SCL_PFENET跑通填坑
1.数据准备:VOC2012数据集,initmodel文件夹(预训练模型),SegmentationClassAug数据
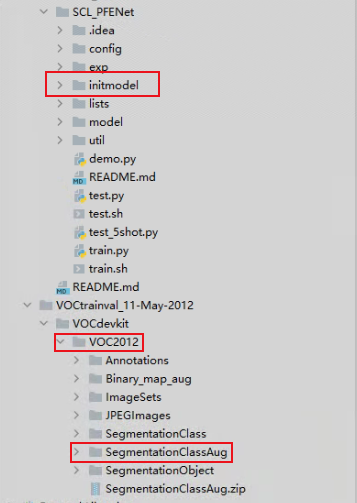
2.训练部分:训练部分没什么需要改动的,也就改一下选择的配置文件。在config文件夹里有关于coco和voc数据的配置参数,可以根据自己的实际情况来修改。
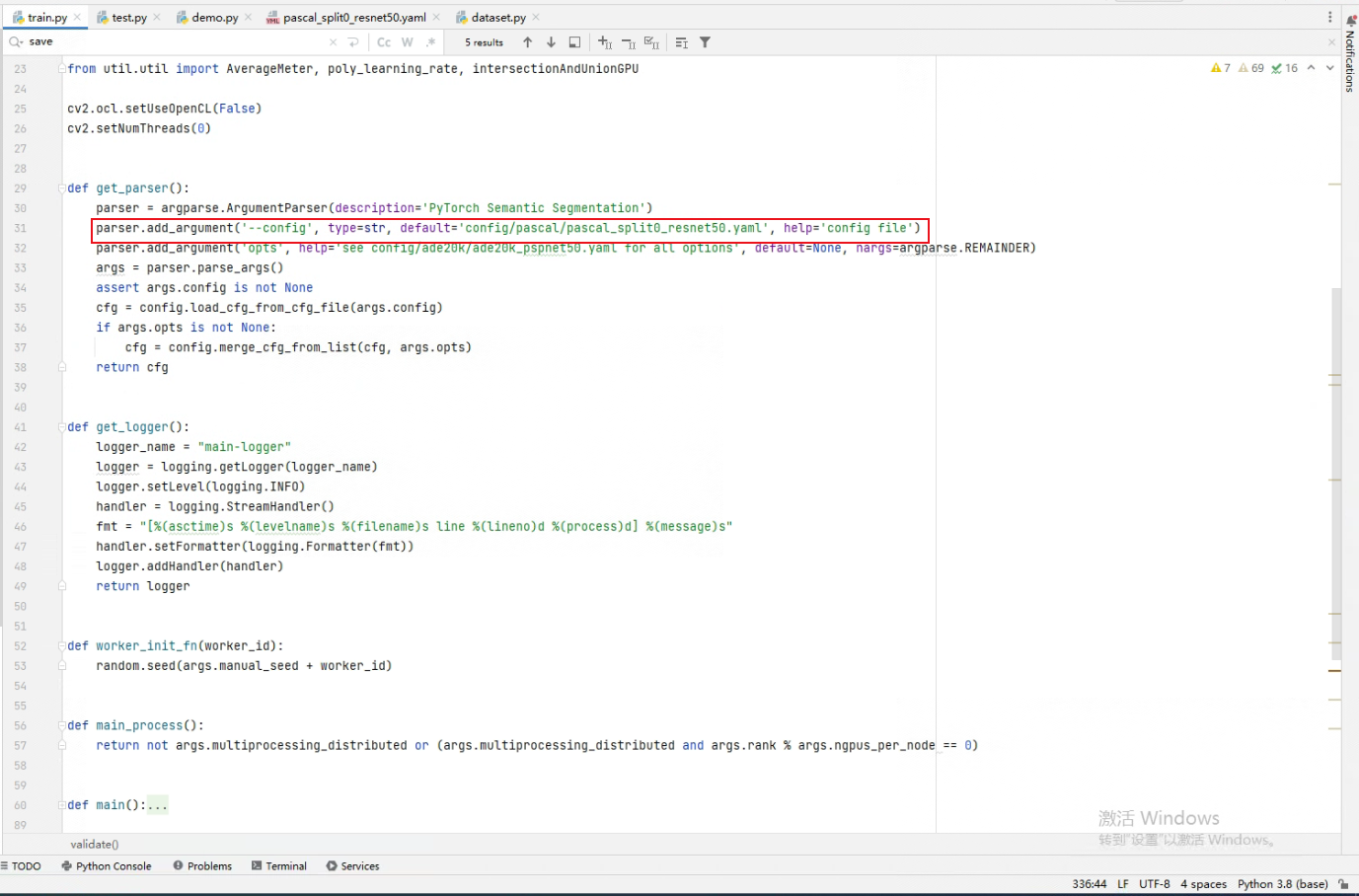
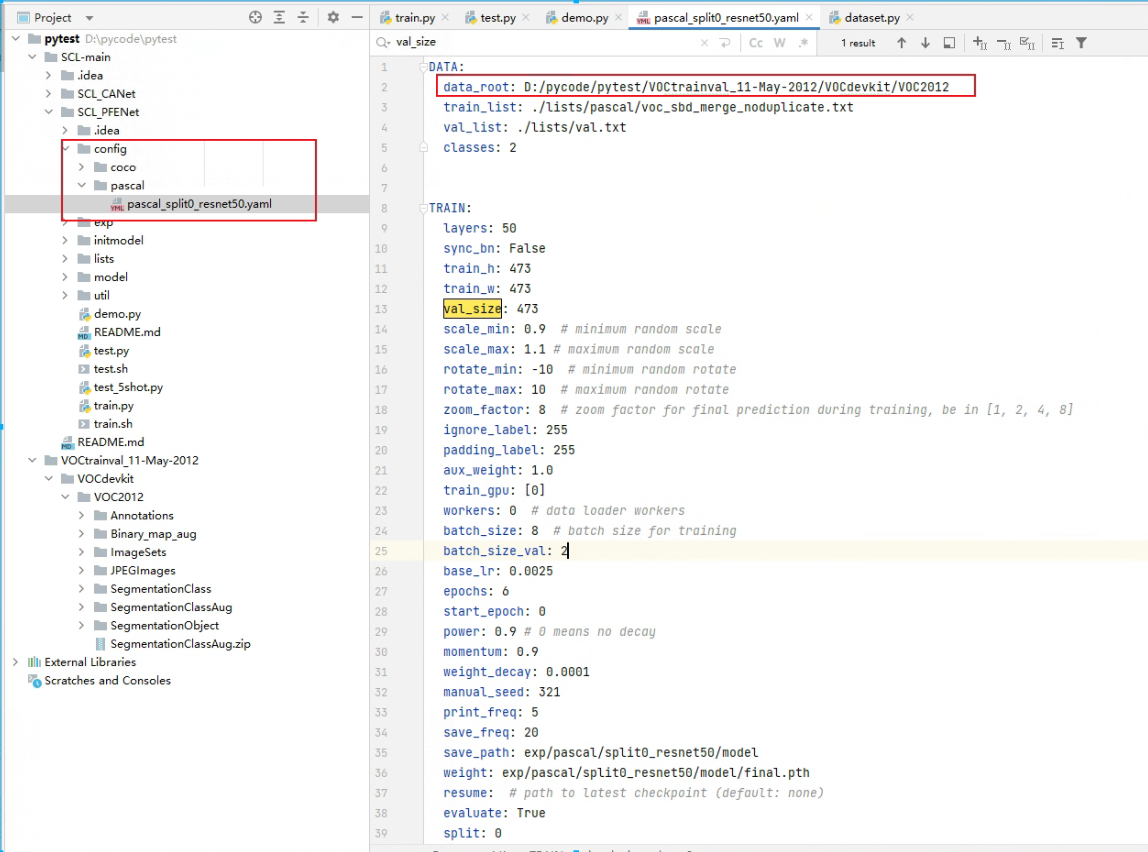
训练前要把数据集的路径修改成自己数据集所在的位置,路径最好不要有中文路径,否则的话训练的时候会发现loss一直是0.这是因为在读数据集的时候代码使用的是cv2.imread,使用这种方法来读图,路径错误或者有中文的时候不会 报错,但独到的图片是None
如果路径有中文可以修改下面的代码,将utils文件夹里面的dataset.py里面的cv2.imread改成cv2.imdecode(注释的代码)
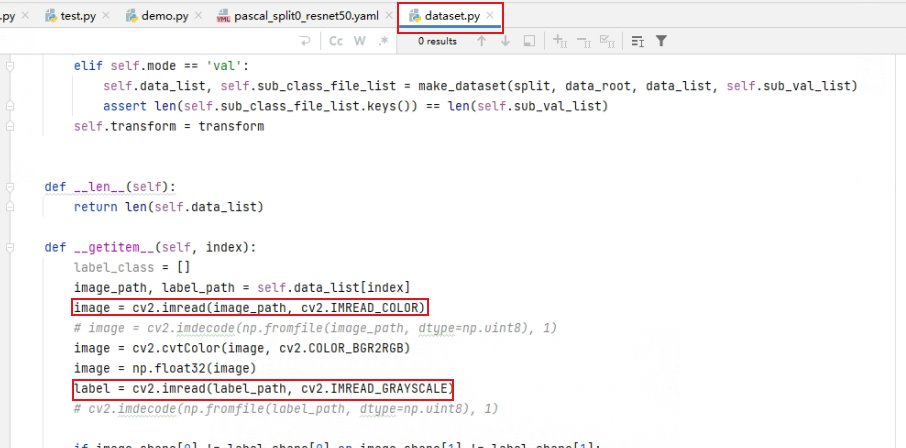
到这里训练部分就结束了,正常训练就可以了
3.测试部分:
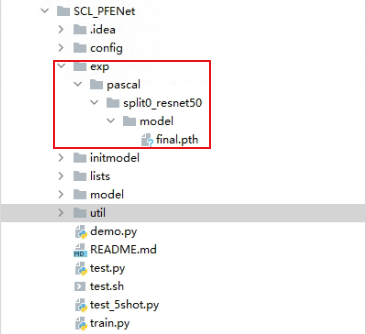
训练完之后会生成一个final.pth的模型文件,在如下位置:
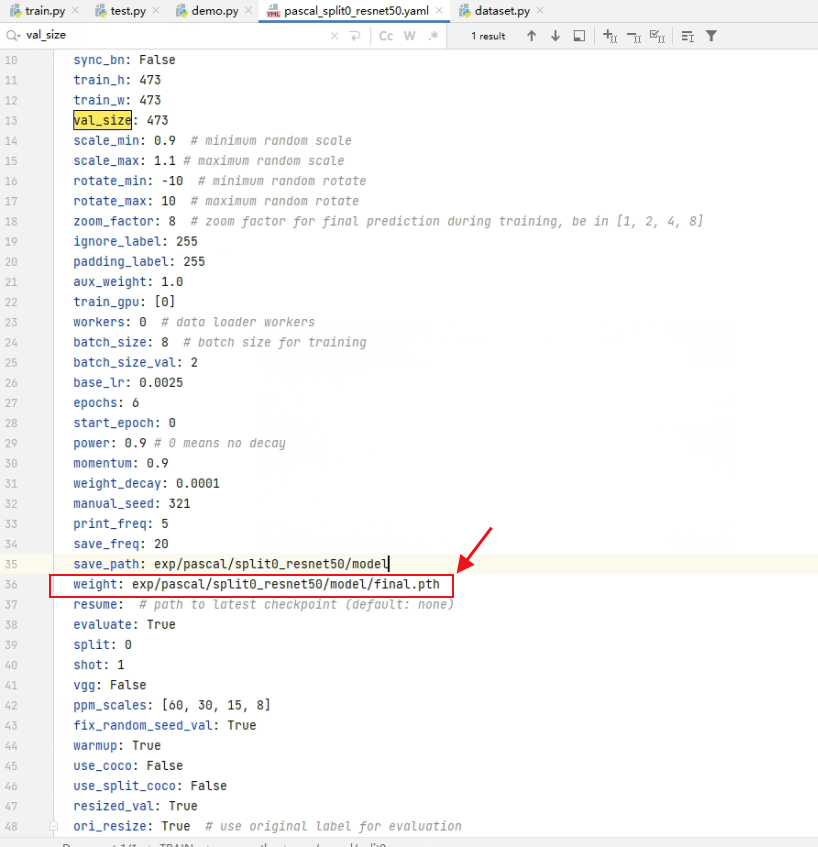
测试之前要修改一下配置文件,将weight对应的路径改成模型所在的路径
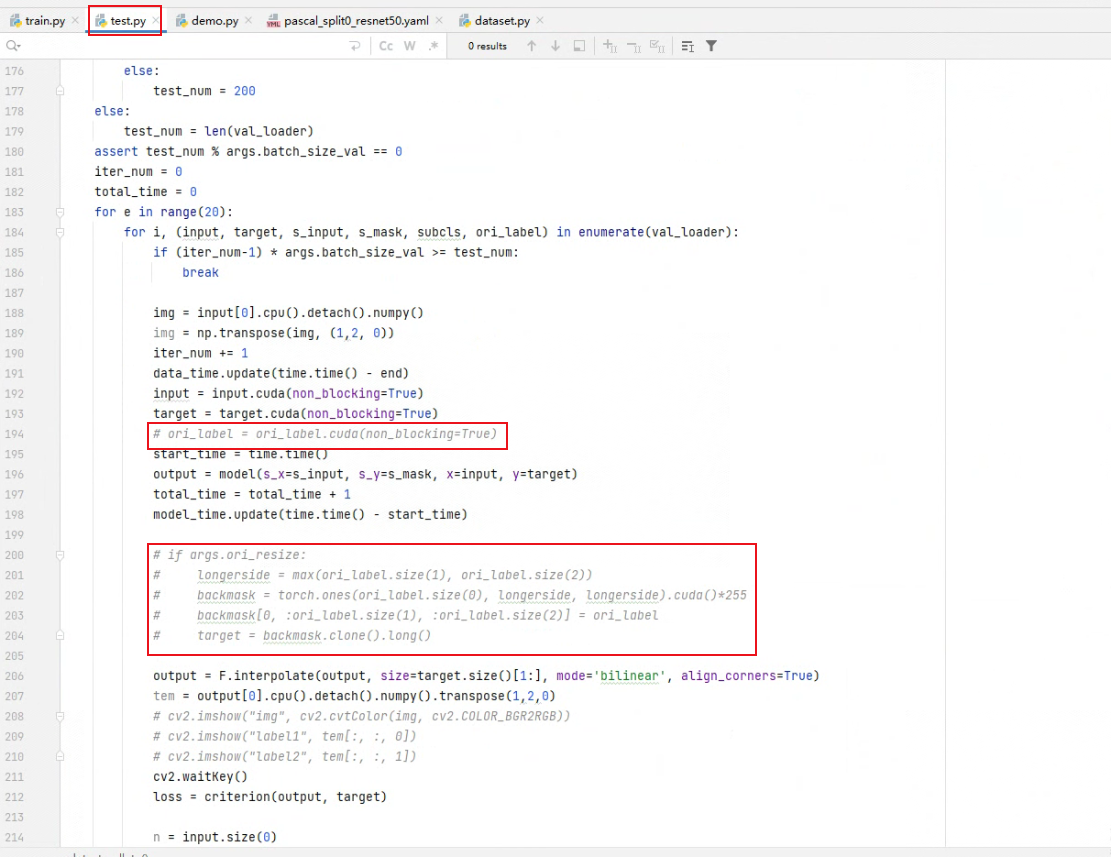
然后运行test.py文件,当batch_size_val为1时,代码不会报错。当batch_size_val>1时,运行代码就会报错:RuntimeError: stack expects each tensor to be equal size, but got [366, 500] at entry 0 and [333, 500] at entry 1
这个报错原因就是在测试的时候mode="val",而当mode="val"的时候,dataset.py里面返回的数据有6个,多了一个raw_label。这个raw_label就是原始的mask图,由于原图大小是不一致的,所以在使用Dataload的时候,Dataload内部在返回前会对一个batch的数据进行stack操作,而由于大小不一致,故报错。
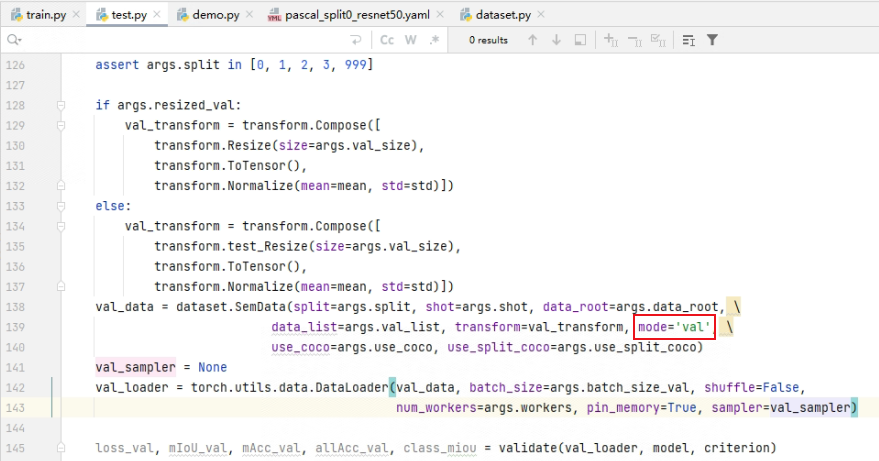
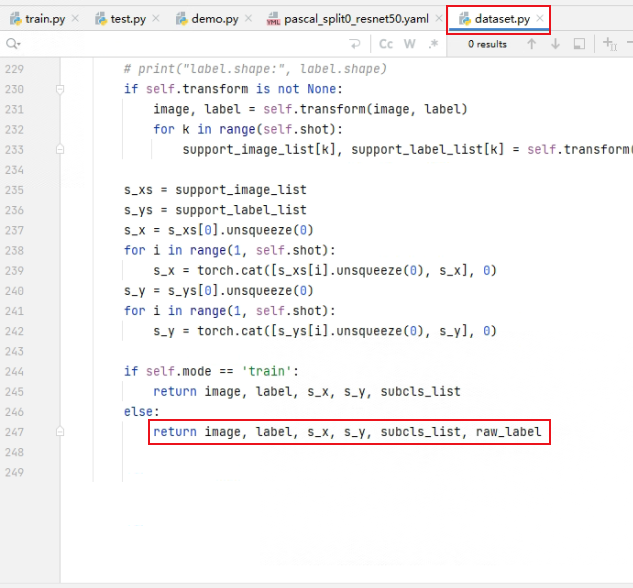
解决方法:
在使用DataLoader的时候,后面加上collate_fn=detect_collate.
detect_collate是自己编写的一个函数,前面已经说了,当mode="val"的时候dataset返回6个数据:所以自己写的函数也是返回6个。通过看代码可以看到返回结果的时候只有ori_label没有进行stack操作,这就是前面说的大小不一致不能 进行stack操作。(主要是在test.py里面这个ori_label并没有太大的用处,所以就不对它进行其他操作了,如果需要ori_label的话也可以在函数里面对它进行处理然后再进行stack操作,然后再返回结果)。这时候返回的ori_label是一个列表。
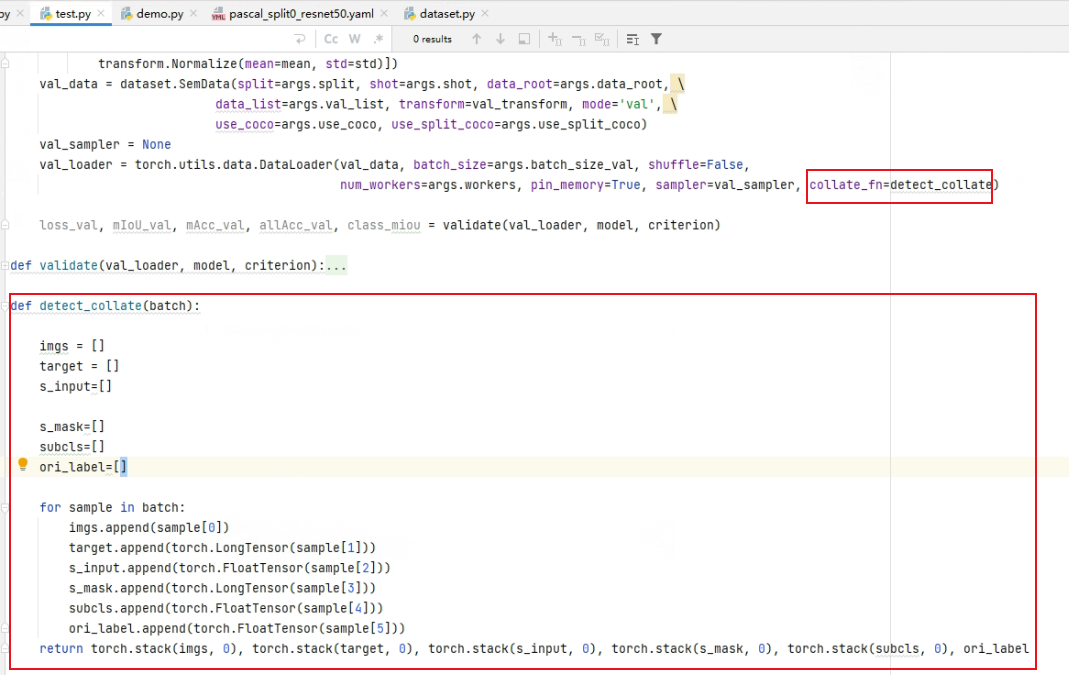
由于返回的ori_label是一个列表,所以还需要对test.py进行一些小修改才能正常运行,注释掉如下代码就ok了: