
行缓冲、全缓冲、无缓冲以及用户缓冲区、内核缓冲区介绍
文章目录
- 1- 缓冲区介绍
- (1)缓冲区以及作用
- (2)缓冲区的类型
- 【1】行缓冲(验证)
- 【2】全缓冲(验证)
- 【3】无缓冲
- 2- 内核缓冲区与用户缓冲区
- (1)用户进程和操作系统的关系
- (2)用户缓冲区和内核缓冲区
最近在这两个知识点遇到了困难,之前不怎么懂,查了资料仿佛懂了,于是写个文档防止后面自己忘记了,顺便加深自己对知识点的印象。
1- 缓冲区介绍
(1)缓冲区以及作用
可以理解为:内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区。后面讲到的内核缓冲区以及用户缓冲区能够更好理解缓冲区的作用。
作用:
- 缓冲区其实可以算是保护我们的硬件的,所有的磁盘都是有寿命限制的(读写的次数不是无限的),到了一定的程度就坏了。所以就将我们要读写的内容都放在缓冲区中,统一进行读写,减少次数。
- 缓冲区就是一块内存区,它用在输入输出设备和CPU之间,用来缓存数据。它使得低速的输入输出设备和高速的CPU能够协调工作,避免低速的输入输出设备占用CPU,解放出CPU,使其能够高效率工作。
(2)缓冲区的类型
【1】行缓冲(验证)
行缓冲:在这种情况下,当在输入和输出中遇到换行符(\n)时,执行真正的I/O操作。
我们来验证一下行缓冲。看看代码然后自己想想这样会使怎么样子的输出结果。
#include
#include
#include int main(int argc, char *argv[])
{printf("Hello world");sleep(3);printf("\n");return 0;
}
结果:你会发现程序会先沉睡三秒然后再打印“Hello world”,在沉睡的三秒钟可以随意按键。本来的程序应该是运行‘Hello world’的,但是因为存在缓冲区,Hello world在缓冲区中,并且是行缓冲的,遇见‘\n’才能输出,于是就一直保存在缓冲区中,直到沉睡3秒遇见‘\n’就输出了。
wangdengtao@wangdengtao-virtual-machine:~$ ./a.out Hello world
【2】全缓冲(验证)
全缓冲:在这种情况下,当填满标准I/O缓存后才进行实际I/O操作。全缓冲的典型代表是对磁盘文件的读写。一般缓冲区的大小是4K,也就是2*2的10次方(2^12),4096个字节。所以到达4096个字节后就会自动进行I/O操作了。
看下面的代码验证,需要首先了解在对文件的操作时,I/O都是全缓冲的。所以需要到达缓冲区的大小才能都输出,所以下面的一串代码在文件中是没有数据的(看注释就懂了代码)。
#include
#include
#include
#include
#include
#include
#include
#include int main(int argc, char *argv[])
{int fd;close(1);/*0 ,1 ,2分别对应标准输入,标准输出,标准出错,关闭标准输出,printf就不会打印到屏幕但是我们打开了一个文件,系统会把最小的存在的没用的这个文件描述符1给反对,所以我们的标准输出就到文件中去了意思就是printf不会打印在屏幕上,会在文件里面*//*O_WRONLY:只读的意思,O_CREAT:没有就创建*/fd = open("Hello", O_WRONLY | O_CREAT, 0666 );printf("Hello World!\n");//fflush(stdout);close(fd);//关闭打开的文件return 0;
}
结果(文本中无数据):
wangdengtao@wangdengtao-virtual-machine:~$ gcc example.c
wangdengtao@wangdengtao-virtual-machine:~$ ./a.out
wangdengtao@wangdengtao-virtual-machine:~$ cat Hello
wangdengtao@wangdengtao-virtual-machine:~$
但是我们将上面代码中注释掉的fflush(stdout)添加上的话,就会看见我们的Hello文件中有这个数据啦!
原因:fflush的作用,就是刷新缓冲区,将缓冲区内的数据输出到设备,这里的设备也就是我们的文件。所以对文件的操作的时候都是全缓冲的,但是我们可以巧妙的运用我们的方法将数据显示出来。当然更方便的当然是write或者read啦,因为这两个都是没有缓冲的,直接写或者读。
wangdengtao@wangdengtao-virtual-machine:~$ gcc example.c
wangdengtao@wangdengtao-virtual-machine:~$ ./a.out
wangdengtao@wangdengtao-virtual-machine:~$ cat Hello
Hello World!
wangdengtao@wangdengtao-virtual-machine:~$
【3】无缓冲
无缓冲:在这种情况下,就是直接进行I/O操作,直接显示出来。标准出错情况stderr是典型代表,这使得出错信息可以直接尽快地显示出来。
我们将全缓冲的代码拿下来,然后将printf改成write,也不需要fflush了,再来看看我们写进去了吗。
#include
#include
#include
#include
#include
#include
#include
#include int main(int argc, char *argv[])
{int fd;close(1);/*0 ,1 ,2分别对应标准输入,标准输出,标准出错,关闭标准输出,printf就不会打印到屏幕但是我们打开了一个文件,系统会把最小的存在的没用的这个文件描述符1给反对,所以我们的标准输出就到文件中去了意思就是printf不会打印在屏幕上,会在文件里面*//*O_WRONLY:只读的意思,O_CREAT:没有就创建*/fd = open("Hello", O_WRONLY | O_CREAT, 0666 );write(fd, "Hello World!", 12);close(fd);//关闭打开的文件return 0;
}
结果(文件中有数据):
wangdengtao@wangdengtao-virtual-machine:~$ gcc example.c
wangdengtao@wangdengtao-virtual-machine:~$ ./a.out
wangdengtao@wangdengtao-virtual-machine:~$ cat Hello
Hello World!wangdengtao@wangdengtao-virtual-machine:~$
这里我们就明白了,write是无缓冲的,直接写进去,也不需要fflush来刷新缓冲区,不受限制的。
2- 内核缓冲区与用户缓冲区
主要参考这篇文文章:一文搞懂用户缓冲区与内核缓冲区
(1)用户进程和操作系统的关系
首先我们来看一下用户进程和操作系统的关系,首先我用一张图来解释“用户进程和操作系统的关系:
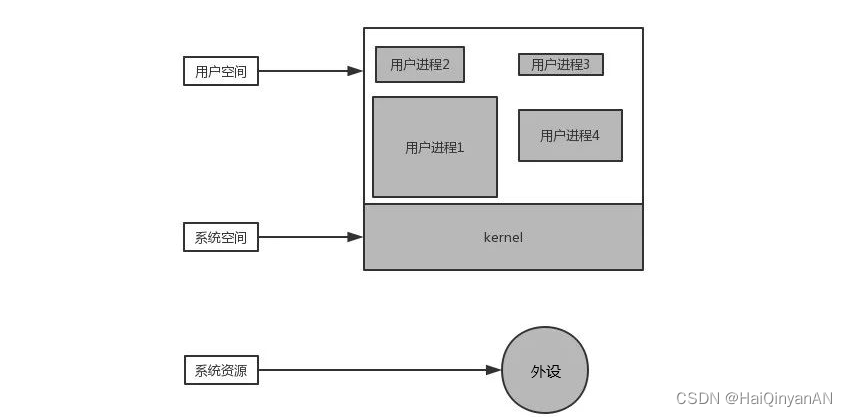
这是一个计算机系统运行时的简化模型,我们把所有运行在操作系统上的进程成为用户进程,它们都运行在用户空间(可以看到用户空间有很多进程)。把操作系统运行的空间成为系统空间。
为什么将进程分为用户进程和系统进程,首先你一定听说过内核态和用户态(kernel mode和user mode),在内核态可以访问系统资源(其中包括处理器cpu、输入输出I/O、进程管理、内存、外设、计时器、进程间通信IPC、网络通信等)。
上面所说的这些系统资源,在用户进程中是无法被直接访问的,只能通过操作系统来访问,所以也把操作系统提供的这些功能成为:“系统调用”。
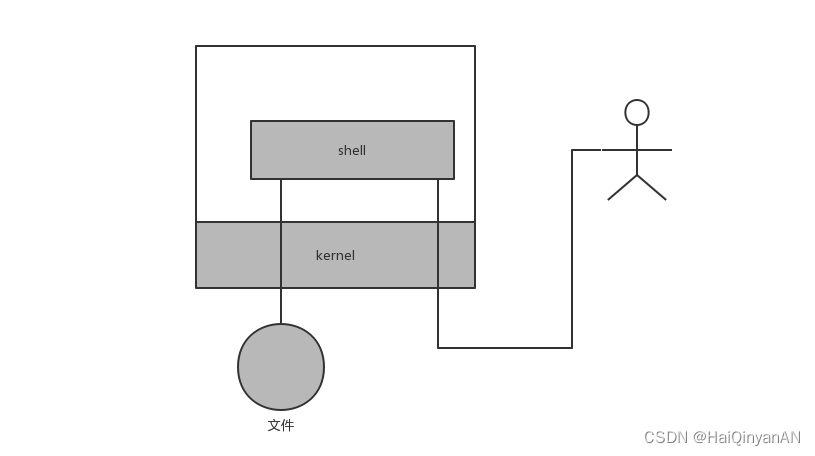
比如下图,展示一个用户通过shell控制计算机所经过的数据流向:文件读写和终端控制,都是通过内核进行的。
(知识点:fflush把进程缓冲区的数据刷新到内核缓冲区,fsync把内核缓冲区的数据刷新到物理媒介上。)
(2)用户缓冲区和内核缓冲区
参考的这篇文章:虎牙一面:请详细介绍一下内核缓冲区

- 用户缓冲区:
普通应用程序可访问的内存区域,就是用户空间。
用户进程通过系统调用访问系统资源的时候,需要切换到内核态,而这对应一些特殊的堆栈和内存环境,必须在系统调用前建立好。而在系统调用结束后,cpu会从核心模式切回到用户模式,而堆栈又必须恢复成用户进程的上下文。而这种切换就会有大量的耗时。
一些程序在读取文件时,会先申请一块内存数组,称为buffer,然后每次调用read,读取设定字节长度的数据,写入buffer。(用较小的次数填满buffer)。之后的程序都是从buffer中获取数据,当buffer使用完后,在进行下一次调用,填充buffer。
所以说:用户缓冲区的目的是为了减少系统调用次数,从而降低操作系统在用户态与核心态切换所耗费的时间。除了在进程中设计缓冲区,内核也有自己的缓冲区。
- 内核缓冲区:
用户操作系统内核能够访问的内存区域,就称为内核空间,它独立于普通的应用程序,是受保护的内存空间。
当一个用户进程要从磁盘读取数据时,内核一般不直接读磁盘,而是将内核缓冲区中的数据复制到进程缓冲区中。访问磁盘的速度要远远低于访问内存的速度,完全不是一个量级的,所以理论上 read 磁盘的速度要远远慢于 read 内存。(注:read是把数据从内核缓冲区复制到进程缓冲区。write是把进程缓冲区复制到内核缓冲区。当然,write并不一定导致内核的写动作,比如os可能会把内核缓冲区的数据积累到一定量后,再一次写入。)
内核缓冲区(Kernel Buffer Cache)就解决了这个问题,本质上其实就是内核空间的一块内存区域。
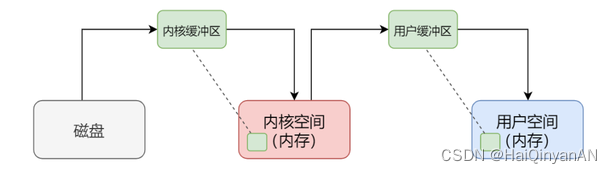
- 总结:
用户缓冲区处理的是用户空间和内核空间的数据传递,目的是减少系统调用的次数;而内核缓冲区处理的是内核空间和磁盘之间的数据传递,目的是减少访问磁盘的次数。