
大数据面试之YARN常见题目
大数据面试之YARN常见题目
1 YARN工作机制
1.1 图解
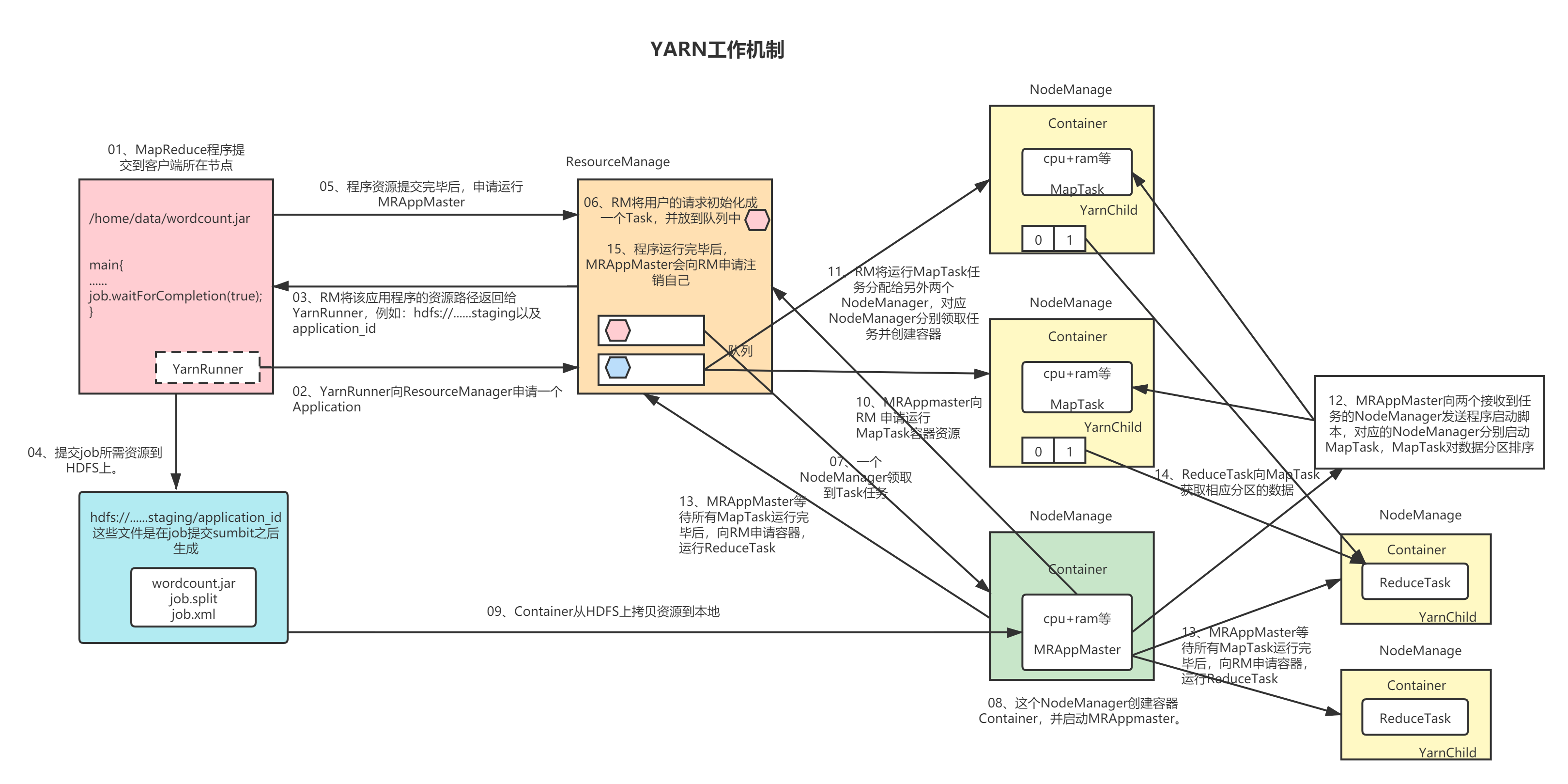
上面有单词少个r,就不改了,大家知道就行。
1.2 文字描述
文字版描述:
1、MapReduce程序提交到Client所在节点,在MR程序的主函数当中有job.waitForCompletion()将任务进行提交给ResourceManager。
2、Client客户端会向ResourceManager申请一个Application ID,其实就是整个程序当中唯一的一个标识。
3、ResourceManager给客户端返回一个路径,让Client给要提交的东西放到这个路径上。这个路径是一个集群的路径。
4、Client提交相应的程序到ResourceManager返回的路径上,提交的程序包含三个部分内容,分别是程序jar本身、切片信息、XML配置信息。Jar包是程序本身代码;XML是指任务按照哪一个配置进行执行,比如说是两个副本等由配置信息决定;切片信息决定了未来要开启多少个MapTask。
05、程序资源提交完毕之后,向ResourceManager申请运行MRAppMaster。就是自己的应用程序的运行老大。
06、ResourceManager将Client的请求形成一个Task,这是一个Client形成了一个任务,因为是集群,会有多个Client客户端进行任务提交,到底要先运行哪个任务,所以要有个排队机制,给这些任务放到调度器的队列当中。到底先运行哪一个由调度器说了算。
07、这个时候有某个NodeManager,正好有对应的资源,就给任务领取了。
08、领取任务之后,NodeManager要想运行任务,要开启相应的Container容器,Container里面有相应的内存、网络、硬盘 等资源,类似于一个单独的小电脑。在Container里面会开启MRAppMaster。
09、开启MRAppMaster之后去集群路径上面找对应的信息,也就是Container从HDFS上面拷贝资源到本地。
10、MRAppMaster向ResourceManager申请运行MapTask的容器资源。比如说上一步确认了切片信息是两个,这个时候NodeManager的Container容器中的MRAppMaster就要跟ResourceManager申请运行两个MapTask。
11、仍然以两个MapTask进行分析,ResourceManager将运行MapTask任务分配给另外两个NodeManager,对应的NodeManager分别领取任务并创建对应的Container容器。这里假设是两个NodeManager分别创建了两个Container容器,也可以是一个NodeManager当中创建两个Container容器来运行两个MapTask任务。
12、MRAppMaster向两个接受到任务的容器发送程序启动命令,启动MapTask进程。MapTask启动之后就开始运行,对分区数据进行排序,运行完毕之后给所有的数据持久化到磁盘。
13、MRAppMaster等待所有MapTask运行完毕之后,向ResourceManager申请Container容器运行ReduceTask。
14、ReduceTask拉取自己分区的数据进行处理。
15、ReduceTask运行完毕之后,由于MRAppMaster向集群的ResourceManager申请注销,释放相应的资源。
以上就是YARN的工作机制。
2 YARN调度器
2.1 调度器分类
FIFO 、Capacity Scheduler(容量调度器)和Fair Scheduler(公平调度器)。
2.2 默认的调度器
Apache版本默认的资源调度器是容量调度器;
CDH版本默认的资源调度器是公平调度器。
2.3 FIFO调度器
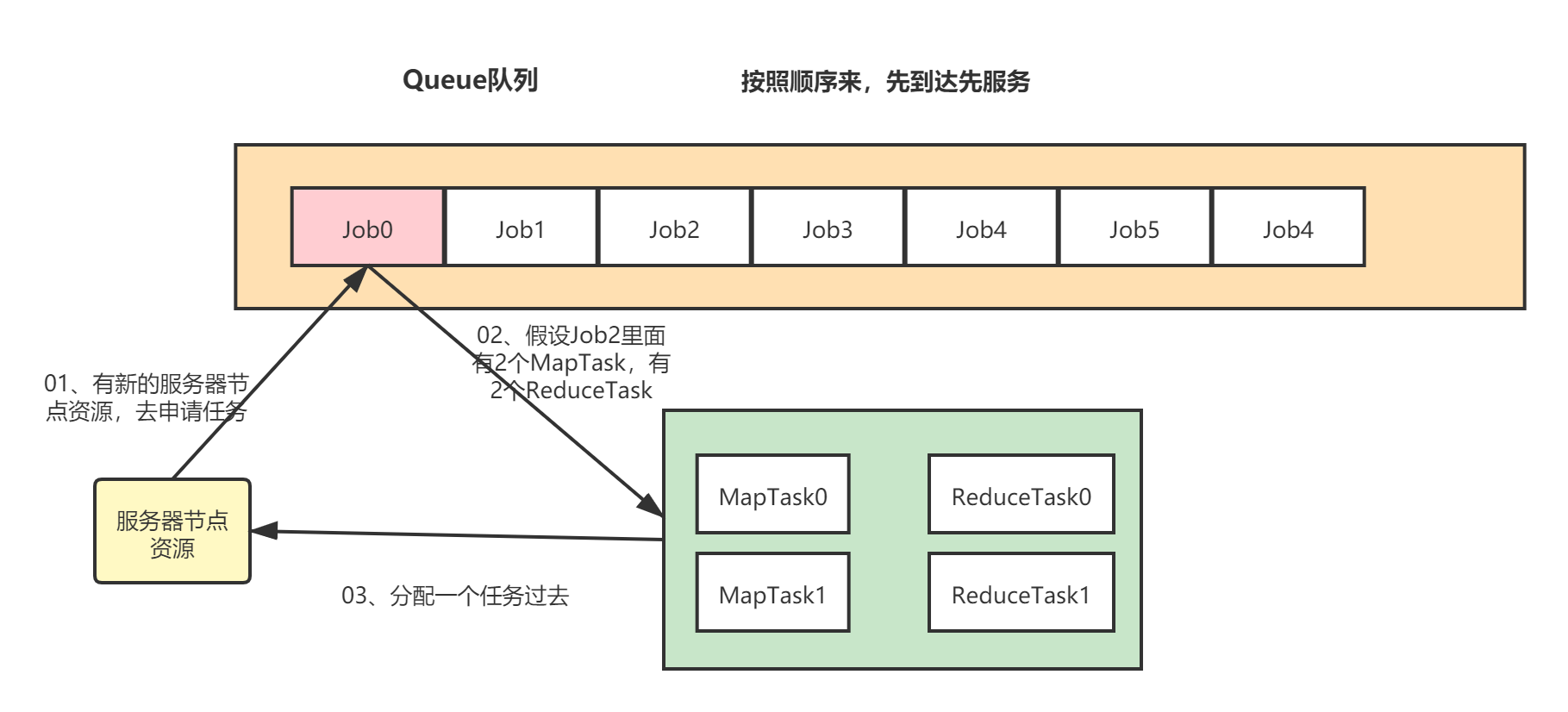
FIFO调度器:
先进先出、支持单队列。
里面的任务按照来的顺序进行排队。生产环境基本不会用。因为是单队列,并行度就是1。一个一个执行,效率不高。
2.4 Capacity Scheduler(容量调度器)
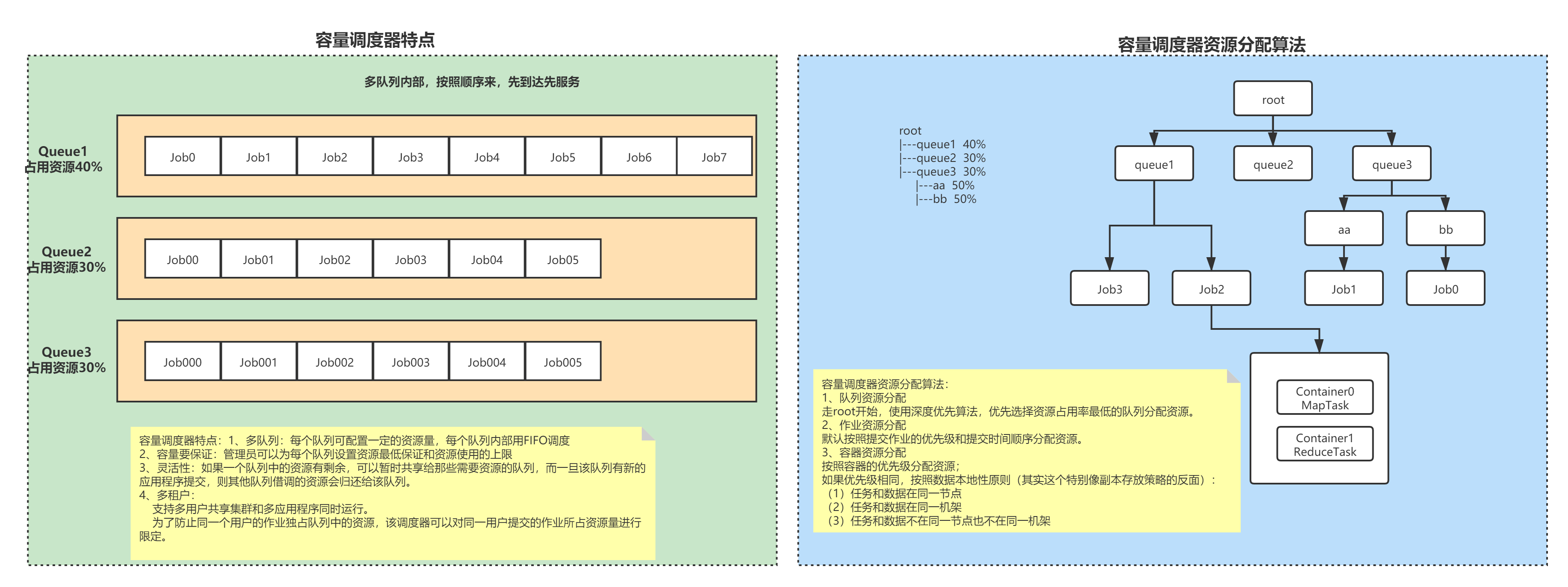
Capacity Scheduler(容量调度器):
支持多队列;
保证先进入的任务优先执行;
资源不够的时候可以向其他队列借。
2.5 Fair Scheduler(公平调度器)

Fair Sceduler(公平调度器):
支持多队列;
保证每个任务公平享有队列资源;
资源不够时可以按照缺额分配;
公平调度器相对容量调度器高些。
2.6 在生产环境下怎么选择
大公司:如果对并发度要求比较高,选择公平,要求服务器性能要没问题;
中小公司:如果对并发度要求比较不高,选择容量,也就是集群服务器资源不太充裕的时候。
2.7 在生产环境怎么创建队列
(1)不管是哪种调度器,默认就1个default队列,不能满足生产要求。
(2)可以按照框架进行创建:hive /spark/ flink 每个框架的任务放入指定的队列(业务不是特别多的情况下可以使用)
(3)可以按照部门和业务模块进行创建:业务部门1、业务部门2、登录、注册、购物车、下单、
2.8 为什么要创建多队列
(1)有些员工不小心写的一些代码,比如递归死循环代码,会把资源耗尽。
(2)实现任务的降级使用,特殊时期保证重要的任务队列资源充足,优先使用,比如特殊的促销节。
声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
B站: https://space.bilibili.com/1523287361 点击打开链接
微博: http://weibo.com/luoyepiaoxue2014 点击打开链接