基于python下selenium库实现交互式图片保存操作(批量保存浏览器中的图片)
Selenium是最广泛使用的开源Web UI(用户界面)自动化测试套件之一,可以通过编程与浏览量的交互式操作对网页进行自动化控制。基于这种操作进行数据保存操作,尤其是在图像数据的批量保存上占据优势。本博文基于selenium 与jupyterlab实现批量保存浏览器搜索到的图片
Selenium的详细使用可以参考:https://blog.csdn.net/sinat_28631741/article/details/115634230
1、Selenium环境安装
使用Selenium进行自动化操作要求电脑局部python环境,且安装好了谷歌浏览器。
1.1 python包安装
Selenium安装命令为:
pip install selenium
为了能进行交互式执行代码片段,建议安装jupyter lab,安装命令
pip install jupyterlab
安装好后在命令行下执行以下命令即可弹出浏览器界面,具体页面如下所示
Jupyter lab
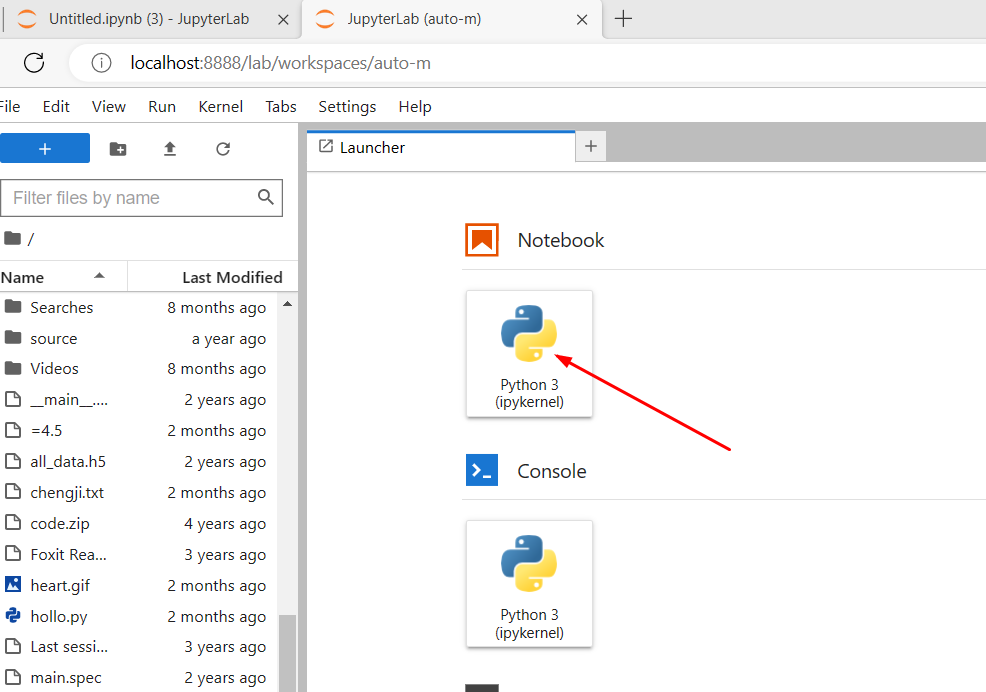
按照上图,点击Python 3即可进入交互式编程界面,具体如下所示
1.2 谷歌驱动下载
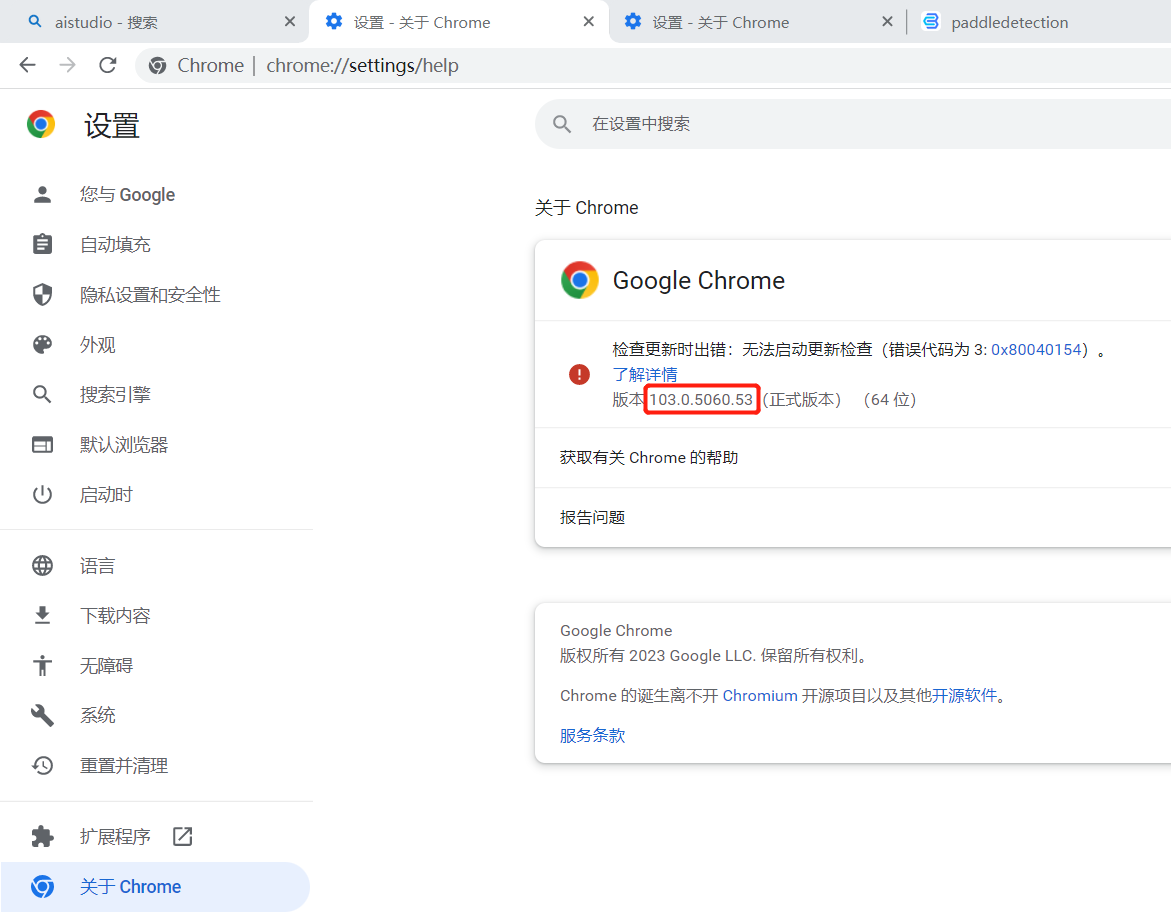
先打开本机的谷歌浏览器,然后在地址栏输入chrome://settings/help,即可进入浏览器的设置页面,然后查看自己浏览器的版本信息。这里的版本是103.0(记住版本号的前两位就行)
打开https://registry.npmmirror.com/binary.html?path=chromedriver/
,下载与浏览器版本号最接近的驱动
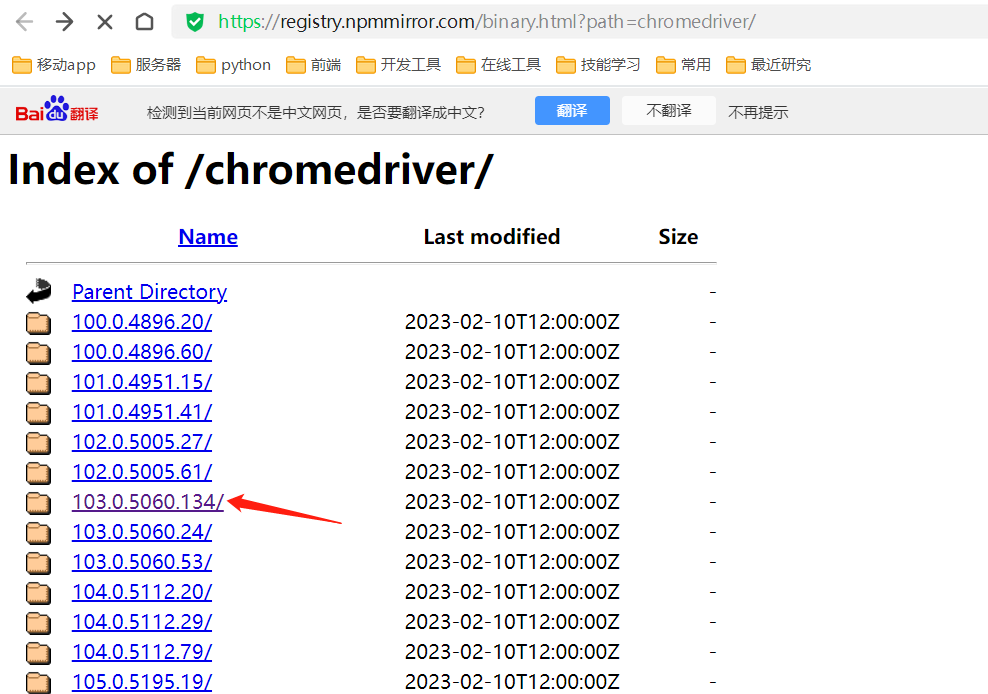
下载win32版本,然后将其解压,将chromedriver.exe复制到C:\Windows\System32目录即可(或者是系统环境变量path配置项中的其他路径)
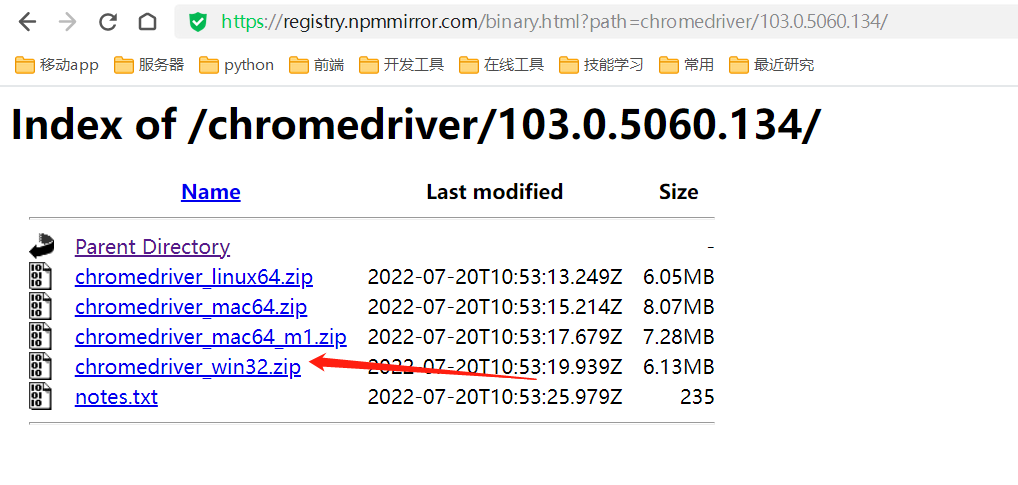
2、 爬取图片
2.1 控制开启浏览器
在jupyter的交互式单元格内输入以下代码,即可控制浏览器自动打开www.baidu.com
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECbrowser = webdriver.Chrome()
browser.get('https://image.baidu.com/')
2.2 交互式搜索图片
在上述步骤中弹出的浏览器窗口中,按照个人爬虫需求,输入关键词,并拖动页面的滚动条,使页面中的图片变多(满足需求就可,越后面的图片与关键词差距越大)
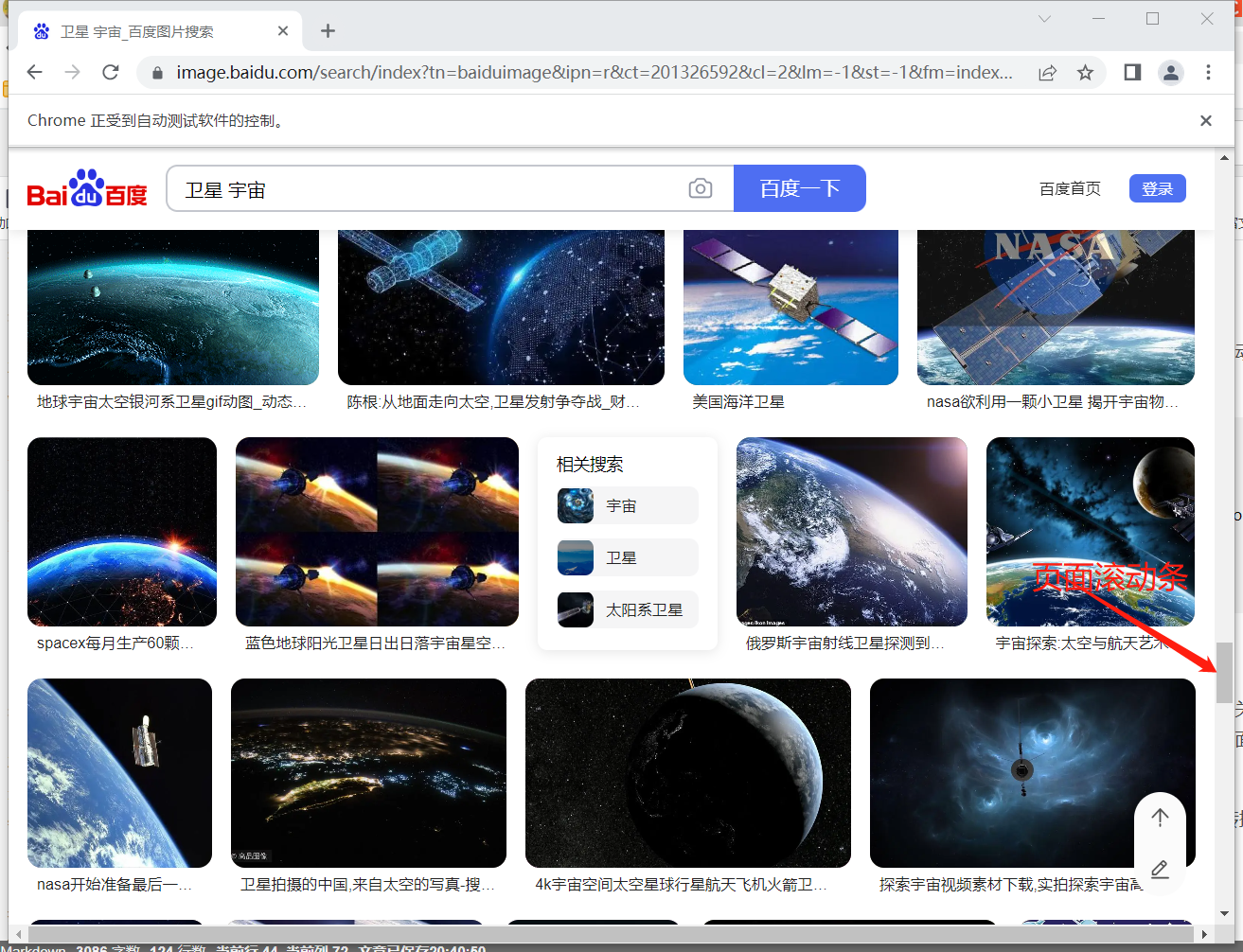
2.3 执行js进行转换
利用代码调用浏览器执行js,将浏览器中页面内所有的img标签的src转换为base64格式。因为直接根据url利用python下载图片的时候有极大可能会被服务器拒绝下载,故此,利用js将现有的图像信息已base64格式存储到网站图片的src中。
js = """_fetch = function(i,src){return fetch(src).then(function(response) {if(!response.ok) throw new Error("No image in the response");var headers = response.headers;var ct = headers.get('Content-Type');var contentType = 'image/png';if(ct !== null){contentType = ct.split(';')[0];}return response.blob().then(function(blob){return {'blob': blob,'mime': contentType,'i':i,};});});};_read = function(response){return new Promise(function(resolve, reject){var blob = new Blob([response.blob], {type : response.mime});var reader = new FileReader();reader.onload = function(e){resolve({'data':e.target.result, 'i':response.i});};reader.onerror = reject;reader.readAsDataURL(blob);});};_replace = function(){for (var i = 0, len = q.length; i < len; i++) {imgs[q[i].item].src = q[i].data;}alert('处理完成!');}var q = [];var imgs = document.querySelectorAll('img');for (var i = 0, len = imgs.length; i < len; i++) {_fetch(i,imgs[i].src).then(_read).then(function(data){q.push({'data': data.data,'item': data.i,});});}setTimeout(_replace, 2000 );"""
browser.execute_script(js)
浏览器在执行完python程序嵌入的js代码后会弹出以下提示信息,这表示图像转base64操作完成。
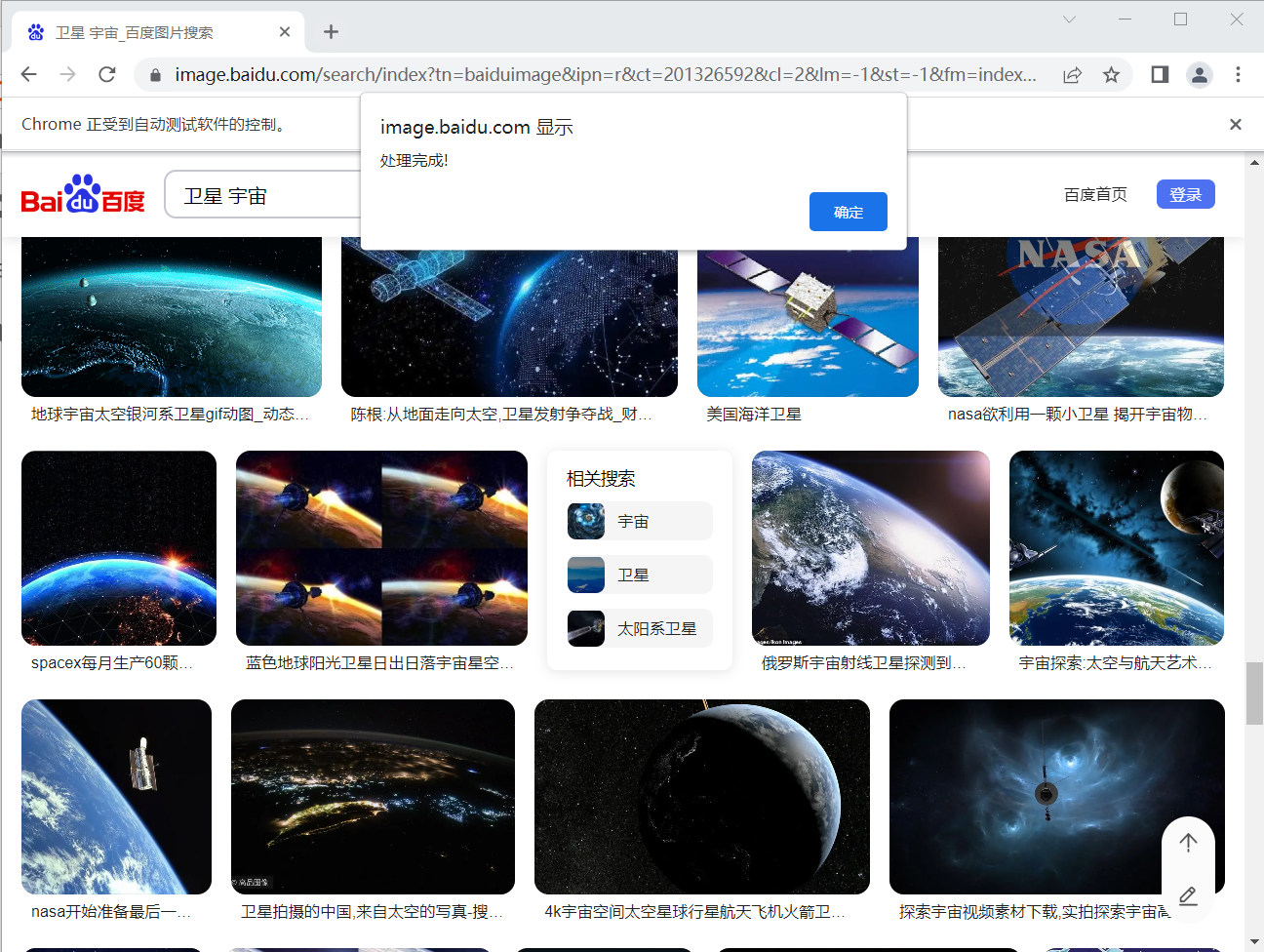
2.4 保存图片
利用selenium获取页面中的节点元素,在https://image.baidu.com/中图像的css选择器路径为’#imgid > div > ul > li’,遍历所获取的页面元素,然后提取其中img元素的src属性,将其转换为img对象,然后使用opencv保存为图像。
执行以下代码先创建一个image目录,用于保存图片
import base64
import numpy as np
import cv2def base64img2file(imgname:str,imgsrc: str):#将base64转码为byte,然后再使用opencv转image对象img_data = base64.b64decode(imgsrc.split(',')[1])nparr = np.fromstring(img_data, np.uint8)img_np = cv2.imdecode(nparr, cv2.IMREAD_COLOR)if img_np is not None:cv2.imwrite(imgname,img_np)
ul_list = browser.find_elements(By.CSS_SELECTOR, '#imgid > div > ul > li') #按CSS选择器for i,li in enumerate(ul_list):print(i,li)img=li.find_element(By.CSS_SELECTOR, 'img')base64str=img.get_attribute('src')imgname='image/%s.jpg'%iif base64str:base64img2file(imgname,base64str)
代码执行输出如下所示
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
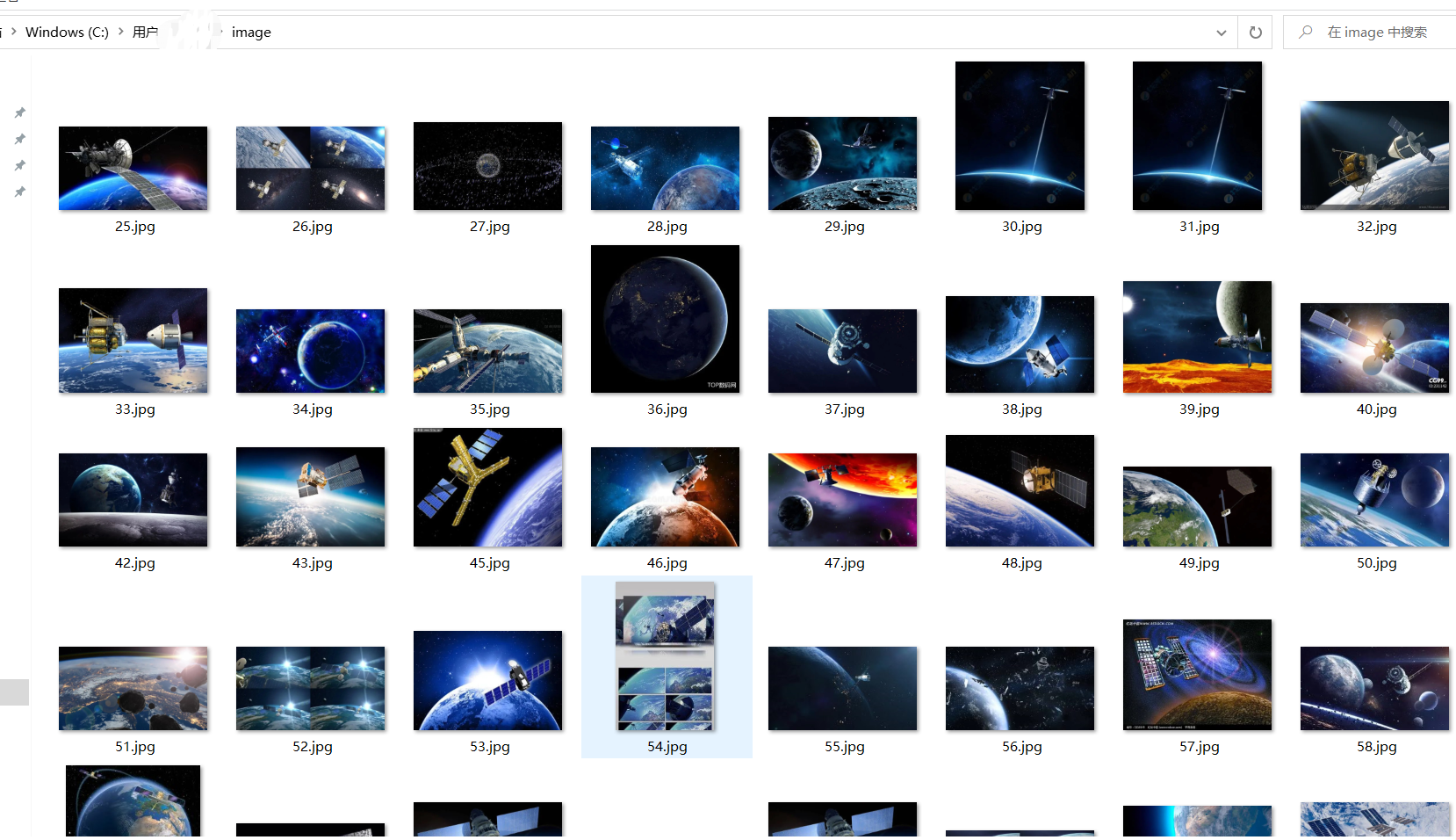
保存后的图像如下所示: