
Kubernetes学习(七)弹性伸缩
Kubernetes中弹性伸缩存在的问题
从传统意义上,弹性伸缩主要解决的问题是容量规划与实际负载的矛盾。
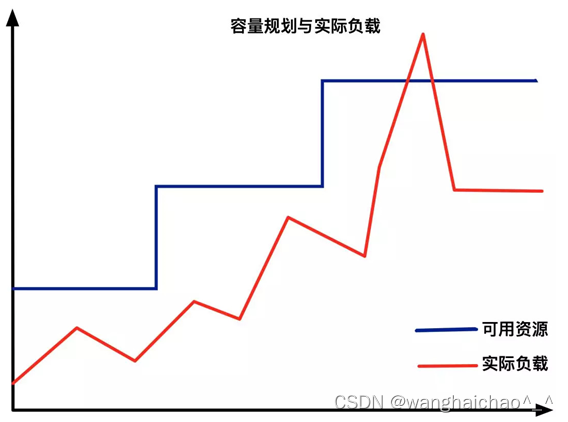
蓝色水位线表示集群资源容量随着负载的增加不断扩容,红色曲线表示集群资源实际负载变化。
弹性伸缩就是要解决当实际负载增大,而集群资源容量没来得及反应的问题。
常规的做法是给集群资源预留保障集群可用,通常20%左右。这种方式看似没什么问题,但放到Kubernetes中,就会发现如下2个问题:
1、机器规格不统一造成机器利用率百分比碎片化
在一个Kubernetes集群中,通常不只包含一种规格的机器,假设集群中存在4C8G与16C32G两种规格的机器,对于10%的资源预留,这两种规格代表的意义是完全不同的。
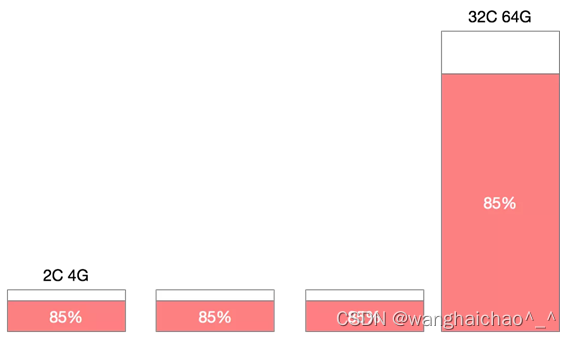
特别是在缩容的场景下,为了保证缩容后集群稳定性,我们一般会一个节点一个节点从集群中摘除,那么如何判断节点是否可以摘除其利用率百分比就是重要的指标。此时如果大规格机器有较低的利用率被判断缩容,那么很有可能会造成节点缩容后,容器重新调度后的争抢。如果优先缩容小规格机器,则可能造成缩容后资源的大量冗余。
2、机器利用率不单纯依靠宿主机计算
在大部分生产环境中,资源利用率都不会保持一个高的水位,但从调度来讲,调度应该保持一个比较高的水位,这样才能保障集群稳定性,又不过多浪费资源。
弹性伸缩概念的延伸
不是所有的业务都存在峰值流量,越来越细分的业务形态带来更多成本节省和可用性之间的跳转。
- 在线负载型:微服务、网站、API
- 离线任务型:离线计算、机器学习
- 定时任务型:定时批量计算
不同类型的负载对于弹性伸缩的要求有所不同,在线负载对弹出时间敏感,离线任务对价格敏感,定时任务对调度敏感。
kubernetes 弹性伸缩布局
在 Kubernetes 的生态中,在多个维度、多个层次提供了不同的组件来满足不同的伸缩场景。
有三种弹性伸缩:
- CA(Cluster Autoscaler):Node级别自动扩/缩容,cluster-autoscaler组件
- HPA(Horizontal Pod Autoscaler):Pod个数自动扩/缩容
- VPA(Vertical Pod Autoscaler):Pod配置自动扩/缩容,主要是CPU、内存,addon-resizer组件
如果在云上建议 HPA 结合 cluster-autoscaler 的方式进行集群的弹性伸缩管理。
Node 自动扩容/缩容
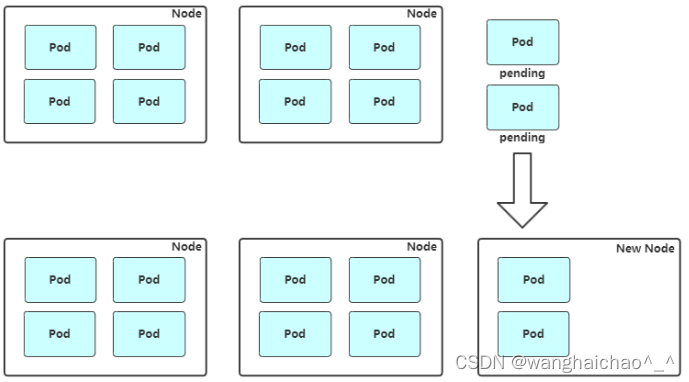
扩容:Cluster AutoScaler 定期检测是否有充足的资源来调度新创建的 Pod,当资源不足时会调用 Cloud Provider 创建新的 Node。
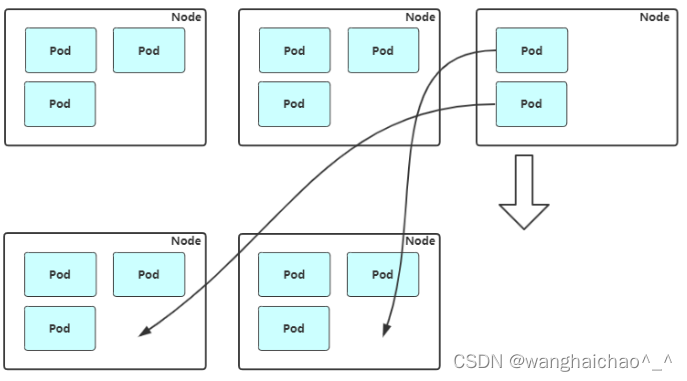
缩容:Cluster AutoScaler 也会定期监测 Node 的资源使用情况,当一个 Node 长时间资源利用率都很低时(低于 50%)自动将其所在虚拟机从云服务商中删除。此时,原来的 Pod 会自动调度到其他 Node 上面。
缩容流程:
1、获取节点列表
kubectl get node2、设置不可调度
kubectl cordon $node_name3、驱逐节点上的Pod
kubectl drain $node_name --ignore-daemonsets4、移除节点
该节点上已经没有任何资源了,可以直接移除节点:
kubectl delete node $node_name这样,我们平滑移除了一个 k8s 节点。
Pod自动扩容/缩容(HPA)
Horizontal Pod Autoscaler(HPA,Pod水平自动伸缩),根据资源利用率或者自定义指标自动调整replication controller, deployment 或 replica set,实现部署的自动扩展和缩减,让部署的规模接近于实际服务的负载。HPA不适于无法缩放的对象,例如DaemonSet。
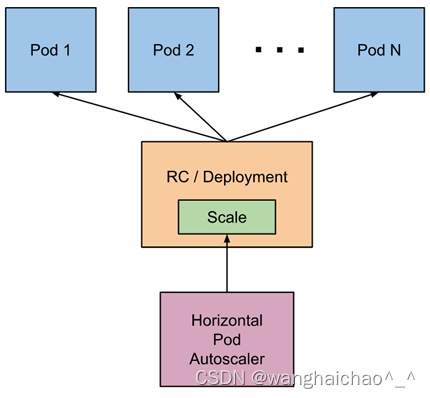
HPA基本原理
Kubernetes 中的 Metrics Server 持续采集所有 Pod 副本的指标数据。HPA 控制器通过 Metrics Server 的 API(Heapster 的 API 或聚合 API)获取这些数据,基于用户定义的扩缩容规则进行计算,得到目标 Pod 副本数量。当目标 Pod 副本数量与当前副本数量不同时,HPA 控制器就向 Pod 的副本控制器(Deployment、RC 或 ReplicaSet)发起 scale 操作,调整 Pod 的副本数量,完成扩缩容操作。如图所示:
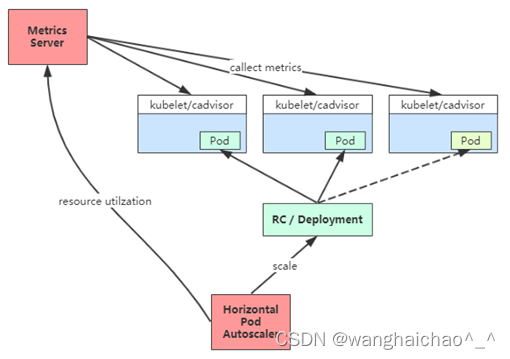
在弹性伸缩中,冷却周期是不能逃避的一个话题, 由于评估的度量标准是动态特性,副本的数量可能会不断波动。有时被称为颠簸, 所以在每次做出扩容缩容后,冷却时间是多少。
在 HPA 中,默认的扩容冷却周期是 3 分钟,缩容冷却周期是 5 分钟。
可以通过调整kube-controller-manager组件启动参数设置冷却时间:
--horizontal-pod-autoscaler-downscale-delay :扩容冷却
--horizontal-pod-autoscaler-upscale-delay :缩容冷却
HPA的演进历程
目前 HPA 已经支持了 autoscaling/v1、autoscaling/v2beta1和autoscaling/v2beta2 三个大版本 。
目前大多数人比较熟悉是autoscaling/v1,这个版本只支持CPU一个指标的弹性伸缩。
而autoscaling/v2beta1增加了支持自定义指标,autoscaling/v2beta2又额外增加了外部指标支持。
而产生这些变化不得不提的是Kubernetes社区对监控与监控指标的认识与转变。从早期Heapster到Metrics Server再到将指标边界进行划分,一直在丰富监控生态。
v1版本:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:name: php-apachenamespace: default
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apacheminReplicas: 1maxReplicas: 10targetCPUUtilizationPercentage: 50v2beta2版本:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:name: php-apachenamespace: default
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apacheminReplicas: 1maxReplicas: 10metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 50- type: Podspods:metric:name: packets-per-secondtarget:type: AverageValueaverageValue: 1k- type: Objectobject:metric:name: requests-per-seconddescribedObject:apiVersion: networking.k8s.io/v1beta1kind: Ingressname: main-routetarget:type: Valuevalue: 10k- type: Externalexternal:metric:name: queue_messages_readyselector: "queue=worker_tasks"target:type: AverageValueaverageValue: 30Kubernetes API Aggregation(API 聚合层)
在 Kubernetes 1.7 版本引入了聚合层,允许第三方应用程序通过将自己注册到kube-apiserver上,仍然通过 API Server 的 HTTP URL 对新的 API 进行访问和操作。为了实现这个机制,Kubernetes 在 kube-apiserver 服务中引入了一个 API 聚合层(API Aggregation Layer),用于将扩展 API 的访问请求转发到用户服务的功能。
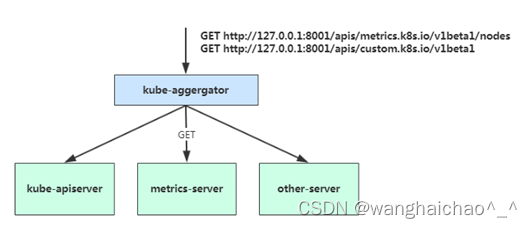
当你访问 apis/metrics.k8s.io/v1beta1 的时候,实际上访问到的是一个叫作 kube-aggregator 的代理。而 kube-apiserver,正是这个代理的一个后端;而 Metrics Server,则是另一个后端 。通过这种方式,我们就可以很方便地扩展 Kubernetes 的 API 了。
如果你使用kubeadm部署的,默认已开启。如果你使用二进制方式部署的话,需要在kube-APIServer中添加启动参数,增加以下配置:
# vi /opt/kubernetes/cfg/kube-apiserver.conf
...
--requestheader-client-ca-file=/opt/kubernetes/ssl/ca.pem \
--proxy-client-cert-file=/opt/kubernetes/ssl/server.pem \
--proxy-client-key-file=/opt/kubernetes/ssl/server-key.pem \
--requestheader-allowed-names=kubernetes \
--requestheader-extra-headers-prefix=X-Remote-Extra- \
--requestheader-group-headers=X-Remote-Group \
--requestheader-username-headers=X-Remote-User \
--enable-aggregator-routing=true \
...在设置完成重启 kube-apiserver 服务,就启用 API 聚合功能了。
部署 Metrics Server
Metrics Server是一个集群范围的资源使用情况的数据聚合器。作为一个应用部署在集群中。
Metric server从每个节点上Kubelet公开的摘要API收集指标。
Metrics server通过Kubernetes聚合器注册在Master APIServer中。
metric-service.yml
---
apiVersion: v1
kind: ServiceAccount
metadata:labels:k8s-app: metrics-servername: metrics-servernamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:labels:k8s-app: metrics-serverrbac.authorization.k8s.io/aggregate-to-admin: "true"rbac.authorization.k8s.io/aggregate-to-edit: "true"rbac.authorization.k8s.io/aggregate-to-view: "true"name: system:aggregated-metrics-reader
rules:
- apiGroups:- metrics.k8s.ioresources:- pods- nodesverbs:- get- list- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:labels:k8s-app: metrics-servername: system:metrics-server
rules:
- apiGroups:- ""resources:- nodes/metricsverbs:- get
- apiGroups:- ""resources:- pods- nodesverbs:- get- list- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:labels:k8s-app: metrics-servername: metrics-server-auth-readernamespace: kube-system
roleRef:apiGroup: rbac.authorization.k8s.iokind: Rolename: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccountname: metrics-servernamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:labels:k8s-app: metrics-servername: metrics-server:system:auth-delegator
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: system:auth-delegator
subjects:
- kind: ServiceAccountname: metrics-servernamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:labels:k8s-app: metrics-servername: system:metrics-server
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: system:metrics-server
subjects:
- kind: ServiceAccountname: metrics-servernamespace: kube-system
---
apiVersion: v1
kind: Service
metadata:labels:k8s-app: metrics-servername: metrics-servernamespace: kube-system
spec:ports:- name: httpsport: 443protocol: TCPtargetPort: httpsselector:k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:labels:k8s-app: metrics-servername: metrics-servernamespace: kube-system
spec:selector:matchLabels:k8s-app: metrics-serverstrategy:rollingUpdate:maxUnavailable: 0template:metadata:labels:k8s-app: metrics-serverspec:containers:- args:- --cert-dir=/tmp- --secure-port=4443- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname- --kubelet-use-node-status-port- --metric-resolution=15s- --kubelet-insecure-tlsimage: bitnami/metrics-server:0.6.2imagePullPolicy: IfNotPresentlivenessProbe:failureThreshold: 3httpGet:path: /livezport: httpsscheme: HTTPSperiodSeconds: 10name: metrics-serverports:- containerPort: 4443name: httpsprotocol: TCPreadinessProbe:failureThreshold: 3httpGet:path: /readyzport: httpsscheme: HTTPSinitialDelaySeconds: 20periodSeconds: 10resources:requests:cpu: 100mmemory: 200MisecurityContext:allowPrivilegeEscalation: falsereadOnlyRootFilesystem: truerunAsNonRoot: truerunAsUser: 1000volumeMounts:- mountPath: /tmpname: tmp-dirnodeSelector:kubernetes.io/os: linuxpriorityClassName: system-cluster-criticalserviceAccountName: metrics-servervolumes:- emptyDir: {}name: tmp-dir
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:labels:k8s-app: metrics-servername: v1beta1.metrics.k8s.io
spec:group: metrics.k8s.iogroupPriorityMinimum: 100insecureSkipTLSVerify: trueservice:name: metrics-servernamespace: kube-systemversion: v1beta1versionPriority: 100验证:
[root@master k8s]# kubectl get apiservice|grep metrics
v1beta1.metrics.k8s.io kube-system/metrics-server True 40h
[root@master k8s]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master 165m 4% 3157Mi 55%
node1 67m 3% 1826Mi 49%
node2 90m 4% 1464Mi 39%
[root@master k8s]#CPU指标扩缩容
部署nginx测试应用:
apiVersion: apps/v1
kind: Deployment
metadata:name: myapp-web
spec:selector:matchLabels:app: myapp-webreplicas: 2 template:metadata:labels:app: myapp-webspec:containers:- name: myapp-webimage: nginxresources:limits:memory: "128Mi"cpu: "500m"ports:- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:name: myapp-web-service
spec:selector:app: myapp-webports:- port: 80targetPort: 80创建HPA策略
scaleTargetRef:表示当前要伸缩对象是谁
targetCPUUtilizationPercentage:当整体的资源利用率超过50%的时候,会进行扩容。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:name: myapp-web-hpa
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: myapp-webminReplicas: 1maxReplicas: 5metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 50创建成功后,获取到CPU指标:
[root@master k8s]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
myapp-web-hpa Deployment/myapp-web 0%/50% 1 5 2 16s
[root@master k8s]#开启压测:
[root@localhost ~]# ab -n 10000000 -c 100 http://179.220.56.230:30088/index观察Pod资源使用率
[root@master k8s]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
myapp-web-hpa Deployment/myapp-web 100%/50% 1 5 1 21m[root@master k8s]# kubectl describe hpa myapp-web-hpa
Warning: autoscaling/v2beta2 HorizontalPodAutoscaler is deprecated in v1.23+, unavailable in v1.26+; use autoscaling/v2 HorizontalPodAutoscaler
Name: myapp-web-hpa
Namespace: default
Labels:
Annotations:
CreationTimestamp: Fri, 17 Mar 2023 09:52:54 +0800
Reference: Deployment/myapp-web
Metrics: ( current / target )resource cpu on pods (as a percentage of request): 101% (50m) / 50%
Min replicas: 1
Max replicas: 5
Deployment pods: 2 current / 4 desired
Conditions:Type Status Reason Message---- ------ ------ -------AbleToScale True SucceededRescale the HPA controller was able to update the target scale to 4ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)ScalingLimited True ScaleUpLimit the desired replica count is increasing faster than the maximum scale rate
Events:Type Reason Age From Message---- ------ ---- ---- -------Warning FailedGetScale 4m59s horizontal-pod-autoscaler deployments/scale.apps "myapp-web" not foundWarning FailedGetResourceMetric 4m29s (x6 over 9m14s) horizontal-pod-autoscaler failed to get cpu utilization: unable to get metrics for resource cpu: no metrics returned from resource metrics APIWarning FailedComputeMetricsReplicas 4m29s (x6 over 9m14s) horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get cpu utilization: unable to get metrics for resource cpu: no metrics returned from resource metrics APIWarning FailedGetResourceMetric 4m14s horizontal-pod-autoscaler failed to get cpu utilization: did not receive metrics for any ready podsWarning FailedComputeMetricsReplicas 4m14s horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get cpu utilization: did not receive metrics for any ready podsNormal SuccessfulRescale 3m59s (x6 over 18m) horizontal-pod-autoscaler New size: 1; reason: All metrics below targetNormal SuccessfulRescale 104s horizontal-pod-autoscaler New size: 2; reason: cpu resource utilization (percentage of request) above targetNormal SuccessfulRescale 13s horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target
[root@master k8s]# 关闭压测,过一会检查缩容状态。
[root@master k8s]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
myapp-web-hpa Deployment/myapp-web 0%/50% 1 5 1 29m
[root@master k8s]# v2还支持其他另种类型的度量指标,:Pods和Object。
type: Pods
pods:metric:name: packets-per-secondtarget:type: AverageValueaverageValue: 1ktype: Object
object:metric:name: requests-per-seconddescribedObject:apiVersion: networking.k8s.io/v1beta1kind: Ingressname: main-routetarget:type: Valuevalue: 2kmetrics中的type字段有四种类型的值:Object、Pods、Resource、External。
- Resource:指的是当前伸缩对象下的pod的cpu和memory指标,只支持Utilization和AverageValue类型的目标值。
- Object:指的是指定k8s内部对象的指标,数据需要第三方adapter提供,只支持Value和AverageValue类型的目标值。
- Pods:指的是伸缩对象Pods的指标,数据需要第三方的adapter提供,只允许AverageValue类型的目标值。
- External:指的是k8s外部的指标,数据同样需要第三方的adapter提供,只支持Value和AverageValue类型的目标值。