
「mysql是怎样运行的」从一条记录说---InnoDB记录存储结构
「mysql是怎样运行的」从一条记录说—InnoDB记录存储结构
文章目录
- 「mysql是怎样运行的」从一条记录说---InnoDB记录存储结构
- 一、InnoDB页介绍
- 二、InnoDB行格式
- 2.1 COMPACT行格式
- 2.2 REDUNDANT行格式
- 2.3 溢出列
- 2.4 DYNAMIC行格式和COMPRESSED行格式
- 三、总结
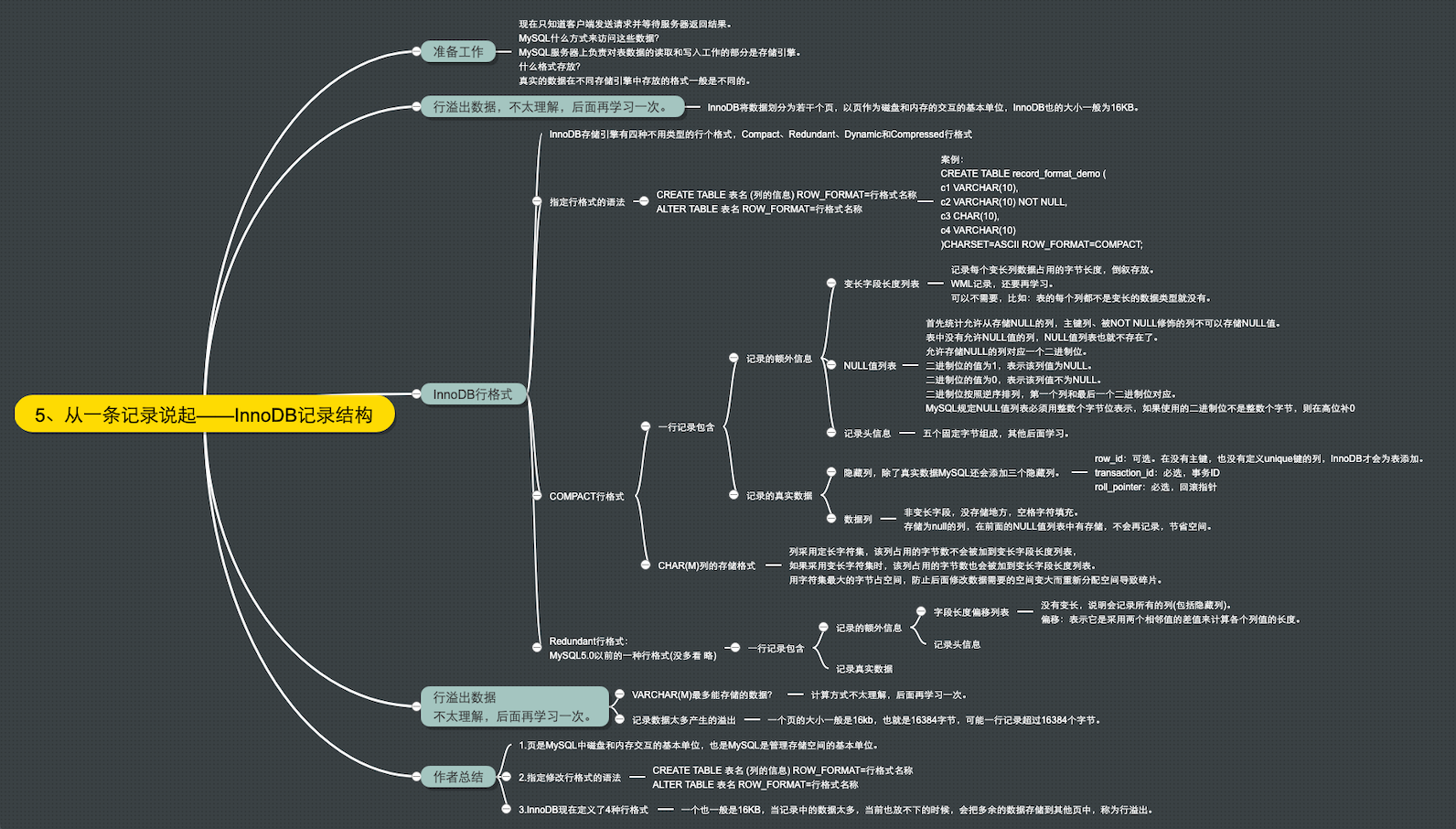
一、InnoDB页介绍
InnoDB是一个把数据存储在硬盘的存储引擎,即使服务器重启,数据依然不会丢失,而真正的数据处理是发生在内存中的,所以InnoDB需要把硬盘上数据加载到内存中,然后在内存中进行各种数据处理,最终在某个时机把内存中的数据刷新到硬盘。而硬盘的处理速度是很慢很慢的,和内存差的太远了,如果InnoDB每次只从硬盘中读取一条数据,显然是不行的,速度会慢死,所以InnoDB会把数据分成若干页,以页作为内存和硬盘之间交互的基本单位,说的再直白点:InnoDB读取数据不是一行一行读,而是以页为最小单位读取数据。默认情况下,一页是16K,也就是InnoDB读取数据的数据大小至少是16K。当然这个值是可以被修改的,因为一般情况下,也没人会修改这个值,所以这里我就不说明应该怎么改了。
二、InnoDB行格式
我们平时是以记录为单位向表中插入数据的,记录在磁盘上的存放形式也被称为行格式或记录格式。
InnoDB 提供了4种行格式供我们选择,分别是Compact、Redundant、Dynamic和Compressed行格式,以后可能会有新的行格式出现,但是区别并不是很大。
我们建表的时候,可以指定某种行格式:
CREATE TABLE table_name (列信息) ROW_FORMAT=行格式名称
也可以修改已经存在的表的行格式:
ALTER TABLE table_name ROW_FORMAT=行格式名称
准备工作
为了后面的故事可以顺利展开,我们先来建一张表:
CREATE TABLE hero( `x` VARCHAR(10), `y` VARCHAR(10) NOT NULL, `z` CHAR(10), `t` VARCHAR(10) )CHARSET=ASCII, ROW_FORMAT=COMPACT;
我建了一张表,指定的行格式是COMPACT,采用的字符集是ASCII,也就是我们的中文是无法存进去的,现在我要向这张表添加两行数据:
INSERT INTO hero(x, y, z, t) VALUES('a', 'bb', 'cccc', 'ddddd'), ('a', 'b', NULL, NULL);
现在表中的数据是这样的:
表建好了,数据填充好了,下面我们就来分析下在COMPACT行格式下,数据是如何存储的吧。
2.1 COMPACT行格式

其中COMPACT的行格式由记录的额外信息和记录的真实数据两部分组成组成。
1、记录的额外信息
- 变长字段列表:在MySQL中一般有一些变长的类型,如VARCHAR(M),text,blob等,InnoDB会将非NULL的变长字段的字节长度按照列的顺序的逆序存储到变长字段列表中,而行中存储真实数据。对于变长字段是用两个字节来存储变长长度还是用1个字节存储遵循以下规则:如果该列能够存储的最大字节数(M(存储的最大字符数)*W(字符集中每个字符所占用的最大字节数))小于等于256时直接采用1个字节存储,如果大于256时,假设实际存储的长度L小于等于127时,便采用1个字节,否者用2个字节,因为此时如果是需要用1位来作为标志位标志是读取1个字节还是2个字节。除此之外,当某个字段的数据特别多的时候,可能采用溢出页来存储剩下的数据。由于每页最多为16KB即16384字节,所以两个字节一定能表示出该字段的长度。
- NULL值列表:将可以将为NULL值的列按列的顺序的逆序存储到NULL值列表中,其中如果该位为NUll值,便将该位对应的值设置为1,并且高位补0。
- 记录头信息:由5个字节固定表示,来描述记录的一些属性。如该记录是否被删除,是否是目录项等。
2、记录的真实数据
-
对于记录的真实数据中除了显示出来的列之外,还有row_id,trx_id,roll_pointer三列隐藏列。
列名 作用 row_id 行ID唯一标识1行 trx_id 事务ID roll_pointer 回滚指针 注意:InnoDB中一定有主键,如果未人为设置了主键,便选取非空的唯一键作为主键,此时都不会添加row_id否者用row_id充当主键。
3、CHAR(M)列的存储格式
当CHAR(M)的字段采用变长编码时,也会将其在变长字段长度列表中记录该字段所占的字节数,但是如果采用定长编码时便不会。同时,如果CHAR(M)如果采用变长编码的形式,其中要求该字段至少占用M个字节。
2.2 REDUNDANT行格式
其中REDUNDANT没有COMPACT紧凑,在一般在MySQL5.0之前常使用。

- 字段长度偏移列表:该行格式会将该记录中所有的列,包括隐藏列的偏移量按逆序存储到字段长度偏移量列表中。一般该字段的长度为相邻两个偏移量之差。
- 记录头信息:会有一个1byte_offs_flag来标记该偏移量存储是1个字节还是2个字节。
- 1byte_offs_flag的选取:如果记录总长度小于等于127遍直接用1个字节存储,否者用2个字节存储。其中为什么是127,因为会在偏移量中选取最高位作为NULL值的标记位。
- NULL值处理:偏移量中选取最高位作为NULL值来标记该字段是否为NULL,并且如果字段是定长类型,比如char(M),则直接将其设置为M*一个字符需要的最大字节数(如utf8为3)个字节,并且将存储实际数据的地方初始化为0,这样可以直接在原位置更新;对于变长类型,便不会在真实数据处记录数据。
2.3 溢出列
当某列的数据超过临界点时,称之为溢出列,此时COMPAT记录格式会记录该列的前768个字节,然后用20字节用来指向存储剩余数据的地址,其中剩余数据是以链表的形式存储在其他页中。
2.4 DYNAMIC行格式和COMPRESSED行格式
其中DYNACMIC格式和COMPACT格式类似,但是在处理溢出列的时候,他不会存储前768个字节,而是只存储20个字节的指针。COMPRESSED则会采用压缩算法来使得存储空间更小。
三、总结
参考
第五节:从一条记录说起——InnoDB记录结构
第4章 从一条记录说起—InnoDB记录存储结构
上一篇:【C++】1.C++基础