VINS-Mono中的边缘化与滑窗 (2)—— 边缘化最老帧
文章目录
- 1. 添加和最老帧有关的参数块
- 1.1. 和最老帧的IMU约束有关的参数块
- 1.2. 和最老帧的视觉重投影约束有关的参数块
- 2. `MarginalizationInfo::preMarginalize()`边缘化预处理
- 2.1. 计算每个残差块的残差和雅克比
- 2.2. 缓存边缘化之前的参数值
- 3. 执行边缘化舒尔补
- 3.1. 统计参数块在边缘化变量中的顺序
- 3.1.1. 优先排列要边缘化掉的参数块
- 3.1.2. 继续排列剩下的边缘化保留的参数块
- 3.2. 多线程构造方程HΔx=gH\Delta x = gHΔx=g
- 3.2.1. 把残差块分配到每个线程中
- 3.2.2. 每个线程中计算H和g
- 3.2.3. 求解舒尔补
- 3.2.4. 对方程H′Δxb=g′H' \Delta x_b = g'H′Δxb=g′中的H′,g′H', g'H′,g′分解得到雅克比矩阵和残差
- 4. 存储边缘化后结果,给下次非线性优化使用
- 4.1. 存储保留下的参数块信息
- 4.2. 赋值本次边缘化变量到全局变量中
- 5. 下次非线性优化使用上次的边缘化因子 MarginalizationFactor
- 5.1. 确定边缘化因子的残差维度和每个参数块维度
- 5.2. 重载`Evaluate`函数计算残差和雅克比
- 5.2.1. 残差计算方式
- 5.2.2. 雅克比计算方式
1. 添加和最老帧有关的参数块
1.1. 和最老帧的IMU约束有关的参数块

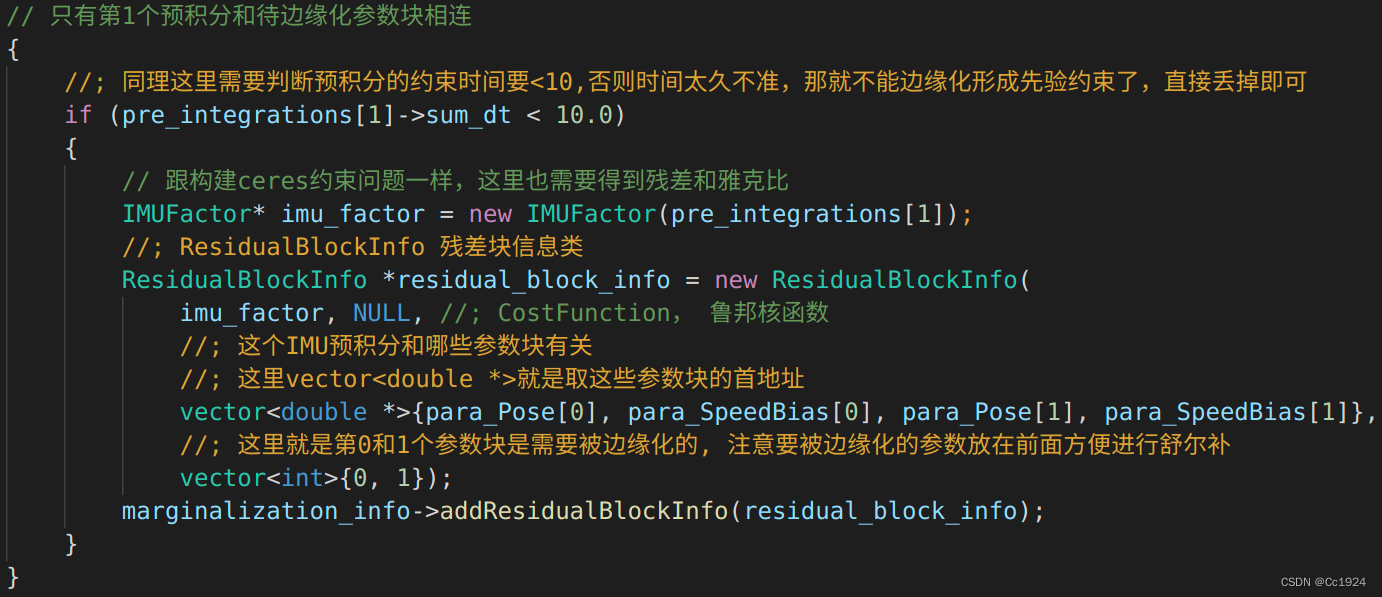
如图所示,第一帧的位姿T1T_1T1和速度零偏B1B_1B1是通过IMU预积分约束和滑窗中的最老帧存在约束关系的。
因此和最老帧有关的IMU预积分约束包含的参数块是T0,B0,T1,B1T_0, B_0, T_1, B_1T0,B0,T1,B1,要边缘化掉的参数块是T0,B0T_0, B_0T0,B0。
代码如下:
在MarginalizationInfo::addResidualBlockInfo函数中,会用一些MarginalizationInfo类变量将上面构建的ResidualBlockInfo残差信息块存储起来:
| 变量 | 内容 |
|---|---|
| factors | 上面构建的IMU残差的残差块residual_block_info |
| parameter_blocks | 这个残差块有关的参数内存地址,即T0,B0,T1,B1T_0, B_0, T_1, B_1T0,B0,T1,B1 |
| parameter_block_size | (参数内存地址数值,参数global维度), 如(&T0T_0T0, 7) (&B0B_0B0, 9) (&T1T_1T1, 7) (&B1B_1B1, 9) |
| parameter_block_idx | (要边缘化掉的参数的内存地址数值,索引暂时赋值0),如(&T0T_0T0, 0) (&B0B_0B0, 0) |
1.2. 和最老帧的视觉重投影约束有关的参数块
第1234帧的 位姿TiT_iTi 是通过视觉重投影和最老帧联系在一起的,此外视觉重投影中还包括IMU和相机外参TicT_{ic}Tic,还包括每个点的逆深度。
因此最老帧看到的每一个视觉点和其他帧构成的视觉重投影约束包含的参数块是:T0,Tj,Tic,λiT_0, T_j, T_{ic}, \lambda_iT0,Tj,Tic,λi,要边缘化掉的参数块是T0,λiT_0, \lambda_iT0,λi。
代码如下:

在MarginalizationInfo::addResidualBlockInfo函数中,会用一些MarginalizationInfo类变量将上面构建的ResidualBlockInfo残差信息块存储起来:
| 变量 | 内容 |
|---|---|
| factors | 上面构建的视觉重投影残差的残差块residual_block_info |
| parameter_blocks | 这个残差块有关的参数内存地址,如T0,T2,Tic,λ1T_0, T_2, T_{ic}, \lambda_1T0,T2,Tic,λ1 |
| parameter_block_size | (参数内存地址数值,参数global维度), 如(&T0T_0T0, 7) (&T2T_2T2, 7) (&TicT_{ic}Tic, 7) (&λi\lambda_iλi, 1) |
| parameter_block_idx | (要边缘化掉的参数的内存地址数值,索引暂时赋值0),如(&T0T_0T0, 0) (&λi\lambda_iλi, 0) |
2. MarginalizationInfo::preMarginalize()边缘化预处理
2.1. 计算每个残差块的残差和雅克比
手动调用ResidualBlockInfo::Evaluate()函数计算每个残差块的残差和雅克比,其内部本质上还是调用了我们定义的各种Factor因子里面的Evaluate函数,比如IMU预积分因子、视觉重投影因子,我们在这些因子中的Evaluate函数中定义了残差和雅克比如何计算,从而提供给ceres进行非线性优化使用。
代码如下:

将计算的结果存到残差块ResidualBlockInfo的类成员变量中:
| 变量 | 内容 |
|---|---|
| residuals | 残差块的残差 |
| jacobians | 残差块对和它有关的参数块的雅克比 |
2.2. 缓存边缘化之前的参数值
这一步是为了边缘化之后,下一次非线性优化执行的时候,计算边缘化约束的残差而使用的,所以这里就是把数据存储到类成员变量中。
代码如下:

3. 执行边缘化舒尔补
3.1. 统计参数块在边缘化变量中的顺序
边缘化的原则是:将要被边缘化的参数块放在状态变量的前面。比如上面的图,我们所有的状态变量是
T0,B0,T1,B1,T2,T3,T4,Tic,λ1,λ2,λ3T_0, B_0, T_1, B_1, T_2, T_3, T_4, T{ic}, \lambda_1, \lambda_2, \lambda_3T0,B0,T1,B1,T2,T3,T4,Tic,λ1,λ2,λ3,要边缘化掉的参数块是T0,B0,λ1,λ2,λ3T_0, B_0, \lambda_1, \lambda_2, \lambda_3T0,B0,λ1,λ2,λ3。那么就把这些变量放在前面,然后在状态变量中的索引按照内存维度来排列。
3.1.1. 优先排列要边缘化掉的参数块
代码:

将要边缘化掉的参数块放在前面,对每一个参数块在边缘化的大向量XXX中的内存索引进行排列,结果更新到MarginalizationInfo的类成员变量parameter_block_idx中。注意变量用localPose,即实际自由度;而golbalPose是参数块存储的维度;比如对位姿来说,localPose是6,globalPose是7。
上面的程序执行后,结果如下:
| 变量 |
|---|
| parameter_block_idx(&T0T_0T0, 0), localPose = 6 |
| parameter_block_idx(&B0B_0B0, 6) , localPose = 9 |
| parameter_block_idx(&λ1\lambda_1λ1, 15), localPose = 1 |
| parameter_block_idx(&λ2\lambda_2λ2, 16), localPose = 1 |
| parameter_block_idx(&λ3\lambda_3λ3, 17), localPose = 1 |
| m = 18 (6+9+1+1+1),要边缘化掉的参数的维度 |
3.1.2. 继续排列剩下的边缘化保留的参数块
代码:

把剩下的边缘化保留下的参数块排在后面,对这些参数块在边缘化的大向量XXX中的内存索引进行排列,结果同样存储在上面的变量中。注意变量用localPose,即实际自由度。
假设这里排序的时候留下的参数块的排列顺序如下,我们这里故意颠倒了T3,T2T_3, T_2T3,T2的顺序,是为了后面说明这个顺序其实没有影响:
| 变量 |
|---|
| parameter_block_idx(&T1T_1T1, 18), localPose = 6 |
| parameter_block_idx(&B1B_1B1, 24), localPose = 9 |
| parameter_block_idx(&T3T_3T3, 33), localPose = 6 |
| parameter_block_idx(&T2T_2T2, 39), localPose = 6 |
| parameter_block_idx(&T4T_4T4, 45), localPose = 6 |
| parameter_block_idx(&TicT_{ic}Tic, 51), localPose = 6 |
| n = 57 - 18 = 39 保留下的参数的维度 |
因此最后状态变量的顺序如下,其中前5个是要被边缘化掉的。
| T0T_0T0 | B0B_0B0 | λ1\lambda_1λ1 | λ2\lambda_2λ2 | λ3\lambda_3λ3 | T1T_1T1 | B1B_1B1 | T3T_3T3 | T2T_2T2 | T4T_4T4 | TicT_{ic}Tic |
|---|
3.2. 多线程构造方程HΔx=gH\Delta x = gHΔx=g
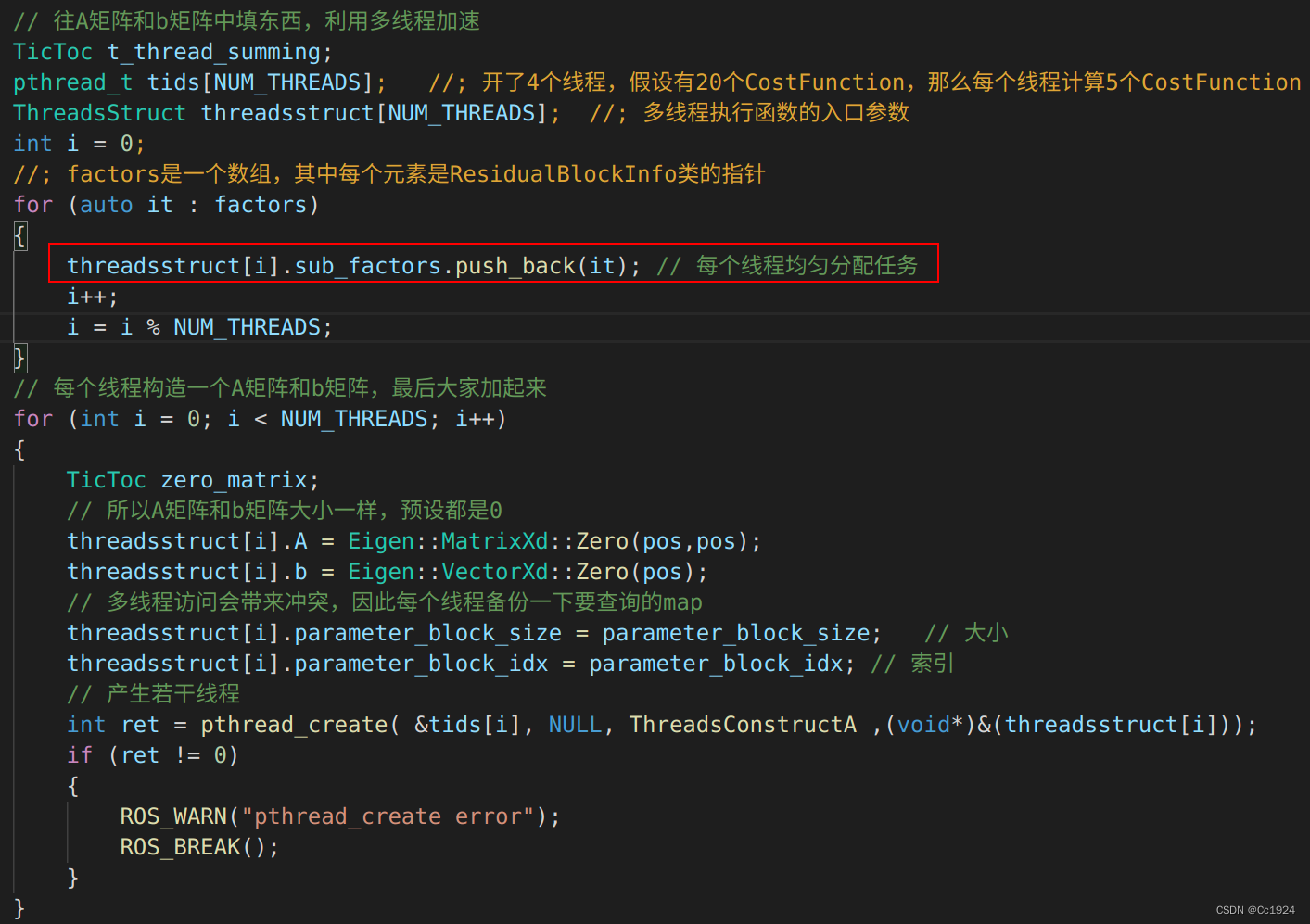
3.2.1. 把残差块分配到每个线程中
将之前存储在factor中的所有残差块都平均分配到四个线程中,然后在每个线程中对残差块进行处理。
代码如下:
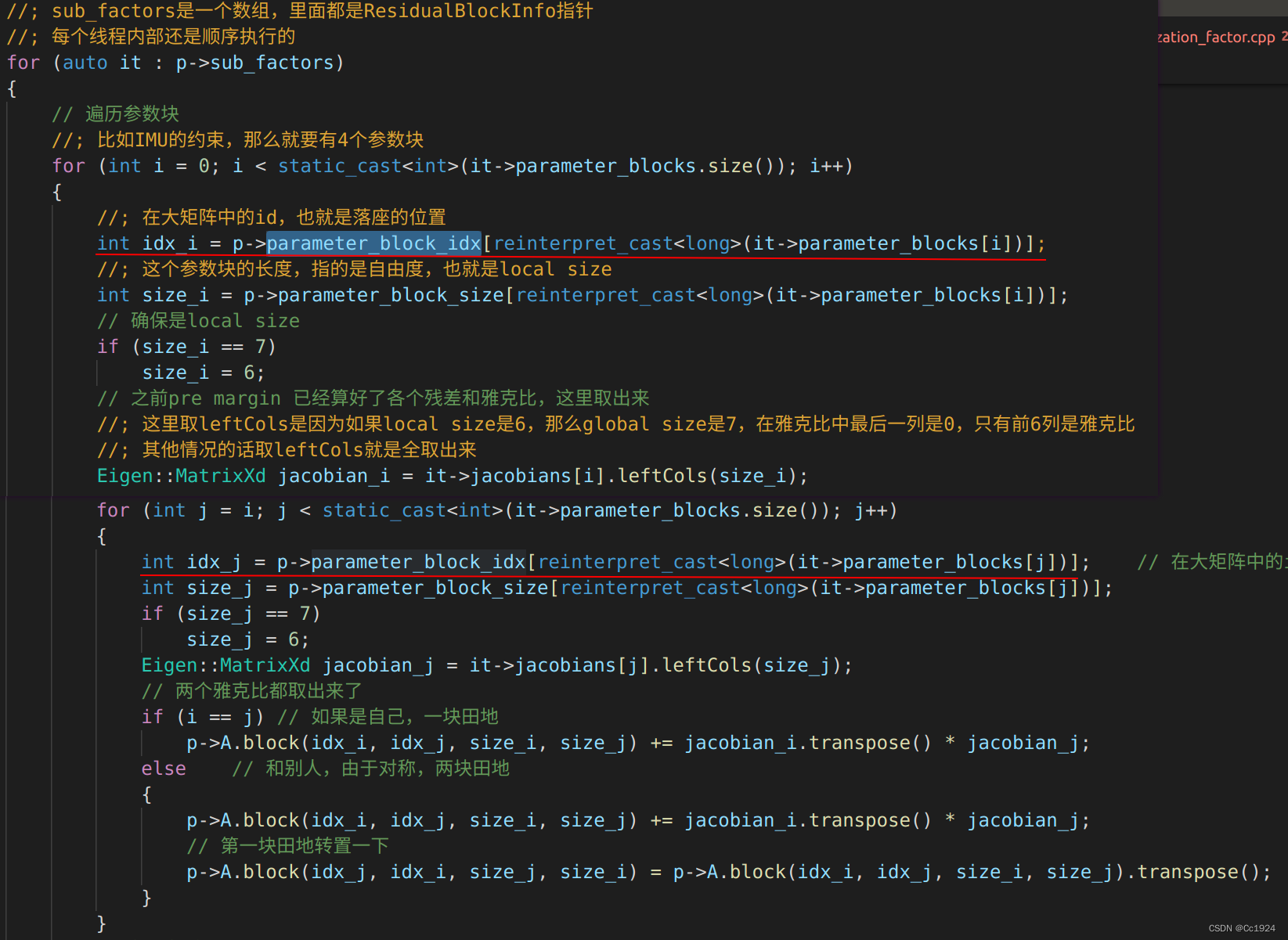
3.2.2. 每个线程中计算H和g
对最终每个线程计算的HHH和ggg都加起来,就得到最后总的HHH和ggg。
代码如下:
分析如下:
H=JTJH = J^T JH=JTJ,其中J(n,m)J(n, m)J(n,m),nnn是边缘化中所有残差块的总维度,mmm是边缘化中所有参数块的总维度,所以最后H(m,m)H(m,m)H(m,m)是和所有参数块的总维度相等的,和残差块的维度无关。
这里以 T0−λ1−T3−TicT_0 - \lambda_1 - T_3 - T_{ic}T0−λ1−T3−Tic 构成的视觉重投影约束为例(注意视觉重投影要从IMU系到相机系转换,因此参数块包含外参),其在雅克比矩阵中的位置如下。注意该雅克比矩阵的行数是这个残差块的维度,视觉重投影中就是2;而对每一个参数块的雅克比的列数就是这个参数块的维度,比如T0T_0T0是6列,λ1\lambda_1λ1是1列。

那么HHH矩阵如下所示,可见HHH矩阵中每一块的位置都只和状态变量的位置有关,而和残差无关。
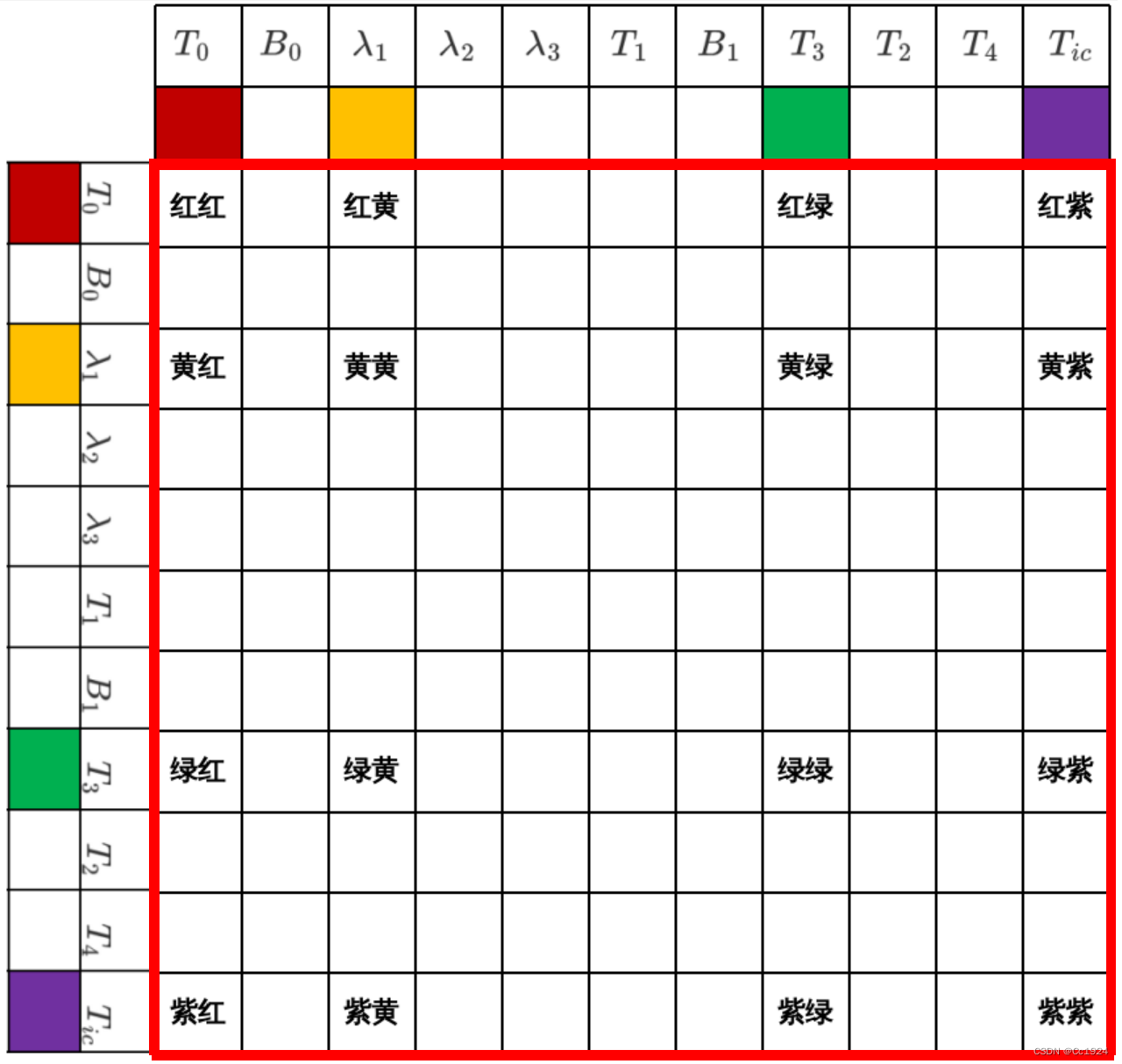
3.2.3. 求解舒尔补
对HHH矩阵按照要边缘化的参数块的位置进行分块,然后进行舒尔补得到只包含保留下来的参数块的方程H′Δxb=g′H' \Delta x_b = g'H′Δxb=g′。
代码:
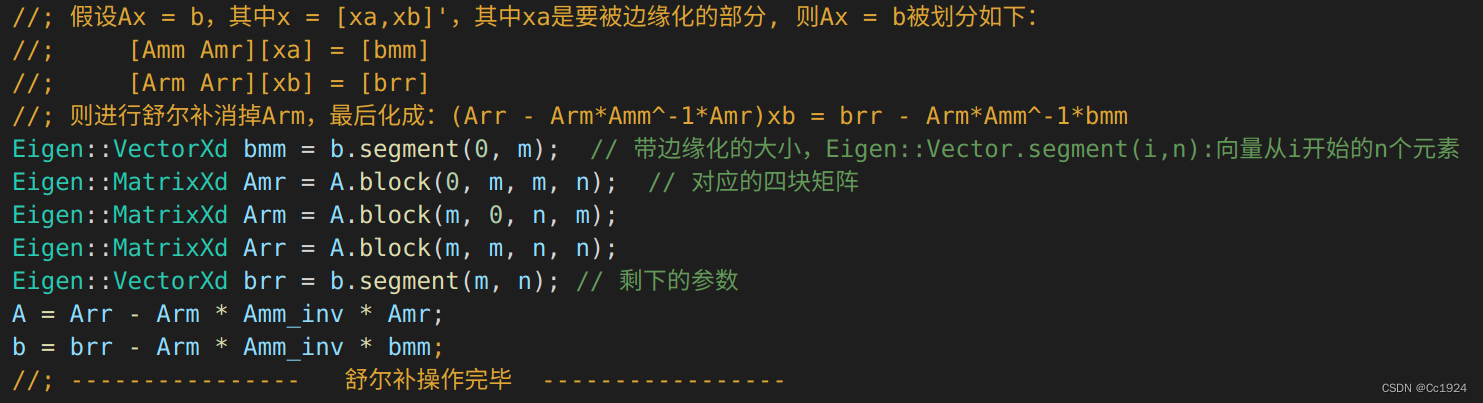
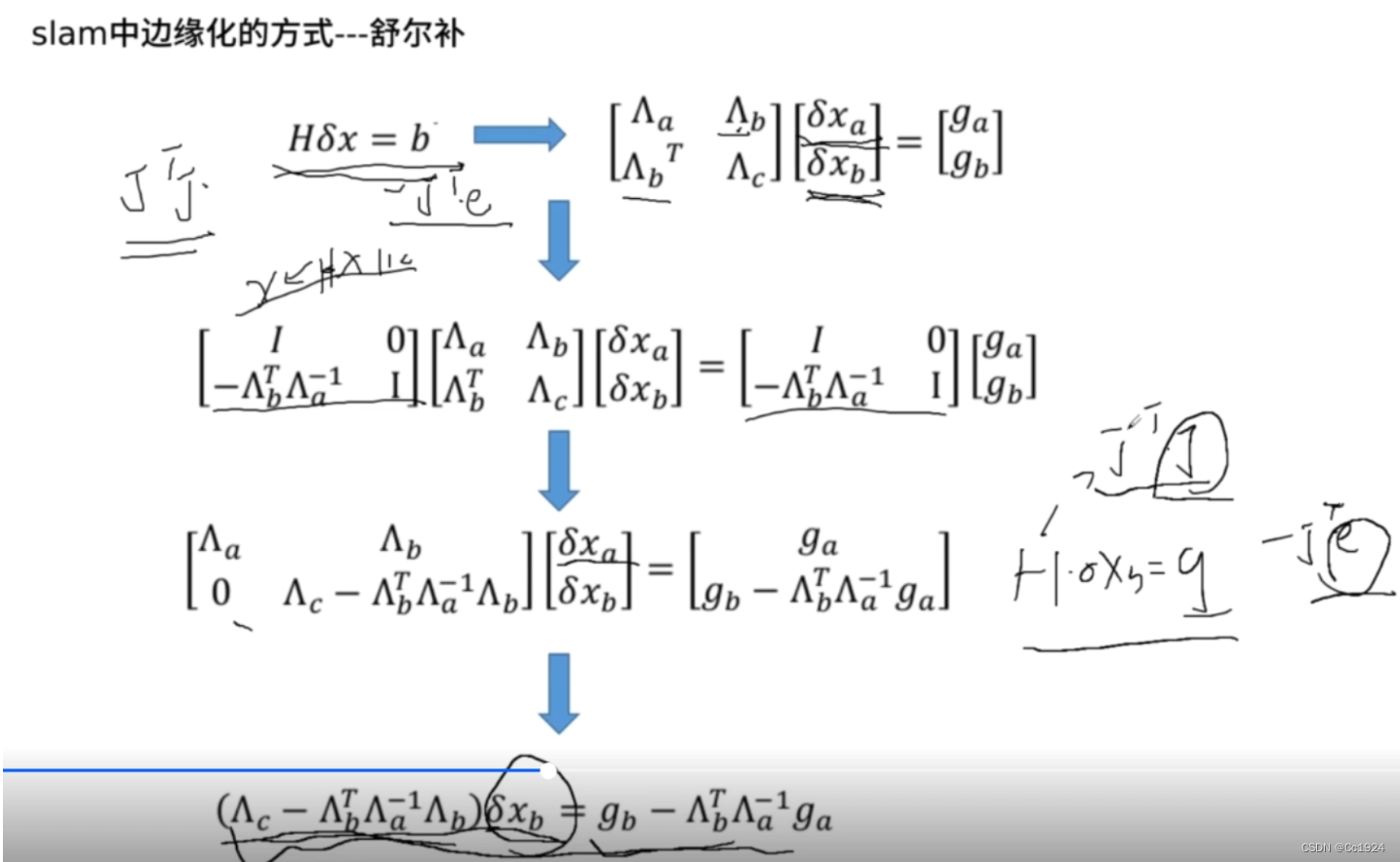
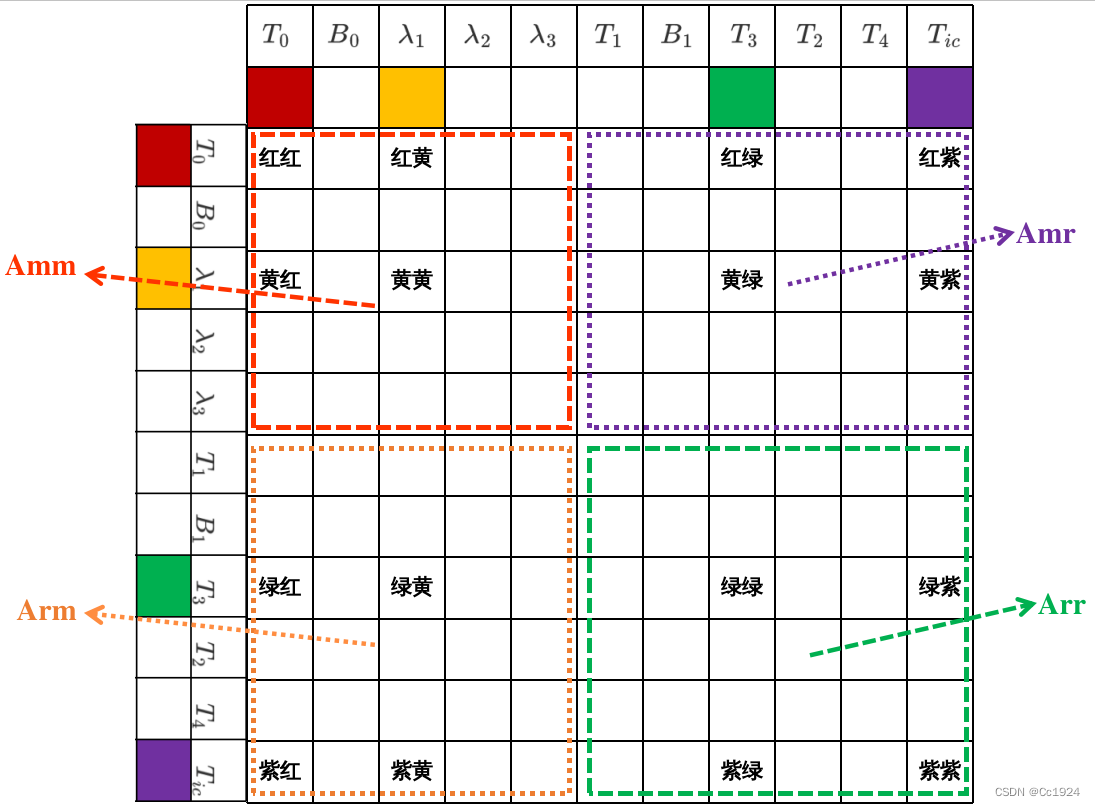
3.2.4. 对方程H′Δxb=g′H' \Delta x_b = g'H′Δxb=g′中的H′,g′H', g'H′,g′分解得到雅克比矩阵和残差
边缘化最终的目的就是得到像普通的IMU预积分约束和视觉重投影约束一样的结果:残差和关于哪些参数块的雅克比矩阵。而我们得到的是H′Δxb=g′H' \Delta x_b = g'H′Δxb=g′,如果通过正常的残差和雅克比矩阵的话,等效的方程就是JTJΔx=−JTeJ^TJ \Delta x = -J^T eJTJΔx=−JTe,所以我们要从H′H'H′和g′g'g′中分离出残差和雅克比矩阵。
代码如下:
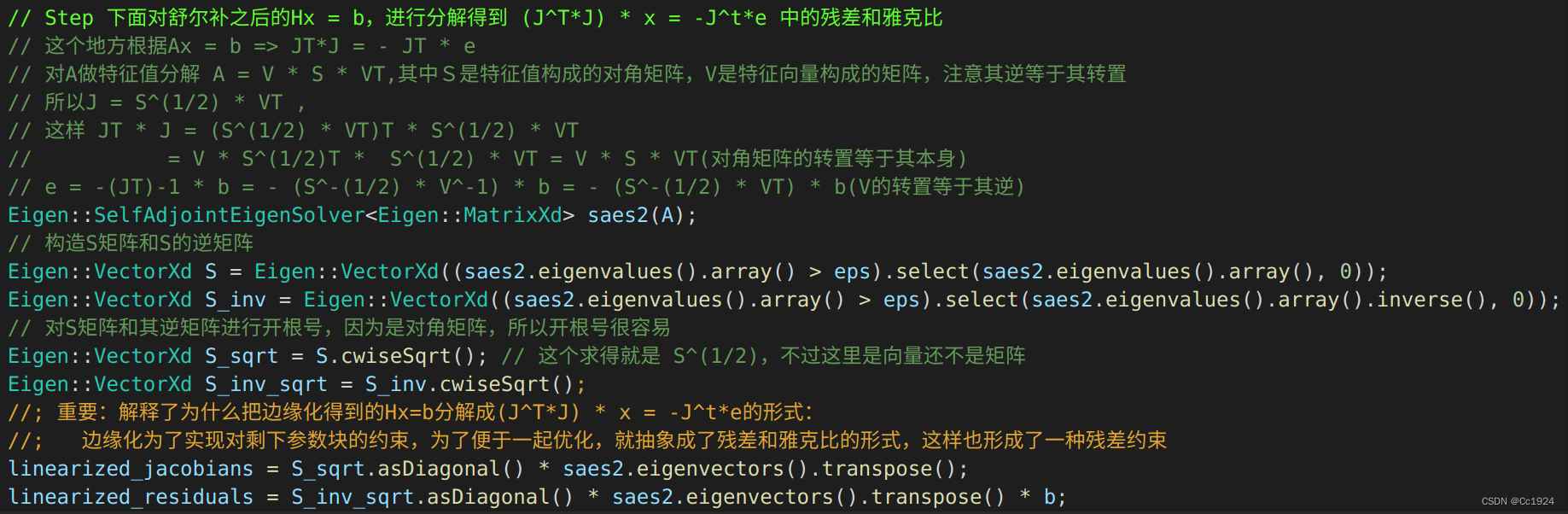
最终得到存储在MarginalizationInfo类中的成员变量linearized_jacobians和linearized_residuals,代表边缘化得到的残差和雅克比。
注意思考:
1.残差的维度是多少?其实是和留下来的状态变量的维度一样的,因为我们对H′H'H′矩阵进行的是类似开根号的分解,所以得到的JJJ矩阵还是一个方阵,其行数和列数都是保留下的状态变量的维度。
2.雅克比矩阵是对哪些参数块的雅克比?这个根据上面的解释很显然了,就是对边缘化留下来的状态变量参数块的雅克比。
| 变量 | 内容 |
|---|---|
| linearized_jacobians | 对留下来的状态的雅克比,即对T1,B1,T3,T2,T4,TicT_1, B_1, T_3, T_2, T_4, T_{ic}T1,B1,T3,T2,T4,Tic的雅克比 |
| linearized_residuals | 和留下来的状态维数一样的残差,上面的例子就是 n = 39 |
4. 存储边缘化后结果,给下次非线性优化使用
4.1. 存储保留下的参数块信息
对于边缘化最老帧来说,边缘化之后,下一次再进行非线性优化的时候,第1帧就存到第0帧的位置,第2帧存到第1帧的位置,依次类推,因此要记录这次边缘化留下的参数块在下一次进行非线性优化的时候内存地址在哪里。
代码如下(注意下面这个addr_shift只是一个局部变量,其真正起作用是被传入getParameterBlocks函数中起作用):
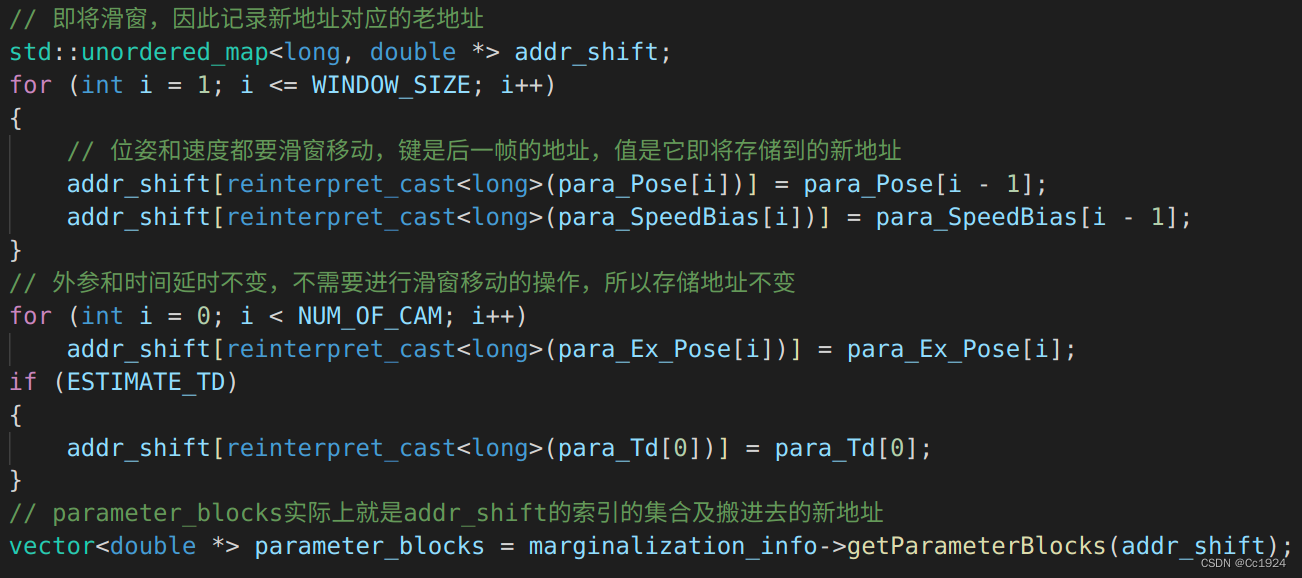
然后在MarginalizationInfo::getParameterBlocks函数中,会保存边缘化留下来的参数块的信息到MarginalizationInfo类成员变量中:
| 变量 | 内容 |
|---|---|
| keep_block_size | 留下来的参数块的global维度,如留下T1,B1,T3,T2,T4,TicT_1, B_1, T_3, T_2, T_4, T_{ic}T1,B1,T3,T2,T4,Tic,则为7, 9, 7, 7, 7, 7 |
| keep_block_idx | 留下来的参数块在边缘化的大向量XXX中的索引位置,本例为 18, 24, 33, 39, 45, 51 |
| keep_block_data | 留下来的参数块在边缘化之前的值,即parameter_block_data中对应的参数块的值 |
| keep_block_addr | 函数返回值,即留下来的参数在下次优化的时候(经过滑窗地址已变)的内存地址 |
4.2. 赋值本次边缘化变量到全局变量中

| 变量 | 内容 |
|---|---|
| last_marginalization_info | 本次边缘化得到的结果,各种变量都在其中 |
| last_marginalization_parameter_blocks | 本次边缘化保留下的参数块在下次优化的时所在的内存地址 |
注意思考:
问题:既然last_marginalization_info保留了MarginalizationInfo这个边缘化的巨无霸类,这个类中已经包含了keep_block_size等记录本次边缘化保留下来的参数块的信息,为什么不把last_marginalization_parameter_blocks参数块也定义在类中呢?
解答:其实主要是为了下次非线性优化的时候使用边缘化先验因子方便,因为在ceres中添加残差块的时候,通常要传入3大块参数,如下所示:
problem.AddResidualBlock(残差块因子, 鲁棒核函数, 和残差块因子有关的参数块1内存地址, 和残差块因子有关的参数块2内存地址, ...);
-
残差块因子:就是各种
Factor,里面重载了Evaluate函数,其中定义了如何计算残差,如何计算残差对优化参数块的雅克比矩阵; -
鲁棒核函数:排除外点用的;
-
优化参数块内存地址:这部分就是和残差块因子有关的优化参数块的地址,有多个参数块的话就要分别传入每个参数块的首地址。而我们定义的是
vector,可以直接传入一个,会自动隐式转换成多个==?==反正就是可以这样用,比写在类中更加方便。last_marginalization_parameter_blocks;
5. 下次非线性优化使用上次的边缘化因子 MarginalizationFactor
5.1. 确定边缘化因子的残差维度和每个参数块维度
首先明确每次边缘化的残差和雅克比的维度都不一样:假设每次边缘化都是边缘化掉最老帧,那么关于IMU因子的边缘化残差维度和状态变量的维度是确定的。但是每次视觉重投影的边缘化,由于看到的路标点数目不确定,这些路标点被哪些帧看到也不确定,因此他们的参数块个数是不确定的。这就意味着我们无法在编译程序的时候就确定这个维度,所以就无法使用ceres中普通的确定维度的Factor,即继承SizedCostFunction的Factor,如下所示:
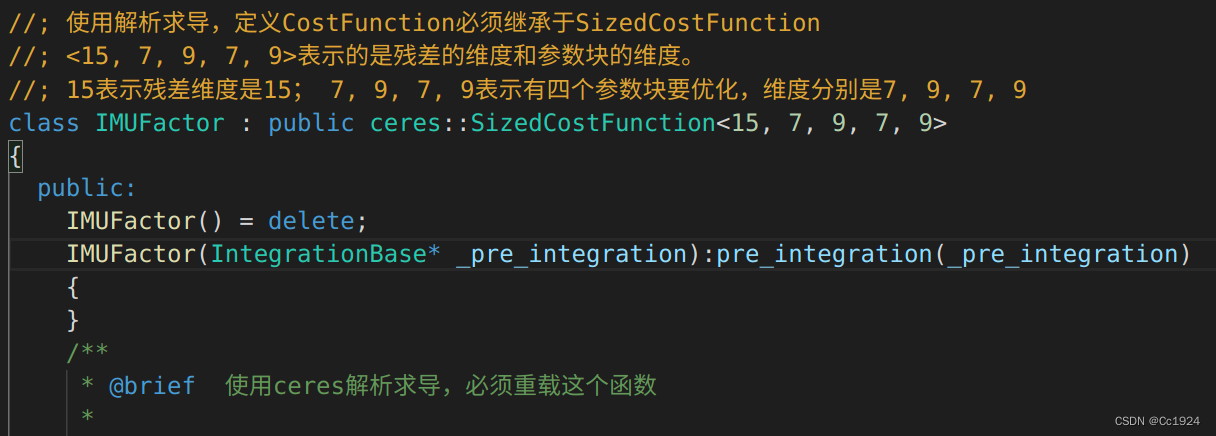
所以只能使用更加基础的CostFunction,然后在类的构造函数中,每次运行到这里我都知道了上一次边缘化的参数块个数和残差维度,然后在类的构造函数中对CostFunction的残差块维度和各个优化参数块的维度进行赋值,注意这里对优化参数块维度是使用globalSize,因为我们要的是本次优化参数块在内存中存储的维度,这也是我们边缘化的最后存储留下来的参数块的globalSize到变量keep_block_sieze的原因。
代码如下:
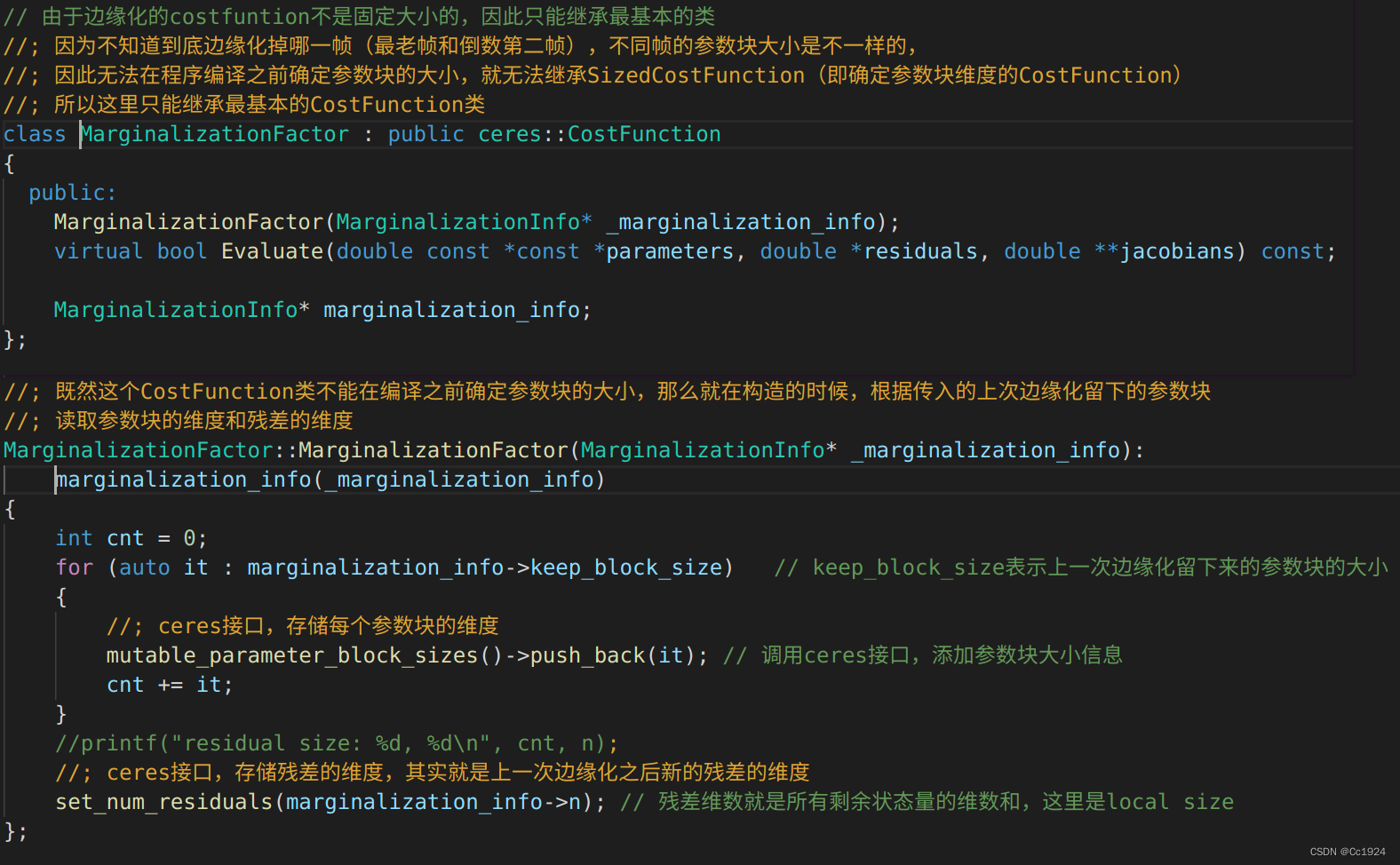
5.2. 重载Evaluate函数计算残差和雅克比
5.2.1. 残差计算方式
代码如下:
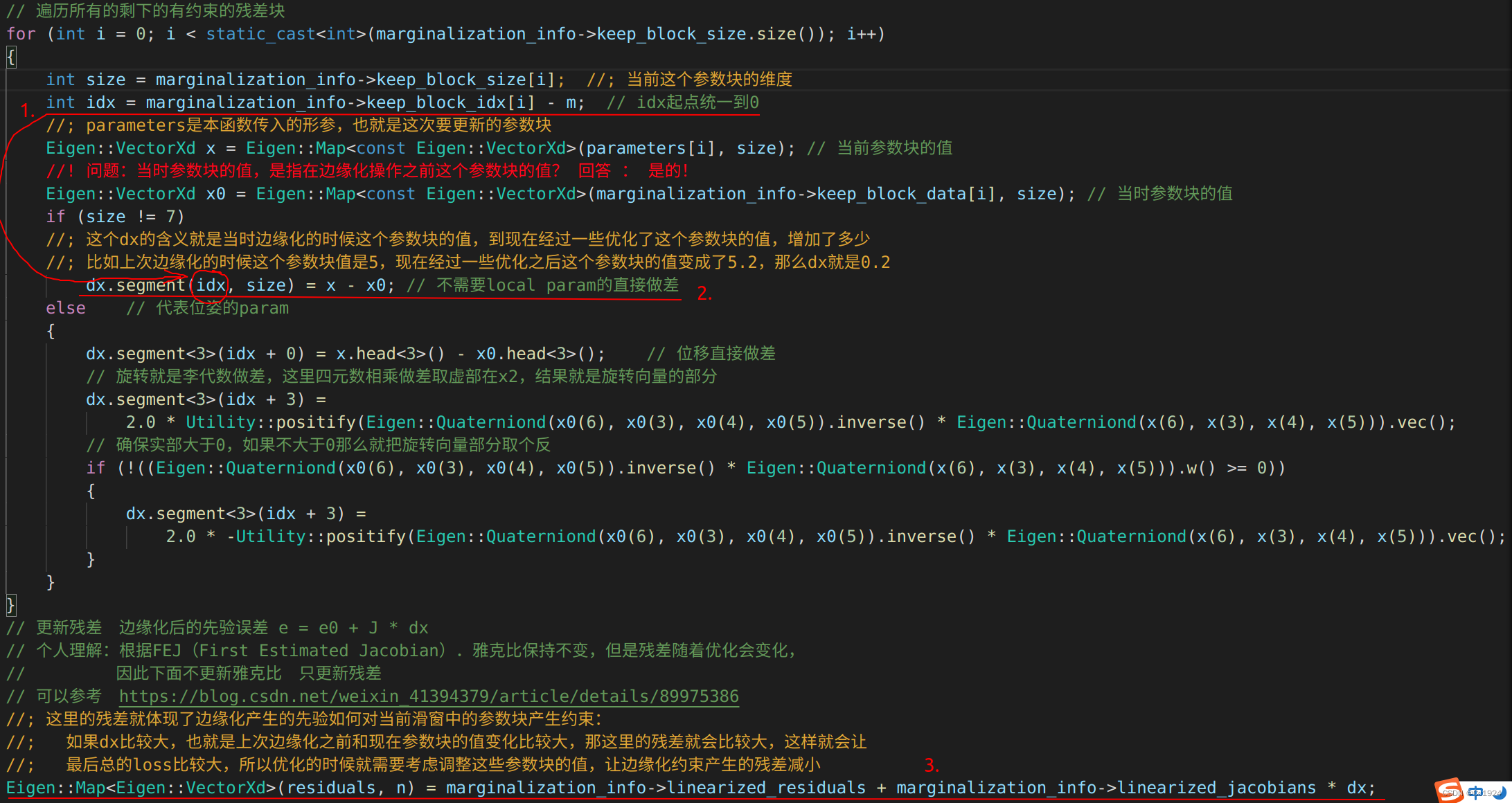
上面的程序中,需要理解三个地方:
-
为什么要把残差的
index统一到0? -
为什么要把本次优化参数块和上次边缘化之前对应的参数块做差?
-
FEJ(First Estimated Jacobian)是怎么回事?
解答这三个问题,要从头开始慢慢思考:
1. 边缘化得到的残差和雅克比是什么意义?
首先我们知道边缘化得到的残差维度就是边缘化留下来的所有参数块的localSize的和,然后我们还保存了边缘化之前这些参数块的值。这就相当于我们边缘化得到了一个对留下来的参数块的先验因子,如下图所示,我们边缘化掉的参数块变成了灰色,然后它们对留下来的参数块形成了一个先验因子。这个先验因子就好比是我们对这些保留下来的状态的一个约束,约束这次非线性优化的时候这些状态不能离先验因子表示的状态太远。
 2.那么这里的先验因子是什么呢?是边缘化得到的残差吗?
2.那么这里的先验因子是什么呢?是边缘化得到的残差吗?
按照后面的公式看并不是,代码中的公式如下:
dx.segment(idx, size) = x - x0; // 不需要local param的直接做差
Eigen::Map(residuals, n) = marginalization_info->linearized_residuals + marginalization_info->linearized_jacobians * dx;
(1)按照公式可以这么理解:
我们得到的先验因子其实就是边缘化之前的参数块的值,也就是程序中的keep_block_data,它约束这我们这次进行非线性优化的结果不能离这个值太远。那么从边缘化过程中来看,我们得到的雅克比是边缘化得到的残差e0\boldsymbol e_0e0关于边缘化保留下来的状态的雅克比,对应到上面的程序中,就是对x0的雅克比,即J=∂e0∂x0\boldsymbol J = \frac{\partial{\boldsymbol {e}_0}}{\partial{\boldsymbol {x}_0}}J=∂x0∂e0。但是现在我们优化的是x,是这次的状态变量,而x0只是上次优化的结果,在这次优化过程中它是一个常数。但是我们也说了,x0是作为x的先验因子,这意味着x和x0不会相差太远。那么之前边缘化时候的雅克比J=∂e∂x0\boldsymbol J = \frac{\partial{\boldsymbol e}}{\partial{\boldsymbol {x}_0}}J=∂x0∂e,就约等于J=∂e∂x−x0\boldsymbol J = \frac{\partial{\boldsymbol e}}{\partial{\boldsymbol x - \boldsymbol {x}_0}}J=∂x−x0∂e。
注意:前面的一个偏导x0\boldsymbol {x}_0x0是状态变量,因此x0\boldsymbol {x}_0x0是变量;后面的一个偏导x\boldsymbol {x}x是状态变量,因此x\boldsymbol {x}x是变量,而x0\boldsymbol {x}_0x0只是一个常量;所以就相当于后面的一个偏导用x\boldsymbol xx来近似了前面一个偏导的x0\boldsymbol {x}_0x0。从而当此次非线性优化的过程中,如果状态变量x\boldsymbol xx离先验状态x0\boldsymbol {x}_0x0发生了x−x0\boldsymbol x - \boldsymbol {x}_0x−x0的变化,那么边缘化的残差e\boldsymbol ee应该产生的增量就是使用一阶泰勒展开,为J(x−x0)\boldsymbol J (\boldsymbol x - \boldsymbol{x}_0)J(x−x0)。那么总的边缘化残差就是上次边缘化的时候的残差e0\boldsymbol e_0e0加上增量,即e=e0+J(x−x0)\boldsymbol e = \boldsymbol {e}_0 + \boldsymbol J (\boldsymbol x - \boldsymbol{x}_0)e=e0+J(x−x0)。这其实就是 FEJ(First Estimated Jacobian)。
(2)再来思考,上次边缘化的残差e0\boldsymbol e_0e0代表什么意义呢?
可以这么想,每一次的优化结果都是一个最小二乘结果,也就是每一个状态变量都非常接近真实值,但又都不是真实值。因为如果一旦迁就了某个状态变量让它变成真实值,那么其他状态变量就会更加的偏离真实值,最后造成所有状态变量偏离真实值的误差平方和更大了。所以说这个上次边缘化的残差e0\boldsymbol e_0e0就是代表上次边缘化给出的先验状态因子x0\boldsymbol {x}_0x0离真实状态的误差,这是由于最小二乘造成的,是为了兼顾总的误差最小而导致每个状态变量都有一个误差。
3.再回到我们的问题,为什么要把残差的index统一到0?
其实就是因为现在我们的先验状态因子只有对上次边缘化保留下来的状态的先验因子,而我们的keep_block_idx存储的是上次边缘化开始之前,包含被边缘化的参数块和保留下来的参数块的所有参数块的内存索引排序。以上图为例,之前我们推导排序结果如下:
| parameter_block_idx中保留下的参数块的索引 |
|---|
| m = 18 (6+9+1+1+1),要边缘化掉的参数的维度 |
| parameter_block_idx(&T1T_1T1, 18), localPose = 6 |
| parameter_block_idx(&B1B_1B1, 24), localPose = 9 |
| parameter_block_idx(&T3T_3T3, 33), localPose = 6 |
| parameter_block_idx(&T2T_2T2, 39), localPose = 6 |
| parameter_block_idx(&T4T_4T4, 45), localPose = 6 |
| parameter_block_idx(&TicT_{ic}Tic, 51), localPose = 6 |
| n = 57 - 18 = 39 保留下的参数的维度 |
也就是上次边缘化中,我们保留下的参数块只有39个维度,也就是我们的残差是39维度,并且在边缘化中的状态向量XXX中的内存索引是从18—56(注意最后一个索引是56,总数是57)。
而此次非线性优化在内存中存储上次边缘化保留下来的状态变量到Eigen::VectorXd的时候,我们应该是从0—38存储,所以说我们要把边缘化掉的那些参数块的索引偏移减掉。
4.另外注意,在边缘化的误差中,我们的状态变量的排列顺序有影响吗?
比如上面边缘化我们对保留下来的状态变量的排列顺序是T1,B1,T3,T2,T4,TicT_1, B_1, T_3, T_2, T_4, T_{ic}T1,B1,T3,T2,T4,Tic,而一般我们在非线性优化中对状态变量应该都是按照关键帧的顺序进行顺序排列的,也就是应该是T1,B1,T2,T3,T4,TicT_1, B_1, T_2, T_3, T_4, T_{ic}T1,B1,T2,T3,T4,Tic,即边缘化中我们把保留下来的状态变量中有些顺序颠倒了,这在本次的非线性优化中有影响吗?即这样是否会造成我们本次非线性优化对状态变量计算的残差和雅克比位置不对应?
其实是没有影响的, 因为我们传入参数块(状态变量)的时候传入的是它们的地址,这也就保证了本次非线性优化拿到的某个参数块和我们保留的边缘化之前的某个参数块一定是对应的,这个对应关系是由keep_block_data和last_marginalization_parameter_blocks的顺序是一一对应而决定的。因此只要参数块的内存地址是正确的,那我们本次优化计算的边缘化因子的残差就和参数块是对应的,从而这两块参数在最后本次非线性优化的整个HHH矩阵中的位置就可以正确的找到,因为ceres就是通过参数块的内存地址来构造HHH矩阵。
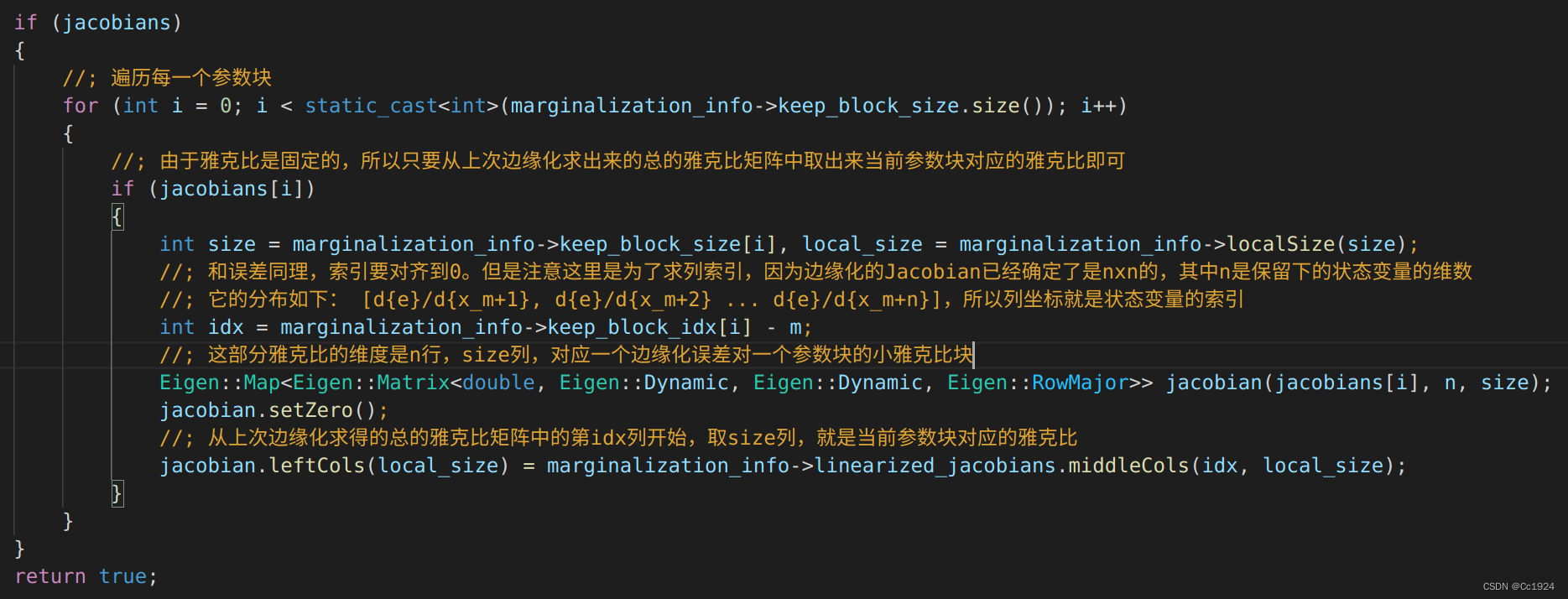
5.2.2. 雅克比计算方式
其实前面就用FEJ来解释过了,在本次的非线性优化过程中,认为x\boldsymbol xx离我边缘化得到的先验x0\boldsymbol {x}_0x0不会太远,因此使用上次边缘化的时候误差对x0\boldsymbol {x}_0x0的雅克比近似本次非线性优化过程中的雅克比即可。
但是要注意的是,程序中的索引对齐是为了得到边缘化的雅克比矩阵中对当前参数块的偏导。因为边缘化的雅克比维度是n×nn \times nn×n,其中行数就是和残差的维度对应的,而残差的维度就是保留下来的状态变量的维度。而列数是和求导的状态变量的维度对应的,其实也是保留下来的状态变量的维度。以上面的例子为例,边缘化的雅克比形式如下:
J=[∂e∂T1∣∂e∂B1∣∂e∂T3∣∂e∂T2∣∂e∂T4∣∂e∂Tic]\boldsymbol J = \left[ \begin{matrix} \frac{\partial {\boldsymbol e}}{\partial {\boldsymbol {T}_1}} \quad | \quad \frac{\partial {\boldsymbol e}}{\partial {\boldsymbol {B}_1}} \quad | \quad \frac{\partial {\boldsymbol e}}{\partial {\boldsymbol {T}_3}} \quad | \quad \frac{\partial {\boldsymbol e}}{\partial {\boldsymbol {T}_2}} \quad | \quad \frac{\partial {\boldsymbol e}}{\partial {\boldsymbol {T}_4}} \quad | \quad \frac{\partial {\boldsymbol e}}{\partial {\boldsymbol {T}_{ic}}} \end{matrix} \right] J=[∂T1∂e∣∂B1∂e∣∂T3∂e∣∂T2∂e∣∂T4∂e∣∂Tic∂e]
所以为了得到对某一个参数块的雅克比,需要在列上寻找对应的索引。
代码如下: