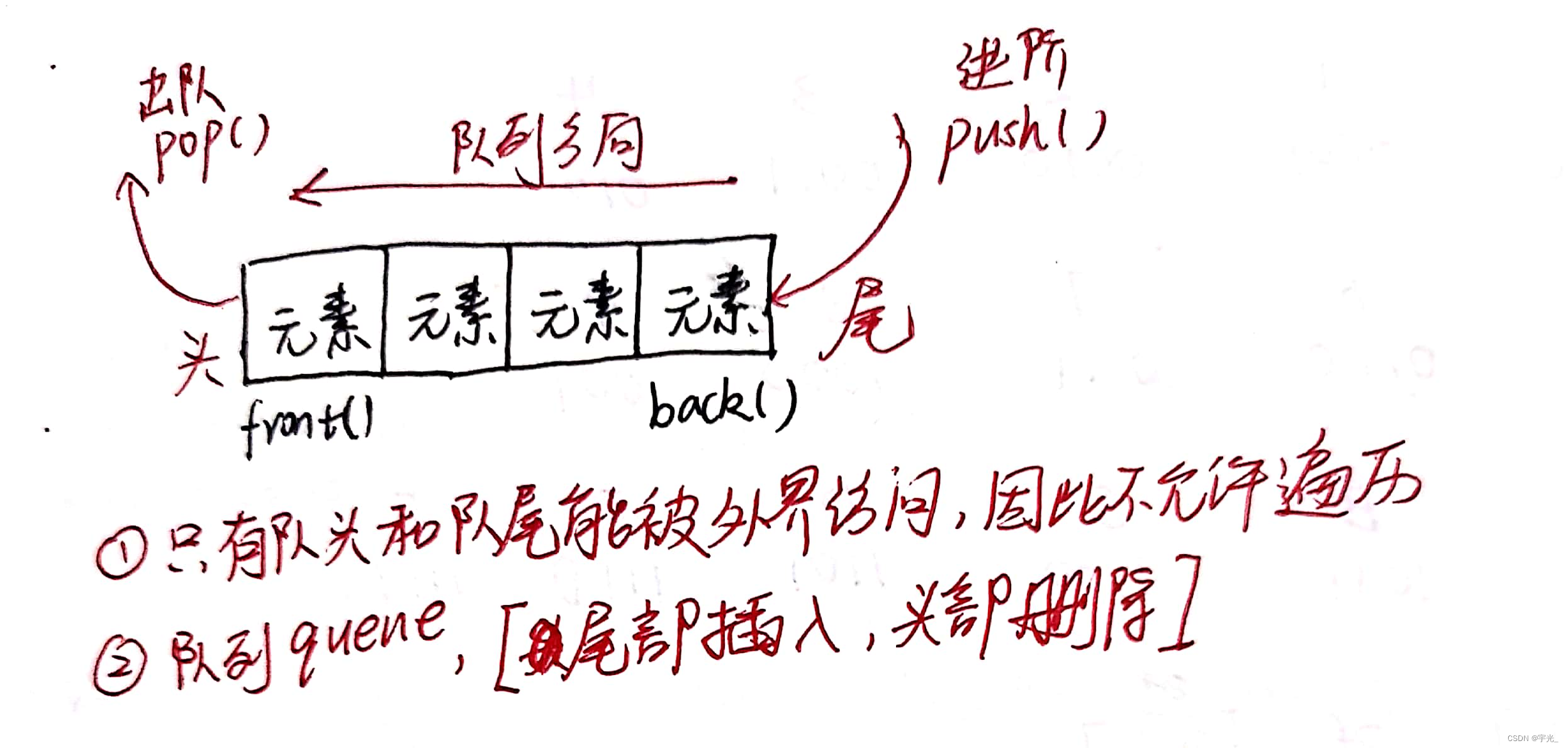
- Queue是一种先进先出(First In First Out,FIFO)的数据结构,它有两个出口(队列容器)
- 队列容器允许从队尾新增元素,从另队头移除元素
- 队列中只有队头和队尾才可以被外界使用,因此队列不允许有遍历行为
队列中进数据称为 — 入队 q.push()
队列中出数据称为 — 出队 q.pop()
2 queue 常用接口(构造函数、赋值操作、数据存储、empty、size)
//构造函数
queue q; //queue采用类模板实现,queue对象的默认构造形式
queue q1(q); //拷贝构造函数
//赋值操作
q=q1; //重载等号操作符
//数据存取
q.push(p1); //往队尾添加元素
q.pop(); //从队头移除第一个元素
q.back(); //返回最后一个元素值
q.front() //返回第一个元素值
//大小操作
q.empty() //判断堆栈是否为空
q.size() //返回栈的大小
#include
#include class Person
{
public:Person(string name, int age){this->m_Name = name;this->m_Age = age;}string m_Name;int m_Age;
};//队列 Queue
void test01() {//创建队列queue q;//准备数据Person p1("唐僧", 30);Person p2("孙悟空", 1000);Person p3("猪八戒", 900);Person p4("沙僧", 800);//向队列中添加元素 入队操作q.push(p1);q.push(p2);q.push(p3);q.push(p4);//队列不提供迭代器,更不支持随机访问 while (!q.empty()) {//输出队头元素cout << "队头元素-- 姓名: " << q.front().m_Name<< " 年龄: " << q.front().m_Age << endl;cout << "队尾元素-- 姓名: " << q.back().m_Name<< " 年龄: " << q.back().m_Age << endl;cout << endl;//弹出队头元素q.pop();}cout << "队列大小为:" << q.size() << endl;
}int main() {test01();system("pause");return 0;
}
3 priority_queue
3.1 用pair<int,int>建立优先队列(小根堆)
- 比较对象是pair的第一个元素
priority_queue,vector>,greater>>pq;
- 取元素
1.pq.top().first;
2.pq.top().second;
三、list(最常用)(双向迭代器、单向链表/双向循环链表、可以遍历)
1 list基本概念(插入删除效率高,随机存储不行)
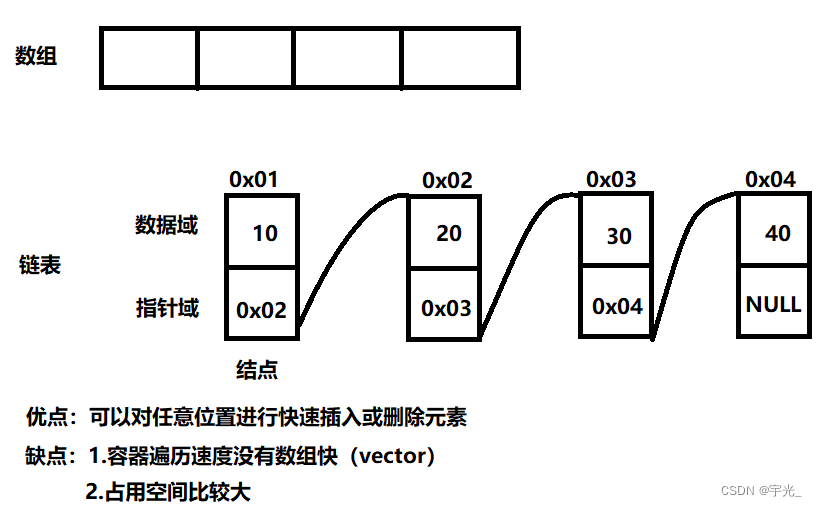
- 链表(list):是一种物理存储单元上非连续的存储结构,数据元素的逻辑顺序是通过链表中的指针链接实现的(指针域)
- STL中的链表是一个双向循环链表,由于链表的存储方式并不是连续的内存空间,因此链表list中的迭代器只支持前移和后移,属于双向迭代器,只支持it++、it-- ,不支持 it = it + 1(不能跳跃式的访问)
(1)链表的组成:链表由一系列结点组成
(2)结点的组成:一个是存储数据元素的数据域,一个是存储下一个结点地址的指针域
(3)list的优点:
- 采用动态存储分配,不会造成内存浪费和溢出
- 链表执行插入和删除操作十分方便,修改指针即可,不需要移动大量元素
(4)list的缺点:
- 容器遍历速度没有数组快
- 链表灵活,但是空间(指针域) 和 时间(遍历)额外耗费较大
(5)List有一个重要的性质:
- 插入操作和删除操作都不会造成原有list迭代器的失效,这在vector是不成立的(vector会从新找一块更长的存储空间,原有迭代器失效)
总结:STL中List和vector是两个最常被使用的容器,各有优缺点
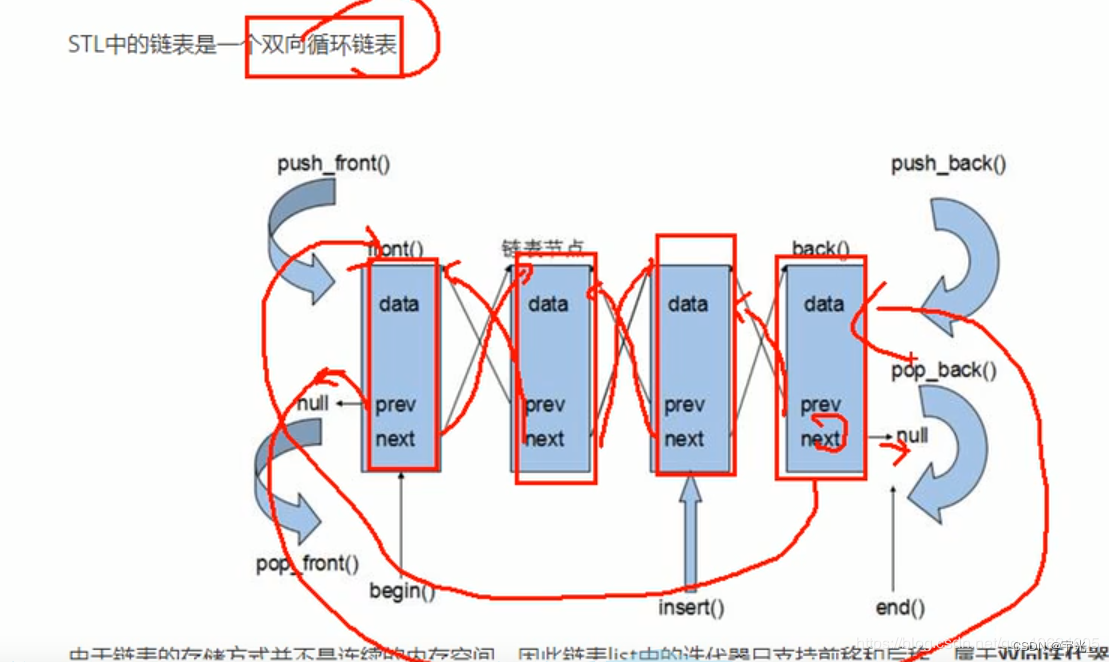
- 两个指针,next指针指向下一个节点,prev指针指向上一个节点(双向)
- 最后一个节点记录第一个节点的位置,前一个节点记录最后一个节点的位置(循环)
2 list构造函数(默认构造、区间拷贝、n个元素拷贝、拷贝)
listL1; //list采用类模板实现,对象的默认构造形式:
listL2(L1.begin(), L1.end()); //构造函数将[beg, end)区间中的元素拷贝给本身。
listL4(5, 10); //构造函数将5个10拷贝给本身
listL3(L2); //拷贝构造函数。
//list容器的构造
void printList(const list& L) {//只读迭代器for (list::const_iterator it = L.begin(); it != L.end(); it++) {cout << *it << " ";}cout << endl;
}void test01()
{//创建list容器listL1;//默认构造//添加数据L1.push_back(10);L1.push_back(20);L1.push_back(30);L1.push_back(40);printList(L1);//区间方式listL2(L1.begin(), L1.end());printList(L2);//拷贝构造listL3(L2);printList(L3);//n个elemlistL4(10, 1000);printList(L4);
}int main() {test01();system("pause");return 0;
}
3 list 赋值和交换(operator=、assign、swap)
//assign 赋值函数
L3.assign(L2.begin(), L2.end()); //将[beg, end)区间中的数据拷贝赋值给本身。
L4.assign(10, 100); //将n个elem拷贝赋值给本身。
//operator= 重载
L2 = L1; //重载等号操作符
//swap 互换函数
L1.swap(L2); //将L1与L2的元素互换。
4 list 大小操作 (size、emply、resize) (无容量capacity)
//(无容量capacity)
L1.size() //返回容器中元素的个数
L1.empty() //判断容器是否为空//resize 重新指定容器的长度(大小)
L1.resize(10); //10个0
//重新指定容器的长度为10,若容器变长,则以默认值0填充新位置。
//如果容器变短,则末尾超出容器长度的元素被删除。
L1.resize(10,1000); //10个1000
//重新指定容器的长度为10,若容器变长,则以1000值填充新位置。
//如果容器变短,则末尾超出容器长度的元素被删除。
5 list 插入和删除 (insert、erase、remove(移除指定数据)、clear)(迭代器找位置)
- 最好把链表当作动态的双端数组(deque)来使用,只访问或者增删头端或者尾端的数据,这样速度快
//it表示某个迭代器,n为整数。该函数的功能是将it迭代器前进或后退n个位置。
//n为正数时表示将it右移(前进)n个位置,n为负数时表示将it左移(后退)n个位置
#include
using namespace std;
advance(it, n); // 要判断 n 是否越界 (双向循环链表也要防止越界) Data.insert(it, tem2); //插入数据
Data.erase(it); //删除数据
//两端插入、删除操作
L.push_back(10); //在容器尾部加入一个元素
L.pop_back(); //删除容器中最后一个元素
L.push_front(100); //在容器开头插入一个元素
L.pop_front(); //从容器开头移除第一个元素//insert 指定位置插入
list::iterator it;
L.insert(it, 10); //在迭代器位置插10元素,返回新数据的位置。
L.insert(it, 2, 10); //在迭代器位置插入2个10数据,无返回值。
L.insert(it, L2.begin(), L2.end()); //在迭代器位置插入[beg,end)区间的数据,无返回值。//erase 指定位置删除
L.erase(L.begin(), L.end()); //删除[beg,end)区间的数据,返回下一个数据的位置。
L.erase(it); //删除迭代器位置的数据,返回下一个数据的位置。//remove 移除指定数据(特有)
L.remove(100); //删除容器中所有与100值匹配的元素。//clear 清除所有元素
L.clear(); //移除容器的所有数据
6 list 数据存取(front、back、不支持[ ]和at的方式)(迭代器找位置)
- 不支持[ ]和at的方式。因为list链表存储方式不是连续的,它的迭代器不支持随机访问,是双向迭代器,只能前移后移,无法跳跃式访问(不支持 it = it + 1)。
//不支持[ ]和at的方式
L.front() //返回第一个元素。
L.back() //返回最后一个元素。//只支持it++、it-- ,不支持 it = it + 1;
//双向迭代器,不可以跳跃访问,即使是+1
list::iterator it = L.begin();
int a = *it; //返回迭代器所在的位置
//数据存取
void test01()
{listL1;L1.push_back(10);L1.push_back(20);L1.push_back(30);L1.push_back(40);//cout << L1.at(0) << endl;//错误 不支持at访问数据//cout << L1[0] << endl; //错误 不支持[]方式访问数据//不支持随机访问迭代器cout << "第一个元素为: " << L1.front() << endl;cout << "最后一个元素为: " << L1.back() << endl;//list容器的迭代器是双向迭代器,不支持随机访问list::iterator it = L1.begin();it++;//只能++,--//it = it + 1;//错误,不可以跳跃访问,即使是+1
}int main() {test01();system("pause");return 0;
}
7 list 反转和排序(L.reverse()(反转)、L.sort()(排序,链表内部提供))
L.reverse(); //反转链表
L.sort(); //链表排序//默认排序规则从小到大
- 注意:所有不支持随机访问迭代器的容器,不可以用标准算法(自带的全局函数)
void printList(const list& L) {for (list::const_iterator it = L.begin(); it != L.end(); it++) {cout << *it << " ";}cout << endl;
}//回调函数
bool myCompare(int val1, int val2)
{//降序,就让第一个数大于第二个数return val1 > val2;
}//list容器反转和排序
//反转
void test01()
{list L;L.push_back(90);L.push_back(30);L.push_back(20);L.push_back(70);cout << "反转前: " << endl;printList(L);//反转容器的元素L.reverse();cout << "反转后: " << endl;printList(L);}
//排序
void test02()
{list L;L.push_back(90);L.push_back(30);L.push_back(20);L.push_back(70);cout << "排序前: " << endl;printList(L);//所有不支持随机访问迭代器的容器,不可以用标准算法//不支持随机访问迭代器的容器,内部会提供对应一些算法L.sort();//默认排序规则从小到大cout << "排序后:" << endl;printList(L);L.sort(myCompare); //写一个回调函数,从大到小printList(L);}
int main() {test01();test02();system("pause");return 0;
}
8、C++ STL 中list是双向循环链表,双向可以理解,有两个指针域,指向前一结点和指向后一结点,双向可以实现从末尾结点到头结点的遍历,但循环实现什么功能?
#include
#include
int main()
{list li;for (int i = 0; i < 5; ++i){li.push_back(i);}list::iterator it = li.end();cout << *(--it); //输出4cout << *(++it); //若为循环链表,不是应该回到头结点吗?实际输出错误!//若为循环链表,那end()是指向哪里?return 0;
}
-
一个node结构自己是不知道自己是list中的第几个(没有储存相应的信息)。但是,最末一个node,它的后指针是指向链表的终结记号,然后终结记号的node也有一个指针,才指向list的第一个node。所以,++it指向的是终结记号,上面是没有数据的,当然输出错误。
-
双向的意思是:你可以在首端加入新的数据node,也可以在末端加入新的数据node,但不表示你可以无限循环的遍历它。另外,List模板,不建议你使用iterator(迭代器),因为每一个node都不知道自己是第几个node,如果你使用迭代器指定你要访问第n个node的数据,它总是从首元素开始一个个数到第n,然后才返回数据给你。最好把链表当作动态的双端数组(deque)来使用,只访问或者增删头端或者尾端的数据,这样速度快