
elasticsearch基础(一)
一、初识elasticsearch
1. 了解ES
1.1 什么是elasticsearch
elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容。
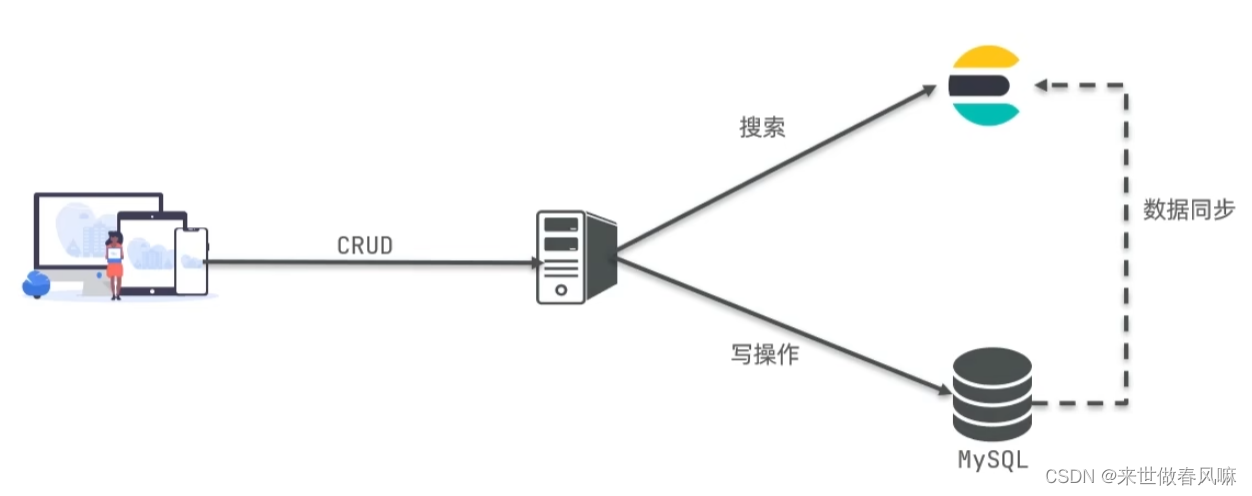
elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域。
elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。

1.2 elasticsearch的发展
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。
官网地址:https://lucene.apache.org/ 。
Lucene的优势:
(1)易扩展
(2)高性能(基于倒排索引)
Lucene的缺点:
(1)只限于Java语言开发
(2)学习曲线陡峭
(3)不支持水平扩展
2004年Shay Banon 基于Lucene开发了Compass
2010年Shay Banon 重写了Compass,取名为Elasticsearch。
官网地址: https://www.elastic.co/cn/
相比与lucene,elasticsearch具备下列优势:
(1)支持分布式,可水平扩展
(2)提供Restful接口,可被任何语言调用
2. 倒排索引
2.1 正向索引和倒排索引
传统数据库(如MySQL)采用正向索引,例如给下表(tb_goods)中的id创建索引:
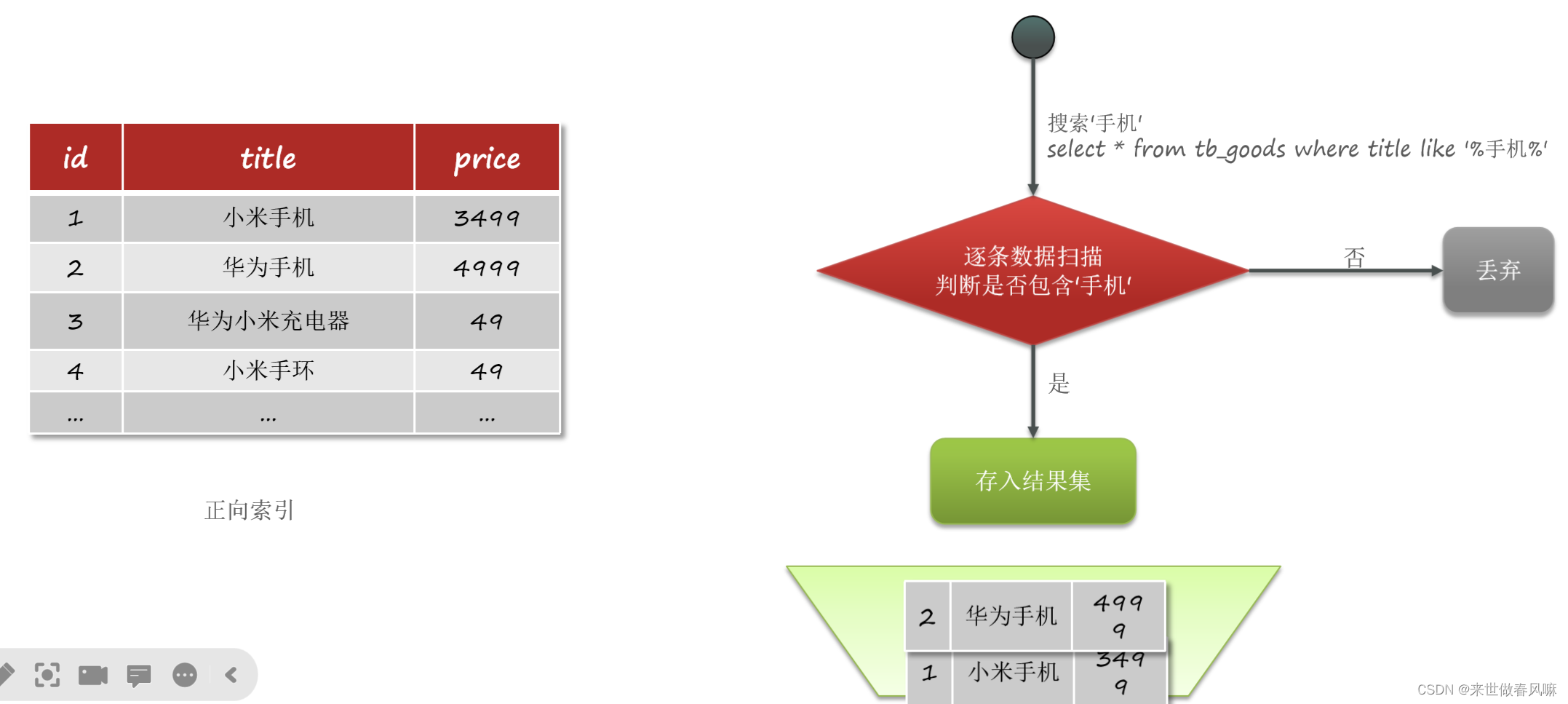
elasticsearch采用倒排索引:
(1)文档(document):每条数据就是一个文档
(2)词条(term):文档按照语义分成的词语
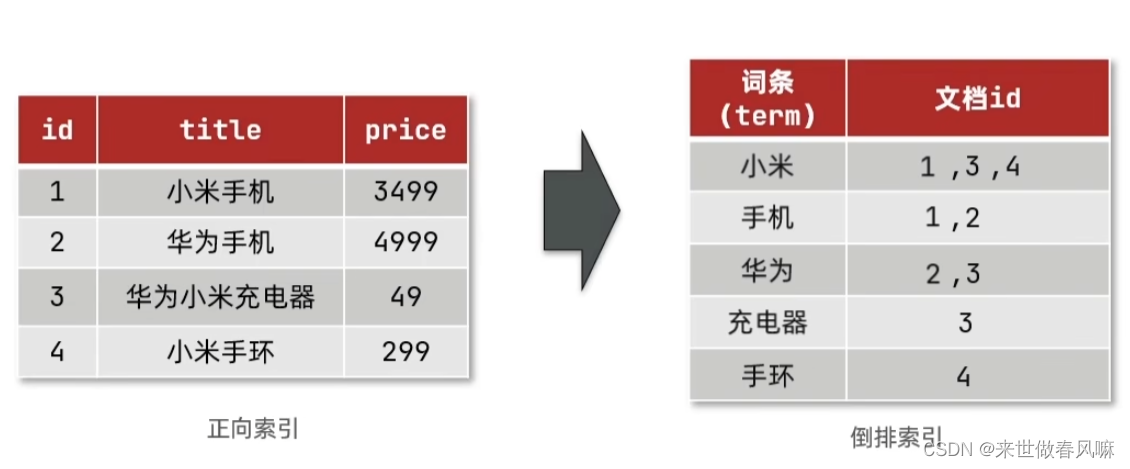
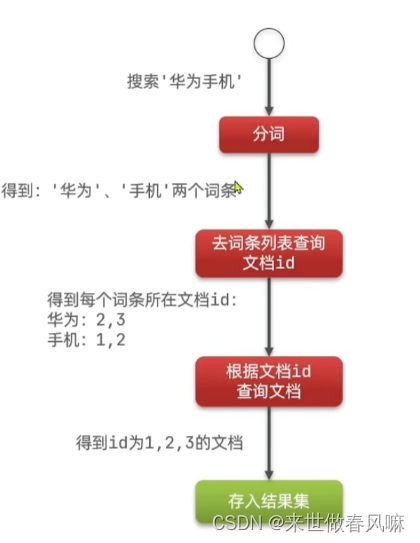
(1)什么是正向索引?
基于文档id创建索引。查询词条时必须先找到文档,而后判断是否包含词条
(2)什么是倒排索引?
对文档内容分词,对词条创建索引,并记录词条所在文档的信息。查询时先根据词条查询到文档id,而后获取到文档
3. es的一些概念
3.1 文档
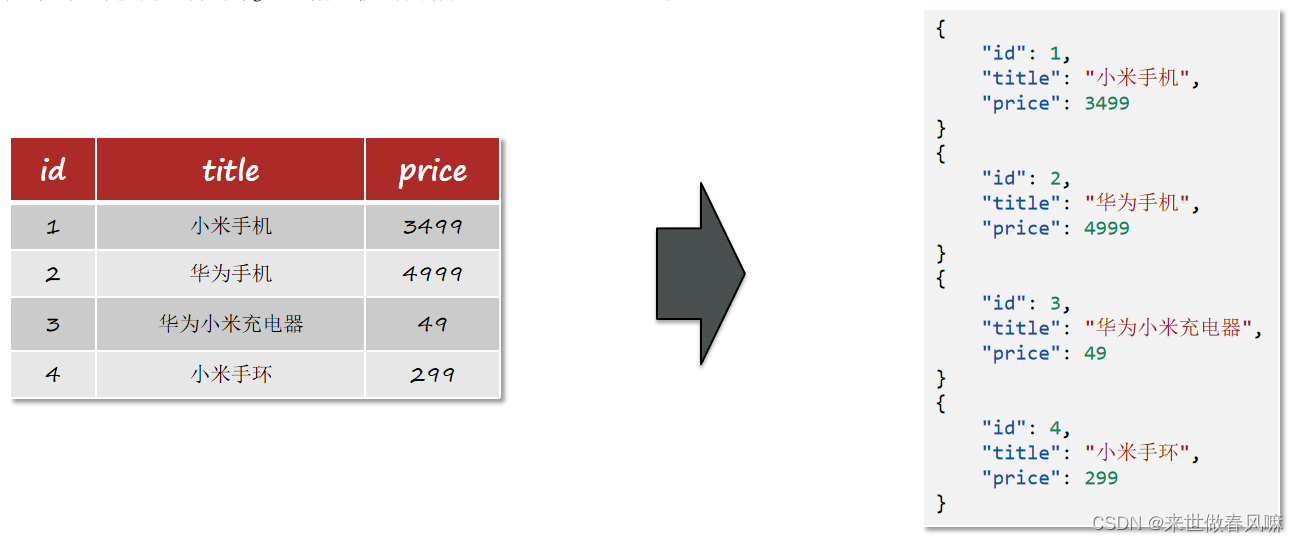
elasticsearch是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息。
文档数据会被序列化为json格式后存储在elasticsearch中。
3.2 索引(Index)
索引(index):相同类型的文档的集合
映射(mapping):索引中文档的字段约束信息,类似表的结构约束

3.3 概念对比
MySQL
Elasticsearch
说明
Table
Index
索引(index),就是文档的集合,类似数据库的表(table)
Row
Document
文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式
Column
Field
字段(Field),就是JSON文档中的字段,类似数据库中的列(Column)
Schema
Mapping
Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema)
SQL
DSL
DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD
(1)Mysql:擅长事务类型操作,可以确保数据的安全和一致性
(2)Elasticsearch:擅长海量数据的搜索、分析、计算
3.4 分词器
es在创建倒排索引时需要对文档分词;在搜索时,需要对用户输入内容分词。但默认的分词规则对中文处理并不友好。
我们在kibana的DevTools中测试:
语法说明:
(1)POST:请求方式
(2)/_analyze:请求路径,这里省略了http://192.168.150.101:9200,有kibana帮我们补充 (3)请求参数,json风格:
1️⃣analyzer:分词器类型,这里是默认的standard分词器
2️⃣text:要分词的内容

处理中文分词,一般会使用IK分词器。https://github.com/medcl/elasticsearch-analysis-ik
ik分词器包含两种模式:
(1)ik_smart:最少切分,粗粒度
(2)ik_max_word:最细切分,细粒度
3.5 ik分词器-拓展词库
要拓展ik分词器的词库,只需要修改一个ik分词器目录中的config目录中的IkAnalyzer.cfg.xml文件:
然后在名为ext.dic的文件中,添加想要拓展的词语即可:


3.6 ik分词器-停用词库
要禁用某些敏感词条,只需要修改一个ik分词器目录中的config目录中的IkAnalyzer.cfg.xml文件:
然后在名为stopword.dic的文件中,添加想要拓展的词语即可:


4. 安装es、kibana
二、索引库操作
1. mapping映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
(1)type:字段数据类型,常见的简单类型有: 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址) 数值:long、integer、short、byte、double、float、 布尔:boolean 日期:date 对象:object index:是否创建索引,默认为true analyzer:使用哪种分词器 properties:该字段的子字段
2. 索引库的CRUD
三、文档操作
四、RestAPI