
C++面经:C/C++语法,C++的三大特性
创始人
2024-06-02 07:44:14
文章目录
- 1. 类和对象,C++的三大特性
- 2. 指针,智能指针
- 3. 函数
- 4. 内存管理
- 5. 关键字
- 6. C++11新特性
前言: 本文主要讲解,C++的一些常考的面试题,对C/C++的一些细节考察。
1. 类和对象,C++的三大特性
- 虚函数和析构函数,析构函数是否一定要将其定义为析构函数?
- 如果类中至少有一个虚函数,那么它的析构函数必须是虚函数。
- 一个类它的析构函数不是virtual的,那就表明它不希望被继承。
- 原因:假设基类的析构函数不是virtual的,用基类指针
ptr指向派生类的对象,此时deleteptr,就仅仅析构基类的资源,不会析构派生类的所剩资源。这就导致了内存泄漏。如果将基类的析构函数修饰为virtual,那么就不会出现以上问题,因为deleteptr,会调用ptr指向对象的析构函数,因为析构函数构成多态,现在调用是派生类的析构函数(不构成多态调用的是基类的析构函数),派生类的析构函数的动作是:先析构派生类的资源,再调用基类的析构函数,析构基类的资源。- 综上:要为多态基类声明virtual析构函数,如果基类不是为了多态用途,也就不要virtual析构函数,比如:标准程序库中STL的迭代器实现。
- 虚函数和普通的函数相比性能消耗会更大一些,这是为什么?
- 空间消耗:类只有是有虚函数,那必定会有一个虚表指针,这个指针可以理解为函数数组指针,它指向了虚函数表。在32位下是4字节,64位下是8字节。
- 时间消耗:在调用虚函数时,汇编call的不是虚函数的地址,而是一个间接地址,再由间接地址跳转到虚函数地址处,也就是说编译时,并不清楚要调用哪个函数,而是运行时确定的虚函数地址,这就有时间消耗。并且那分支预测的成功率也会降低很多,分支预测错误也会导致程序性能下降。
- 讲一下虚函数
虚函数,是指被virtual关键字修饰的成员函数。多态的实现依赖虚函数。
- 虚函数的实现:虚函数指针,虚函数表。
每个虚函数都有对应的虚函数指针,每个有虚函数的类都有虚函数表,并且虚函数表在类的开头处,注意虚函数表是不可见的,除非是直接访问地址的方式,才能够看到虚函数表,当然调试中的监视窗口可以看见。- 派生类的虚函数表:首先开头处是基类的虚函数表,如果派生类对基类的virtual函数进行重写,那么在派生类的虚函数表处会进行替换,就是把原来基类的virtual函数指针,替换成派生类重写后的虚函数指针。
- 多继承的派生类:在派生类的虚函数表中,会根据继承的顺序,来排列派生类虚函数表中基类虚函数表的顺序。
- 最后想说的就是:派生类自己的虚函数在其虚函数表中的位置,如果是单继承,那就放在基类虚函数表下面。多继承的话,那就放在第一个基类虚函数表的后面。
- 理解到这里已经比较深入,如果还要说的话,那你可以讲讲扯扯多态的原理。
- 虚函数和纯虚函数的区别
- 形式上区别:虚函数在成员函数前加上virtual,纯虚函数是在成员函数前加上virtual并且在声明的末尾出加上
=0。- 作用上区别:虚函数一般都是要有定义的,声明得有,定义也得有。纯虚函数它是只有声明没有定义,这其实就是一种接口继承。有纯虚函数的基类,被称为抽象类,它是不能够实列化出对象的,只有被继承才有意义。继承抽象类的派生类,它必须对其纯虚函数进行重写。
- 讲一下多态,虚表初始化?虚表共用,构造函数为什么不能是虚函数?
- 多态的实现依赖的就是虚表,有虚函数的类都会有一个虚表指针,所谓多态就是派生类对基类虚函数进行重写,重写后派生类中所继承的基类虚表中的原虚函数指针会被替换。比如:用一个基类指针
ptr指向派生类对象,ptr去调用被重写的基类虚函数,就会调用派生类重写的版本。而基类指针ptr指向基类对象时,ptr去调用被重写的基类虚函数,调用的是基类的虚函数。很好理解就是因为虚函数表中的虚函数指针被替换了。- 虚表的初始化:一个类对象被创建时,会调用其构造函数,构造函数的列表初始化会对其类内成员变量进行初始化,如果类中有虚函数或者继承的基类有虚函数,那么这时候就会发生虚表的初始化。这初始化其实有点复杂,分为单继承和多继承或者说没有继承。
单继承:拷贝一下基类的虚表,把自己的虚函数放在自己虚表里面。如果发生重写,那就替换一下虚表里虚函数指针。
多继承:按继承的顺序拷贝基类的虚表,把自己的虚函数放在第一个虚表里面。
没有继承:构建一个虚表,把虚函数地址放在虚表中。- 虚表共用:一个类的所有对象都共用同一张虚表,这很节约内存。
- 构造函数不能虚函数,因为前面说了,构造函数的列表初始化期间,才会初始化虚表,也就是说虚表还不存在。类似:先有鸡,后有蛋。
- 什么是虚拟继承?
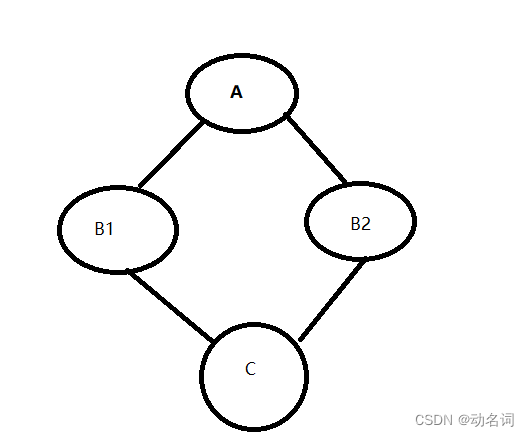
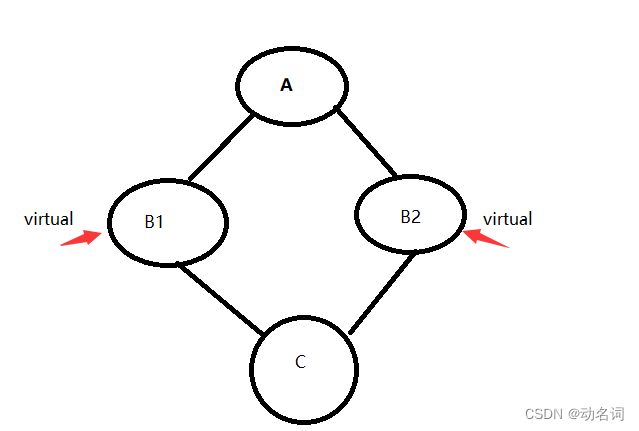
- 虚拟继承用于解决菱形继承中,数据冗余和二义性的问题。
- 比如:原始基类:A ,次派生类:B1 B2 ,派生类:C
假如:类A中有一个成员变量int _a;那么在类C会继承两份_a,因为B1,B2分别继承了一个_a,在C中就有了两份。这就造成了二义性问题,C对象要访问_a,你要指定是访问B1的_a,还是B2的_a。
还有就是数据冗余问题,完全可以只有一份_a就行了,结果继承了两份。
解决方法就是:虚拟继承
这样就是在C中继承了一份A的数据,在C的末尾处会有A的数据。那么原来B1和B2继承A的数据处放的是它俩距离A数据的距离。这个有点抽象,感兴趣的可以看看我的博客
多态。
- 为什么存在friend?
- 有元:friend函数,friend类
- friend可以访问类的private成员,这在一定意义上破坏了封装。
- 注意:friend类的friend属性不会被继承,比如:我和他爸爸是朋友,但不一定和他的儿子是朋友。还有一种情况就是:我和他儿子是朋友,但不一定和他爸爸是朋友。
- friend一般少用,因为一定程度上是破坏封装,但用的得当,也很好用。
就比如:你的成员函数的所有参数都要发生类型转换,这个时候就必须有friend来帮助你。否则会发生问题,这里涉及到this,隐式转换的知识。
- C++构造函数能不能调用虚函数?
- 答案是:可以调用虚函数。
- 注意:虚函数在构造函数期间就不是虚函数。
- 构建派生类对象,先会调用基类的构造函数,如果基类的构造函数调用了虚函数,那么毫无疑问,这时候调用的虚函数是基类版本的,这就造成一个困惑的现象:派生类对象调用的是基类的虚函数,不符合多态。
- 所以切记:不要在构造函数中调用虚函数,也不要在析构函数中调用虚函数。
- 空类的大小?
class{int a},class{int a;void func(){}},class{int a,static int b;},class {int a,virtual void func()}的大小?
- 空类:大小为一个字节,因为每个类对象在内存中都有唯一的地址,空类对象也一样,所以默认给空类一个字节。因为空类大小就不能为0,这样避免了两个问题:new 不会分配0个空间大小,sizeof()不会发生除零错误,所以规定类对象的大小不能为0,所以默认给空类一个字节,从而可以创建空类对象。
- class{int a;void func(){}},大小是4字节,普通成员函数不会影响类的大小,因为普通成员函数可以看成全局函数,它的参数是this指针,以及参数。它是放在代码段的。
- class {int a;static int b;}, 大小是4字节,静态成员也不影响类的大小,它是放在数据段,所有类对象共享一份静态成员。
- class {int a,virtual void func()},大小是8字节,只有有虚函数,就会在类头存一个虚表指针,它的大小是4字节。默认32位机器。
- 结构体的内存对齐规则,以及怎么可以使得同样成员数量的相框下结构体的大小减小?
- 结构体的内存对齐规则:
#pragma pack 可以修改内存对齐规则,默认是4.
- 第一个成员的首地址为0.
- 其他成员变量要对齐到某个数字(对齐数)的整数倍。
- 结构体的总大小,为其成员中所含最大类型的整数倍。
对齐数 = 编译器默认的一个对齐数与成员大小的较小值。
- 结构体大小减小:让相同类型的成员挨在一起放,中间最好不要穿插其他类型成员。
- 讲一下继承方式?
- 接口继承
就是将函数声明为纯虚函数,被派生类继承后,只是继承其接口,并不继承实现。- 实现继承
- 想要实现多态,那么就声明为虚函数,这就是希望派生类可以继承函数实现,并支持它去重写
- 只想让派生类继承函数实现,那么函数不能是虚函数。
以另一个角度看:
- public继承:
is-a的关系,派生类就是基类的一种,基类的所能做的事,派生类也得会做。基类的public在派生类中也是public,protect在派生类中是proctect。- protect继承:这个有点困惑,没啥用。基类的public,proctect在派生类中是protect。
- private继承:has-a的关系,继承基类的public,proctect在派生类中是private,这种关系就是 派生类继承了 基类的一些方法。
- 共同点:基类的private,在派生类中不可见。
2. 指针,智能指针
- 智能指针 auto_ptr 和 shared_ptr的区别
它俩的区别在于:处理拷贝,赋值的情况:
- auto_ptr,它是一种资源转移,会把原来的auto_ptr置空,把资源的处理转交给拷贝它的auto_ptr,或者 被其赋值的auto_ptr。
- shared_ptr,它是利用的引用计数,所有拷贝或赋值了它资源的shared_ptr,都会导致其内部的引用计数+1,如果要释放资源,只有当引用计数为0的时候,才会真正的释放资源,其余情况都是引用计数-1;
- 指针的null和nullptr的区别
- 在C语言中null 是 #define NULL void*(0) 。
- 因为C++是强类型语言,所以不支持NULL发生隐式转换,所以NULL在C++中是#define NULL 0,所以它是一个整型。
- NULL无法代表完全意义上的空指针,C++引入了nullptr,它可以转换成任意对象的空指针。
- 所以在C++中表示空指针,尽量使用nullptr
auto a = null,猜一下a的类型
毫无疑问,类型是整型,值为0。
- unique_ptr不能拷贝,那如何进行资源转移?
- unique_ptr 是不支持拷贝构造和赋值重载的,那么它的资源转移只能使用move()。
- 之所以可以使用move(),是因为unique_ptr 它实现了移动构造和移动赋值重载。
- unique_ptr 资源转移后,它会被置空。
- 智能指针的原理
- 智能指针设计思想是RALL,它通过类的构造获取资源,类的析构来释放资源。
- 它的难点就是拷贝构造和赋值重载的实现:
- auto_ptr C++17已经移除了,它的拷贝构造和赋值重载实现,是靠的资源转移,把它管理的资源赋值给另一个auto_ptr,把自己置空。
- shared_ptr它是利用的引用计数的方式,但是有循环引用的问题。
- unique_ptr它直接把拷贝,赋值重载给delete了,只支持移动拷贝,移动赋值重载。
- weak_ptr 它就解决了shared_ptr的循环引用问题。
- 说一下智能指针的使用场景
- 为了防止内存泄漏,从而使用智能指针对资源进行管理。
- 智能指针有auto_ptr,unique_ptr,shared_ptr,weak_ptr。具体要使用哪类智能指针,还得看使用场景。auto_ptr不建议使用。unique_ptr:专属所有权,它不支持共享资源,只能由一个对象持有。它的性能较高,在内存上没有额外的消耗。shared_ptr,共享所有权,内部利用引用计数来统计管理资源的shared_ptr。考虑到线程安全问题,其内部对引用计数的++,- -都是原子性操作,所以时间消耗变大,同时内存消耗也大于unique_ptr。所以它的使用场景是需要多个智能指针管理同一资源的情况,但是性能肯定略差。weak_ptr是专门用于解决shared_ptr中循环引用问题的。
- shared_ptr的循环引用,线程安全问题?
- shared_ptr循环引用问题,当两个智能指针互相指向时就会出现循环引用的问题。
- 线程安全:shared_ptr内部的引用计数的++ - - 都是原子性操作,不会出现线程安全问题。关键就是对shared_ptr所管理的资源进行访问是线程不安全的。比如对其原始指针的内容进行写操作,拷贝操作都是需要手动的进行线程安全处理的。
- c++中引用和指针的区别
- 引用它是一个变量的别名,声明时必须初始化,并且不可以指向其他的变量
- 指针它根据类型指向某个类型的对象,指针可以修改,中途可以指向其他的变量
- 由于引用声明时就初始化,所以它不会有空指针,野指针问题;如果是指针的话,就要判断指针是否为null的情况。
- 野指针问题
- 在C++中尽量使用引用,如果需要使用指针,那么就要避免野指针的问题。
- 出现野指针的情况:
- 使用未初始化的指针
- 指针释放后,未置空,继续使用指针
- 指针指向的对象,已经被销毁,继续使用指针
- 避免野指针问题:
使用引用 / 记住对指针进行初始化 / 释放指针所指向后,要把指针置为null
- 指针数组和数组指针的区别
- 指针数组是数组,数组中保存的是指针
- 数组指针是指针,指针指向了一个数组
- c++ 中指针函数和函数指针的区别
- 指针函数是一个函数,返回一个指针
- 函数指针是一个指针,它指向了一个函数
- shared_ptr 和 weak_ptr区别
- shared_ptr的默认能力是管理动态内存,但支持自定义的Deleter以实现个性化的资源释放动作。
- weak_ptr用于解决“引用计数”模型循环依赖问题,weak_ptr指向一个对象,并不增减该对象的引用计数器
- 万能引用?
- 万能引用是一个模板,它涉及到了类型的推导,但注意的是函数的参数永远是左值。
- 所以要对函数参数做处理,那就是利用 std::forward,如果函数参数是右值引用,那么forward会把它的右值属性保持下去,如果函数参数是左值引用,那么forward不会对它做处理。
3. 函数
- extern C 的作用?
- extren "C"是为了在C++环境下去编译C的函数,库函数之类的。
- C++和C语言对函数的修饰是不一样的,C++支持重载,所以保存的是函数名以及函数参数,C语言比较简单,就是一个保存函数名。
- 讲一下程序编译的过程
- 预处理器:头文件展开,宏替换,去注释,生成.i 文件
- 编译器:语法分析,词法分析,生成汇编代码 .s 文件
- 汇编器:生成机器码,.o文件
- 链接器:形成可执行 .out文件
- C++11 中lambda表达式?[a]与[&a]的区别?[this]?
- lambda表达式底层是一个仿函数类,构建一个lambda表达式对象,然后调用其operator()重载。
- [a]以值传递捕获某个具体的变量,[&a] 引用传递的捕获某个变量。
- [this],捕获对象,然后可以使用对象内的pubic成员函数。
- 函数是如何调用的?子函数调用返回之后,怎么找到自己的返回位置?
- 函数的调用是在栈上的完成的,由两个寄存器维护函数在栈上的空间,分别是esp,ebp。
- main函数调用子函数,会先把传的参数压在main函数的栈顶,然后调用call指令,call指令有两个动作,一是把main函数下一条指令的地址压在栈顶,二是跳转到子函数处。
- 子函数在栈上开辟地址空间,然后把main栈顶的参数拷贝进来,然后执行子函数,返回的时候,要销毁子函数栈,其实就是esp和ebp,不再管理这片栈内存;再把参数的临时拷贝给释放了,来到存放main函数下一条指令地址处,ret指令被调用,跳转到main的下一个指令处。esp和ebp再次维护main函数的栈区。
- C++中函数符号和C语言的函数符号有什么区别?
- 函数的修饰规则不同,C语言不支持重载,所以符号表中存的就是函数名。
- C++支持重载,所以符号表中存的函数名+函数参数的组合名。
4. 内存管理
- c++内存泄漏和内存溢出的区别
- 内存泄漏:向系统申请的空间不释放,系统不会把这块内存再次分配。
- 内存溢出:指的是向系统申请空间,但是系统没有足够的空间,从而导致内存溢出。
- 内存泄漏如何解决?如何避免?
- 内存泄漏可以用valgrind和mtrace进行泄漏检测。
- 避免内存泄漏:
- 多使用引用
- 使用智能指针对资源进行管理
- 规范的设计类,比如基类的析构函数设置为虚函数
- 加锁解锁的场景?死锁的情况,怎么避免死锁?
- 如果⼀个进程集合中的每⼀个进程都在等待只能由该进程集合中的其他进程才能引发的事件,那么,该进程集合就是死锁
- 遇到野指针,段错误,内存泄漏怎么解决?
- 野指针可以使用shared_ptr和weak_ptr结合使用来尽量规避。
- 使用shared_ptr要尽量小心,否则可能导致对象无法释放,导致内存泄漏。
- 堆和栈的大小?
- 栈是向低地址扩展的数据结构,是一块连续的内存区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,是一个编译时就确定的常数,如果申请空间超过栈的剩余空间时,将提示overflow(溢出)。因此,能从栈获得的空间较小。window下大小为2M,也有点1M。
- 堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是由链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
- new一个类型的对象,依据什么来判断开辟空间的大小?
- new一个类型的对象,会申请类型大小的空间,并且会调用对象的构造函数。
- 底层new也是调用的malloc去申请空间,空间的大小,sizeof(类)。
- 空类是一个特殊情况,它的大小是1字节。
- free后,是不是直接释放?
- free并不是直接还给释放,不会直接还给操作系统。free没有能力释放内存,它只是将内存空间放到free列表中。
- malloc也不是直接向操作系统申请空间,而是先从free列表中查看是否有合适的内存。
- 这样操作提高了效率,不需要频繁的向os申请空间,向os归还空间。
- 说一下,深浅拷贝
a = b
- 浅拷贝就是按照字节序进行拷贝,b的内容和a完全一样,并且如果a中有在堆上开辟的资源,那么b也执行同一个堆上资源。
- 深拷贝就是重新开辟一个空间,把内容拷贝到开辟的空间里,再赋值给b。
- malloc,realloc,calloc的使用
- malloc:
void *malloc(size_t size);,向系统申请分配指定size个字节的内存空间,size是一个无符号数;返回类型为void*,表示不确定返回类型的指针。也就是说,返回类型的指针可以被强制转换成任意类型的指针。- realloc:
void *calloc(size_t n, size_t size),在内存的动态存储区域区中分配n个长度为size的连续存储空间,函数返回一个指向分配起始地址的指针,如果分配不成功,则
返回NULL- calloc:
void *realloc(void *mem_address, unsigned int newsize);,先判断当前的指针是否有足够的连续空间,如果有扩大mem_address指向的地址,并且将mem_address返回,如果空间不够,先按照newsize指定的大小分配空间,将原有数据从头到尾拷贝到新分配的内存区域,而后释放原来mem_address所指内存区域(注意:原来指针是自动释放,不需要使用free),同时返回新分配的内存区域的首地址。即重新分配存储器块的地址。
- C++的内存分布
- 内核空间:放置操作系统相关的代码和数据。
- 栈:非静态局部变量/函数参数/返回值等等,栈是向下增长的
- 内存映射段:是高效的I/O映射方式,用于装载一个共享的 动态内存库。用户可使用系统接口创建共享共享内存,做进程间通信
- 堆:用于程序运行时动态内存分配,堆是可以上增长的
- 数据段:存储全局数据和静态数据。
- 代码段:可执行的代码/只读常量
- 栈上面都会存放哪些东西?
- 函数,非静态局部变量/函数参数/返回值,
- malloc的原理
- malloc是向堆区申请size大小的空间,底层其实很复杂。如果是第一次申请,它是小于mmap的阈值那就是Sbrk申请,如果大于mmap分配的阈值那就是Mmap申请。
- 实际开辟的空间一般比size要大,这是为了减少后续重复申请空间。
- 如果是后续申请空间,是向bin空闲链表申请空间,根据你所申请空间的大小,进行空间分配,优先级fastbin(16-64b)>small bins(2-63b)>unsorted bins(1b) > large bins(64 - 126b)>top bins(扩容)。
- 如何判断内存泄漏?工具?
- 内存泄漏是常见的问题,那么就需要我们有工具去分析程序中是否存在内存泄漏
- 工具是valgrind和matrace,推荐使用valgrind工具它比较常用而且功能强大。
- valgrind中内嵌多个工具,我常用的是memcheck,valgrind --tool==memcheck --leak-check=full ./可执行文件 类似这种格式去检测dubug文件。
- 什么时候会发生段错误?
- 指针访问不明确的地址就会发生段错误。
- 本质是因为操作系统向进程发送了信号SIGSEGV,是由于访问内存管理单元MMU异常所致。
- 发送段错误后,监测段错误问题可以使用dmesg命令,可以找到发送段错误的地址
- malloc和new的区别
- malloc申请堆上的内存,size大小
- new除了会申请内存,还会调用类的构造函数
5. 关键字
- 讲一讲static和const
- 在C语言中:static有两个作用,一是可以将全局变量,函数修饰为内部链接,二是可以将局部变量存放在静态数据段,这样它的生命周期变长,不过需要注意的是它依旧是局部变量,只能在它的作用域内使用。const刚开始被推出是为了取代宏定义变量的,const修饰的全局变量也会被存在符号表中,做常量使用。它可以使得变量具有常量性,不可以被修改。
- 在C++中:static除了在C语言中作用外,它还可以修饰类中的成员变量,成员函数,类中的静态成员是服务类的,它不属于类的任一对象,而是被共用。静态成员变量,函数一般都是在类内声明,在类外定义。const在C++中很常见,除了C语言的作用外,它可以用于修饰类的成员变量,函数。修饰成员函数就是在类后加上const,它使得成员函数内部不能够对成员变量进行修改,注意const修饰的函数是可以构成重载的。
- #define 和 const 的区别
- 更推荐使用const,#define NUM 10 ,const int NUM = 10。它俩没有什么区别。
- 但是,#define在别的头文件中定义,你在实现文件中使用时,有可能会对10有疑惑,所以还得找它的定义,NUM。但是const int NUM是必然在符号表中有的。
- 而且在C++中如果想要在类内定义一个常量,没有private: #define NUM这么一说,也就是#define是不在意作用域的,后面的所有NUM都会被替换。在类中定义常量,可以用const int ,或者可以用 enum{ NUM } 。
- static的作用?局部变量被static修饰与没被修饰存储区域有何不同?
- static有两个作用,一是可以将全局变量,函数修饰为内部链接,二是可以将局部变量存放在静态数据段,这样它的生命周期变长,不过需要注意的是它依旧是局部变量,只能在它的作用域内使用。
- static除了在C语言中作用外,它还可以修饰类中的成员变量,成员函数,类中的静态成员是服务类的,它不属于类的任一对象,而是被共用。静态成员变量,函数一般都是在类内声明,在类外定义。
- inline关键字
- 可以用来定义内联函数,也就是直接把函数体展开。
- inline是对编译器处理函数的一个建议,不是强制的。也就是说 即便你把一个函数声明成inline,它也不一定是内联函数,比如:把一个递归函数声明成inline,编译器在处理的时候不会按照内联处理。
- 在类中定义的函数,默认是inline修饰的,也就是在类内定义函数,其实就是告诉编译器,建议把此成员函数按照内联处理,当然还是定义。
- volatile关键字
- 禁止编译器优化,编译器优化的变量,会保存在寄存器中,从寄存器中读取,比在内存中读取更快。
- volatile修饰的变量,每次读取都是从内存读取,而不是从寄存器中读取。
- 这防止了读取错误,但是并不保证原子性。
- virtual关键字
- 可以把类的普通成员函数修饰为虚函数
- 可以修饰继承方式为虚拟继承,多用在多继承中
- 在这里补充两个关键字:override和final,override它修饰派生类的成员函数,表明此成员函数是必须要重写的。final它可以修饰基类本身,表明不可以被继承;也可以修饰final的虚函数表明不可以被重写。
- static的作用,在c和c++中的区别
区别:上面讲过了,可以看上面。
- extern的作用
- 在C语言:它可以修饰函数或者变量,表明它可以被外部链接。默认一个文件A里面的全局变量和全局函数都是extern的,是外部链接的,如果文件B想要使用文件A的extern变量或者函数,需要在文件B里面使用extern 声明,这样就是告诉文件B的编译器,虽然我要使用的变量没有在我这里定义,但是链接的时候可以在别的文件中找到。如果找不到,那毫无疑问这是欺骗了编译器,在链接的时候会出现问题。
- 在C++中:依旧有上面的作用,我想补充的是extren “C”。它可以让C++中合理的使用C语言的函数。
- 一个变量可以同时被static和const修饰吗?
- 可以的,注意这里不要混淆。
- 局部变量同时被修饰:此变量具有常量性不可以被修改,并且保存在静态区。
- 全局变量同时被修饰:此变量为内部链接,并且不可以被修改。
- 用全局变量取代static可以吗?
- 不可以
- 首先,如果是局部变量static,它的作用域只在其定义函数内,用全局变量会扩大它的作用域。
- 其次,全局变量static和全局变量,一个是支持内部链接,一个是外部链接。
- 静态变量啥时候初始化?
- 静态变量:全局静态变量,局部静态变量,类内的静态成员变量
- 全局变量,全局静态变量,局部静态变量,都是在编译期完成初始化的,有给定值就是赋值,没有给定值,那就是默认为0。
- 类内的静态成员:一般都是类内声明,类外定义,它也是编译期完成初始化,被所有的类共用,想要操作这个静态成员,可以使用类内的静态成员函数。
不过有懒汉和饿汉这么一说,比如静态成员是一个指针,要开辟空间的。懒汉就是先定义成nullptr,等到真正使用这个类,也就是类对象被创建出来,再去为静态成员指针去开辟空间。饿汉就是一上来就定义好了一段空间,供给使用。
6. C++11新特性
- 右值引用的使用场景
- 实现移动构造和移动赋值,提高了效率
- 给临时对象起别名,使得右值有了左值的属性,比如可以取地址,赋值之类的
- 实现万能模板
- c和c++的区别
- C++是C的超集,这意味着一个有效的C程序也是一个有效的C++程序。
- C和C++的主要区别是,C++支持许多附加特性。但是,C++中有许多规则与C稍有不同。这些不同使得C程序作为C++程序编译时可能以不同的方式运行或根本不能运行。
- enum在c和c++的区别
- C 枚举类型支持不同类型枚举值之间赋值、以及数字赋值、比较,并且具有外层作用域。
- C++ 中枚举不允许不同类型的值给枚举类型变量赋值,但仍然支持不同类型之间枚举进行比较,枚举符号常量具有挖外作用域。
- C++ 强枚举类型不允许不同类型之间的赋值、比较,枚举常量值并不具有外层作用域。
- 说一下,四种类型转换
- static_cast: 相近类型的转换,类似于C语言里面的隐式转换
- reinterpret_cast:强制转换
- const_cast:去除常量属性
- dynamic_cast:用于检查父类子类之间的赋值
相关内容
热门资讯
埃菲尔铁塔在哪 中国仿建埃菲尔...
2019年4月26日,广西南宁市,街头惊现一座巨型山寨版埃菲尔铁塔,高约20米,白色塔身,造型逼真,...
北京的名胜古迹 北京最著名的景...
北京从元代开始,逐渐走上帝国首都的道路,先是成为大辽朝五大首都之一的南京城,随着金灭辽,金代从海陵王...
苗族的传统节日 贵州苗族节日有...
【岜沙苗族芦笙节】岜沙,苗语叫“分送”,距从江县城7.5公里,是世界上最崇拜树木并以树为神的枪手部落...
长白山自助游攻略 吉林长白山游...
昨天介绍了西坡的景点详细请看链接:一个人的旅行,据说能看到长白山天池全凭运气,您的运气如何?今日介绍...
应用未安装解决办法 平板应用未...
---IT小技术,每天Get一个小技能!一、前言描述苹果IPad2居然不能安装怎么办?与此IPad不...
世界上最漂亮的人 世界上最漂亮...
此前在某网上,选出了全球265万颜值姣好的女性。从这些数量庞大的女性群体中,人们投票选出了心目中最美...
猫咪吃了塑料袋怎么办 猫咪误食...
你知道吗?塑料袋放久了会长猫哦!要说猫咪对塑料袋的喜爱程度完完全全可以媲美纸箱家里只要一有塑料袋的响...
脚上的穴位图 脚面经络图对应的...
人体穴位作用图解大全更清晰直观的标注了各个人体穴位的作用,包括头部穴位图、胸部穴位图、背部穴位图、胳...
demo什么意思 demo版本...
618快到了,各位的小金库大概也在准备开闸放水了吧。没有小金库的,也该向老婆撒娇卖萌服个软了,一切只...
埃菲尔铁塔在哪 中国仿建埃菲尔...
2019年4月26日,广西南宁市,街头惊现一座巨型山寨版埃菲尔铁塔,高约20米,白色塔身,造型逼真,...
苗族的传统节日 贵州苗族节日有...
【岜沙苗族芦笙节】岜沙,苗语叫“分送”,距从江县城7.5公里,是世界上最崇拜树木并以树为神的枪手部落...
北京的名胜古迹 北京最著名的景...
北京从元代开始,逐渐走上帝国首都的道路,先是成为大辽朝五大首都之一的南京城,随着金灭辽,金代从海陵王...
应用未安装解决办法 平板应用未...
---IT小技术,每天Get一个小技能!一、前言描述苹果IPad2居然不能安装怎么办?与此IPad不...
长白山自助游攻略 吉林长白山游...
昨天介绍了西坡的景点详细请看链接:一个人的旅行,据说能看到长白山天池全凭运气,您的运气如何?今日介绍...
脚上的穴位图 脚面经络图对应的...
人体穴位作用图解大全更清晰直观的标注了各个人体穴位的作用,包括头部穴位图、胸部穴位图、背部穴位图、胳...
demo什么意思 demo版本...
618快到了,各位的小金库大概也在准备开闸放水了吧。没有小金库的,也该向老婆撒娇卖萌服个软了,一切只...
世界上最漂亮的人 世界上最漂亮...
此前在某网上,选出了全球265万颜值姣好的女性。从这些数量庞大的女性群体中,人们投票选出了心目中最美...