
GO语音-切片使用的雷区与性能优化相关
文章目录
- 前言
- 一、切片是什么?
- 二、切片使用注意项
- 1.避免复制数组
- 2.切片初始化
- 3.切片GC
- 三、切片使用注意什么
- 1. 大家来思考一个代码示例:
- 2. 修改切片的值
- 3. 降低切片重复申请内存
- 总结
前言
在 Go 语言中,切片(slice)可能是使用最为频繁的数据结构之一,切片类型为处理同类型数据序列提供一个方便而高效的方式。
一、切片是什么?
Go 的切片(slice)是在数组(array)之上的抽象数据类型,数组类型定义了长度和元素类型。例如, [3]int 类型表示由 3 个 int 整型组成的数组,数组以索引方式访问,例如表达式 s[n] 访问数组的第 n 个元素。数组的长度是固定的,长度是数组类型的一部分。长度不同的 2 个数组是不可以相互赋值的,因为这 2 个数组属于不同的类型。例如下面的代码是不合法的:
a := [3]int{1, 2, 3}
b := [4]int{2, 4, 5, 6}
a = b // cannot use b (type [4]int) as type [3]int in assignment
在 C 语言中,数组变量是指向第一个元素的指针,但是 Go 语言中并不是。Go 语言中,数组变量属于值类型(value type),因此当一个数组变量被赋值或者传递时,实际上会复制整个数组。例如,将 a 赋值给 b,修改 a 中的元素并不会改变 b 中的元素:
注释\color{#FF0000}{注释}注释: makemap 和 makeslice 的区别,带来一个不同点:当 map 和 slice 作为函数参数时,在函数参数内部对 map 的操作会影响 map 自身;而对 slice 却不会。
主要原因:一个是指针(*hmap),一个是结构体(slice)。Go 语言中的函数传参都是值传递,在函数内部,参数会被 copy 到本地。*hmap指针 copy 完之后,仍然指向同一个 map,因此函数内部对 map 的操作会影响实参。而 slice 被 copy 后,会成为一个新的 slice,对它进行的操作不会影响到实参。
二、切片使用注意项
1.避免复制数组
为了避免复制数组,一般会传递指向数组的指针。例如:
func square(arr *[3]int) {for i, num := range *arr {(*arr)[i] = num * num}
}func TestArrayPointer(t *testing.T) {a := [...]int{1, 2, 3}square(&a)fmt.Println(a) // [1 4 9]if a[1] != 4 && a[2] != 9 {t.Fatal("failed")}
}
2.切片初始化
切片使用字面量初始化时和数组很像,但是不需要指定长度:
languages := []string{"Go", "Python", "C"}
或者使用内置函数 make 进行初始化,make 的函数定义如下:
func make([]T, len, cap) []T
第一个参数是 []T,T 即元素类型,第二个参数是长度 len,即初始化的切片拥有多少个元素,第三个参数是容量 cap,容量是可选参数,默认等于长度。使用内置函数 len 和 cap 可以得到切片的长度和容量,例如:
func printLenCap(nums []int) {fmt.Printf("len: %d, cap: %d %v\n", len(nums), cap(nums), nums)
}func TestSliceLenAndCap(t *testing.T) {nums := []int{1}printLenCap(nums) // len: 1, cap: 1 [1]nums = append(nums, 2)printLenCap(nums) // len: 2, cap: 2 [1 2]nums = append(nums, 3)printLenCap(nums) // len: 3, cap: 4 [1 2 3]nums = append(nums, 3)printLenCap(nums) // len: 4, cap: 4 [1 2 3 3]
}
容量是当前切片已经预分配的内存能够容纳的元素个数,如果往切片中不断地增加新的元素。如果超过了当前切片的容量,就需要分配新的内存,并将当前切片所有的元素拷贝到新的内存块上。因此为了减少内存的拷贝次数,容量在比较小的时候,一般是以 2 的倍数扩大的,例如 2 4 8 16 …,当达到 2048 时,会采取新的策略,避免申请内存过大,导致浪费。Go 语言源代码 runtime/slice.go 中是这么实现的,不同版本可能有所差异:
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {newcap = cap
} else {if old.len < 1024 {newcap = doublecap} else {// Check 0 < newcap to detect overflow// and prevent an infinite loop.for 0 < newcap && newcap < cap {newcap += newcap / 4}// Set newcap to the requested cap when// the newcap calculation overflowed.if newcap <= 0 {newcap = cap}}
}
3.切片GC
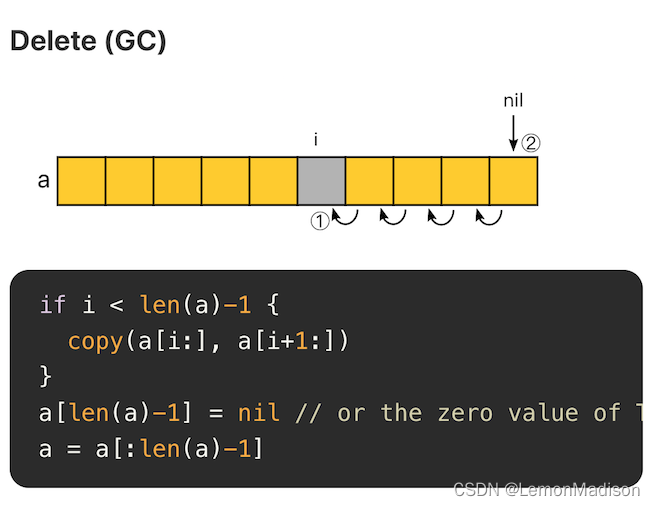
删除后,将空余的位置置空,有助于垃圾回收。
三、切片使用注意什么
1. 大家来思考一个代码示例:
// 初始化一个新的切片 seqseq := []string{"a", "b"}for k := range seq {if seq[k] == "a" {fmt.Println(k)seq = append(seq[:k],seq[k+1:]...)fmt.Println(seq)}}
请问这段代码会出现什么问题?
这段代码其实会出现代码下标越界的问题
为什么会出现这个问题呢?是因为在for循环中一遍遍历着数组,一遍去删除数组,变量seq 的len在循环开始前,仅会计算一次,如果在循环中修改切片的长度不会改变本次循环的次数。
2. 修改切片的值
请看示例:
func test03() {list2 := []string{"a","b"}for _, test := range list2 {test = "c"fmt.Println(test)}fmt.Println(list2)
}
请问输出结果是什么?最后输出的list2是 a b 还是c c
c
c
[a b]这是为什么呢?
这是因为当for range去遍历一个数组切片的时候,新的变量test是重新分配的一块内存地址,只是将本次遍历的值赋值给了新的地址中的test变量,当我们去对 test 进行赋值的时候,并不会影响指向 list2 的指针所对应的值
如果我们需要改变 list2 中的 a 和 b 需要对代码改为:
func test03() {list2 := []string{"a","b"}for i, test := range list2 {list2[i] = "c"fmt.Println(test)}fmt.Println(list2)
}
输出结果:
a
b
[c c]3. 降低切片重复申请内存
内存复用的例子
func test02() {for i := 0; i < 1000; i++ {buf := make([]int, 0, 3)for j := 0; j < 3; j++ {buf = append(buf, i)}buf = buf[:0] // 内存复用//fmt.Printf("buf, len = %d, cap = %d\n", len(buf), cap(buf))}}
内存复用详细讲解
举个分页查询例子
for {//这里的3个切片尽量放在for外面,这样可以只申请一次内存tmpContainers := make([]*container.Container, 0, option.Opt.MaxDeleteContainerPagingLimit)tmpContainerIDs := make([]int, 0, option.Opt.MaxDeleteContainerPagingLimit)tmpContainerHashIDs := make([]string, 0, option.Opt.MaxDeleteContainerPagingLimit)err = engine.Paging(container.TableContainer, "id", startID, option.Opt.MaxDeleteContainerPagingLimit).Where("offline is not null and cluster_id = ? and remove_time is null", config.ClusterID).Cols("id", "hash_id").Find(&tmpContainers)if err != nil {return l.WrapError(err)}if len(tmpContainers) == 0 {l.Warn("delete containers with warnings get containers ids len is 0")break}for k := range tmpContainers {tmpContainerIDs = append(tmpContainerIDs, tmpContainers[k].ID)tmpContainerHashIDs = append(tmpContainerHashIDs, tmpContainers[k].HashID)}if err = DeleteContainerRelatedData(tmpContainerHashIDs); err != nil {return l.WrapError(err)}rows, err := engine.Paging(container.TableContainer, "id", startID, option.Opt.MaxDeleteContainerPagingLimit).Unscoped().Where("offline is not null and cluster_id = ? and remove_time is null", config.ClusterID).In("id", tmpContainerIDs).Delete(&c)rowSum = rowSum + rowsif err != nil {return l.WrapError(err)}if len(tmpContainerIDs) < option.Opt.MaxDeleteContainerPagingLimit {break}startID = tmpContainerIDs[len(tmpContainerIDs)-1]//这里进行内存复用,减少内存的浪费,避免内存释放缓慢的情况tmpContainers = tmpContainers[:0]tmpContainerIDs = tmpContainerIDs[:0]tmpContainerHashIDs = tmpContainerHashIDs[:0]}
func (engine *Engine) Paging(tableName, col string, start, limit int) *Session {sql := fmt.Sprintf("%s > %d", col, start)return engine.Table(tableName).Asc(col).Where(sql).Limit(limit)
}总结
切片使用有很多的雷区,尽量别让自己踩入进去,写代码得时候也要注意性能的优化,避免为后续的开发留下悔恨的种子。和大家分享这么多关于切片的知识,如果哪里有不正确的地方,欢迎大家评论讨论