
redis的热key、大key
目录
1.概述
2.查找方法
2.1.知道具体哪个key有问题
2.2.不知道具体哪个key有问题
3.处理方法
3.1.大key的处理方法
3.2.热key的处理方法
1.概述
大key:
含有较大数据或含有大量成员的Key称之为大Key,常见的大key如:
-
String类型的Key值大于10kb
-
list、set、zset、hash的成员个数超过5000
-
list、set、zset、hash的成员数量虽然只有1000个但这些成员的value总大小为100MB(成员体积过大)
注意:以上值只是参考,根据实际情况确定。
热key:
某个Key接收到的访问次数、显著高于其它Key时,称之为热Key。
大key带来的问题:
- 对Redis的请求变慢。
- Redis内存不断变大引发OOM,或达到maxmemory值引发写阻塞或重要Key被逐出。
- Redis Cluster中的某个node内存远超其余node。
- 由于对大key的请求很慢,容易造成请求的阻塞,在分布式架构下容易造成服务雪崩。
- 删除一个大Key很耗时,容易造成主结点阻塞,从而主从切换。
热key带来的问题:
- 大量请求直接打过来,服务器可能会扛不住,造成缓存击穿从而直接打挂后端存储(数据库),影响其他使用后端存储的业务。
- 可能使得redis的集群失去意义,Redis Cluster中各node流量不均衡造成Redis Cluster的分布式优势无法被利用,一个分片负载很高而其它分片十分空闲。
大key、热key的产生原因:
- 存放不合理,存储了不适合存放在内存中的数据,如用key存放音频视频这一类大体积二进制文件(大key)。
- 设计不合理,造成个别key中成员过多。(大key)。
- 未定期清理数据,没有设置过期时间,造成了如hash类型中key中的成员不断增加。
- 流量陡增,如出现某款爆款商品等(热key)。
- bug,代码的业务逻辑上对key的成员只增不减也未设置过期时间。
2.查找方法
2.1.知道具体哪个key有问题
利用调试指令进行分析查找大key:
debug key名,对Key进行分析并返回分析结果,其中serializedlength的值为该Key的序列化长度,序列化长度可以作为key大小的判断参考,但不一定准确。而且debug命令属于调试命令,在其运行时,进入Redis的其余请求将会被阻塞直到其执行完毕。线上环境进行分析不推荐该命令。
利用操作指令进行分析查找大key:
redis的各个数据结构的操作API自带返回其成员长度的命令。利用这些命令进行分析风险更小。
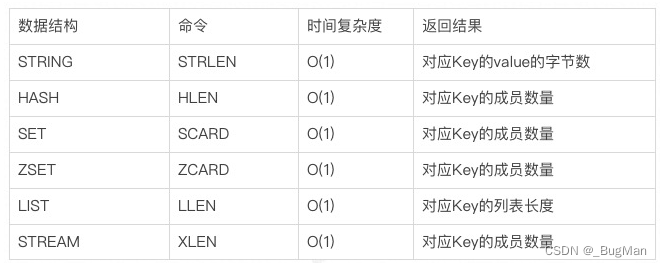
2.2.不知道具体哪个key有问题
前面的指令都是对具体的key进行分析,在不知道哪个key会有问题的时候,可以使用参数进行分析。
redis-cli的bigkeys参数用于查找大key。bigkeys仅能分别输出最大Key,如果想进行范围查询,比如找出全部成员数量超过10的hash,bigkeys是办不到的。
redis-cli的hotkeys参数用来分析热key,该参数能够返回所有Key的被访问次数,试用hotkeys的前提条件是将redis-server的maxmemory-policy参数设置为LFU。
3.处理方法
3.1.大key的处理方法
大key的处理方法有两种:
-
拆分
-
删除
拆分:
如将一个成员很多的hash拆分为多个hash。
删除:
将不适合Redis能力的数据存放至其它存储,并在Redis中删除此类数据。需要注意的是,删除大key可能很耗时,redis又是单线程执行的,很可能造成阻塞,Redis自4.0起提供了UNLINK命令,该命令能够异步的方式安全的删除大Key。
3.2.热key的处理方法
热key的处理方法有两种:
-
复制
-
读写分离
-
多级缓存
复制:
在使用redis集群时,可以将热key复制多份,每个redis节点上存放一份,这样不存在请求的重定向使得压力全部定向到单个节点,能有效减轻单节点的压力。缺点是要进行复制的画只能在代码层手动操作,而且复制多份存放后会存在数据一致性问题。因此复制方案只能用于临时解决线上问题。
读写分离:
热key多数是读热key的操作,读写分离能保证从节点中数据的一致性,并且能轻松的横向扩展,能有效的分散压力,只是有点浪费资源,因为读写分离每个从节点上存的都是一样的数据。
多级缓存:
当热key数量不多,比如电商平台促销活动,热key都集中在少部分key上面,为此做读写分离增加机器性价比不高,使用多级缓存是个不错的解决方法。具体实现思路两种:
1.客户端本地缓存,redis和客户端之间增加一个中间层(proxy),专门用来进行热key探查,这个proxy专门用来监视redis来统计达到预设的热key阈值的key,统计好后推送给客户端,让客户端存在本地缓存。
2.将proxy探查到的热key推送到需要访问该热key的服务结点,使用服务结点的本地缓存,下次再来请求就不将流量打到redis上。
使用多级缓存会存在一个问题,因为每次推送之间有时间间隔,缓存中的数据和redis中的数据不是呈现强一致性的,而是呈现最终一致性的。这种代价也是不得不接受的,在使用缓存的时候注意不要拿缓存做逻辑,只用来做查询即可。