
有监督,无监督,半监督,弱监督学习
0.概述
什么是有监督学习、无监督学习、弱监督学习、半监督学习、强化学习?
随着机器学习问题不断深入人心,人们也将现实中遇到不同的问题分为不同的学习方式,其中,最基础的应属监督学习,无监督学习和强化学习了。
1.有监督学习(supervised learning)
已知数据和其对应的标签,训练一个学习模型或算法,将输入数据映射到标签的过程。监督学习是最常见的学习问题之一,就是人们口中常说的分类问题。比如已知一些图片是猫或狗,一些图片不是相应的类别,那么训练一个算法,当一个新的图片输入算法或模型的时候,能够告诉我们这张图片是猫还是狗。
2.无监督学习(unsupervised learning)
已知数据不知道任何标签,按照一定的偏好,训练一个智能算法,将所有的数据映射到多个不同标签的过程。相对于有监督学习,无监督学习是一类比较困难的问题,所谓的按照一定的偏好,是比如特征空间距离最近,等人们认为属于一类的事物应具有的一些特点。
无监督学习典型如常见的十种聚类算法,K-means,DBSCAN,GMM等。
3.半监督学习(semi supervised learning)
已知数据和部分数据一一对应的标签,有一部分数据的标签未知,训练一个智能算法,学习已知标签和未知标签的数据,将输入数据映射到标签的过程。半监督通常是一个数据的标注非常困难,比如说医院的检查结果,医生也需要一段时间来判断健康与否,可能只有几组数据知道是健康还是非健康,其他的只有数据不知道是不是健康。那么通过有监督学习和无监督的结合的半监督学习就在这里发挥作用了。
机器学习中常见的就是S3VM模型,在深度学习中,利用数据分布上的模型假设建立一个学习模型对未标签的数据样例进行打标签。通常是两个阶段的训练,先用较小的有标签数据训练一个teacher模型,再用这个模型对(较大规模的)无标签数据逐个预测伪标签,作为Student模型的训练数据。
4.自监督学习(semi supervised learning)
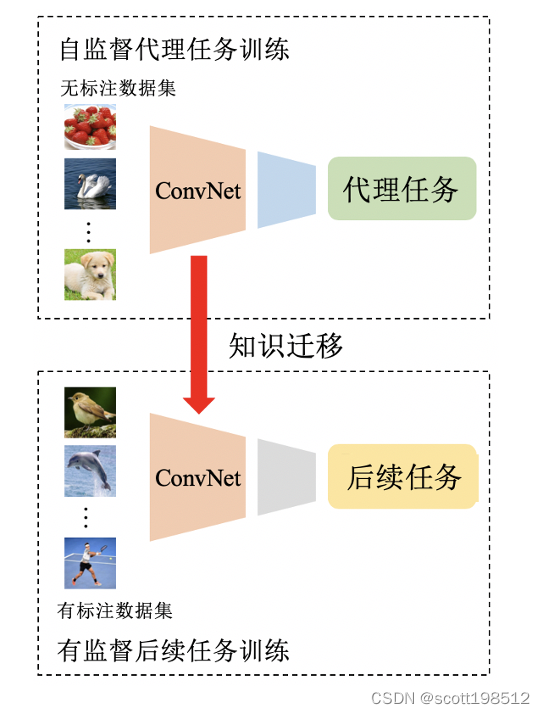
自监督学习的总体流程如图1所示。在自监督训练阶段,首先设计一个预定义的代理任务,该代理任务的伪标签是基于数据的某些属性自动生成的。 然后,对ConvNet进行训练,学习代理任务的目标函数,解决该任务。 在自监督的训练完成之后,将学习到的视觉特征作为预训练模型进一步迁移到后续任务(尤其是当只有相对较小的数据时),以提高性能并克服过拟合的情况。 通常,浅层捕获一般的低级特征,例如边缘,拐角和纹理,而深层捕获与任务相关的高级特征。 因此,在有监督的后续任务训练阶段,仅转移前几层的视觉特征。
自监督的数据来源于其本身,其实就是自己生成一些简单的标签,然后去学习,理论上网络模型可以学习到图像的一些特征信息,然后在这个模型的基础上添加其他任务。
a) 图像数据中分割后的各个区域打乱,然后将它还原为原始图片,类似于拼图游戏。
b) 将图片中某些区域挖空,然后让模型进行预测,使输出的结果尽可能还原输入的图片,类似壁画图像修复。
c) 将图像旋转一定的角度,让模型预测其旋转了多少度,或者将图片旋转0°,90°,180°,270°等四种类别,让模型预测对应的旋转类别。
5.弱监督学习(weakly supervised learning)
已知数据和其对应的弱标签,训练一个智能算法,将输入数据映射到一组更强的标签的过程。标签的强弱指的是标签蕴含的信息量的多少,比如相对于分割的标签来说,分类的标签就是弱标签,如果我们知道一幅图,告诉你图上有一只狗,然后需要你把狗在哪里,狗和背景的分界在哪里找出来,那么这就是一个已知弱标签,去学习强标签的弱监督学习问题。
6.强化学习(reinforcement learning)
智能算法在没有人为指导的情况下,通过不断的试错来提升任务性能的过程。“试错”的意思是还是有一个衡量标准,用棋类游戏举例,我们并不知道棋手下一步棋是对是错,不知道哪步棋是制胜的关键,但是我们知道结果是输还是赢,如果算法这样走最后的结果是胜利,那么算法就学习记忆,如果按照那样走最后输了,那么算法就学习以后不这样走。强化学习典型就是通过试错,给出一个相应的“reward”来训练试错的过程,不断的反馈校正,得到最大的“reward”结果。