
说话人识别中的损失函数
创始人
2024-05-03 10:55:40
损失函数
- 损失函数L(yi,y^i)L(y_i,\hat{y}_i)L(yi,y^i)用来描述神经网络的输出y^i\hat{y}_iy^i和基本事实(Ground Truth,GT)yiy_iyi的差异
- 对于回归问题,常用均方误差(Mean Square Error,MSE)损失函数
L(yi,y^i)=∥yi−y^i∥22L(y_i,\hat{y}_i)=\left \| y_i-\hat{y}_i \right \|_2^2 L(yi,y^i)=∥yi−y^i∥22 - 神经网络的训练过程就是寻找一组参数θ\thetaθ,使得神经网络在一个batch的训练上,损失函数的和最小
θ=argminθ∑i=1NL(yi,y^i)\theta=\arg\min_{\theta}\sum_{i=1}^{N}L(y_i,\hat{y}_i) θ=argθmini=1∑NL(yi,y^i) - 对于说话人识别,通常有两种类型的损失函数
- 将说话人识别看作一个多说话人分类问题,即模拟说话人辨认问题
- 将说话人识别看作一个二值决策问题,即模拟说话人验证问题
多说话人分类
- 在该问题中,假设不同的说话人属于不同的类
- 训练时
- 每个说话人都有一个全局唯一标签
- 每个话语(Utterance)都有一个说话人标签
- 运行时
- 需要识别在训练集中未出现过的说话人,因此无法使用训练数据的标签作为输出
- 得到嵌入码之后,需要经过一个MLP(该MLP的激活函数是Softmax),得到该嵌入码属于训练数据中哪一个说话人的概率分布
Cross Entropy Loss
- 得到概率分布后,使用交叉熵(Cross Entropy,CE)损失函数,计算预测的概率分布,与真实的概率分布之间的差距,假设概率分布的向量维度为K
H(p,q)=−∑i=1Kpi⋅lnqiH(p,q)=-\sum_{i=1}^{K}p_i\cdot\ln q_i H(p,q)=−i=1∑Kpi⋅lnqi
其中,- ppp是真实的概率分布,采用独热向量(One-hot Vector),即只有真实说话人对应的值为1,其他的值都为0
- qqq是预测的概率分布,经过Softmax激活函数之后,最大值接近1,所有值求和等于1
- 由于ppp为独热向量,所以损失函数简化为H(p,q)=−lnqjH(p,q)=-\ln q_jH(p,q)=−lnqj,qjq_jqj指预测的概率分布中,真实说话人对应的概率
- H(p,q)H(p,q)H(p,q)的值越小,代表两个分布越接近
- 训练时:在训练数据上,最小化H(p,q)H(p,q)H(p,q)来优化参数
- 运行时:直接使用嵌入码,用于说话人识别(可用余弦相似度、欧氏距离等)
- 这种方法的缺点
- 用于计算概率分布的MLP,其参数会随着训练数据说话人数量线性增加
- 例如嵌入码的维度是1280,训练数据有1000人,那么MLP的参数矩阵WSoftmax∈R1000×1280W_{Softmax} \in R^{1000 \times 1280}WSoftmax∈R1000×1280,光是MLP的参数量就达到了128万
- 训练集中,部分说话人的数据量较少,这意味着WSoftmaxW_{Softmax}WSoftmax中,有部分参数极少发挥作用,但是前向传播时每次都需要计算整个矩阵,这导致训练过程中,花费了大量的资源用于优化几乎没有用的参数
- WSoftmaxW_{Softmax}WSoftmax只在训练时发挥作用,与运行时的相似度计算不完全一致,这会导致网络难以泛化到训练集中未出现过的说话人
Angular Softmax
- 为了改善训练和运行时,目标不匹配的问题,Softmax有一个变种,叫做Angular Softmax,思路如下:
- 将WSoftmaxW_{Softmax}WSoftmax中的每个行向量wrw_rwr都限制为单位长度的向量,设嵌入码为eee,那么wr⋅e=∣∣e∣∣cosθiw_r \cdot e=||e|| \cos \theta_iwr⋅e=∣∣e∣∣cosθi
- WSoftmax⋅eW_{Softmax} \cdot eWSoftmax⋅e的运算结果,就是eee的范数,乘以一个余弦值,此时的优化过程,会与运行时的相似度计算更加一致
- 注意,关于Softmax的计算,如果幂的值很大,取指数会导致溢出(即便是Python也要考虑这个问题),此时需要令输入向量中的每一个值,都减去向量中的最大值,然后再进行标准的Softmax运算,这不影响运算结果,但是保证了数值计算的稳定,原因如下
yi=exp(xi−xmax)∑j=iKexp(xj−xmax)=exp(xi)/exp(xmax)∑j=iK[exp(xj)/exp(xmax)]=exp(xi)∑j=iKexp(xj)\begin{aligned} y_i&=\frac{exp(x_i-x_{max})}{\sum_{j=i}^{K}exp(x_j-x_{max})} \\ &=\frac{exp(x_i)/exp(x_{max})}{\sum_{j=i}^{K}[exp(x_j)/exp(x_{max})]} \\ &=\frac{exp(x_i)}{\sum_{j=i}^{K}exp(x_j)} \\ \end{aligned} yi=∑j=iKexp(xj−xmax)exp(xi−xmax)=∑j=iK[exp(xj)/exp(xmax)]exp(xi)/exp(xmax)=∑j=iKexp(xj)exp(xi)
二值决策
- 针对多说话人分类方法,训练和运行时,目标不匹配的问题,研究人员提出二值决策方法
- 给定两个话语,网络对这两个话语进行二值决策:
- 0,表示两个话语来自不同的说话人
- 1,表示两个话语来自同一个说话人
- 损失函数必须基于,由至少两个话语组成的样本,来定义
Pairwise Loss
- 假设有两个输入xix_ixi和xjx_jxj,它们都进入同一个网络,得到两个嵌入码,两个嵌入码的余弦相似度是sijs_{ij}sij,假设GT表示为:
yij={0,若xi和xj来自不同的说话人1,若xi和xj来自同一个说话人y_{ij}= \left\{\begin{matrix} 0,若x_i和x_j来自不同的说话人\\ 1,若x_i和x_j来自同一个说话人 \end{matrix}\right. yij={0,若xi和xj来自不同的说话人1,若xi和xj来自同一个说话人 - 对应的损失函数为L(sij,yij)L(s_{ij},y_{ij})L(sij,yij)
- 可以将这个问题视为二分类问题,使用二元交叉熵(Binary Cross Entropy,BCE)损失函数
LBCE(s,y)=−ylns−(1−y)ln(1−s)L_{BCE}(s,y)=-y\ln s- (1-y)\ln (1-s) LBCE(s,y)=−ylns−(1−y)ln(1−s) - 由于要对余弦相似度取对数,而余弦相似度可能为负数,所需需要将sss变换为正数,常见做法:
s′=σ(ws+b)=11+exp(−(ws+b))s'=\sigma (ws+b)=\frac{1}{1+exp(-(ws+b))} s′=σ(ws+b)=1+exp(−(ws+b))1
其中,www和bbb都是可学习参数,w>0w>0w>0,σ(⋅)\sigma(\cdot)σ(⋅)是Sigmoid函数。从而,损失函数变为LBCE(s′,y)L_{BCE}(s',y)LBCE(s′,y),这就是基于样本对的损失函数Pairwise Loss - 缺点:由于网络参数随训练过程变化,所以难以平衡正样本和负样本在训练过程中的数量平衡
Triplet Loss
- 针对Pairwise Loss的缺点,研究人员提出了基于三元组的损失函数Triplet Loss
- 先思考:在设计损失函数时,我们希望给网络的监督信息的效果是什么?
- 对于同一个说话人的嵌入码,我们希望这两个嵌入码在嵌入码空间中越接近越好
- 对于不同的说话人的嵌入码,我们希望这两个嵌入码在嵌入码空间中越远离越好
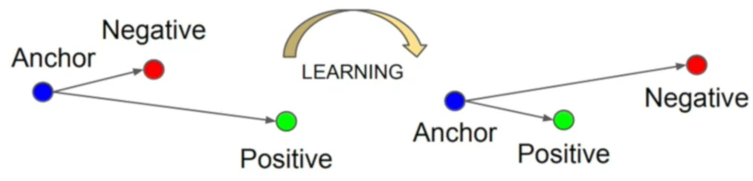
- 针对上述思考,Triplet Loss需要挑选三个话语:
- 锚样本(Anchor)xax^axa
- 正样本(Positive)xpx^pxp,和锚样本来自同一个说话人
- 负样本(Negative)xnx^nxn,和锚样本来自不同的说话人
- 那么,这三个话语的嵌入码,经过参数更新后效果如下图所示:
- 数学形式
L=[∥f(xa)−f(xp)∥22−∥f(xa)−f(xn)∥22+α]+L=[\left \| f(x^a)-f(x^p) \right \|_2^2-\left \| f(x^a)-f(x^n) \right \|_2^2 +\alpha]_+ L=[∥f(xa)−f(xp)∥22−∥f(xa)−f(xn)∥22+α]+
其中,- f(x)f(x)f(x)表示xxx的嵌入码
- α≥0\alpha \ge 0α≥0,是预先定义的超参数,表示正样本,相对于负样本,更靠近锚样本的距离
- [x]+[x]_+[x]+表示函数max(x,0)max(x,0)max(x,0)
- ∥∥22\left \| \right \|_2^2∥∥22表示欧氏距离的平方
- 上述形式的Triplet Loss常用于人脸识别,对于说话人识别,会将欧氏距离改为余弦相似度:
L=[cos(f(xa),f(xn))−cos(f(xa),f(xp))+α]+L=[\cos (f(x^a),f(x^n)) - \cos (f(x^a),f(x^p)) +\alpha]_+ L=[cos(f(xa),f(xn))−cos(f(xa),f(xp))+α]+
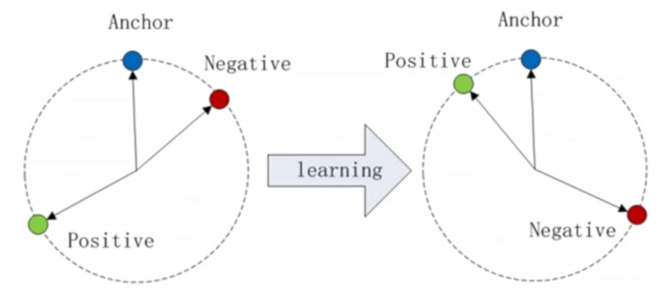
- 注意,由于欧氏距离是越小越靠近,而余弦相似度是越大越靠近,所以对比上一个式子,正样本对之间的距离,和负样本对之间的距离,要交换位置
- 关键点
- 正样本对和负样本对的选择,对于训练的效率非常关键
- 需要挖掘困难样本,至少使[x]+[x]_+[x]+是正数,否则不会有梯度信息
- 由于网络参数随训练过程变化,所以难以提前找到困难样本
- 困难样本挖掘的办法:
- 离线挖掘:每训练一定的步数,根据当前的网络参数,计算训练集的嵌入码,根据此时的嵌入码选取困难样本
- 在线挖掘:对每个batch,计算里面每个样本的嵌入码,构造一个最困难的样本
端到端的说话人识别系统
- 对于端到端的定义,业界尚无明确定论,一般而言:
- 第一个“端”,是指系统的输入,如音频数据
- 第一个“端”,是指系统的输出,如预测结果
- 端到端系统应满足下列条件:
- 除了神经网络外,不再使用任何其他模型,不能有GMM、因子分析、PLDA等
- 采用单一的一个神经网络进行推理
- 采用一个损失函数进行参数优化
- 端到端的损失函数,能够在训练时,完全模拟运行时的情况。说话人识别在运行时的特点:
- 注册阶段,有多个注册话语,需要对这些话语提取嵌入码,然后聚合
- 识别阶段,话语可能来自真实说话人或仿冒说话人,需要给出二值决策
端到端的损失函数
- 在训练时,使用N+1N+1N+1个话语
- 其中NNN个话语来自真实说话人
- 另外一个话语来自真实说话人或仿冒说话人
- 这N+1N+1N+1个话语,经过同一个神经网络,其中来自真实说话人的NNN个话语的嵌入码,被聚合(通常是取平均),成为说话人模型
- 另外一个嵌入码,与说话人模型计算余弦相似度
- 余弦相似度经过变换成为正数,然后计算二元交叉熵损失
s′=σ(ws+b)=11+exp(−(ws+b))LBCE(s′,y)=−ylns′−(1−y)ln(1−s′)\begin{aligned} s'&=\sigma (ws+b)=\frac{1}{1+exp(-(ws+b))} \\ L_{BCE}(s',y)&=-y\ln s'- (1-y)\ln (1-s') \end{aligned} s′LBCE(s′,y)=σ(ws+b)=1+exp(−(ws+b))1=−ylns′−(1−y)ln(1−s′)
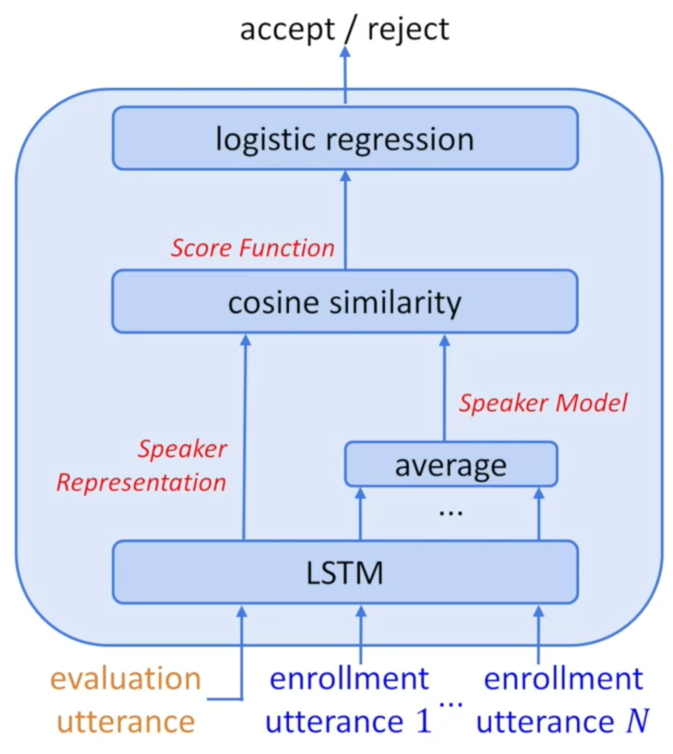
- 最后的损失函数计算过程,非常类似Pairwise Loss,只不过端到端系统的输入是N+1N+1N+1个话语,而不是两个话语
- x-vector系统采用的是类似上述的端到端损失函数,不过将余弦相似度,替换成了另一种相似性度量:
L(e1,e2)=e1Te2−e1TSe1−e2TSe2+bL(e_1,e_2)=e_1^Te_2-e_1^TSe_1-e_2^TSe_2+b L(e1,e2)=e1Te2−e1TSe1−e2TSe2+b
其中,- 矩阵SSS和标量bbb都是可学习参数
- 这是基于PLDA所衍生出来的一种相似性度量
- 关键点
- 关于NNN的选定,可以按照运行时的情况来决定,如果不确定运行时会有几个注册话语,则取平均值或者中间值
- 如何平衡正负样本比例?这是常见的问题,通常负样本数远远多于正样本数,常见的做法是:在负样本的损失函数上,乘以一个常数K,0
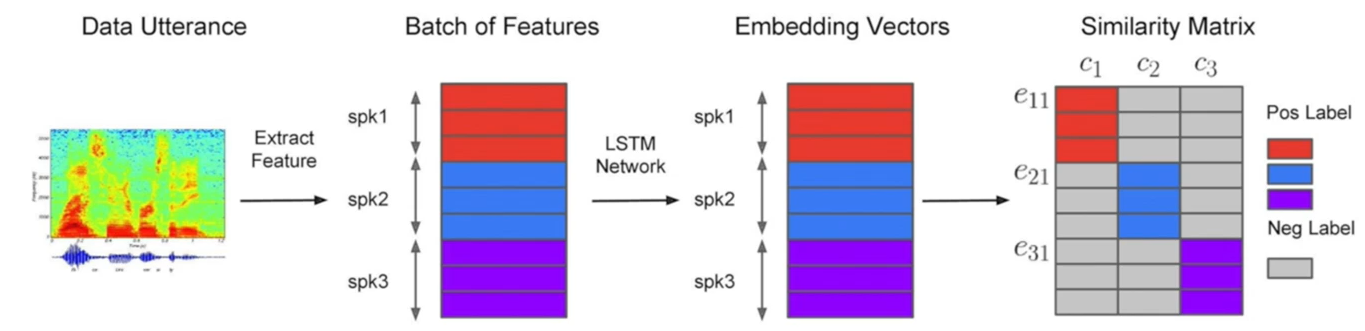
广义端到端损失函数(Generalized End-to-End Loss,GE2E)
- 基本思想
- 通过减少一个batch中的重复计算,使训练更加高效
- 对于一个batch中的所有负样本而言,只关注最困难的那个样本,利用最大间隔原理(梦回SVM)
- 接下来将视角放在一个batch的数据中:
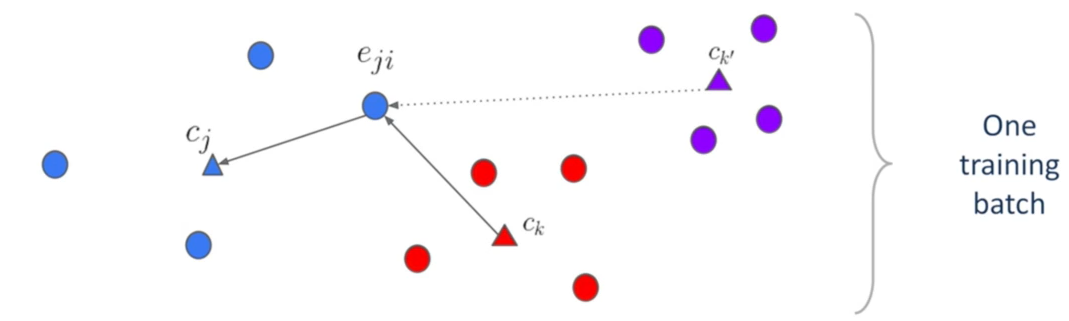
- 上图中,每个圆圈是一个话语的嵌入码,不同的颜色表示该话语来自不同的说话人。可见上图中有三个说话人,每个说话人对应四个嵌入码
- 用正三角形表示每个说话人的嵌入码的中心点(也叫质心,论文中叫Centroid)
- 将嵌入码记为ejie_{ji}eji,jjj表示说话人,iii表示属于第jjj个说话人的第iii个话语;某个说话人的嵌入码中心记为cjc_jcj
- 基本思想,具体而言:
- 对于每一个ejie_{ji}eji而言,我们希望它与cjc_jcj靠近,与其他的ck、ck′c_k、c_{k'}ck、ck′远离
- 在一个batch内,对于一个ejie_{ji}eji而言,会出现多个其他说话人的中心点,如ck、ck′c_k、c_{k'}ck、ck′
- 根据最大间隔原理,只关注距离该ejie_{ji}eji最接近的其他说话人的中心,从图中来看,则是只关注ckc_kck,不关注ck′c_{k'}ck′
- 对神经网络而言,ckc_kck是区分ejie_{ji}eji属于cjc_jcj,最困难的一个其他说话人。也就是说,对于ejie_{ji}eji而言,ckc_kck是支持说话人(Support Speaker)
- 计算损失函数前的准备工作
- 假设,一个batch的维度为N×MN \times MN×M,NNN表示该batch包含的说话人个数,MMM表示该batch中每个说话人的话语数
- 该batch的数据,经过神经网络后,每个话语都向量化,得到嵌入码ejie_{ji}eji,从而:
cj=1M∑i=1Mejic_j=\frac{1}{M}\sum_{i=1}^{M}e_{ji} cj=M1i=1∑Meji - 对整个batch,计算相似度矩阵,维度为NM×NNM \times NNM×N:
Sji,k=w⋅cos(eji,ck)+bS_{ji,k}=w\cdot \cos (e_{ji},c_k)+b Sji,k=w⋅cos(eji,ck)+b
其中,- w>0,w、bw>0,w、bw>0,w、b都是可学习参数
- 相似度矩阵,表示batch中的每一个嵌入码ejie_{ji}eji,与batch内所有说话人的中心点ckc_kck,计算相似度,然后进行线性变换,因此维度是NM×NNM \times NNM×N
- 损失函数的定义:有两种方法实现最大间隔原理
- 基于对比的方法:对于每一个ejie_{ji}eji而言,损失函数为
L(eji)=1−σ(Sji,j)+max1≤k≤N,k≠jσ(Sji,k)L(e_{ji})=1-\sigma(S_{ji,j})+\max_{1\le k \le N,k \ne j} \sigma(S_{ji,k}) L(eji)=1−σ(Sji,j)+1≤k≤N,k=jmaxσ(Sji,k)
其中,- 1−σ(Sji,j)1-\sigma(S_{ji,j})1−σ(Sji,j)表示正样本对的余弦相似度越接近1越好
- max1≤k≤N,k≠jσ(Sji,k)\max_{1\le k \le N,k \ne j} \sigma(S_{ji,k})max1≤k≤N,k=jσ(Sji,k)表示最困难负样本对的余弦相似度越小越好
- 这种同时考虑正样本对和负样本对的思想,与Triplet Loss类似,不同之处在于:
- 使用中心点,模拟运行时的说话人嵌入码
- 负样本对的优化,只针对支持说话人
- 缺点:使用了max(⋅)\max(\cdot)max(⋅),这是不可导的函数
- 基于Softmax的方法,针对方法1的缺点,采用max(⋅)\max(\cdot)max(⋅)的可微分版本——Softmax来改进
L(eji)=−Sji,j+ln∑k=1Nexp(Sji,k)=−ln(exp(Sji,j))+ln∑k=1Nexp(Sji,k)=ln∑k=1Nexp(Sji,k)exp(Sji,j)=−lnexp(Sji,j)∑k=1Nexp(Sji,k)\begin{aligned} L(e_{ji})&=-S_{ji,j}+\ln \sum_{k=1}^{N} \exp(S_{ji,k}) \\ &=-\ln(\exp(S_{ji,j}))+\ln \sum_{k=1}^{N} \exp(S_{ji,k}) \\ &=\ln \frac{\sum_{k=1}^{N} \exp(S_{ji,k})}{\exp(S_{ji,j})} \\ &=- \ln \frac{\exp(S_{ji,j})}{\sum_{k=1}^{N} \exp(S_{ji,k})} \end{aligned} L(eji)=−Sji,j+lnk=1∑Nexp(Sji,k)=−ln(exp(Sji,j))+lnk=1∑Nexp(Sji,k)=lnexp(Sji,j)∑k=1Nexp(Sji,k)=−ln∑k=1Nexp(Sji,k)exp(Sji,j)
这个损失函数,将每个嵌入码推到其对应说话人中心点附近,并将其拉离所有其他说话人中心点
- 关键点
- 神经网络在优化时,会收敛到一个平凡解(Trivial Solutions),类似于微分方程的特解,会导致所有嵌入码都变成相同的值
- 为了避免平凡解,一个重要的技巧是:在计算ejie_{ji}eji的损失函数时,对于cjc_jcj的计算,不要将ejie_{ji}eji本身加进去,新的cjc_jcj表达式如下,式中的(−i)(-i)(−i)表示排除iii
cj(−i)=1M−1∑m=1,m≠iMejmc_j^{(-i)}=\frac{1}{M-1}\sum_{m=1,m \ne i}^{M}e_{jm} cj(−i)=M−11m=1,m=i∑Mejm
- 步骤总结
- 对每一个batch,经过神经网络,得到嵌入码
- 计算batch内每个说话人的中心点
- 计算相似度矩阵
- 根据相似度矩阵,计算每个嵌入码的损失函数,对batch内所有嵌入码的损失函数求和,得到一个batch的总损失
- 优点
- 动态地挖掘困难样本,每次参数优化都有足够的监督信息
- 训练时,神经网络前向推理次数,等于样本数,而不是排列组合数,比其他基于二值决策的损失函数更加高效
其他广义端到端损失函数
- Dynamic-additive-margin Softmax(DAM-Softmax)
- Angular Margin Centroid Loss(AMCL)
Prototypical Loss(原型损失)
- 原型损失来自于图像分类任务中的少样本学习,少样本学习描述的是这样一个问题:N-way K-shot,意思是说对于N个类别,每个类别K个样本,一共会有N×KN \times KN×K个样本,就利用这些样本,对神经网络进行训练。训练集N×KN \times KN×K,通常来自对巨型数据集的下采样
- 测试时,测试集也是按照N×KN \times KN×K这样来组织,但是每个N的K会很少,比如5-way 1-shot,就是5个类各1张图片,再另外给出一些图片,神经网络将这些图片分类到,给出的5个类中,注意,这5个类是训练集中不曾出现的
- 少样本学习在测试时,所需分的类别不会出现在训练集中,这和说话人识别的运行时情况很相似,而原型损失,更是采用距离度量的方式进行分类的,所以原型损失可以用于说话人识别
- 原型损失基本思想:对于给出的N×KN \times KN×K测试集,和一个样本,利用神经网络提取出测试集和样本的嵌入码,再利用每个类别的K个嵌入码,计算每个类别的“原型”,然后将样本的嵌入码与各类别的原型分别计算距离,取距离最近的一个类别,作为该样本的分类结果。这里所说的“距离最近”,要和所用的距离函数相关,比如:欧氏距离是值越小,越接近;余弦距离是值越大,越接近
- 数学形式
- 训练集D={(x1,y1),...,(xN,yN)}D=\left \{ (x_1,y_1),...,(x_N,y_N) \right \}D={(x1,y1),...,(xN,yN)},其中yi∈{1,...,K}y_i \in \left \{ 1,...,K \right \}yi∈{1,...,K},DkD_kDk表示DDD中属于类别kkk的样本
- 从训练集中,采样NCN_CNC个类别,NC≤KN_C \le KNC≤K,并为NCN_CNC中的每个类别kkk,采样NSN_SNS个样本作为支持集SkS_kSk,采样NQN_QNQ个样本作为查询集QkQ_kQk,SkS_kSk和QkQ_kQk无重叠样本。总的支持集S=∑k=1NCSkS=\sum_{k=1}^{N_C}S_kS=∑k=1NCSk和总的查询集Q=∑k=1NCQkQ=\sum_{k=1}^{N_C}Q_kQ=∑k=1NCQk,构成一个batch
- 对batch中的每一个样本,经过神经网络,得到对应的嵌入码f(xi)f(x_i)f(xi),然后根据每个SkS_kSk,计算每个类别的“原型”
ck=1∣Sk∣∑(xi,yi)∈Skf(xi)c_k=\frac{1}{\left | S_k \right | } \sum_{(x_i,y_i) \in S_k} f(x_i)ck=∣Sk∣1(xi,yi)∈Sk∑f(xi)
其中,∣Sk∣\left | S_k \right |∣Sk∣表示SkS_kSk的l1l_1l1范数,即SkS_kSk所含样本个数 - 将查询集QQQ中的每个样本的嵌入码,与NCN_CNC个原型,计算距离d(f(xi),ck)d(f(x_i),c_k)d(f(xi),ck),然后计算Softmax Loss
L(xi,yi)=−lnexp(−d(f(xi),cyi))∑k=1NCexp(−d(f(xi),ck))L(x_i,y_i)=- \ln \frac{exp(-d(f(x_i),c_{y_i}))}{\sum_{k=1}^{N_C} exp(-d(f(x_i),c_k))} L(xi,yi)=−ln∑k=1NCexp(−d(f(xi),ck))exp(−d(f(xi),cyi))
其中,yiy_iyi是嵌入码f(xi)f(x_i)f(xi)所属的GT类别,d(f(xi),ck)d(f(x_i),c_k)d(f(xi),ck)是欧氏距离,因为值越小表示越接近,所以要取符号 - 将查询集QQQ中的每个样本的LxiL_{x_i}Lxi加起来,求均值,即得到这个batch的总损失
J=1NC×NQ∑(xi,yi)∈QL(xi,yi)J=\frac{1}{N_C \times N_Q} \sum_{(x_i,y_i) \in Q} L(x_i,y_i) J=NC×NQ1(xi,yi)∈Q∑L(xi,yi)
- 关键点
- 距离d(f(xi),ck)d(f(x_i),c_k)d(f(xi),ck)经过原论文的实验,发现欧氏距离优于余弦距离
- 如果在测试时是N-way K-shot的,那么训练时的NCN_CNC要大于N,比如测试时5-way,则训练时采取20-way,shot取值相同即可。可以理解为训练时,要对网络要求更高
- 原型损失与GE2E比较类似,都利用了中心点,但是根据In defence of metric learning for speaker recognition,原型损失优于GE2E
总结
| 损失函数 | 多说话人交叉熵 | Pairwise Loss | Triplet Loss | End-to-End Loss | GE2E Loss | Prototypical Loss |
|---|---|---|---|---|---|---|
| 输入 | 单个话语 | 两个话语 | 三个话语 | N+1N+1N+1 | N×MN \times MN×M | NC×(NS+NQ)N_C \times (N_S+N_Q)NC×(NS+NQ) |
| 中心点使用 | 否 | 否 | 否 | 使用一个说话人的中心点 | 使用一个batch中所有说话人的中心点 | 使用一个batch中所有说话人的支持集的中心点 |
| 实现方式 | Softmax | BCE | 对比 | BCE | 对比或Softmax | Softmax |
相关内容
热门资讯
埃菲尔铁塔在哪 中国仿建埃菲尔...
2019年4月26日,广西南宁市,街头惊现一座巨型山寨版埃菲尔铁塔,高约20米,白色塔身,造型逼真,...
苗族的传统节日 贵州苗族节日有...
【岜沙苗族芦笙节】岜沙,苗语叫“分送”,距从江县城7.5公里,是世界上最崇拜树木并以树为神的枪手部落...
北京的名胜古迹 北京最著名的景...
北京从元代开始,逐渐走上帝国首都的道路,先是成为大辽朝五大首都之一的南京城,随着金灭辽,金代从海陵王...
长白山自助游攻略 吉林长白山游...
昨天介绍了西坡的景点详细请看链接:一个人的旅行,据说能看到长白山天池全凭运气,您的运气如何?今日介绍...
应用未安装解决办法 平板应用未...
---IT小技术,每天Get一个小技能!一、前言描述苹果IPad2居然不能安装怎么办?与此IPad不...
脚上的穴位图 脚面经络图对应的...
人体穴位作用图解大全更清晰直观的标注了各个人体穴位的作用,包括头部穴位图、胸部穴位图、背部穴位图、胳...
猫咪吃了塑料袋怎么办 猫咪误食...
你知道吗?塑料袋放久了会长猫哦!要说猫咪对塑料袋的喜爱程度完完全全可以媲美纸箱家里只要一有塑料袋的响...
demo什么意思 demo版本...
618快到了,各位的小金库大概也在准备开闸放水了吧。没有小金库的,也该向老婆撒娇卖萌服个软了,一切只...
世界上最漂亮的人 世界上最漂亮...
此前在某网上,选出了全球265万颜值姣好的女性。从这些数量庞大的女性群体中,人们投票选出了心目中最美...
埃菲尔铁塔在哪 中国仿建埃菲尔...
2019年4月26日,广西南宁市,街头惊现一座巨型山寨版埃菲尔铁塔,高约20米,白色塔身,造型逼真,...
苗族的传统节日 贵州苗族节日有...
【岜沙苗族芦笙节】岜沙,苗语叫“分送”,距从江县城7.5公里,是世界上最崇拜树木并以树为神的枪手部落...
北京的名胜古迹 北京最著名的景...
北京从元代开始,逐渐走上帝国首都的道路,先是成为大辽朝五大首都之一的南京城,随着金灭辽,金代从海陵王...
长白山自助游攻略 吉林长白山游...
昨天介绍了西坡的景点详细请看链接:一个人的旅行,据说能看到长白山天池全凭运气,您的运气如何?今日介绍...
世界上最漂亮的人 世界上最漂亮...
此前在某网上,选出了全球265万颜值姣好的女性。从这些数量庞大的女性群体中,人们投票选出了心目中最美...
应用未安装解决办法 平板应用未...
---IT小技术,每天Get一个小技能!一、前言描述苹果IPad2居然不能安装怎么办?与此IPad不...
脚上的穴位图 脚面经络图对应的...
人体穴位作用图解大全更清晰直观的标注了各个人体穴位的作用,包括头部穴位图、胸部穴位图、背部穴位图、胳...
demo什么意思 demo版本...
618快到了,各位的小金库大概也在准备开闸放水了吧。没有小金库的,也该向老婆撒娇卖萌服个软了,一切只...
猫咪吃了塑料袋怎么办 猫咪误食...
你知道吗?塑料袋放久了会长猫哦!要说猫咪对塑料袋的喜爱程度完完全全可以媲美纸箱家里只要一有塑料袋的响...