
机器学习笔记之配分函数(二)——随机最大似然
机器学习笔记之配分函数——随机最大似然
- 引言
- 回顾:对数似然梯度
- 关于∇θL(θ)\nabla_{\theta}\mathcal L(\theta)∇θL(θ)的简化
- 基于MCMC求解负相
- 关于书中图像的解释
引言
上一节介绍了对包含配分函数的概率分布——使用极大似然估计求解模型参数的梯度(对数似然梯度),本节将基于上述结论,介绍随机最大似然(Stochastic Maximum Likelihood)。
回顾:对数似然梯度
已知样本集合X={x(i)}i=1N\mathcal X = \{x^{(i)}\}_{i=1}^NX={x(i)}i=1N,且随机变量X={x1,⋯,xp}\mathcal X = \{x_1,\cdots,x_p\}X={x1,⋯,xp}在ppp维实数域上有意义(X∈Rp\mathcal X \in \mathbb R^pX∈Rp)。
ML Learning : \text{ML Learning : }ML Learning : 针对包含配分函数的概率模型P(X;θ)\mathcal P(\mathcal X;\theta)P(X;θ)中对模型参数θ\thetaθ进行求解。以极大似然估计为例,最优模型参数θ^\hat \thetaθ^表示如下:
θ^=argmaxθlog∏i=1NP(x(i);θ)=argmaxθ∑i=1Nlog[1Z(θ)P^(x(i);θ)]=argmaxθ∑i=1N[logP^(x(i);θ)−logZ(θ)]\begin{aligned} \hat \theta & = \mathop{\arg\max}\limits_{\theta} \log \prod_{i=1}^N \mathcal P(x^{(i)};\theta) \\ & = \mathop{\arg\max}\limits_{\theta} \sum_{i=1}^N \log \left[\frac{1}{\mathcal Z(\theta)} \hat \mathcal P(x^{(i)};\theta)\right] \\ & = \mathop{\arg\max}\limits_{\theta} \sum_{i=1}^N \left[\log \hat \mathcal P(x^{(i)};\theta) - \log \mathcal Z(\theta)\right] \end{aligned}θ^=θargmaxlogi=1∏NP(x(i);θ)=θargmaxi=1∑Nlog[Z(θ)1P^(x(i);θ)]=θargmaxi=1∑N[logP^(x(i);θ)−logZ(θ)]
其中P^(X;θ)\hat \mathcal P(\mathcal X;\theta)P^(X;θ)表示不包含配分函数的概率模型结果;Z(θ)\mathcal Z(\theta)Z(θ)表示配分函数(Partition Function),假设X\mathcal XX是连续型随机变量,配分函数可表示为:
Z(θ)=∫XP^(X;θ)dX=∫x1,⋯,∫xpP^(x1,⋯,xp;θ)d(x1,⋯,xp)\begin{aligned} \mathcal Z(\theta) & = \int_{\mathcal X} \hat \mathcal P(\mathcal X;\theta) d\mathcal X \\ & = \int_{x_1},\cdots,\int_{x_p} \hat \mathcal P(x_1,\cdots,x_p;\theta) \text{ } d(x_1,\cdots,x_p) \end{aligned}Z(θ)=∫XP^(X;θ)dX=∫x1,⋯,∫xpP^(x1,⋯,xp;θ) d(x1,⋯,xp)
将上式进行整理,可表示为如下表达:
{L(θ)=1N∑i=1NlogP^(x(i);θ)−logZ(θ)θ^=argmaxθL(θ)\begin{cases} \mathcal L(\theta) = \frac{1}{N} \sum_{i=1}^N \log \hat \mathcal P(x^{(i)};\theta) - \log \mathcal Z(\theta) \\ \quad \\ \hat \theta = \mathop{\arg\max}\limits_{\theta} \mathcal L(\theta) \end{cases}⎩⎪⎪⎨⎪⎪⎧L(θ)=N1∑i=1NlogP^(x(i);θ)−logZ(θ)θ^=θargmaxL(θ)
针对最大值的求解,常用方法是梯度上升法。对目标函数L(θ)\mathcal L(\theta)L(θ)关于θ\thetaθ求梯度:
∇θL(θ)=1N∑i=1N∇θlogP^(x(i);θ)−∇θlogZ(θ)\nabla_{\theta}\mathcal L(\theta) = \frac{1}{N} \sum_{i=1}^N \nabla_{\theta} \log \hat \mathcal P(x^{(i)};\theta) - \nabla_{\theta} \log \mathcal Z(\theta)∇θL(θ)=N1i=1∑N∇θlogP^(x(i);θ)−∇θlogZ(θ)
通常将1N∑i=1N∇θlogP^(x(i);θ)\frac{1}{N}\sum_{i=1}^N \nabla_{\theta} \log \hat \mathcal P(x^{(i)};\theta)N1∑i=1N∇θlogP^(x(i);θ)看作正相,将∇θlogZ(θ)\nabla_{\theta} \log \mathcal Z(\theta)∇θlogZ(θ)看作负相。
针对负相计算中的难点,将Z(θ)\mathcal Z(\theta)Z(θ)展开,最终化为期望形式:
∇θlogZ(θ)=EP(X;θ)[∇θlogP^(X;θ)]\nabla_{\theta}\log \mathcal Z(\theta) = \mathbb E_{\mathcal P(\mathcal X;\theta)} \left[\nabla_{\theta} \log \hat \mathcal P(\mathcal X;\theta)\right]∇θlogZ(θ)=EP(X;θ)[∇θlogP^(X;θ)]
最终目标函数梯度∇θL(θ)\nabla_{\theta}\mathcal L(\theta)∇θL(θ)可表示为如下形式:
∇θL(θ)=1N∑i=1N∇θlogP^(x(i);θ)−EP(X;θ)[∇θlogP^(X;θ)]\nabla_{\theta}\mathcal L(\theta) = \frac{1}{N} \sum_{i=1}^N \nabla_{\theta} \log \hat \mathcal P(x^{(i)};\theta) - \mathbb E_{\mathcal P(\mathcal X;\theta)} \left[\nabla_{\theta} \log \hat \mathcal P(\mathcal X;\theta)\right]∇θL(θ)=N1i=1∑N∇θlogP^(x(i);θ)−EP(X;θ)[∇θlogP^(X;θ)]
关于正相部分可以使用如基于Batch/mini-Batch\text{Batch/mini-Batch}Batch/mini-Batch的梯度上升方法(因为样本是给定的);关于负相部分可以使用马尔可夫链蒙特卡洛方法进行近似求解。
关于∇θL(θ)\nabla_{\theta}\mathcal L(\theta)∇θL(θ)的简化
为了将正相与负相的格式统一,也将正相写成期望形式,这里引入一个概率分布——真实分布Pdata\mathcal P_{data}Pdata。
早在第一节极大似然估计与最大后验概率估计介绍过概率模型的概念。一个真实模型Pdata(X;θ)\mathcal P_{data}(\mathcal X;\theta)Pdata(X;θ),可以通过模型参数θ\thetaθ生成无穷无尽的样本,而我们的样本集合X\mathcal XX只是其中的一个 子集。由于噪声的原因,我们可能无法将真实模型的分布精确的求解出来,但可以通过样本集合X\mathcal XX对真实分布进行近似。样本量越多,样本分布结果越接近真实分布。
简单理解为,真实分布是基于问题客观存在的,但是它很‘缥缈’,我们只能得到它的近似结果。
通过已有样本集合X\mathcal XX估计出的‘近似分布’称为‘经验分布’(Empirical Distribution)。
但是在这里,虽然经验分布只是真实分布的一个近似,但是在这里将正相看作是基于真实分布的期望。因为正相确实是通过采样真实样本的方式更新梯度的。
相比之下,概率模型P(X;θ)=1Z(θ)P^(X;θ)\mathcal P(\mathcal X;\theta) = \frac{1}{\mathcal Z(\theta)} \hat \mathcal P(\mathcal X;\theta)P(X;θ)=Z(θ)1P^(X;θ)是基于概率图结构的假设。与Pdata\mathcal P_{data}Pdata相对应,称其为Pmodel\mathcal P_{model}Pmodel。
至此,关于∇θL(θ)\nabla_{\theta}\mathcal L(\theta)∇θL(θ)的简化结果可表示为:
∇θL(θ)=1N∑i=1N∇θlogP^(x(i);θ)−EP(X;θ)[∇θlogP^(X;θ)]=EPdata[∇θlogP^(x(i);θ)]−EPmodel[∇θlogP^(X;θ)]\begin{aligned} \nabla_{\theta}\mathcal L(\theta) & = \frac{1}{N} \sum_{i=1}^N \nabla_{\theta} \log \hat \mathcal P(x^{(i)};\theta) - \mathbb E_{\mathcal P(\mathcal X;\theta)} \left[\nabla_{\theta} \log \hat \mathcal P(\mathcal X;\theta)\right] \\ & = \mathbb E_{\mathcal P_{data}} [\nabla_{\theta} \log \hat \mathcal P(x^{(i)};\theta)] - \mathbb E_{\mathcal P_{model}} [\nabla_{\theta} \log \hat \mathcal P(\mathcal X;\theta)] \end{aligned}∇θL(θ)=N1i=1∑N∇θlogP^(x(i);θ)−EP(X;θ)[∇θlogP^(X;θ)]=EPdata[∇θlogP^(x(i);θ)]−EPmodel[∇θlogP^(X;θ)]
之所以称EPdata[∇θlogP^(x(i);θ)]\mathbb E_{\mathcal P_{data}} [\nabla_{\theta} \log \hat \mathcal P(x^{(i)};\theta)]EPdata[∇θlogP^(x(i);θ)]为正相,是因为 正向的增加了∇θL(θ)\nabla_{\theta}\mathcal L(\theta)∇θL(θ)梯度上升的过程;相反,由于负相EPmodel[∇θlogP^(X;θ)]\mathbb E_{\mathcal P_{model}} [\nabla_{\theta} \log \hat \mathcal P(\mathcal X;\theta)]EPmodel[∇θlogP^(X;θ)]的增加使得∇θL(θ)\nabla_{\theta}\mathcal L(\theta)∇θL(θ)梯度上升的过程放缓(起到反作用)。
基于MCMC求解负相
之前介绍过了,如果负相能够轻松地求解出结果,那么可以直接使用梯度上升法(Gradient Ascent)对模型参数θ\thetaθ进行近似求解:
η\etaη表示学习率~
θ(t+1)⇐θ(t)+η∇θL(θ)\theta^{(t+1)} \Leftarrow \theta^{(t)} + \eta \nabla_{\theta} \mathcal L(\theta)θ(t+1)⇐θ(t)+η∇θL(θ)
如果负相无法求解出精确结果,那么通常采用马尔可夫链蒙特卡洛方法,如吉布斯采样(Gibbs Sampling)进行求解。
而这个采样过程本质上是迭代过程。否则就是从分布Pmodel=P(X;θ)\mathcal P_{model} = \mathcal P(\mathcal X;\theta)Pmodel=P(X;θ)中进行采样,而θ\thetaθ是我们要求解的量,两者之间相互矛盾。
如果想要求解t+1t+1t+1次迭代的负相,需要从上一迭代的分布Pmodel=P(X;θ(t))\mathcal P_{model} = \mathcal P(\mathcal X;\theta^{(t)})Pmodel=P(X;θ(t))中进行采样:
《深度学习》(花书)中称从Pmodel\mathcal P_{model}Pmodel中采集的样本称为“幻想粒子”(Fantasy Particle)。因为模型本身是基于’概率图结构‘假设的,那么Pmodel\mathcal P_{model}Pmodel自然不是真实的。对于它采集的样本不足够信任。
x^(t+1)={x^t+1(1)∼P(X;θ(t))x^t+1(2)∼P(X;θ(t))⋮x^t+1(M)∼P(X;θ(t))\hat {x}^{(t+1)} = \begin{cases} {\hat x_{t+1}}^{(1)} \sim \mathcal P(\mathcal X;\theta^{(t)}) \\ {\hat x_{t+1}}^{(2)} \sim \mathcal P(\mathcal X;\theta^{(t)}) \\ \quad \vdots \\ {\hat x_{t+1}}^{(\mathcal M)} \sim \mathcal P(\mathcal X;\theta^{(t)}) \end{cases}x^(t+1)=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧x^t+1(1)∼P(X;θ(t))x^t+1(2)∼P(X;θ(t))⋮x^t+1(M)∼P(X;θ(t))
至此,基于梯度上升法模型参数θ\thetaθ的迭代过程归纳如下:
θ(t+1)⇐θ(t)+η[∑i=1M∇θlogP^(x(i);θ(t))−∑i=1M∇θlogP^(x^(i);θ(t))]\theta^{(t+1)} \Leftarrow \theta^{(t)} + \eta \left[\sum_{i=1}^{\mathcal M} \nabla_{\theta} \log \hat \mathcal P(x^{(i)};\theta^{(t)}) - \sum_{i=1}^{\mathcal M}\nabla_{\theta} \log \hat \mathcal P({\hat x}^{(i)};\theta^{(t)})\right]θ(t+1)⇐θ(t)+η[i=1∑M∇θlogP^(x(i);θ(t))−i=1∑M∇θlogP^(x^(i);θ(t))]
个人理解:
上面中括号中均少了1M\frac{1}{\mathcal M}M1应该是并在了η\etaη中;这里仅是使用’吉布斯采样方法‘从平稳分布中采集若干样本,和吉布斯采样本身的迭代过程(在实现平稳分布过程中每一个step对个维度采样、固定)没有关联关系。
关于书中图像的解释
某一维随机变量的概率分布表示如下(蓝色线):
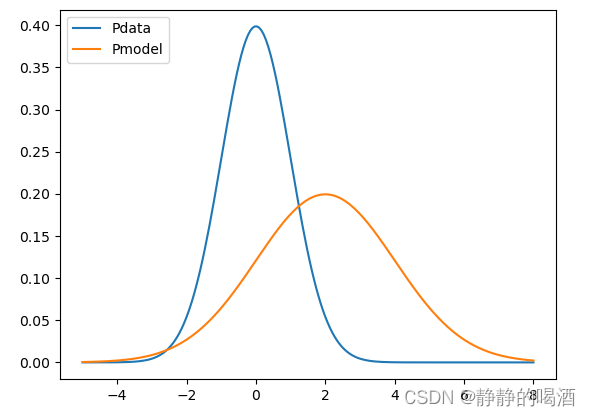
而橙色线表示假设的概率模型Pmodel=P(X;θ)\mathcal P_{model} = \mathcal P(\mathcal X;\theta)Pmodel=P(X;θ)在某迭代步骤的概率分布预测结果。
回顾梯度∇θL(θ)\nabla_{\theta}\mathcal L(\theta)∇θL(θ)在梯度上升法的作用,我们希望每一次迭代,梯度结果越高,它的梯度方向就越指向最优模型参数:
∇θL(θ)=EPdata[∇θlogP^(x(i);θ)]⏟Positive Phase−EPmodel[∇θlogP^(X;θ)]⏟Negative Phase\nabla_{\theta}\mathcal L(\theta) = \underbrace{\mathbb E_{\mathcal P_{data}} [\nabla_{\theta} \log \hat \mathcal P(x^{(i)};\theta)]}_{\text{Positive Phase}} - \underbrace{\mathbb E_{\mathcal P_{model}} [\nabla_{\theta} \log \hat \mathcal P(\mathcal X;\theta)]}_{\text{Negative Phase}}∇θL(θ)=Positive PhaseEPdata[∇θlogP^(x(i);θ)]−Negative PhaseEPmodel[∇θlogP^(X;θ)]
从而有:正相越高越好,负相越低越好。
-
首先,从Pdata\mathcal P_{data}Pdata中采集了M\mathcal MM个样本,由于Pdata\mathcal P_{data}Pdata的概率密度函数,采集的样本更多概率聚集在0附近。
Pdata\mathcal P_{data}Pdata是真实分布,是基于问题客观存在的。 -
拿到样本之后,对当前迭代步骤的正相进行求解。但求解并不是最终目的,而是希望使用极大似然估计,找到一款参数,使得L(θ)\mathcal L(\theta)L(θ)达到最大。
而L(θ)\mathcal L(\theta)L(θ)达到最大的目的是让假设概率模型的分布Pmodel\mathcal P_{model}Pmodel接近真实分布Pdata\mathcal P_{data}Pdata.观察上图0附近的关于Pmodel\mathcal P_{model}Pmodel的概率分布结果,很显然并不在Pmodel\mathcal P_{model}Pmodel的波峰位置,这说明 此时的Pmodel\mathcal P_{model}Pmodel和真实分布Pdata\mathcal P_{data}Pdata是有差距的。
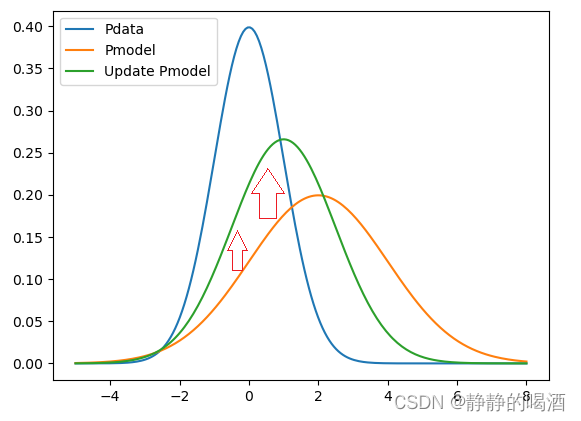
如何缩小这种差距——通过修正模型参数θ\thetaθ,让这些采集的样本对应的概率结果提高:
此时Pmodel\mathcal P_{model}Pmodel橙色线到绿色线的变化区域(横坐标)基本已经涵盖了Pdata\mathcal P_{data}Pdata(蓝色线)的有效范围。在Pdata\mathcal P_{data}Pdata有效范围内Pmodel\mathcal P_{model}Pmodel的概率结果提高,从图形的趋势上来看,它相比之前的橙色线,更接近于Pdata\mathcal P_{data}Pdata.
图画的不好,见谅哈~
-
同理,观察负相,和正相不同的是,负相是从Pmodel\mathcal P_{model}Pmodel中进行采样,而不是Pdata\mathcal P_{data}Pdata。观察Pmodel\mathcal P_{model}Pmodel的高概率部分(波峰部分),与该部分样本点对应的Pdata\mathcal P_{data}Pdata概率结果明显存在差距。
如何缩小这种差距——调整模型参数θ\thetaθ让这些采样点对应的概率结果降低。
最终目标就是‘无限逼近’Pdata\mathcal P_{data}Pdata。因为Pdata\mathcal P_{data}Pdata是客观存在的,是恒定不变的。
以正相结果为基础,进行如下修正:
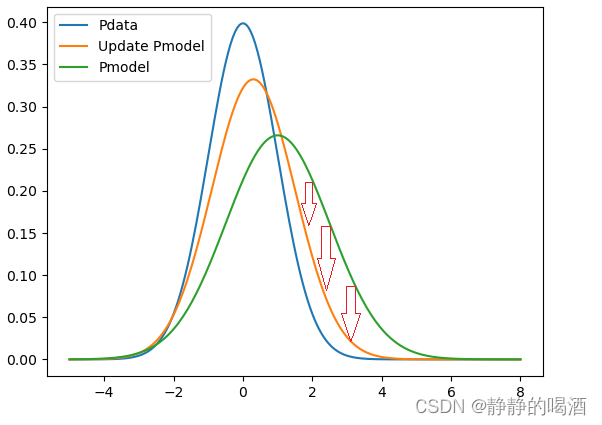
相比于初始状态,此时已经很接近真实分布Pdata\mathcal P_{data}Pdata了。
需要注意的点:正相和负相不是各变各的,而是同时进行。 -
迭代过程到什么状态下停止?
从∇θL(θ)\nabla_{\theta}\mathcal L(\theta)∇θL(θ)中可以看出:
∇θL(θ)=EPdata[∇θlogP^(x(i);θ)]⏟Positive Phase−EPmodel[∇θlogP^(X;θ)]⏟Negative Phase\nabla_{\theta}\mathcal L(\theta) = \underbrace{\mathbb E_{\mathcal P_{data}} [\nabla_{\theta} \log \hat \mathcal P(x^{(i)};\theta)]}_{\text{Positive Phase}} - \underbrace{\mathbb E_{\mathcal P_{model}} [\nabla_{\theta} \log \hat \mathcal P(\mathcal X;\theta)]}_{\text{Negative Phase}}∇θL(θ)=Positive PhaseEPdata[∇θlogP^(x(i);θ)]−Negative PhaseEPmodel[∇θlogP^(X;θ)]
正相、负相期望中的函数部分完全相同,只有期望基于的概率分布(Pmodel,Pdata\mathcal P_{model},\mathcal P_{data}Pmodel,Pdata)不一样。如果Pmodel=Pdata\mathcal P_{model} = \mathcal P_{data}Pmodel=Pdata,∇θL(θ)=0\nabla_{\theta}\mathcal L(\theta) = 0∇θL(θ)=0,不会再更新梯度,此时迭代过程自然就停止了。
下一节将介绍对比散度。
相关参考:
直面配分函数-2-Stochastic Maximum Likelihood(随机最大似然)
深度学习(花书)——第18章 直面配分函数