
365天深度学习训练营-第P4周:猴痘病识别
创始人
2024-05-03 08:17:43
- 🍨 本文为🔗365天深度学习训练营 内部限免文章(版权归 K同学啊 所有)
- 🍦 参考文章地址: 🔗第P4周:猴痘病识别 | 365天深度学习训练营
- 🍖 作者:K同学啊 | 接辅导、程序定制
文章目录
- 我的环境:
- 一、前期工作
- 1. 设置 GPU
- 2. 导入数据
- 3. 划分数据集
- 二、构建简单的CNN网络
- 三、训练模型
- 1. 设置超参数
- 2. 编写训练函数
- 3. 编写测试函数
- 4. 正式训练
- 四、结果可视化
我的环境:
- 语言环境:Python 3.6.8
- 编译器:jupyter notebook
- 深度学习环境:
- torch==0.13.1、cuda==11.3
- torchvision==1.12.1、cuda==11.3
一、前期工作
1. 设置 GPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms,datasetsimport os,PIL,pathlibdevice = torch.device("cuda" if torch.cuda.is_available() else "cp")device
device(type='cuda')
2. 导入数据
data_dir = 'D:\\jupyter notebook\\DL-100-days\\datasets\\45-data'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[5] for path in data_paths]
print(classeNames)
['Monkeypox', 'Others']
total_datadir = 'D:\\jupyter notebook\\DL-100-days\\datasets\\45-data'train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])total_data = datasets.ImageFolder(total_datadir, transform=train_transforms)
print(total_data)
Dataset ImageFolderNumber of datapoints: 2142Root location: D:\jupyter notebook\DL-100-days\datasets\45-dataStandardTransform
Transform: Compose(Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=None)ToTensor()Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]))
print(total_data.class_to_idx)
{'Monkeypox': 0, 'Others': 1}
3. 划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print(train_dataset, test_dataset)
print(train_size, test_size)
1713 429
train_size,test_size
(900, 225)
batch_size = 128train_dl = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=0)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=0)# 数据的shape为:[batch_size, channel, height, weight]
# 其中batch_size为自己设定,channel,height和weight分别是图片的通道数,高度和宽度。
for X, y in test_dl:print("Shape of X [N, C, H, W]: ", X.shape)print("Shape of y: ", y.shape, y.dtype)break
Shape of X [N, C, H, W]: torch.Size([128, 3, 224, 224])
Shape of y: torch.Size([128]) torch.int64
二、构建简单的CNN网络
import torch.nn.functional as Fclass Network_bn(nn.Module):def __init__(self):super(Network_bn,self).__init__()self.conv1 = nn.Conv2d(in_channels=3,out_channels=12,kernel_size=5,stride=1,padding=0)self.bn1 = nn.BatchNorm2d(12)self.conv2 = nn.Conv2d(in_channels=12,out_channels=12,kernel_size=5,stride=1,padding=0)self.bn2 = nn.BatchNorm2d(12)self.pool = nn.MaxPool2d(12)self.conv4 = nn.Conv2d(in_channels=12,out_channels=24,kernel_size=5,stride=1,padding=0)self.bn1 = nn.BatchNorm2d(24)self.conv5 = nn.Conv2d(in_channels=24,out_channels=24,kernel_size=5,stride=1,padding=0)self.bn5 = nn.BatchNorm2d(24)self.fc1 = nn.Linear(24*50*50,len(classNames))def forward(self,x):x = F.relu(self.bn1(self.conv1(x)))x = F.relu(self.bn2(self.conv2(x)))x = self.pool(x)x = F.relu(self.bn4(self.conv4(x)))x = F.relu(self.bn5(self.conv5(x)))x = self.pool(x)x = x.view(-1,24*50*50)x = self.fc1(x)return xdevice = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))model = Network_bn().to(device)
model
Using cuda device
Network_bn((conv1): Conv2d(3, 12, kernel_size=(5, 5), stride=(1, 1))(bn1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(12, 12, kernel_size=(5, 5), stride=(1, 1))(bn2): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(conv4): Conv2d(12, 24, kernel_size=(5, 5), stride=(1, 1))(bn4): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv5): Conv2d(24, 24, kernel_size=(5, 5), stride=(1, 1))(bn5): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(fc1): Linear(in_features=60000, out_features=2, bias=True)
)
三、训练模型
1. 设置超参数
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-4 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
2. 编写训练函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小num_batches = len(dataloader) # 批次数目train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
3. 编写测试函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小num_batches = len(dataloader) # 批次数目train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
4. 正式训练
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))
print('Done')
Epoch: 1, Train_acc:56.7%, Train_loss:0.694, Test_acc:65.3%,Test_loss:0.671
Epoch: 2, Train_acc:62.8%, Train_loss:0.636, Test_acc:61.5%,Test_loss:0.652
Epoch: 3, Train_acc:64.9%, Train_loss:0.622, Test_acc:58.7%,Test_loss:0.688
Epoch: 4, Train_acc:68.0%, Train_loss:0.597, Test_acc:68.1%,Test_loss:0.630
Epoch: 5, Train_acc:68.4%, Train_loss:0.590, Test_acc:68.1%,Test_loss:0.623
Epoch: 6, Train_acc:70.9%, Train_loss:0.572, Test_acc:69.2%,Test_loss:0.581
Epoch: 7, Train_acc:71.7%, Train_loss:0.554, Test_acc:69.2%,Test_loss:0.596
Epoch: 8, Train_acc:72.7%, Train_loss:0.542, Test_acc:68.3%,Test_loss:0.617
Epoch: 9, Train_acc:74.0%, Train_loss:0.530, Test_acc:70.9%,Test_loss:0.577
Epoch:10, Train_acc:74.3%, Train_loss:0.520, Test_acc:73.2%,Test_loss:0.595
Epoch:11, Train_acc:75.1%, Train_loss:0.510, Test_acc:68.1%,Test_loss:0.589
Epoch:12, Train_acc:75.3%, Train_loss:0.505, Test_acc:73.7%,Test_loss:0.559
Epoch:13, Train_acc:77.2%, Train_loss:0.488, Test_acc:71.6%,Test_loss:0.563
Epoch:14, Train_acc:78.4%, Train_loss:0.478, Test_acc:73.0%,Test_loss:0.545
Epoch:15, Train_acc:78.9%, Train_loss:0.468, Test_acc:74.8%,Test_loss:0.537
Epoch:16, Train_acc:80.1%, Train_loss:0.463, Test_acc:75.1%,Test_loss:0.538
Epoch:17, Train_acc:80.1%, Train_loss:0.457, Test_acc:75.1%,Test_loss:0.550
Epoch:18, Train_acc:79.8%, Train_loss:0.447, Test_acc:76.5%,Test_loss:0.503
Epoch:19, Train_acc:81.6%, Train_loss:0.440, Test_acc:76.9%,Test_loss:0.511
Epoch:20, Train_acc:82.0%, Train_loss:0.435, Test_acc:78.1%,Test_loss:0.508
Done四、结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
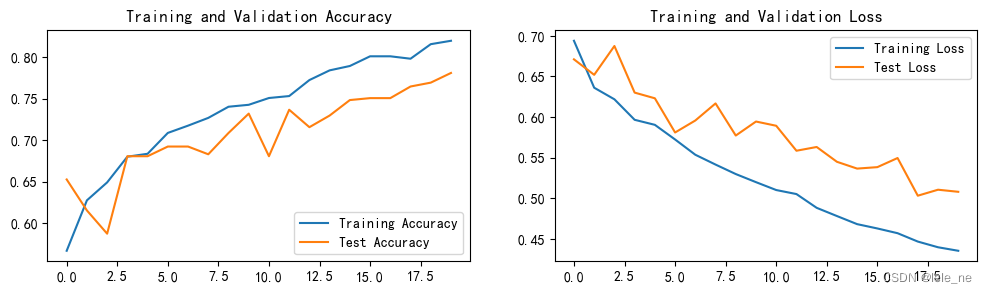
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
# 模型保存
PATH = 'D:\\jupyter notebook\\DL-100-days\\datasets\\45-data\\model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)# 将参数加载到model当中
model.load_state_dict(torch.load(PATH, map_location=device))
from PIL import Imageclasses = list(total_data.class_to_idx)def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB')# plt.imshow(test_img) # 展示预测的图片test_img = transform(test_img)img = test_img.to(device).unsqueeze(0) #(0表示,在第一个位置增加维度)model.eval()output = model(img)_, pred = torch.max(output, 1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')# 预测训练集中的某张照片predict_one_image(image_path='D:\\jupyter notebook\\DL-100-days\\datasets\\45-data\\Others\\NM01_01_00.jpg',model=model,transform=train_transforms,classes=classes)
预测结果是:Others
上一篇:被取消的AP考试到底是什么嘞?
相关内容
热门资讯
埃菲尔铁塔在哪 中国仿建埃菲尔...
2019年4月26日,广西南宁市,街头惊现一座巨型山寨版埃菲尔铁塔,高约20米,白色塔身,造型逼真,...
苗族的传统节日 贵州苗族节日有...
【岜沙苗族芦笙节】岜沙,苗语叫“分送”,距从江县城7.5公里,是世界上最崇拜树木并以树为神的枪手部落...
北京的名胜古迹 北京最著名的景...
北京从元代开始,逐渐走上帝国首都的道路,先是成为大辽朝五大首都之一的南京城,随着金灭辽,金代从海陵王...
长白山自助游攻略 吉林长白山游...
昨天介绍了西坡的景点详细请看链接:一个人的旅行,据说能看到长白山天池全凭运气,您的运气如何?今日介绍...
应用未安装解决办法 平板应用未...
---IT小技术,每天Get一个小技能!一、前言描述苹果IPad2居然不能安装怎么办?与此IPad不...
脚上的穴位图 脚面经络图对应的...
人体穴位作用图解大全更清晰直观的标注了各个人体穴位的作用,包括头部穴位图、胸部穴位图、背部穴位图、胳...
猫咪吃了塑料袋怎么办 猫咪误食...
你知道吗?塑料袋放久了会长猫哦!要说猫咪对塑料袋的喜爱程度完完全全可以媲美纸箱家里只要一有塑料袋的响...
demo什么意思 demo版本...
618快到了,各位的小金库大概也在准备开闸放水了吧。没有小金库的,也该向老婆撒娇卖萌服个软了,一切只...
世界上最漂亮的人 世界上最漂亮...
此前在某网上,选出了全球265万颜值姣好的女性。从这些数量庞大的女性群体中,人们投票选出了心目中最美...
埃菲尔铁塔在哪 中国仿建埃菲尔...
2019年4月26日,广西南宁市,街头惊现一座巨型山寨版埃菲尔铁塔,高约20米,白色塔身,造型逼真,...
苗族的传统节日 贵州苗族节日有...
【岜沙苗族芦笙节】岜沙,苗语叫“分送”,距从江县城7.5公里,是世界上最崇拜树木并以树为神的枪手部落...
北京的名胜古迹 北京最著名的景...
北京从元代开始,逐渐走上帝国首都的道路,先是成为大辽朝五大首都之一的南京城,随着金灭辽,金代从海陵王...
长白山自助游攻略 吉林长白山游...
昨天介绍了西坡的景点详细请看链接:一个人的旅行,据说能看到长白山天池全凭运气,您的运气如何?今日介绍...
世界上最漂亮的人 世界上最漂亮...
此前在某网上,选出了全球265万颜值姣好的女性。从这些数量庞大的女性群体中,人们投票选出了心目中最美...
应用未安装解决办法 平板应用未...
---IT小技术,每天Get一个小技能!一、前言描述苹果IPad2居然不能安装怎么办?与此IPad不...
脚上的穴位图 脚面经络图对应的...
人体穴位作用图解大全更清晰直观的标注了各个人体穴位的作用,包括头部穴位图、胸部穴位图、背部穴位图、胳...
demo什么意思 demo版本...
618快到了,各位的小金库大概也在准备开闸放水了吧。没有小金库的,也该向老婆撒娇卖萌服个软了,一切只...
猫咪吃了塑料袋怎么办 猫咪误食...
你知道吗?塑料袋放久了会长猫哦!要说猫咪对塑料袋的喜爱程度完完全全可以媲美纸箱家里只要一有塑料袋的响...