Linux- 系统随你玩之--文本处理三剑客-带头一哥-awk
文章目录
- 1、awk概述
- 2、awk原理
- 2.1、 awk 工作原理
- 2.2、 与sed工作原理比较
- 2.3、 awk与sed的区别
- 3、使用方法及原理
- 3.1、格式如下:
- 3.2、 匹配规则
- 3.3、 参数说明
- 3.4、处理规则与流程控制
- 3.5、 常用 awk 内置变量
- 3.6、 awk 正则表达式解释
- 4、操作实例
- 4.1、 准备工作
- 4.2、 操作实例
1、awk概述
AWK 来自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。它是专门为文本处理设计的编程语言,也是行处理软件,通常用于扫描,过滤,为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其它的功能。
平时主要用来处理文本,将文本按照指定的格式输出。其中包含了变量,循环以及数组。
2、awk原理
2.1、 awk 工作原理
- 当读到第一行时,匹配条件,然后执行指定动作,在接着读取第二行数据处理,不会默认输出。
- 如果没有定义匹配条件,则是默认匹配所有数据行,awk隐含循环,条件匹配多少次,动作就会执行多少次。
- 逐行读取文本,默认以空格或tab键为分割符进行分割,将分割所得的各个字段,保存到内建变量中,并按模式或或条件执行编辑命令。
2.2、 与sed工作原理比较
sed命令常用于一整行的处理。而awk比较倾向于将一行分成多个 “ 字段 ” 然后再进行处理。
awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示。
在使用awk命令的过程中,可以使用逻辑操作符。(&&“表示"与”、“||表示"或”、"!“表示非”;还可以进行简单的数学运算,如+、一、*、/、%、^分别表示加、减、乘、除、取余和乘方。)
2.3、 awk与sed的区别
awk 用于”比较规范“的文本处理,用于统计指定内容的数量并输出字段。
sed 将不规范或无规则的文本,处理成相对”比较规范“的文本。
3、使用方法及原理
3.1、格式如下:
格式1: awk '{pattern + action}' filenames //awk [选项] '匹配规则和处理规则 ' [处理文本路径]格式2: awk -f 脚本文件 filenames
3.2、 匹配规则
它的匹配规则主要是:正则表达式
处理规则主要是:
- 设置变量
- 设置数组
- 定义函数 (用的比较少)
- 数组循环
- 加减乘除运算
- 字符串拼接
处理规则
3.3、 参数说明
-F参数:指定分隔符,可指定一个或多个
print 后面做字符串的拼接
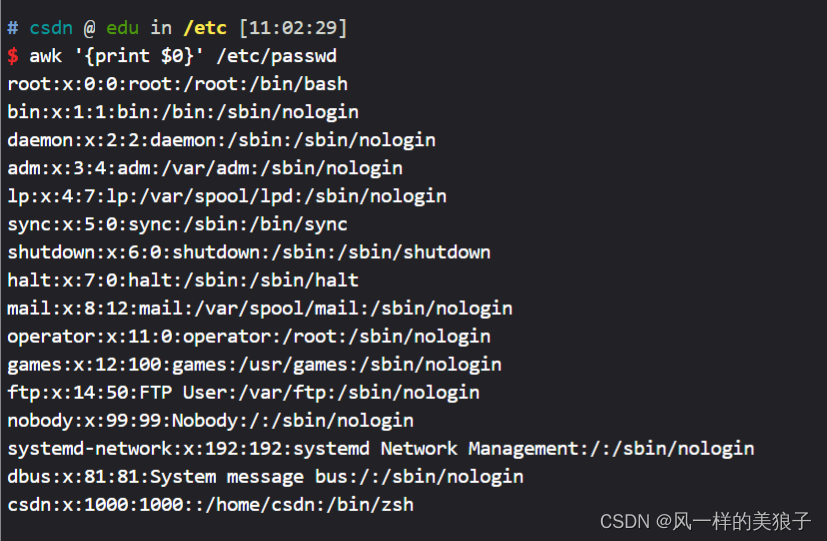
awk -F":" '{ print $1 }' /etc/passwd
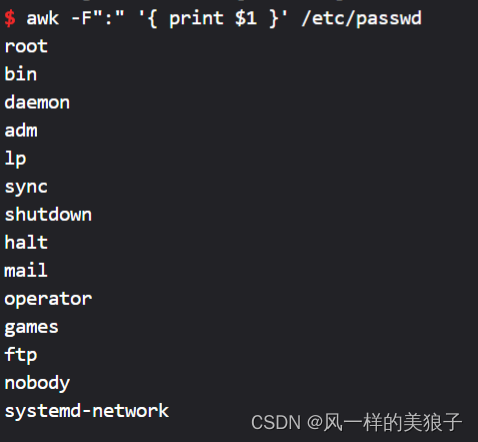
awk -F":" '{ print $1 $3 }' /etc/passwd
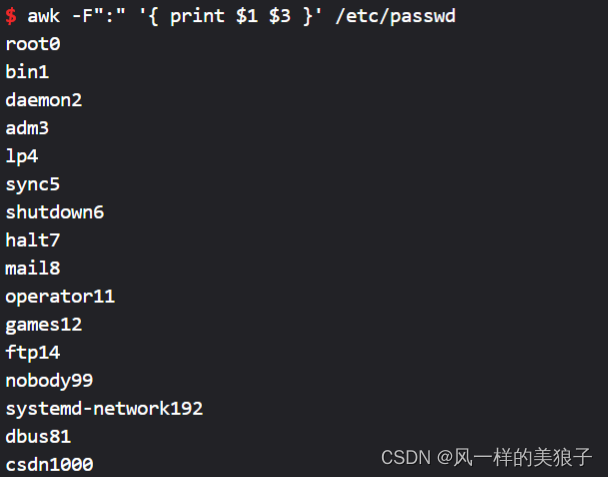
awk -F":" '{ print $1 " " $3 }' /etc/passwd
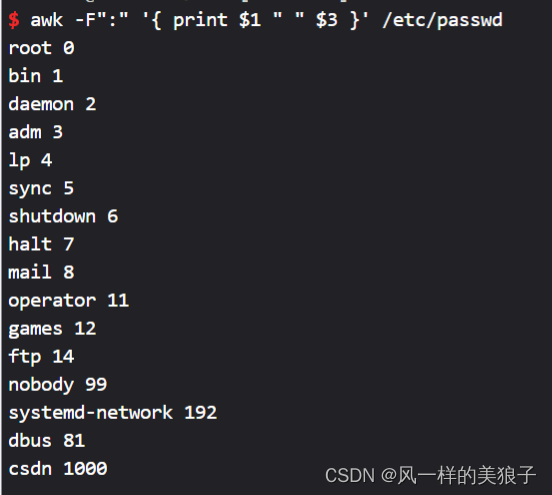
awk -F":" '{ print "username: " $1 "\t\tuid:" $3" }' /etc/passwd

3.4、处理规则与流程控制
BEGIN 和 END 模块
通常,对于每个输入行, awk 都会执行每个脚本代码块一次。然而,在许多编程情况中,可能需要在 awk 开始处理输入文件中的文本之前执行初始化代码。对于这种情况, awk 允许您定义一个 BEGIN 块。
因为 awk 在开始处理输入文件之前会执行 BEGIN 块,因此它是初始化 FS(字段分隔符)变量、打印页眉或初始化其它在程序中以后会引用的全局变量的极佳位置。
awk 还提供了另一个特殊块,叫作 END 块。 awk 在处理了输入文件中的所有行之后执行这个块。通常, END 块用于执行最终计算或打印应该出现在输出流结尾的摘要信息。
小结:
逐行执行开始之前执行什么任务,结束之后再执行什么任务,用BEGIN、END。
BEGIN:一般用来做初始化操作,仅在读取数据记录之前执行一次。
END:一般用来做汇总操作,仅在读取完数据记录之后执行一次。
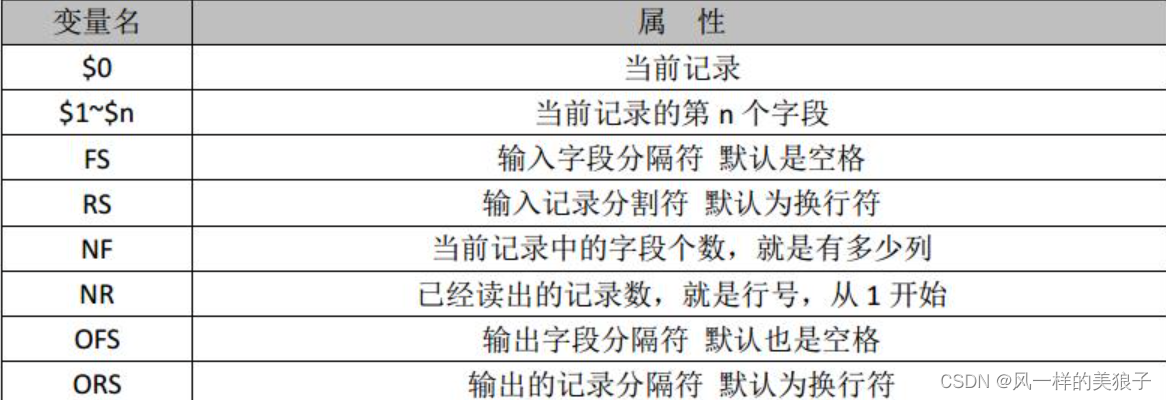
3.5、 常用 awk 内置变量
3.6、 awk 正则表达式解释
4、操作实例
4.1、 准备工作
准备文件fyydlz.txt的文本如下(可以利用touch命令和vi命令组合创建):
- hello world fyydlz
- wold hello
- nothing is important
- i like fyydlz fyydlz
4.2、 操作实例
这里是最常用的几个操作例子:
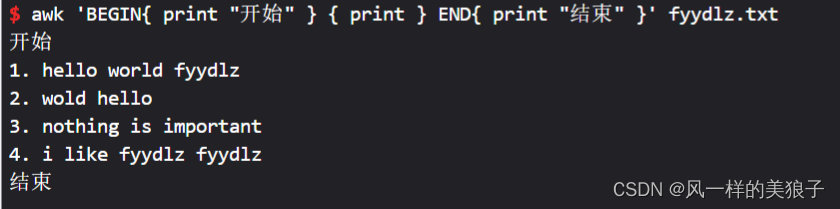
1、打印“开始”,打印每行,打印“结束”:
awk 'BEGIN{ print "开始" } { print } END{ print "结束" }' fyydlz.txt
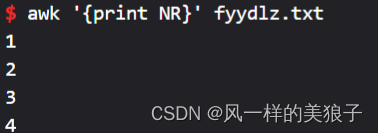
2、打印每行的行号:
awk '{print NR}' fyydlz.txt
3、打印每行的文本:
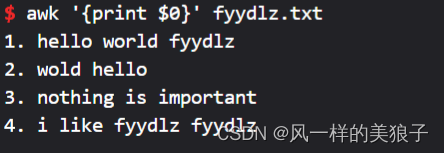
awk '{print $0}' fyydlz.txt
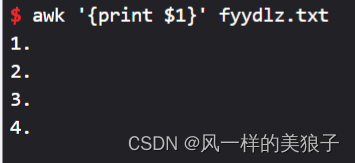
4、打印每行的第1列(默认用空格分离):
awk '{print $1}' fyydlz.txt
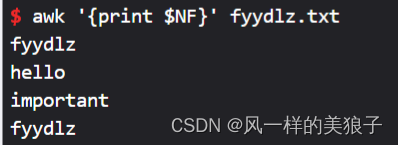
5、打印每行的最后1列(默认用空格分离):
awk '{print $NF}' fyydlz.txt
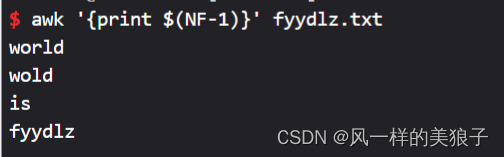
6、打印每行的倒数第2列(默认用空格分离):
awk '{print $(NF-1)}' fyydlz.txt
7、打印每行,并为每行带上行号:
awk '{print NR":",$0}' fyydlz.txt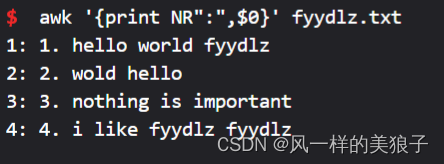
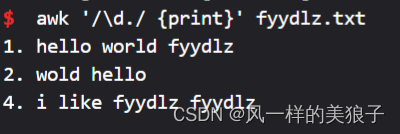
8、打印含有序号的行:
awk '/\d./ {print}' fyydlz.txt