
查找算法之费氏搜寻法
给定一个大小为n的排序数组arr[],并在其中搜索一个元素x。如果x在数组中,则返回x的下标,否则返回-1。
费氏搜索是一种基于比较的技术,它使用斐波那契数搜索排序数组中的元素。
与二分搜索的相似之处:
适用于排序数组
分治算法。
时间复杂度为Log n。
与二分查找的区别:
斐波那契搜索将给定数组分割成不相等的部分
二分搜索使用除法运算符来分割范围。斐波那契搜索不使用/,而是使用+和-。除法运算符在某些cpu上可能代价很高。
斐波那契搜索在后续步骤中检查相对较近的元素。因此,当输入数组很大,无法装入CPU缓存甚至RAM时,斐波那契搜索就很有用了。
背景
斐波那契数被递归定义为 F(n) = F(n-1) + F(n-2), F(0) = 0, F(1) =
1. 前几个斐波那契数是 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, …
观测
下面的观察结果用于范围消除,因此用于O(log(n))复杂度。
F(n - 2) ≈ (1/3)*F(n) and
F(n - 1) ≈ (2/3)*F(n).
算法
设搜索的元素为x。
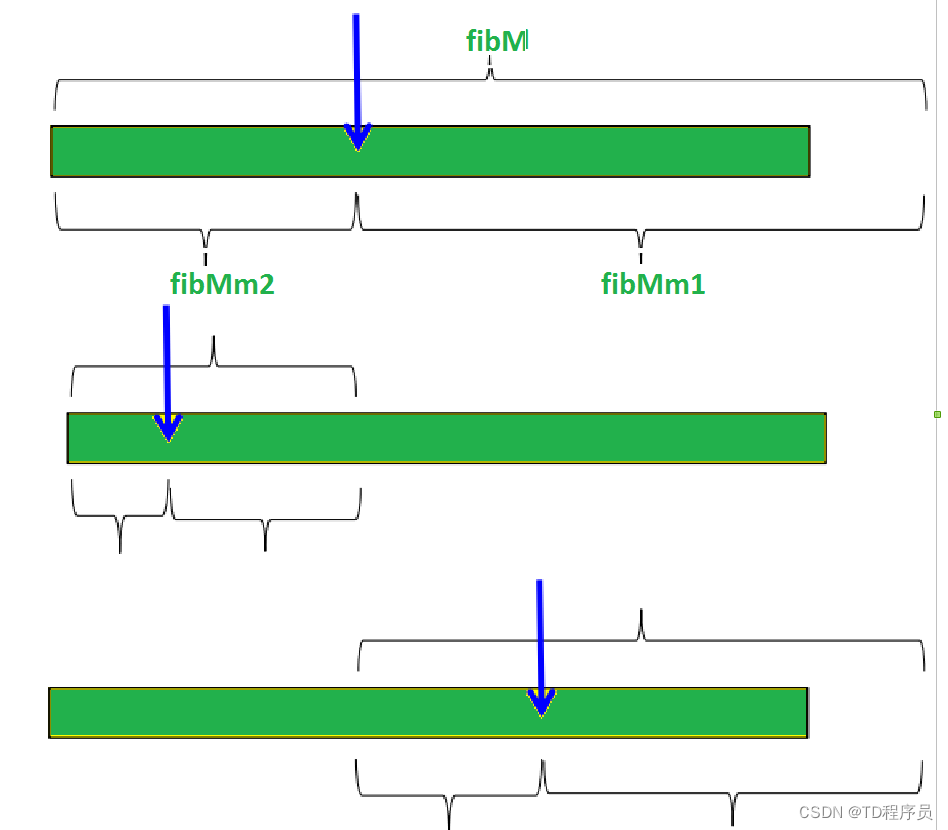
其思想是首先找到大于或等于给定数组长度的最小斐波那契数。让找到的斐波那契数为fib(第m个斐波那契数)。我们使用(m-2)次斐波那契数作为索引(如果它是一个有效的索引)。设(m-2)第1个斐波那契数为i,我们比较arr[i]和x,如果x相同,我们返回i。否则如果x更大,我们在i之后递归子数组,否则在i之前递归子数组。
下面是完整的算法
让arr [0 . .N-1]为输入数组,要搜索的元素为x。
找出大于或等于n的最小斐波那契数。设此数为fibM[第m个斐波那契数]。设它前面的两个斐波那契数为fibMm1 [(m-1)第th斐波那契数]和fibMm2 [(m-2)第th斐波那契数]。
当数组有要检查的元素时:
将x与fibMm2覆盖的范围的最后一个元素进行比较
如果 x 匹配, return 索引
如果x小于该元素,则将三个斐波那契变量向下移动两个斐波那契,表示消除大约后面三分之二的剩余数组。
否则x大于元素,将三个斐波那契变量向下移动一个斐波那契。将偏移量重置为索引。这些组合在一起表明消除了大约前三分之一的剩余阵列。
由于可能剩下一个元素进行比较,因此检查fibMm1是否为1。如果是,将x与剩余的元素进行比较。如果匹配,返回索引。
以下是C代码的实现源码
// C program for Fibonacci Search
#include // Utility function to find minimum of two elements
int min(int x, int y) { return (x <= y) ? x : y; }/* Returns index of x if present, else returns -1 */
int fibMonaccianSearch(int arr[], int x, int n)
{/* Initialize fibonacci numbers */int fibMMm2 = 0; // (m-2)'th Fibonacci No.int fibMMm1 = 1; // (m-1)'th Fibonacci No.int fibM = fibMMm2 + fibMMm1; // m'th Fibonacci/* fibM is going to store the smallest FibonacciNumber greater than or equal to n */while (fibM < n) {fibMMm2 = fibMMm1;fibMMm1 = fibM;fibM = fibMMm2 + fibMMm1;}// Marks the eliminated range from frontint offset = -1;/* while there are elements to be inspected. Note thatwe compare arr[fibMm2] with x. When fibM becomes 1,fibMm2 becomes 0 */while (fibM > 1) {// Check if fibMm2 is a valid locationint i = min(offset + fibMMm2, n - 1);/* If x is greater than the value at index fibMm2,cut the subarray array from offset to i */if (arr[i] < x) {fibM = fibMMm1;fibMMm1 = fibMMm2;fibMMm2 = fibM - fibMMm1;offset = i;}/* If x is greater than the value at index fibMm2,cut the subarray after i+1 */else if (arr[i] > x) {fibM = fibMMm2;fibMMm1 = fibMMm1 - fibMMm2;fibMMm2 = fibM - fibMMm1;}/* element found. return index */elsereturn i;}/* comparing the last element with x */if (fibMMm1 && arr[offset + 1] == x)return offset + 1;/*element not found. return -1 */return -1;
}/* driver function */
int main(void)
{int arr[]= { 10, 22, 35, 40, 45, 50, 80, 82, 85, 90, 100,235};int n = sizeof(arr) / sizeof(arr[0]);int x = 235;int ind = fibMonaccianSearch(arr, x, n);
if(ind>=0)printf("Found at index: %d",ind);
elseprintf("%d isn't present in the array",x);return 0;
}
输出
Found at index: 11
说明:
让我们用下面的例子来理解这个算法:

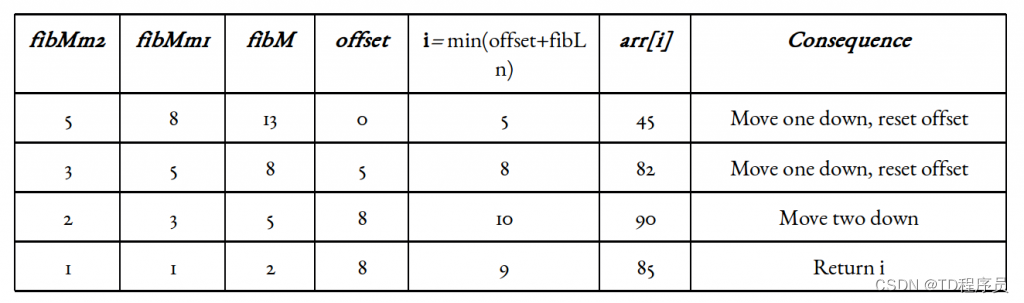
举例假设:基于1的索引。目标元素x是85。数组长度n = 11。
大于或等于11的最小斐波那契数是13。根据我们的例子,fibMm2 = 5, fibMm1 = 8, fibM = 13。
另一个实现细节是偏移量变量(零初始化)。它从前面开始标记已消除的范围。我们会不时更新。
现在,由于偏移值是一个指标,包括它在内的所有指标和低于它的指标都被消除了,所以只有向它添加一些东西才有意义。由于fibMm2标记了大约三分之一的数组,以及它标记的索引,确保是有效的,我们可以将fibMm2添加到offset,并检查索引i = min(offset + fibMm2, n)处的元素。
时间复杂度分析
当我们的目标在数组的较大(2/3)部分时,最坏情况将发生,因为我们继续寻找它。换句话说,我们每次都要消除数组中较小的(1/3)部分。我们对n调用一次,然后是(2/3)n,然后是(4/9)n,如此类推。
