
kafka入门篇
文章目录
- 前言
- 介绍
- 概念与说明
- 安装
- 启动
- 配置
- 命令操作
- 创建topic
- 查看topic列表
- 发送消息(启动一个生产者)
- 消费消息(启动一个消费者)
- 查询topic信息
- 删除topic
- 集群
- 关机
- 使用
- 报错
- java连接示例
前言
作为入门篇,主要是了解Kafka的概念,还有一些基本操作和使用。
介绍
官方为kafka做了比较完善的介绍:Kafka 中文文档 - ApacheCN
kafka是一个分布式流出来平台。
作为流处理平台它有三种特性:
- 可以让你发布和订阅流式的记录。这一方面与消息队列或者企业消息系统类似。
- 可以储存流式的记录,并且有较好的容错性。
- 可以在流式记录产生时就进行处理。
它可以用于两大类别的应用:
- 构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。 (相当于message queue)
- 构建实时流式应用程序,对这些流数据进行转换或者影响。 (就是流处理,通过kafka stream topic和topic之间内部进行变化)
概念与说明
kafka作为一个集群,可以运行在一台或多台服务器上
kafka通过topic对存储的数据进行分类
每条记录包含一个key,一个value和一个timestamp
kafka的一个结构如下:
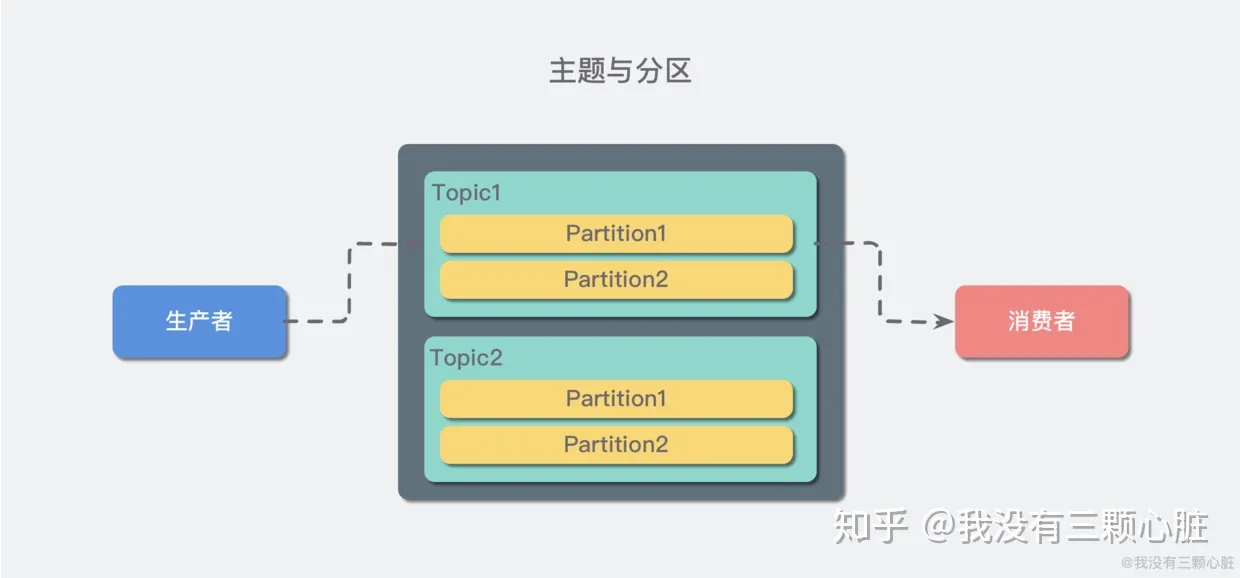
kafka 生产者和消费者均通过TCP协议进行连接。
producer:生产者,也是我们的应用,或是其他要发送的程序,它负责将消息发送到topic的partition中,
consumer:消费者,通过消费者组表示,可以将消费者组看成一个消费者,消费者订阅一个topic,那么Kafka会将消息发送给这个消费者组,此时,这个消费者组会负载均衡的把消息平均分配给组下的所有消费者实例.
topic:主题(数据主题),存储数据记录的地方,可以通过它来区分业务数据,一个topic,可以有一个或多个消费者订阅
partition:分区,每个topic都会有一个或多个分区,分区是将topic接收到的数据按指定的分区和分区规则,拆分到不同分区。消费者订阅topic消费消息时,可以指定分区,或不指定,不指定时Kafka会采用轮询方式将所有分区下的数据发送给消费者;指定分区当然也只会发送指定分区的消息,不同的点也是很明显的,在同一个分区上的消息是有序的。
(官网描述:每一个topic,kafka集群都会维护一个分区日志,每个分区的数据都是有序的,并且不断追加到commit log文件中。分区中的每一条记录,都会分配一个ID号表示顺序,也可以称之为offset(偏移量),也就是说,消费者可以通过这个offset来获取日志,可以从指定的位置获取。
一个分区的存储量受限于主机的文件限制,但是topic可以有多个partition,在集群中,一个topic是在集群节点上的,那么分区也会同步到其他节点的topic下,保持容错性)
replication:副本,每个分区都有一个leader,0个或多个follower,leader只做独写,follower只做备份,当leader宕机,在剩下的follower中就会选举一个leader。
注意:如果创建topic时,副本数时不能大于broker数的,也就是不能大于Kafka节点数,因为副本是同步到其他节点上的,所有如果大于节点数据,就无法创建。
broker:kafka服务
集群:在集群下,总会有一个节点作为leader,零台或者多台作为follwers,只有leader节点处理一切的读写请求,其他节点都是被动的同步leader达到数据,如果这些leader宕机,则会在follwers中选举一个新的leader。
消息系统:相对于其他消息系统的模式来说(有队列和发布-订阅两个模块),kafka在队列模式中,消费者是一个消费者组,像redis,队列模式只能一个消费者,消费了就没了;发布订阅模式,其他中间件也是多订阅模式的,kafka订阅是针对topic,所有消费者组里的消费者实例个数不能多于分区数量。
流处理:kafka拥有流处理的功能,它会不断的从topic获取数据,然后做数据处理,可以做数据聚合,join等复杂处理,然后再写入topic
安装
官方地址:Kafka 中文文档 - ApacheCN
官方提供的下载的地址,下载很快。
启动
方式一
kafka是使用zookeeper做集群管理的,所以你需要个zookeeper服务器,kafka有提供zookeeper,可以直接使用
./bin/zookeeper-server-start.sh -daemon config/zoeeper.properties
它和zookeeper的还是有点不一样的,kafka这个脚本,是启动脚本,zookeeper那个是命令行方式的。
启动kafka
./bin/kafka-server-start.sh -daemon config/server.properties
方式二
不使用kafka自带的zookeeper,使用之前我们搭建的zookeeper集群
vi config/server.properties
/zookeeper
#修改配置为zookeeper集群地址
zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
启动
./bin/zkServer.sh start zoo.cfg
./bin/zkServer.sh start zoo2.cfg
./bin/zkServer.sh start zoo3.cfg
./bin/kafka-server-start.sh config/server.properties
配置
配置项说明:Kafka 中文文档 - ApacheCN
命令操作
kafka它带了很多命令,我们一个通过这些命令进行创建topic、发送消息和消费消息等。
创建topic
./bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic test_topic --partitions 3 --replication-factor 3
–zookeeper:指定zookeeper地址
–partitions:topic分片多少个
–replication-factor:复制因子,控制写入的数据副本个数,这个值是<=broker数量,这里我是单机的,所以这里是1
查看topic列表
./bin/kafka-topics.sh --list --zookeeper localhost:2181
发送消息(启动一个生产者)
#长连接
./bin/kafka-console-producer.sh --broker-list 192.168.17.128:9092 --topic test_topic
客户端收到消息表示成功 了
消费消息(启动一个消费者)
#长连接
./bin/kafka-console-consumer.sh --bootstrap-server 192.168.17.128:9092 --topic test_topic
在生产者客户端发送小,这边能收到就已经成功了
查询topic信息
./bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test_topic

虽然概念上面已经说明过,不过这里还是在提一遍。
**topic:**主题名称,因为指定了3分区,3分布,所有这里是3条数据;
**Partition:**分区,表示当前分区在哪一个节点上。每个topic都会有一个或多个分区,每个分区保存的数据不同(均匀分配了topic上的数据)
**Leader与Replicas:**副本信息,每个分区数据都会备份指定数量的副本,保证容灾能力,每个分区有一个leader,0个或多个follower,leader只做独写,follower只做备份,当一个分区的leader宕机,剩余follower会选举一个leader,如上图Replicas: 1,2,3,

如果leader1掉线,那么剩下的2,3会便会选举其中一个作为leader。
所以这里Leader是分区副本的主节点,负责一切的读写,Replicas是分布所在的信息。
现在kill一个kafka节点:
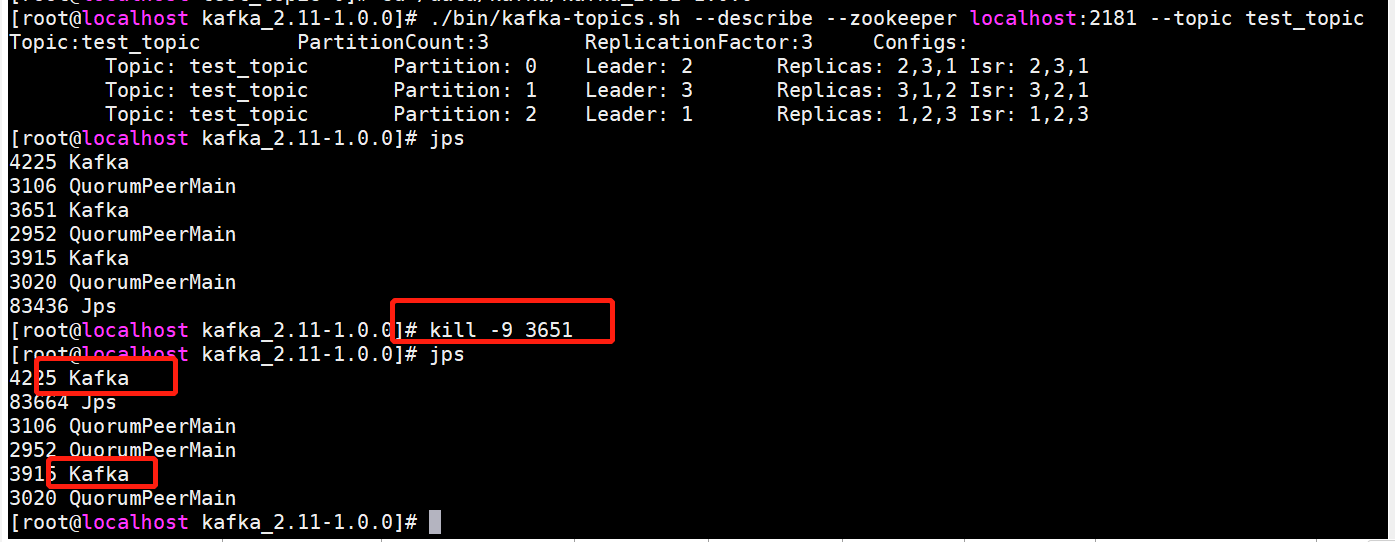
它成功的将1剔除,并且选举出了一个新的leader

注意:
- 之前提过,副本数不能大于Kafka节点数,而这里是本身节点数是够的,只是在运行过程中的不可抗力因素导致的这个集群主动的删除了删除了放弃了异常的节点。
- 这个命令可以查看topic的信息,在Kafka里也作为一个检查集群状态的命令,在Kafka里他没有类似像
zkServer.sh status那样的命令,所有可以通过这个命令,来查看是否有分区掉线。
删除topic
这个需要在server.properties里设置:delete.topic.enable=true,不然这个topic只会被标记为删除,并不会真删
./bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic test_topic

集群
kafka官网提供了配置示例,我们根据它给的添加配置就行,集群的配置,只有3个地方不一样,因为我是在一台服务器上部署,所以要区别其他服务。
- log.dir
- broker.id
- listeners(注意这里的地址配置ip)
zookeeper简单配置示例
# ZooKeeper服务地址
zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
# topic分区日志数
num.partitions=8
# 自动创建topic的默认副本数
default.replication.factor=3
# 自动创建topic
auto.create.topics.enable=false
# 指定写入成功的副本数,当写入数据的副本数达不到这个值,则会报错
min.insync.replicas=2
delete.topic.enable=true# 集群配置
# 日志保存目录
log.dir=./log1
# broker服务ID
broker.id=1
# 监听地址
listeners=PLAINTEXT://192.168.17.128:9092
判断集群状态是否成功:
./bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test_topic
关机
关机和故障时不同的,正常关机,Kafka会执行:
- 同步所有日志到磁盘,可以避免重启时还有执行恢复日志过程,可以提供启动速度;
- 关闭leader时,会将leader上的分区迁移到其他副本,而且切换leader更快;
使用
-
首先确定服务器防火墙端口已经打开
firewall-cmd --add-port=9200/tcp --permanent -
kafka需要logback的依赖
org.apache.kafka kafka-clients 2.8.0 com.fasterxml.jackson.core jackson-databind 2.13.1 org.slf4j slf4j-api 1.7.33 ch.qos.logback logback-core 1.2.10 ch.qos.logback logback-classic 1.2.10 ch.qos.logback logback-access 1.2.3 logback.xml
%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level %logger - %msg%n ERROR ACCEPT DENY ${log_dir}/error/%d{yyyy-MM-dd}/error-log.log ${maxHistory} %d{yyyy-MM-dd HH:mm:ss.SSS} %-5level %logger - %msg%n WARN ACCEPT DENY ${log_dir}/warn/%d{yyyy-MM-dd}/warn-log.log ${maxHistory} %d{yyyy-MM-dd HH:mm:ss.SSS} %-5level %logger - %msg%n INFO ACCEPT DENY ${log_dir}/info/%d{yyyy-MM-dd}/info-log.log ${maxHistory} %d{yyyy-MM-dd HH:mm:ss.SSS} %-5level %logger - %msg%n DEBUG ACCEPT DENY ${log_dir}/debug/%d{yyyy-MM-dd}/debug-log.log ${maxHistory} %d{yyyy-MM-dd HH:mm:ss.SSS} %-5level %logger - %msg%n TRACE ACCEPT DENY ${log_dir}/trace/%d{yyyy-MM-dd}/trace-log.log ${maxHistory} %d{yyyy-MM-dd HH:mm:ss.SSS} %-5level %logger - %msg%n
报错
- 连接出现这样的错误
org.apache.kafka.common.network.Selector - [Consumer clientId=con, groupId=con-group] Connection with /192.168.17.128 disconnected
java.net.ConnectException: Connection refused: no further informationorg.apache.kafka.clients.NetworkClient - [Consumer clientId=con, groupId=con-group] Connection to node -1 (/192.168.17.128:9092) could not be established. Broker may not be available.
最有可能的就是listeners配置没有配置ip导致的,所有可以先尝试改一下,我这里就是因为没有配置IP出现的;最后改成了listeners=PLAINTEXT://192.168.17.128:9092,然后consumer的报错没有了,
- 接下来是生产者的报错:
Error while fetching metadata with correlation id 53 : {test_topic=UNKNOWN_TOPIC_OR_PARTITION}
看着像是未知的topic,我看官网是默认TRUE不是
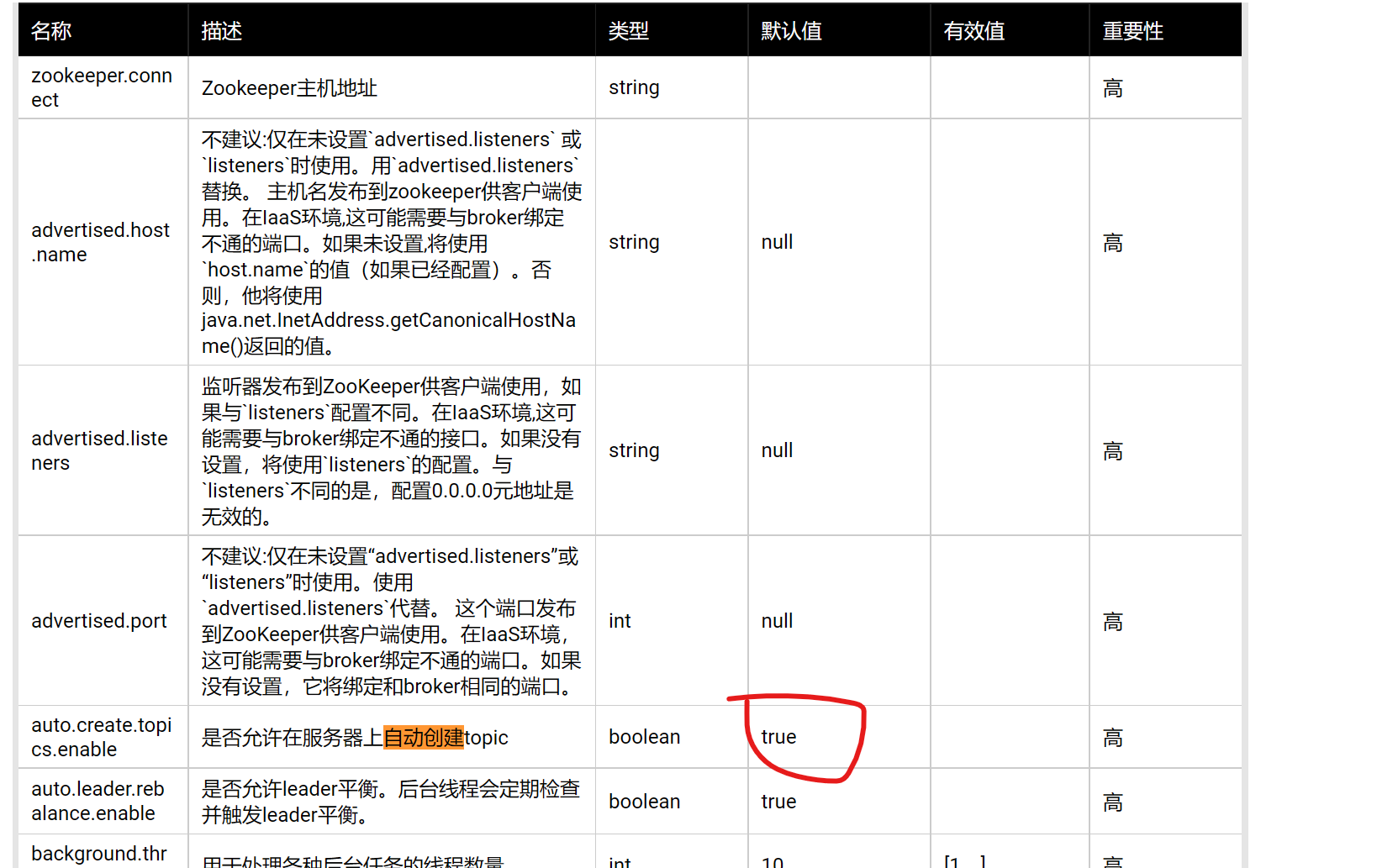
最后配置里又加了一句auto.create.topics.enable=true,完整配置如下:
# ZooKeeper服务地址
zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
# topic分区日志数
num.partitions=2
# 自动创建topic的默认副本数
default.replication.factor=3
# 自动创建topic
auto.create.topics.enable=false
# 指定写入成功的副本数,当写入数据的副本数达不到这个值,则会报错
min.insync.replicas=2
# 设置自动创建topic
auto.create.topics.enable=true
delete.topic.enable=true#集群配置
# 日志保存目录
log.dir=./log1
# broker服务ID
broker.id=1
# 监听地址
listeners=PLAINTEXT://192.168.17.128:9092之后就正常了
弄一个一键启动脚本:
/data/kafka/kafka_2.11-1.0.0/bin/kafka-server-start.sh -daemon /data/kafka/kafka_2.11-1.0.0/config/server.properties/data/kafka/kafka_2.11-1.0.0/bin/kafka-server-start.sh -daemon /data/kafka/kafka_2.11-1.0.0/config/server2.properties/data/kafka/kafka_2.11-1.0.0/bin/kafka-server-start.sh -daemon /data/kafka/kafka_2.11-1.0.0/config/server3.propertiessleep 3echo 'kafka启动完成'java连接示例
消费者代码:
这里有几个必填配置,对应shell命令里的参数
bootstrap.servers - Kafka服务地址
client.id - 客户端id
key.deserializer - key反序列化配置
value.deserializer - value反序列化配置
group.id - 消费者组id
auto.offset.reset - offset方式
public static void consumer() {Properties properties = new Properties();// 必填参数// kafka服务地址properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, IP);// 客户端消费者IDproperties.put(ConsumerConfig.CLIENT_ID_CONFIG, "con");// key序列化器properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// value序列化器properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 消费者组ID,如果需要重新读取,可以切换groupId为新的ID就可以了,然后设置自动提交为trueproperties.put(ConsumerConfig.GROUP_ID_CONFIG, "con-group");// 消费偏移量// earliest:分区中有offset时,从offset位置消费,没有从头消费// latest:分区中有offset时,从offset位置下佛,没有时,消费新产生的// none:分区有offset时,从offset后开始消费,如果有一个分区缺少已提交的offset时,抛异常properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");// 回话超时时间properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 6000);// 心跳间隔properties.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, "2000");// 自动提交间隔properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");// 每次拉取的最大数据量properties.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 2);// 如果需要重复消费,可以设置自动提交为FALSE,这样每次拉取都是从之前的offset开始拉取properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);new Thread(() -> {while (true) {try(KafkaConsumer con = new KafkaConsumer<>(properties);){con.subscribe(Collections.singleton(TOPIC));ConsumerRecords poll = con.poll(Duration.ofSeconds(5000));for (ConsumerRecord record : poll) {System.out.println("topic:" + record.topic() + ",offset:" + record.offset() + ",数据:" + record.value().toString());}}}}).start();}
生产者代码:
同样也是必填参数
bootstrap.servers
client.id
key.deserializer - key序列号配置
value.deserializer - value序列号配置
public static void producer() {Properties properties = new Properties();// 必要条件properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, IP);properties.put(ProducerConfig.CLIENT_ID_CONFIG, "pro");properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());KafkaProducer pro = new KafkaProducer<>(properties);new Thread(() ->{while (true) {try {TimeUnit.SECONDS.sleep(3);} catch (InterruptedException e) {throw new RuntimeException(e);}Future result = pro.send(new ProducerRecord<>(TOPIC, "1","dddd"), (meta, error) -> {if (error != null) {error.printStackTrace();return;}System.out.println("发送回调:" + meta.toString());});System.out.println("发送的结果:" + result );}}).start();}
备注:
-
Kafka会自动将大数据分组给消费者组,同时,在客户端也可以设置
max.poll.records(ConsumerConfig.MAX_POLL_RECORDS_CONFIG)来控制每次拉取的数据量;因为是通过消费者组进行拉取的,所有便可以由多个客户端设置同一个groupId取订阅同一个topic;
-
如果说需要有序的消费数据,那么也要保证生产者的消息都发送到一个分区中,就可以利用Kafka的分区机制进行顺序消费;
-
如果需要全部拉取数据,可以设置groupId,和分批数据量,还有自动提交为true,k
// 消费者组ID,如果需要重新读取,可以切换groupId为新的ID就可以了,然后设置自动提交为trueproperties.put(ConsumerConfig.GROUP_ID_CONFIG, "con-group");// 每次拉取的最大数据量properties.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 2000);// 如果需要重复消费,可以设置自动提交为FALSE,这样每次拉取都是从之前的offset开始拉取properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);// 消费偏移量