
@Component实现原理
直接从关键代码开始:
直接找到org.springframework.context.support.AbstractApplicationContext#refresh方法,找到invokeBeanFactoryPostProcessors(beanFactory)方法,最终找org.springframework.context.support.PostProcessorRegistrationDelegate#invokeBeanFactoryPostProcessors方法,此方法中,存在三次获取并调用实现了 BeanDefinitionRegistryPostProcessor接口类调用其postProcessBeanDefinitionRegistry方法,最终调用的就是ConfigurationClassPostProcessor类的postProcessBeanDefinitionRegistry方法(第一次)
parser.parse(candidates);最终找到此处方法,其中参数其实就是启动类的BeanDefinitionHolder对象,在parse方法中,找到如下代码:
if (basePackages.isEmpty()) {basePackages.add(ClassUtils.getPackageName(declaringClass));}其中declaringClass是启动类的全路径,即在这里读取了启动类的全路径,然后获取其package的值,最后调用org.springframework.context.annotation.ClassPathBeanDefinitionScanner#doScan方法:
protected Set doScan(String... basePackages) {Assert.notEmpty(basePackages, "At least one base package must be specified");Set beanDefinitions = new LinkedHashSet<>();for (String basePackage : basePackages) {Set candidates = findCandidateComponents(basePackage);for (BeanDefinition candidate : candidates) {ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);candidate.setScope(scopeMetadata.getScopeName());String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);if (candidate instanceof AbstractBeanDefinition) {postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);}if (candidate instanceof AnnotatedBeanDefinition) {AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);}if (checkCandidate(beanName, candidate)) {BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);definitionHolder =AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);beanDefinitions.add(definitionHolder);registerBeanDefinition(definitionHolder, this.registry);}}}return beanDefinitions;} 此处的方法:
Set candidates = findCandidateComponents(basePackage); 读取当前启动类路径下的所有类信息,实现方法为org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#scanCandidateComponents,其主要代码如下:
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +resolveBasePackage(basePackage) + '/' + this.resourcePattern;Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);此处的值为:
classpath*:com/example/hanblspringboot/**/*.class可知,其扫描了启动类package下的所有.class文件,其后面的代码如下:
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);if (isCandidateComponent(metadataReader)) {ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);sbd.setSource(resource);if (isCandidateComponent(sbd)) {if (debugEnabled) {logger.debug("Identified candidate component class: " + resource);}candidates.add(sbd);}else {if (debugEnabled) {logger.debug("Ignored because not a concrete top-level class: " + resource);}}}根据source和类加载器创建SimpleMetadataReader对象,即MetadataReader(元数据读取器)
@Overridepublic MetadataReader getMetadataReader(Resource resource) throws IOException {return new SimpleMetadataReader(resource, this.resourceLoader.getClassLoader());}此处有一个判断很重要,即
isCandidateComponent(metadataReader) protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {for (TypeFilter tf : this.excludeFilters) {if (tf.match(metadataReader, getMetadataReaderFactory())) {return false;}}for (TypeFilter tf : this.includeFilters) {if (tf.match(metadataReader, getMetadataReaderFactory())) {return isConditionMatch(metadataReader);}}return false;}可以看到有排除过滤器和包括过滤器,
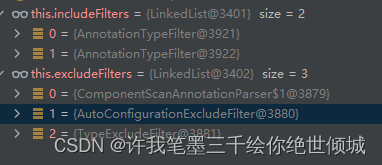
通过类型可以知道,排除过滤器excludeFilters,
1)ComponentScanAnnotationParser类中new的拦截器,排除自身;
scanner.addExcludeFilter(new AbstractTypeHierarchyTraversingFilter(false, false) {@Overrideprotected boolean matchClassName(String className) {return declaringClass.equals(className);}});直接在
2)AutoConfigurationExcludeFilter过滤器,用于排除@Configuration注解中TypeFilter设置的排除类
3)TypeExcludeFilters过滤器,它们主要在内部用于支持 spring-boot-test
注(重点):
这里当然这里也可以使用ComponentScan注解中的excludeFilters来配置过滤器;这里就可以用来实现TypeFilter然后自定义过滤条件;即指定扫描的过滤规则;是一个扩展点。
包括过滤器:
1)包括@Component注解的类,此处就是其自动注入的实现
this.includeFilters.add(new AnnotationTypeFilter(Component.class));2)ManagedBean的注解,可能它不存在,所以使用反射获取;
this.includeFilters.add(new AnnotationTypeFilter(((Class) ClassUtils.forName("javax.annotation.ManagedBean", cl)), false));这里还可能存在Named注解,他跟ManagedBean一样;
经过以上流程,此时会获取到classpath下符合要求的所有.class文件了;最后根具MetadataReader创建ScannedGenericBeanDefinition对象并设置source为对应的类路径。至此,自动注入已经将class文件转换成了对应的definition对象。