
如何在VS中解决查看中文乱码问题。
1 现象 1
我们在调试的过程中,总是会遇到中文字符串。但是你用vs自带的工具去看总是乱码,但有的时候又是正常,完全摸不着头脑。
比如,看如下代码:
int main()
{// 乱码const char *chinese = "白";// 正常显示const wchar_t *t1 = L"白";// 会显示什么?const char *t2 = "}v";short ab = 0x767d;int abc = 0x5c45767d;int test = 39142;std::cout << "Hello World!\n";
}我们打开vs的内存窗口,看下实际上在内存中是什么。



在上面我们提到,chinese是会乱码的。但是t1,t2似乎也是乱码的。但是它们的数据怎么是一样的。很是奇怪啊。
t1 = L"白",而t2 = "}v"。这明显就是不一样啊。
我们在看:
在vs的内存窗口中右键菜单,弹出一个对话框。选择unicode text,在看右边显示了一个大大的“白”字。
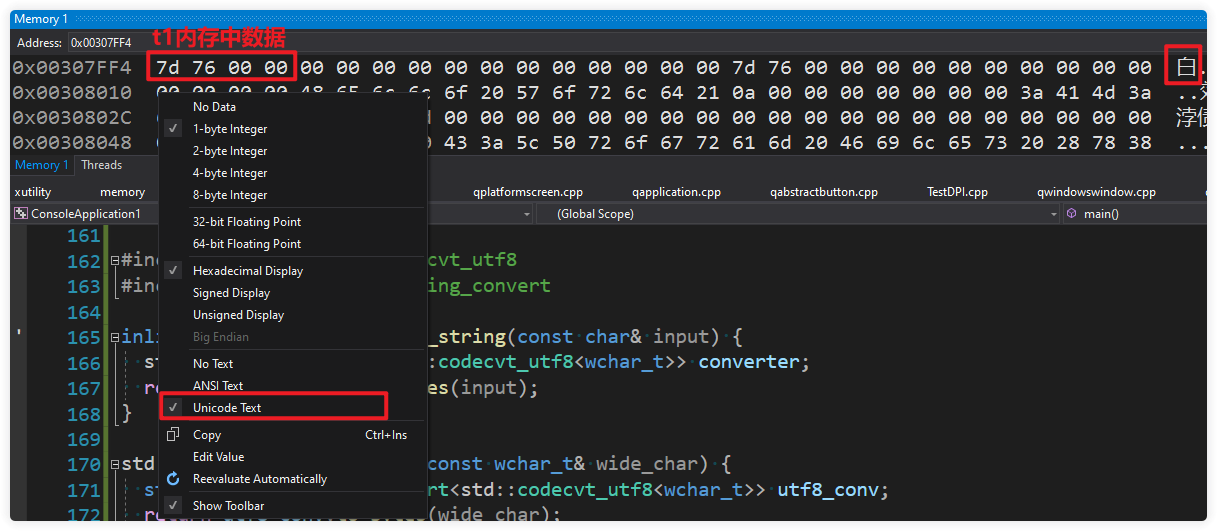
我们再看t2如此的操作,居然也是‘白“字。

*这里引入第一个结论:对内存中的数据如何解释,是至关重要的。 char 中保存的数据也可以解析为中文。
2 现象2
在与服务器在进行通信的时候,字段char *类型的。你运用如上的方法去查看,但还是乱码的,你将内存的数据保存到文本又不是乱码的。
真是个奇怪的问题。
3 原理解释
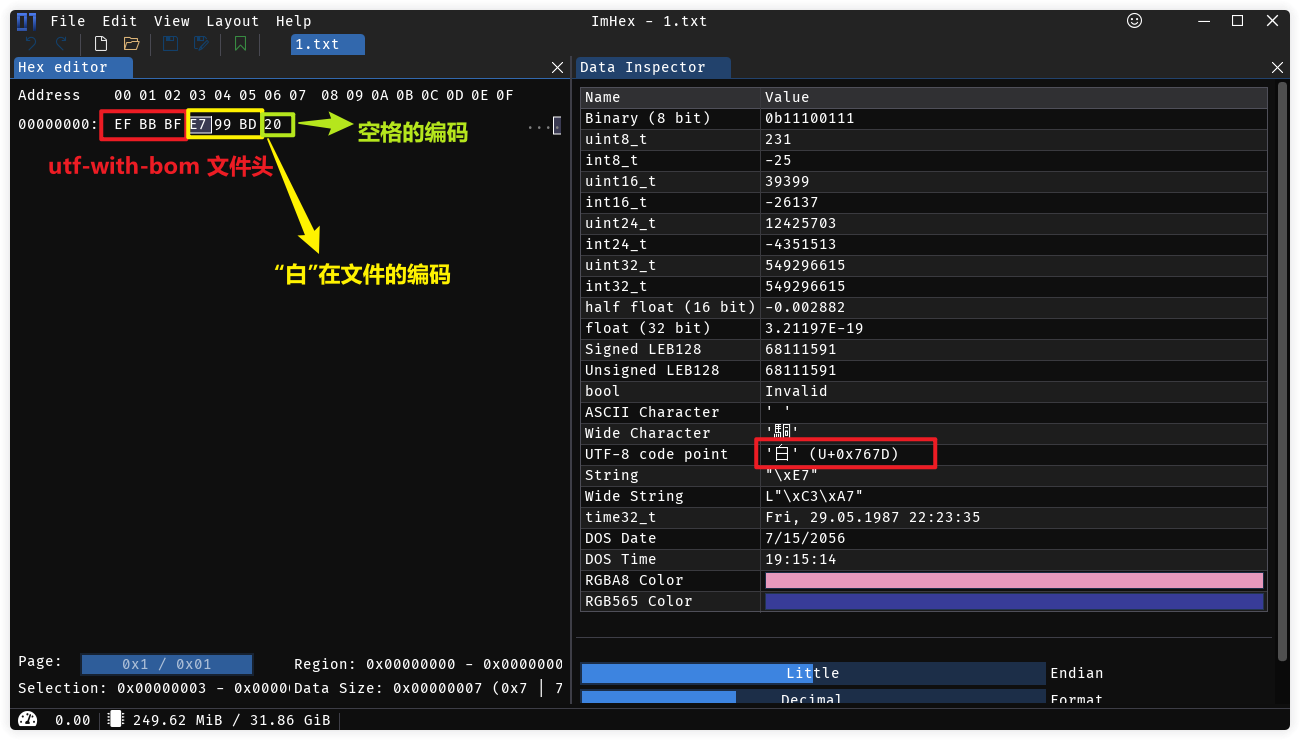
我们打开一个文本文件,在里面写入”白“,再加上一个空格(不加空格imhex可能识别不出来),看下里面到底保存的是什么东西.
用一个二进制工具打开,比如我用的imhex,源码是开放的,在github上.
”白“在文件的编码是:E7 99 BD,在看右侧utf-8 code point 0x767D这个数值和我们在内存的是一致的。
E7 99 BD又是什么呢?
我们打开一个网址:https://unicode-table.com/
1、在搜索框里里面输入”白“,回车

2、选中红色框中内容,看到这里也有个U+767D

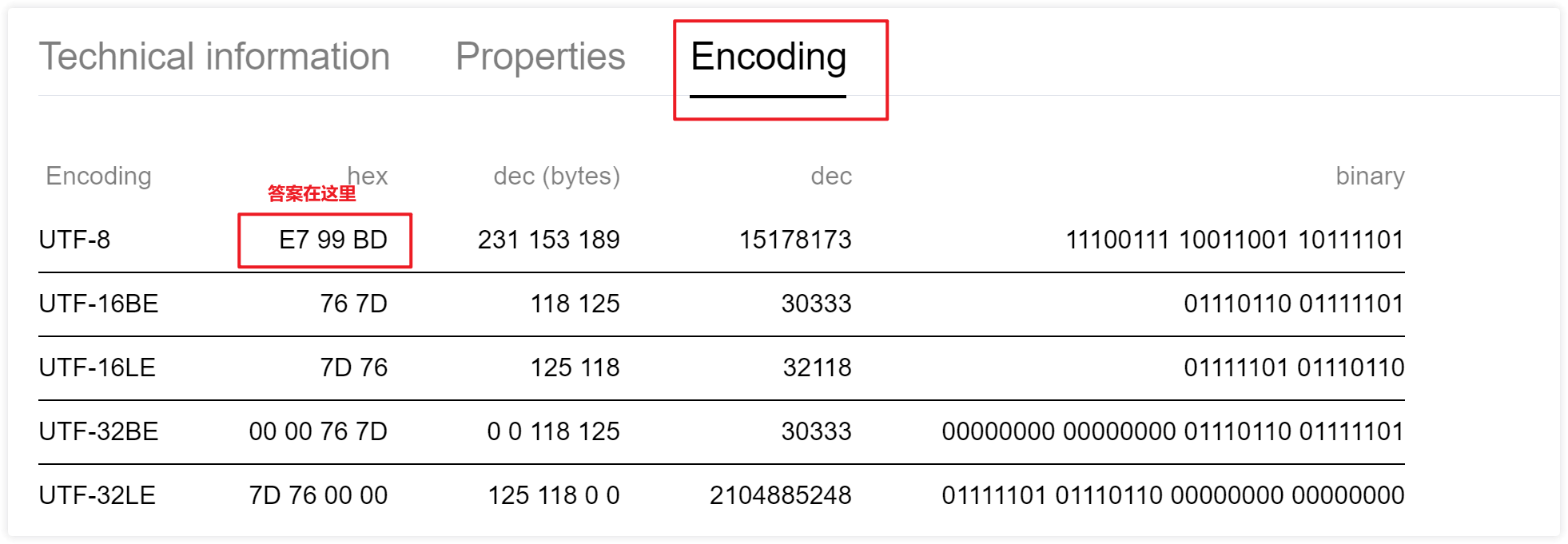
3、我们终于知道这个叫做什么了。原来叫做Unicode number。我猜测类似索引的含义

4、答案在这里,看到了没有。原来这就是实际的编码。
哈哈,终于见到庐山真面目了。E7 99 BD是实际的编码,而U+767D就是索引而已。
4、回顾总结
就是说在内存中保存的数据可能是unicode表索引,也可能是unicode 编码,在使用vs工具查看的时候只能当作索引来处理。
如果保存的是索引,vs工具自然就可以识别(选择unicode text)。如果是unicode编码vs工具自然就是乱码了。
但是保存到文件中必须就是unicode编码,否则就是乱码。
我在啰嗦几句:
**什么是unicode索引:**你可以想象成有一个一维数组array,比如索引为1,那么在内存中保存的就是1
**编码:**就是上面的array索引对应的值,比如:array[1]
再重复一遍上面的话,内存中可能包含了unicode表索引,也可能是unicode 编码,所以对数据的解释不对,就形成了乱码。
你要是问我GBK编码的怎么办,我建议你换成utf8可能更合适。
上一篇:【springboot】文件上传
下一篇:uniapp开发app总结