现代循环神经网络:长短期记忆网络(LSTM),并使用LSTM进行股票的预测
专栏:神经网络复现目录
长短期记忆神经网络
长短期记忆网络(Long Short-Term Memory, LSTM)是一种特殊的循环神经网络(RNN)结构,用于处理序列数据,如语音识别、自然语言处理、视频分析等任务。LSTM网络的主要目的是解决传统RNN在训练过程中遇到的梯度消失和梯度爆炸问题,从而更好地捕捉序列数据中的长期依赖关系。
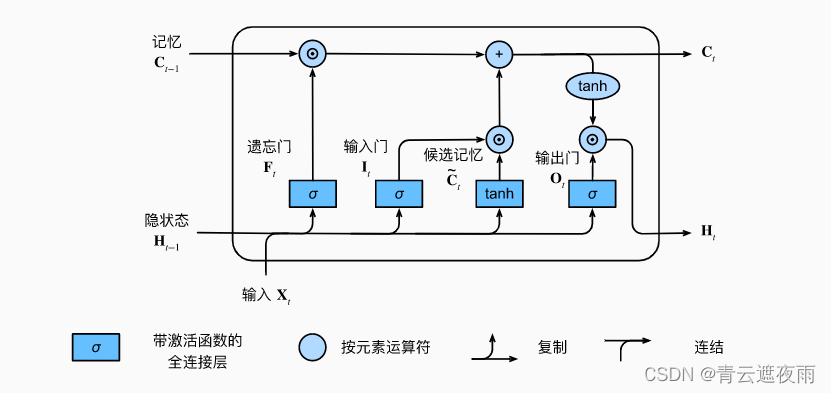
LSTM网络引入了一种记忆单元(memory cell),用于存储和更新序列中的信息,并引入了三个门(gate)控制记忆单元中的信息流动:输入门(input gate)、遗忘门(forget gate)和输出门(output gate)。输入门控制新输入的流入,遗忘门控制历史信息的遗忘,输出门控制记忆单元中的信息输出。三个门的开关状态由sigmoid函数控制,从而可以自适应地控制信息流动。
通过引入记忆单元和门结构,LSTM网络可以更好地处理长序列数据,并在一定程度上缓解了梯度消失和梯度爆炸问题。在实际应用中,LSTM网络被广泛应用于语音识别、机器翻译、图像描述、文本分类等领域,取得了显著的效果。
文章目录
- 长短期记忆神经网络
- 门控记忆元
- 输入门、输出门和遗忘门
- 候选记忆元
- 记忆元
- 隐状态
- 总结
- 从零开始实现
- 初始化模型参数
- 定义模型
- 实战:股票预测
- 数据集处理
- 读取数据集
- 绘制图像
- 选择特征
- 缺失值处理
- 数据缩放
- 数据集的建立
- 建立LSTM模型
- 训练
- 预测效果图
门控记忆元
输入门、输出门和遗忘门
就如在门控循环单元中一样, 当前时间步的输入和前一个时间步的隐状态 作为数据送入长短期记忆网络的门中。 它们由三个具有sigmoid激活函数的全连接层处理, 以计算输入门、遗忘门和输出门的值。 因此,这三个门的值都在(0,1)(0,1)(0,1)的范围内。
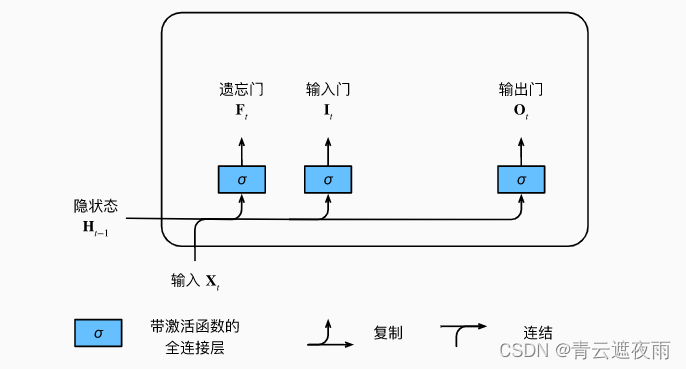
输入门(input gate)用于控制新输入的流入和更新记忆单元(memory cell)中的信息。输入门允许LSTM网络控制新输入的流入,以及选择性地更新记忆单元中的信息,从而更好地捕捉序列数据中的长期依赖关系。
遗忘门(forget gate)用于控制历史信息的遗忘和更新记忆单元(memory cell)中的信息。遗忘门允许LSTM网络选择性地遗忘历史信息,以及更新记忆单元中的信息。这种机制能够更好地捕捉序列数据中的长期依赖关系,并缓解梯度消失和梯度爆炸问题。
输出门(output gate)用于控制记忆单元(memory cell)中的信息输出。输出门允许LSTM网络控制记忆单元中的信息输出,从而更好地捕捉序列数据中的长期依赖关系,并提高模型的预测精度。
公式为:
It=σ(XtWxi+Ht−1Whi+bi)Ft=σ(XtWxf+Ht−1Whf+bf)Ot=σ(XtWxo+Ht−1Who+bo)I_t=\sigma(X_tW_{xi}+H_{t-1}W_{hi}+b_i) \\ F_t=\sigma(X_tW_{xf}+H_{t-1}W_{hf}+b_f) \\ O_t=\sigma(X_tW_{xo}+H_{t-1}W_{ho}+b_o) \\ It=σ(XtWxi+Ht−1Whi+bi)Ft=σ(XtWxf+Ht−1Whf+bf)Ot=σ(XtWxo+Ht−1Who+bo)
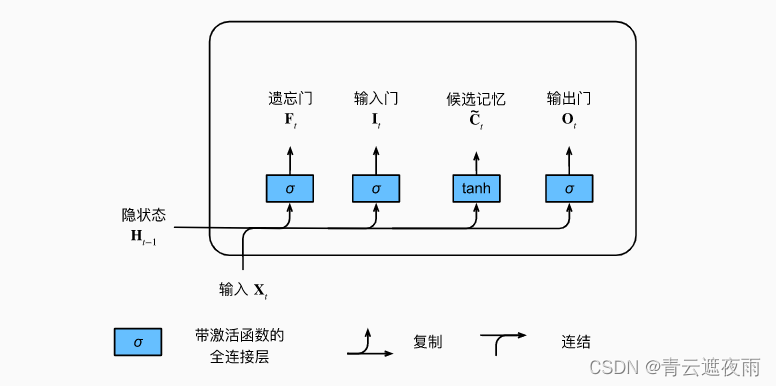
候选记忆元
它的计算与上面描述的三个门的计算类似, 但是使用函数 tanh\tanhtanh 作为激活函数,函数的值范围为(−1,1)(-1,1)(−1,1)。 下面导出在时间步ttt处的方程:
Ct~=tanh(XtWxc+Ht−1Whc+bc)\tilde{C_t}=\tanh(X_tW_{xc}+H_{t-1}W_{hc}+b_c) Ct~=tanh(XtWxc+Ht−1Whc+bc)
候选记忆元的如图所示。
记忆元
在门控循环单元中,有一种机制来控制输入和遗忘(或跳过)。 类似地,在长短期记忆网络中,也有两个门用于这样的目的: 输入门ItI_tIt控制采用多少来自的新数据, 而遗忘门FtF_tFt控制保留多少过去的记忆元Ct−1C_{t-1}Ct−1的内容。 使用按元素乘法,得出:
Ct=Ft⊙Ct−1+It⊙Ct~C_t=F_t\odot C_{t-1}+I_t\odot \tilde{C_t} Ct=Ft⊙Ct−1+It⊙Ct~
如果遗忘门始终为且输入门始终为0, 则过去的记忆元Ct−1C_{t-1}Ct−1将随时间被保存并传递到当前时间步。 引入这种设计是为了缓解梯度消失问题, 并更好地捕获序列中的长距离依赖关系。
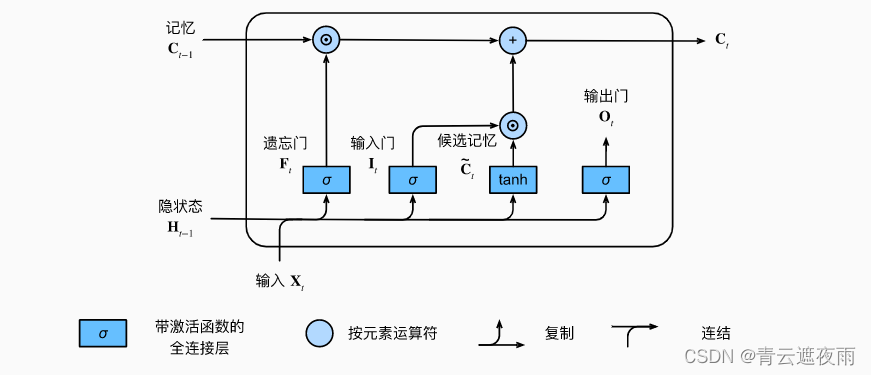
隐状态
在长短期记忆网络中,它仅仅是记忆元的的tanh\tanhtanh门控版本。 这就确保了HtH_tHt的值始终在区间(−1,1)(-1,1)(−1,1)内:
Ht=Ot⊙tanh(Ct)H_t=O_t\odot \tanh(C_t)Ht=Ot⊙tanh(Ct)
只要输出门接近1,我们就能够有效地将所有记忆信息传递给预测部分, 而对于输出门接近,我们只保留记忆元内的所有信息,而不需要更新隐状态。
总结
It=σ(XtWxi+Ht−1Whi+bi)Ft=σ(XtWxf+Ht−1Whf+bf)Ot=σ(XtWxo+Ht−1Who+bo)Ct~=tanh(XtWxc+Ht−1Whc+bc)Ct=Ft⊙Ct−1+It⊙Ct~Ht=Ot⊙tanh(Ct)I_t=\sigma(X_tW_{xi}+H_{t-1}W_{hi}+b_i) \\ F_t=\sigma(X_tW_{xf}+H_{t-1}W_{hf}+b_f) \\ O_t=\sigma(X_tW_{xo}+H_{t-1}W_{ho}+b_o) \\ \tilde{C_t}=\tanh(X_tW_{xc}+H_{t-1}W_{hc}+b_c)\\ C_t=F_t\odot C_{t-1}+I_t\odot \tilde{C_t} \\ H_t=O_t\odot \tanh(C_t) It=σ(XtWxi+Ht−1Whi+bi)Ft=σ(XtWxf+Ht−1Whf+bf)Ot=σ(XtWxo+Ht−1Who+bo)Ct~=tanh(XtWxc+Ht−1Whc+bc)Ct=Ft⊙Ct−1+It⊙Ct~Ht=Ot⊙tanh(Ct)
从零开始实现
初始化模型参数
def get_lstm_params(vocab_size, num_hiddens, device):num_inputs = num_outputs = vocab_sizedef normal(shape):return torch.randn(size=shape, device=device)*0.01def three():return (normal((num_inputs, num_hiddens)),normal((num_hiddens, num_hiddens)),torch.zeros(num_hiddens, device=device))W_xi, W_hi, b_i = three() # 输入门参数W_xf, W_hf, b_f = three() # 遗忘门参数W_xo, W_ho, b_o = three() # 输出门参数W_xc, W_hc, b_c = three() # 候选记忆元参数# 输出层参数W_hq = normal((num_hiddens, num_outputs))b_q = torch.zeros(num_outputs, device=device)# 附加梯度params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc,b_c, W_hq, b_q]for param in params:param.requires_grad_(True)return params
定义模型
def init_lstm_state(batch_size, num_hiddens, device):return (torch.zeros((batch_size, num_hiddens), device=device),torch.zeros((batch_size, num_hiddens), device=device))
def lstm(inputs, state, params):[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,W_hq, b_q] = params(H, C) = stateoutputs = []for X in inputs:I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)C = F * C + I * C_tildaH = O * torch.tanh(C)Y = (H @ W_hq) + b_qoutputs.append(Y)return torch.cat(outputs, dim=0), (H, C)
class RNNModelScratch: #@savedef __init__(self, vocab_size, num_hiddens, device,get_params, init_state, forward_fn):self.vocab_size, self.num_hiddens = vocab_size, num_hiddensself.params = get_params(vocab_size, num_hiddens, device)self.init_state, self.forward_fn = init_state, forward_fndef __call__(self, X, state):X = F.one_hot(X.T, self.vocab_size).type(torch.float32)return self.forward_fn(X, state, self.params)def begin_state(self, batch_size, device):return self.init_state(batch_size, self.num_hiddens, device)实战:股票预测
数据集处理
数据集来源:https://link.zhihu.com/?target=https%3A//github.com/yhannahwang/stock_prediction
读取数据集
df_aaxj = pd.read_csv("data/ETFs/aaxj.us.txt", index_col=0)
df_aaxj
绘制图像
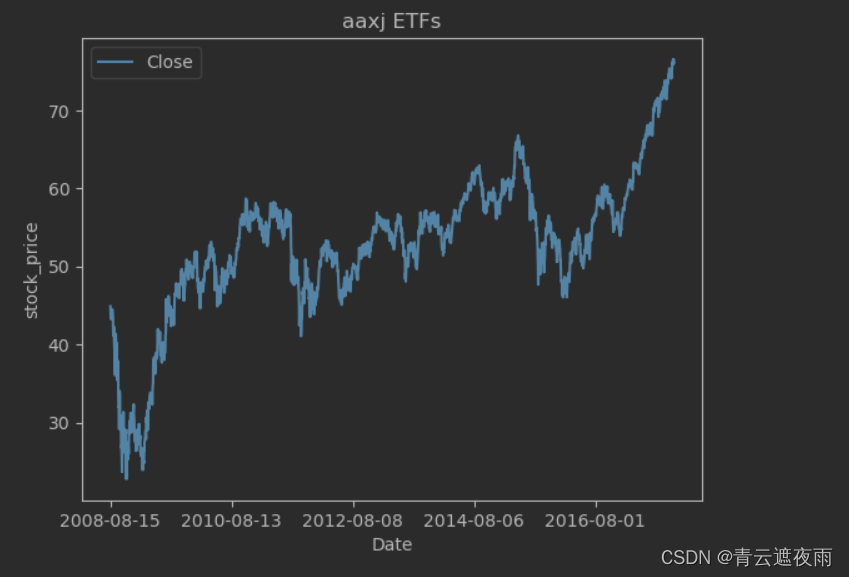
# 绘制收盘价格走势图
df_aaxj[['Close']].plot()
plt.ylabel("stock_price")
plt.title("aaxj ETFs")
plt.show()
选择特征
df_main=df_aaxj
# 筛选四个变量,作为数据的输入特征
sel_col = ['Open', 'High', 'Low', 'Close']
df_main = df_main[sel_col]
df_main.head()
缺失值处理
# 查看是否有缺失值
np.sum(df_main.isnull())
# 缺失值填充
df_main = df_main.fillna(method='ffill') # 缺失值填充,使用上一个有效值
np.sum(df_main.isnull())
数据缩放
# 数据缩放
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(-1, 1))
for col in sel_col: # 这里不能进行统一进行缩放,因为fit_transform返回值是numpy类型df_main[col] = scaler.fit_transform(df_main[col].values.reshape(-1,1))
这段代码的功能是将数据进行缩放处理,使用了 scikit-learn 库中的 MinMaxScaler 类。MinMaxScaler 可以将数据缩放到指定的范围内,这里指定为特征值范围为[-1, 1]。
代码使用 for 循环逐个对每个需要缩放的列进行处理。对于每个列,将该列的数据转换为 numpy 数组,并对其应用 MinMaxScaler 进行缩放。
注意,由于 fit_transform 方法返回的是 numpy 类型的数据,因此必须将结果重新赋值回原始数据框的对应列。
总体来说,这段代码的作用是将指定数据框中的指定列进行缩放,使得它们的值域范围被映射到 [-1, 1] 区间内。这种缩放操作有助于提高模型的训练效果,尤其是当不同特征值的取值范围差异较大时。
# 将下一日的收盘价作为本日的标签
df_main['target'] = df_main['Close'].shift(-1)
df_main.head()
df_main.dropna() # 使用了shift函数,在最后必然是有缺失值的,这里去掉缺失值所在行
df_main = df_main.astype(np.float32) # 修改数据类型
这段代码的意思是将 df_main 数据框中的 “Close” 列进行向下平移(shift)1 个单位,并将结果存储在新列 “target” 中。这里假设 “Close” 列是某个时间序列上的收盘价数据,而 “target” 列则是在 “Close” 数据上进行向下平移后的下一个时间点的收盘价。
具体地,使用 .shift(-1) 方法可以将数据框的所有行中 “Close” 列的值都向下平移 1 个单位。这样,新的 “target” 列中就包含了每个时间点上 “Close” 列下一个时间点的收盘价数据。需要注意的是,由于最后一行没有下一个时间点的数据,因此在进行平移时,最后一行的 “target” 列值会变成 NaN(缺失值)。 所以需要dropna处理缺失值
数据集的建立
# 创建两个列表,用来存储数据的特征和标签
data_feat, data_target = [],[]# 设每条数据序列有20组数据
seq = 20for index in range(len(df_main) - seq):# 构建特征集data_feat.append(df_main[['Open', 'High', 'Low', 'Close']][index: index + seq].values)# 构建target集data_target.append(df_main['target'][index:index + seq])# 将特征集和标签集整理成numpy数组
data_feat = np.array(data_feat)
data_target = np.array(data_target)
# 这里按照8:2的比例划分训练集和测试集
test_set_size = int(np.round(0.2*df_main.shape[0])) # np.round(1)是四舍五入,
train_size = data_feat.shape[0] - (test_set_size)
print(test_set_size) # 输出测试集大小
print(train_size) # 输出训练集大小
trainX = torch.from_numpy(data_feat[:train_size].reshape(-1,seq,4)).type(torch.Tensor)
# 这里第一个维度自动确定,我们认为其为batch_size,因为在LSTM类的定义中,设置了batch_first=True
testX = torch.from_numpy(data_feat[train_size:].reshape(-1,seq,4)).type(torch.Tensor)
trainY = torch.from_numpy(data_target[:train_size].reshape(-1,seq,1)).type(torch.Tensor)
testY = torch.from_numpy(data_target[train_size:].reshape(-1,seq,1)).type(torch.Tensor)
batch_size=1840
train = torch.utils.data.TensorDataset(trainX,trainY)
test = torch.utils.data.TensorDataset(testX,testY)
train_loader = torch.utils.data.DataLoader(dataset=train,batch_size=batch_size,shuffle=False)test_loader = torch.utils.data.DataLoader(dataset=test,batch_size=batch_size,shuffle=False)
建立LSTM模型
import torch.nn as nn
import torch
input_dim = 4 # 数据的特征数
hidden_dim = 32 # 隐藏层的神经元个数
num_layers = 2 # LSTM的层数
output_dim = 1 # 预测值的特征数#(这是预测股票价格,所以这里特征数是1,如果预测一个单词,那么这里是one-hot向量的编码长度)
class LSTM(nn.Module):def __init__(self, input_dim, hidden_dim, num_layers, output_dim):super(LSTM, self).__init__()# Hidden dimensionsself.hidden_dim = hidden_dim# Number of hidden layersself.num_layers = num_layers# Building your LSTM# batch_first=True causes input/output tensors to be of shape (batch_dim, seq_dim, feature_dim)self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)# Readout layer 在LSTM后再加一个全连接层,因为是回归问题,所以不能在线性层后加激活函数self.fc = nn.Linear(hidden_dim, output_dim)def forward(self, x):# Initialize hidden state with zerosh0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).requires_grad_()# 这里x.size(0)就是batch_size# Initialize cell statec0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).requires_grad_()# One time step# We need to detach as we are doing truncated backpropagation through time (BPTT)# If we don't, we'll backprop all the way to the start even after going through another batchout, (hn, cn) = self.lstm(x, (h0.detach(), c0.detach()))out = self.fc(out)return out
训练
# 实例化模型
model = LSTM(input_dim=input_dim, hidden_dim=hidden_dim, output_dim=output_dim, num_layers=num_layers)# 定义优化器和损失函数
optimiser = torch.optim.Adam(model.parameters(), lr=0.01) # 使用Adam优化算法
loss_fn = torch.nn.MSELoss(size_average=True) # 使用均方差作为损失函数# 设定数据遍历次数
num_epochs = 100# 打印模型结构
print(model)

# train model
hist = np.zeros(num_epochs)
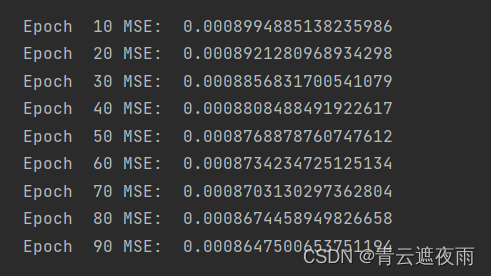
for t in range(num_epochs):# Initialise hidden state# Don't do this if you want your LSTM to be stateful# model.hidden = model.init_hidden()# Forward passy_train_pred = model(trainX)loss = loss_fn(y_train_pred, trainY)if t % 10 == 0 and t !=0: # 每训练十次,打印一次均方差print("Epoch ", t, "MSE: ", loss.item())hist[t] = loss.item()# Zero out gradient, else they will accumulate between epochs 将梯度归零optimiser.zero_grad()# Backward passloss.backward()# Update parametersoptimiser.step()
预测效果图
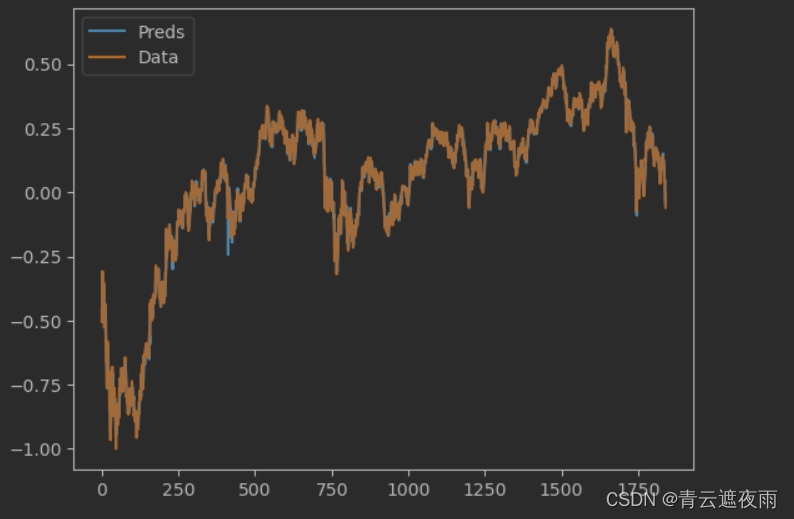
pred_value = y_train_pred.detach().numpy()[:,-1,0]
true_value = trainY.detach().numpy()[:,-1,0]plt.plot(pred_value, label="Preds") # 预测值
plt.plot(true_value, label="Data") # 真实值
plt.legend()
plt.show()