
Flink环境部署
本地单节点启动
集群模式启动
WebUI提交作业
命令行提交作业
部署模式
Flink YARN 模式
本地单节点启动
解压
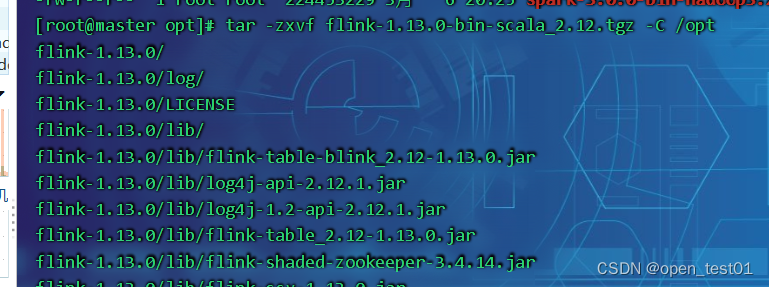
启动进程
[root@master flink-1.13.0]# bin/start-cluster.sh//启动hadoop
[root@master flink-1.13.0]# start-all.sh访问8081端口Web界面
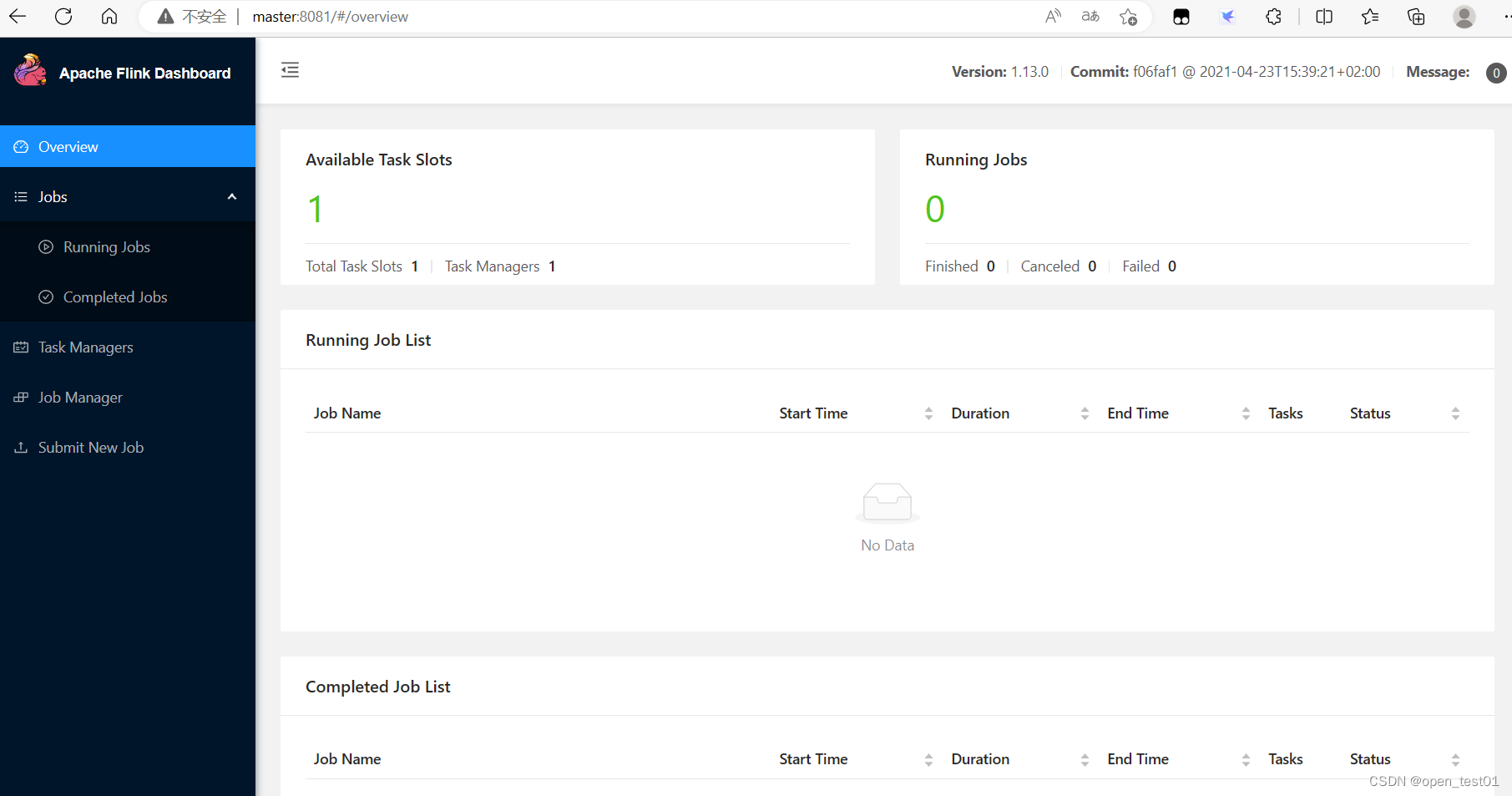
停止进程
[root@master flink-1.13.0]# bin/stop-cluster.sh
集群模式启动
进入 conf 目录下,修改 flink-conf.yaml 文件,修改 jobmanager.rpc.address 参数
vim flink-conf.yaml
指定节点
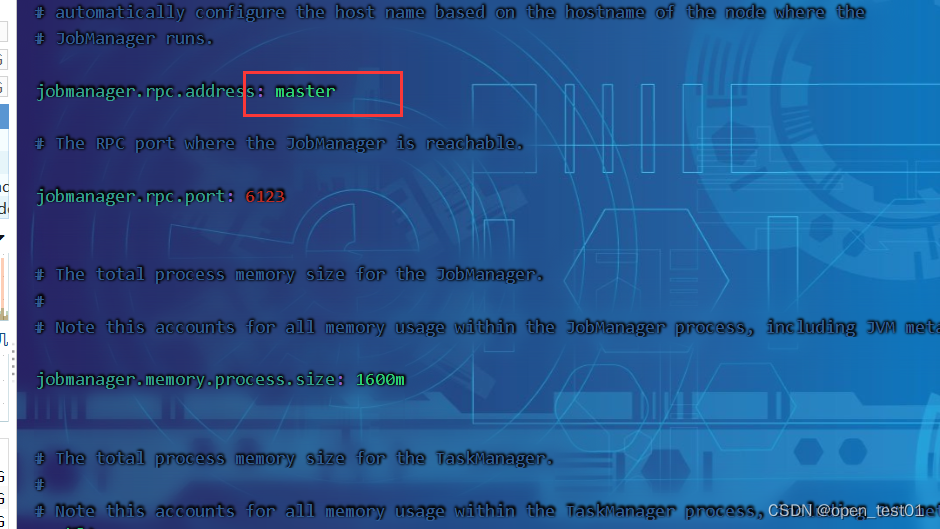
[root@master conf]# vim masters

修改 workers 文件,将另外两台节点服务器添加为本 Flink 集群的 TaskManager 节点
[root@master conf]# vim workers
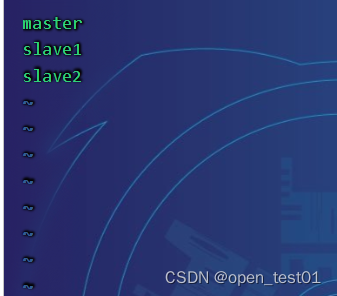
集群分发Flink
分发到slave1
scp -r /opt/flink-1.13.0 root@slave1:/opt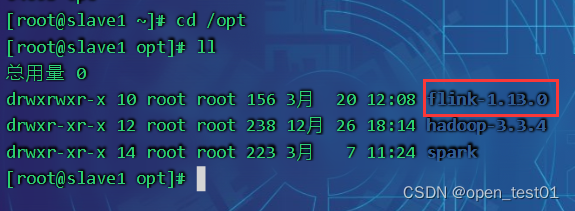
分发到slave2
scp -r /opt/flink-1.13.0 root@slave2:/opt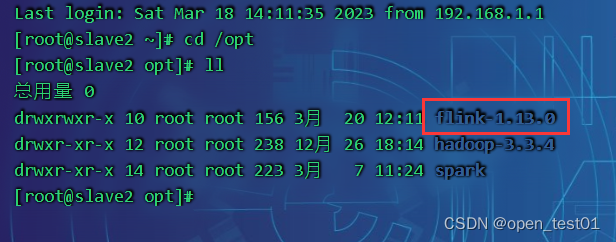
启动集群
bin/start-cluster.sh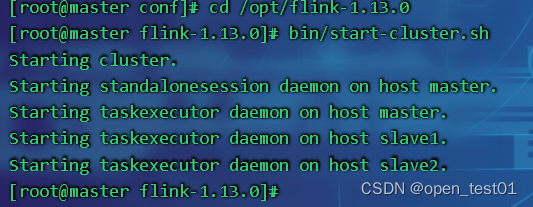
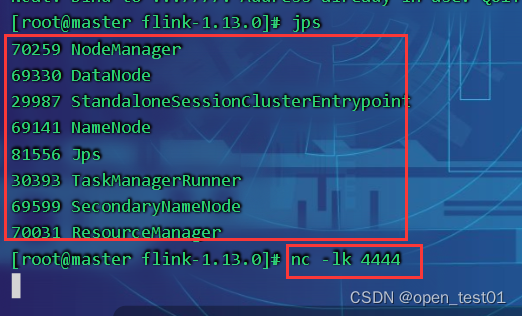
查看master节点进程
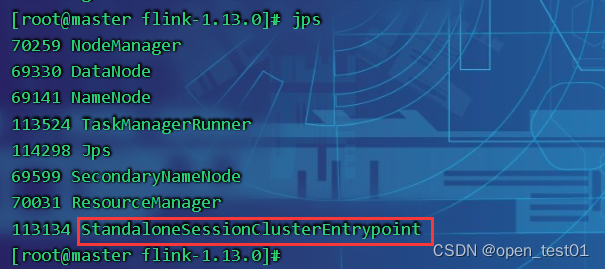
查看slave1节点进程
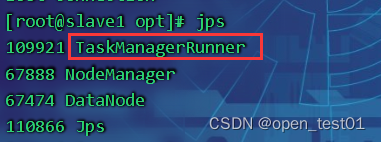
查看slave2节点进程
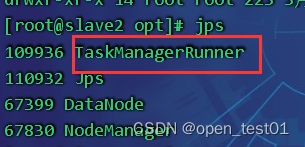
进入查看web端口
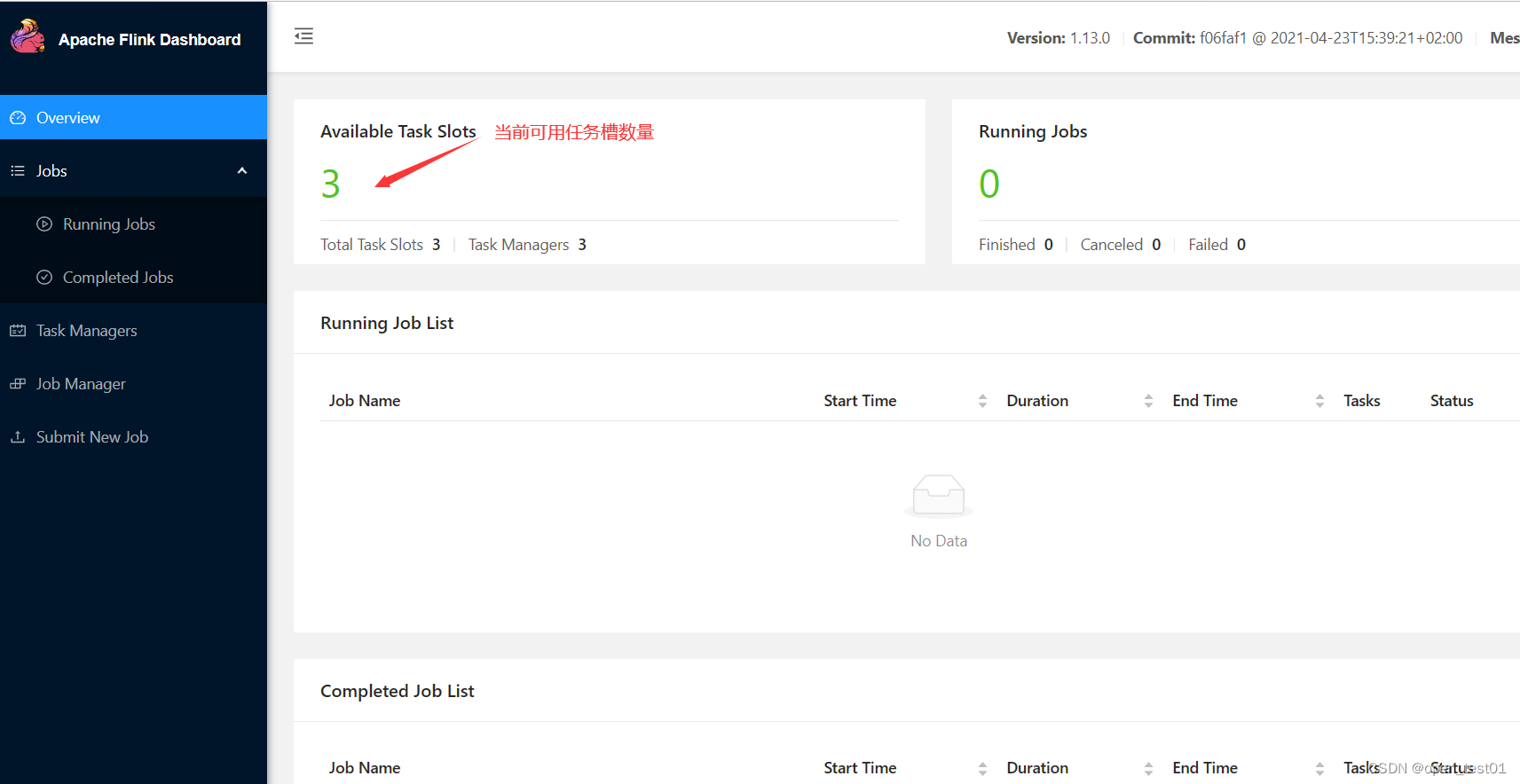
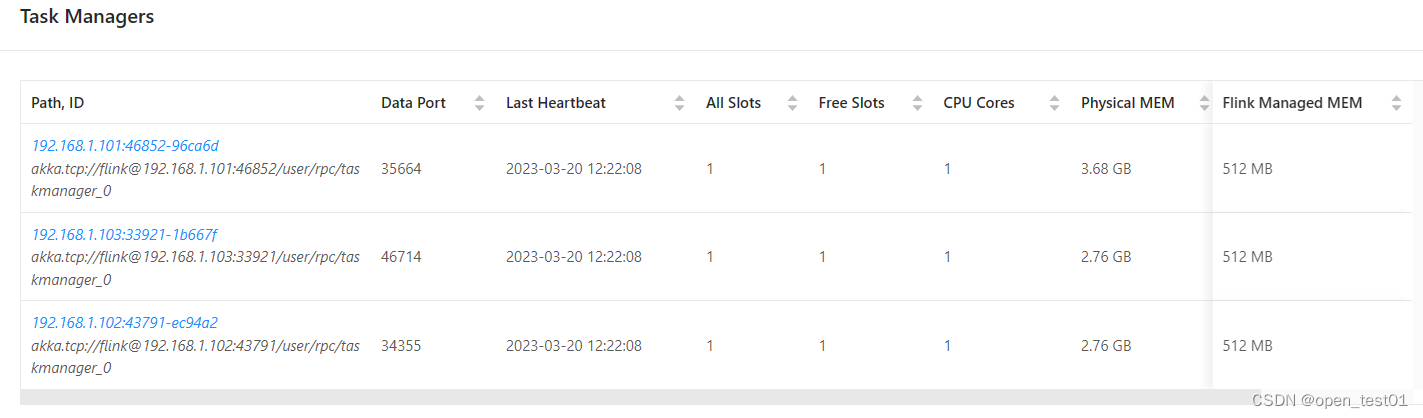
停止集群进程
[root@master flink-1.13.0]# bin/stop-cluster.sh
WebUI提交作业
在IDEA中准备无界流处理实现WordCount程序
def main(args: Array[String]): Unit = {//创建执行环境val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment//读取socket文本流数据//socketTextStream("主机名","端口号")val parTool: ParameterTool = ParameterTool.fromArgs(args)val hostname: String = parTool.get("host")val port: Int = parTool.getInt("port")val line: DataStream[String] = env.socketTextStream(hostname,port)//对数据集进行转换处理val fl: DataStream[(String, Int)] = line.flatMap(_.split("")).map(w => (w,1))//分组val gp: KeyedStream[(String, Int), String] = fl.keyBy(_._1)//聚合统计val rs: DataStream[(String, Int)] = gp.sum(1)//输出rs.print()//执行当前任务env.execute()}服务器中启动nc服务监听进程
nc -lk 7777
如果无法使用nc命令则执行命令安装:yum install -y nc
程序打包
为方便自定义结构和定制依赖,我们可以引入插件 maven-assembly-plugin 进行打包,pom.xml 文件中添加打包插件的配置。
org.apache.maven.plugins maven-assembly-plugin 3.0.0 jar-with-dependencies make-assembly package single 查看引入的打包插件
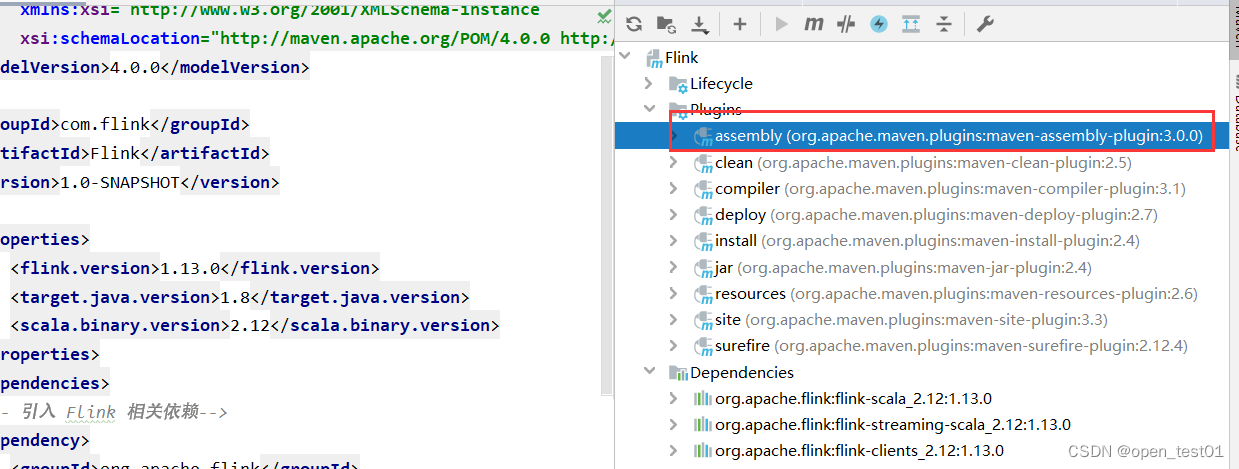
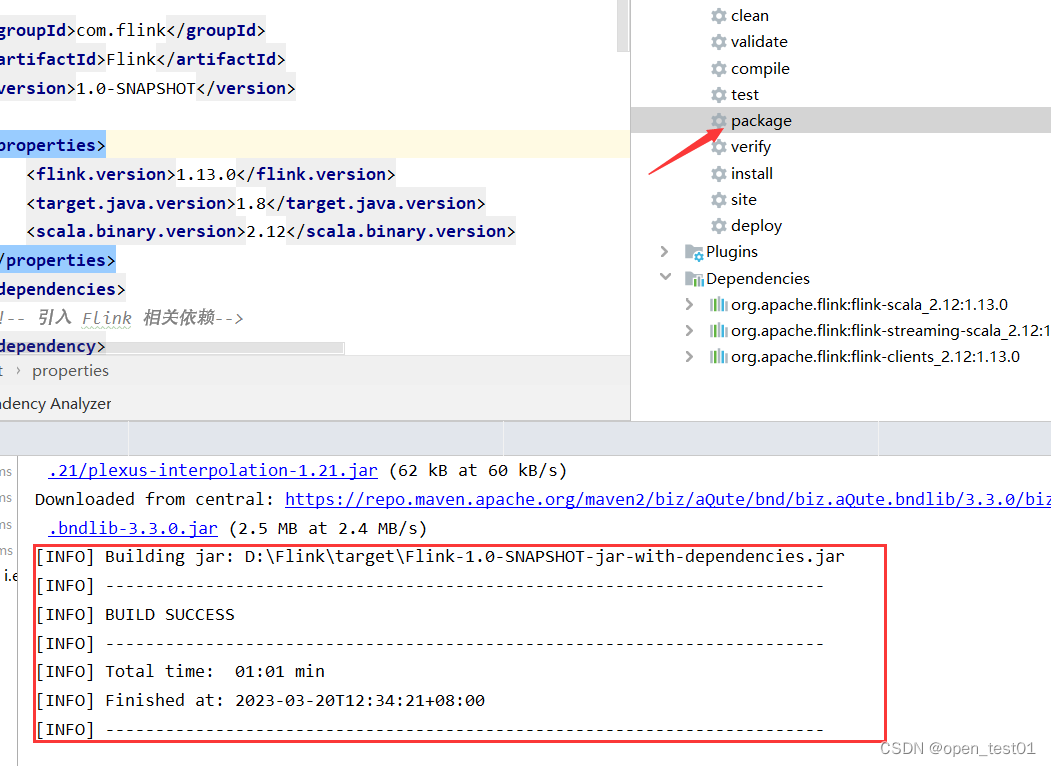
执行打包程序
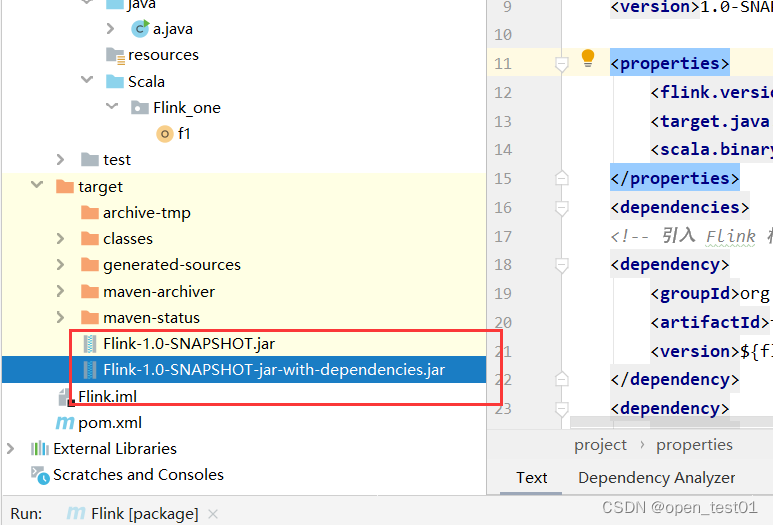
进入WebUI提交jar包作业
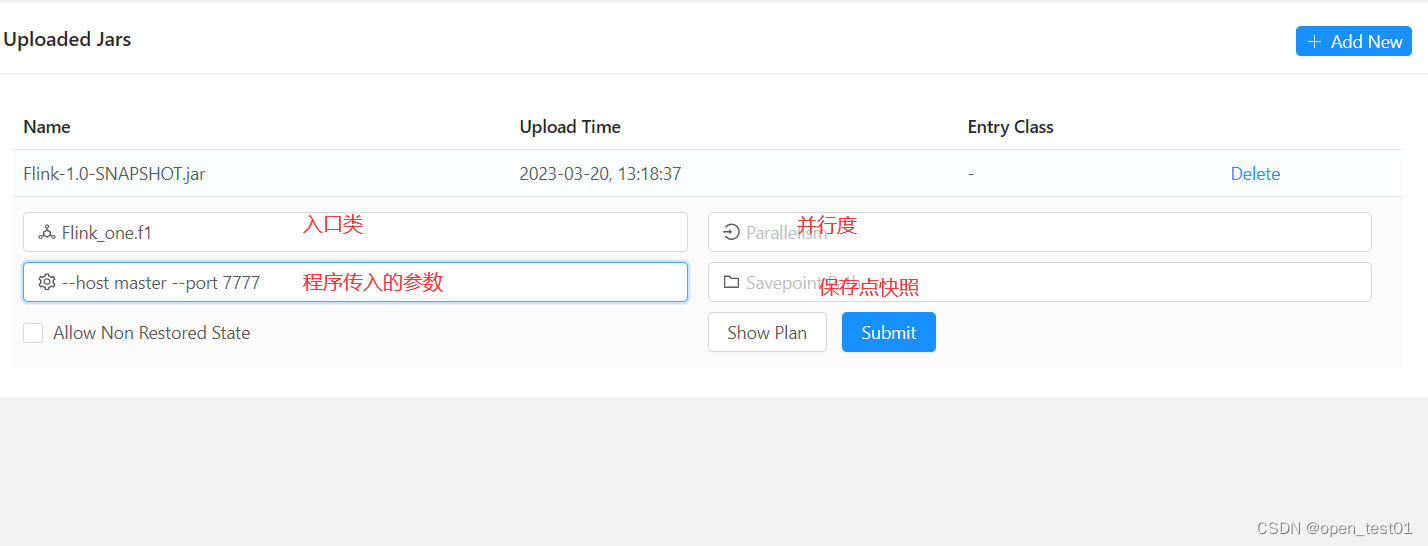
查看当前执行计划

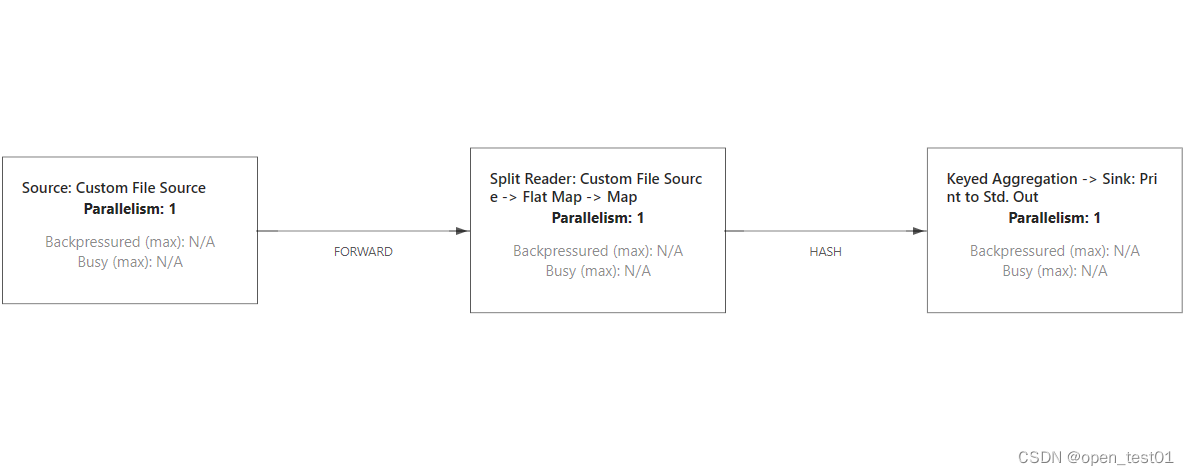
查看提交成功
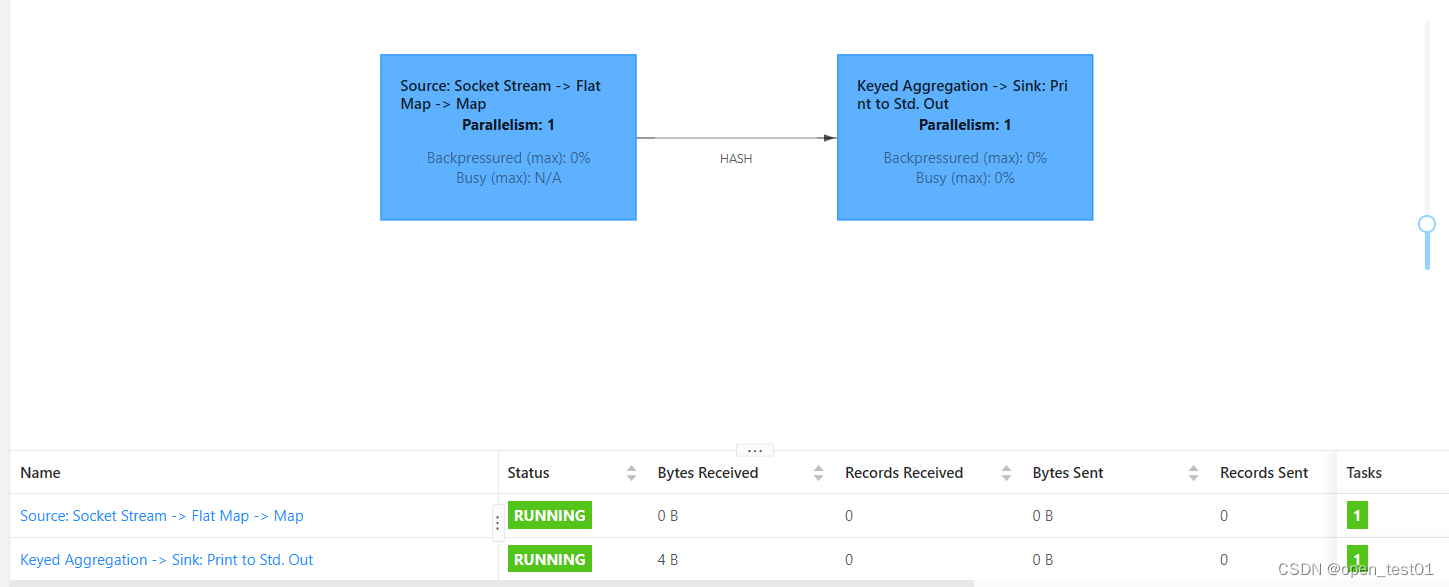
监听程序输入内容

查看作业执行的输出结果
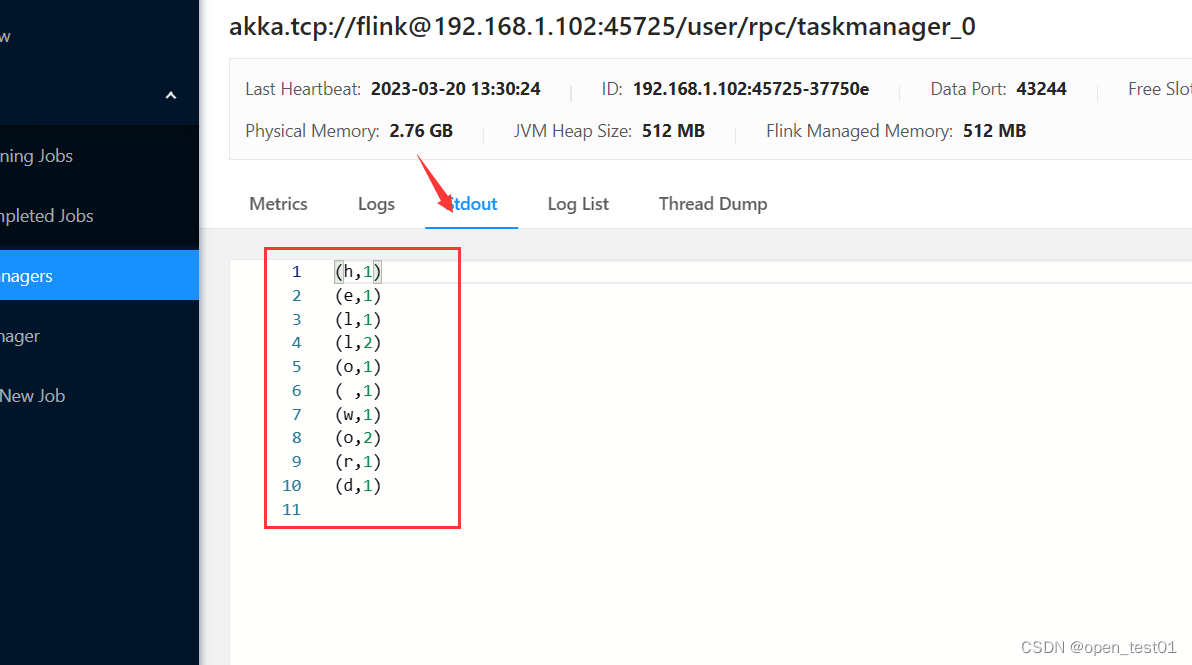 停止作业进程
停止作业进程
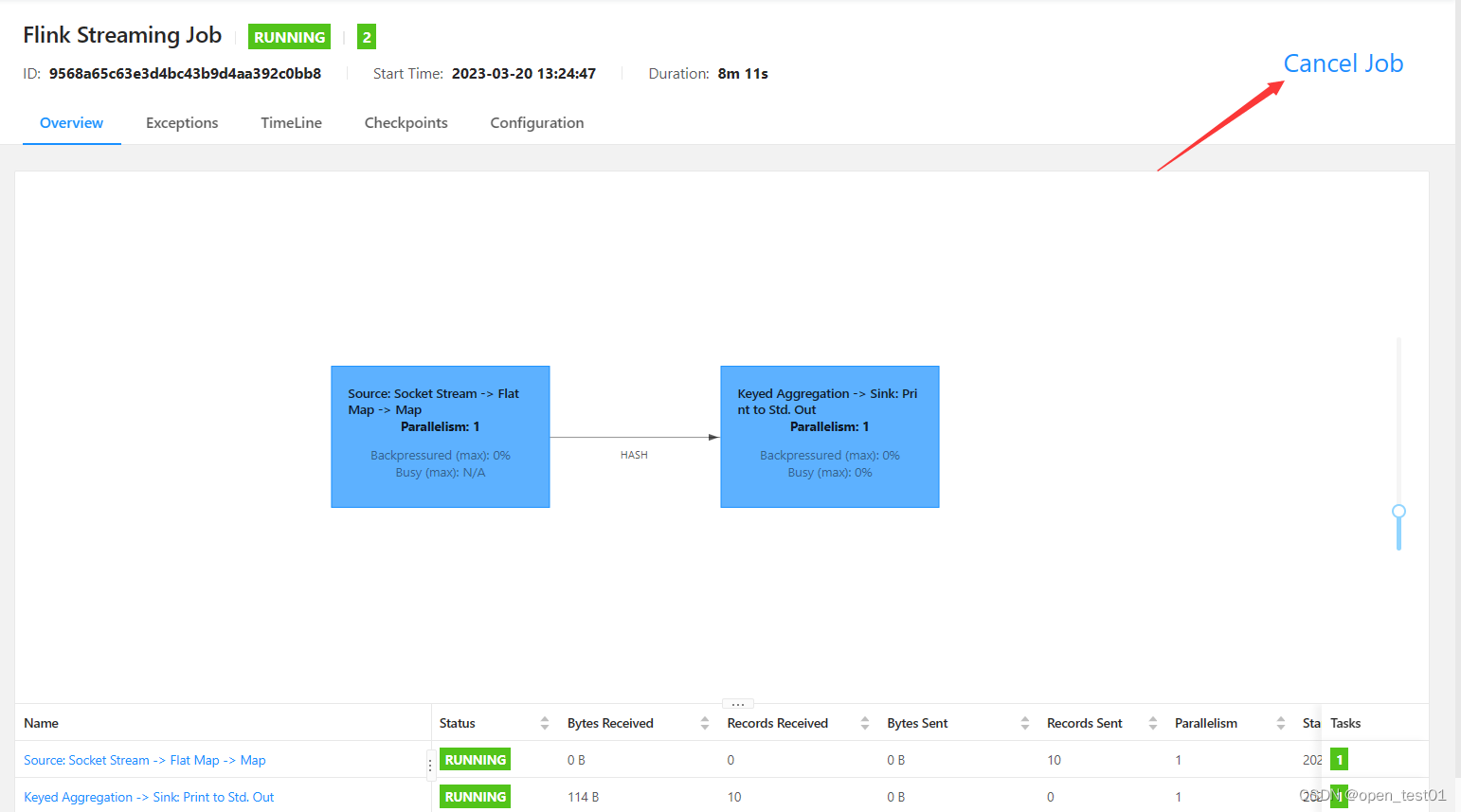
命令行提交作业
启动集群、启动nc监听程序
新打开一个连接窗口
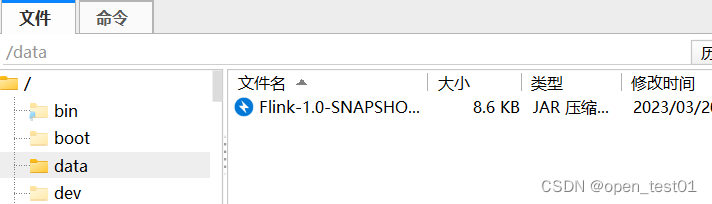
上传jar包到虚拟机中
命令提交
[root@master flink-1.13.0]# bin/flink run -m master:8081 -c Flink_one.f1 /data/Flink-1.0-SNAPSHOT.jar --host master --port 4444
到WebUI查看提交的作业进程

命令行查看当前执行作业运行状态
[root@master flink-1.13.0]# bin/flink list JobID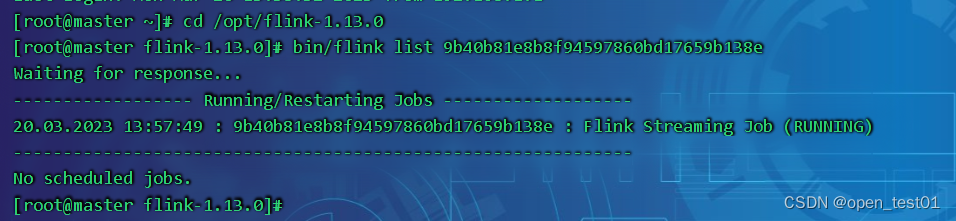
取消作业
[root@master flink-1.13.0]# bin/flink cancel JobID
部署模式
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink 为各 种场景提供了不同的部署模式,主要有以下三种:
- 会话模式(Session Mode)
- 单作业模式(Per-Job Mode)
- 应用模式(Application Mode)
会话模式
会话模式其实最符合常规思维。我们需要先启动一个集群,保持一个会话,在这个会话中 通过客户端提交作业。集群启动时所有资源就都已经确定,所以所有提交的 作业会竞争集群中的资源。会话模式比较适合于单个规模小、执行时间短的大量作业。
单作业模式
会话模式因为资源共享会导致很多问题,所以为了更好地隔离资源,我们可以考虑为每个 提交的作业启动一个集群,这就是所谓的单作业(Per-Job)模式,需要注意的是,Flink 本身无法直接这样运行,所以单作业模式一般需要借助一些资源管 理平台来启动集群,比如 YARN、Kubernetes。
应用模式
前面提到的两种模式下,应用代码都是在客户端上执行,然后由客户端提交给 JobManager 的。但是这种方式客户端需要占用大量网络带宽,去下载依赖和把二进制数据发送给 JobManager;加上很多情况下我们提交作业用的是同一个客户端,就会加重客户端所在节点的 资源消耗。应用模式与单作业模式,都是提交作业之后才创建集群;单作业模式是通过客户端来提交 的,客户端解析出的每一个作业对应一个集群;而应用模式下,是直接由 JobManager 执行应 用程序的,并且即使应用包含了多个作业,也只创建一个集群。
Flink YARN 模式
添加环境变量
export HADOOP_HOME=/opt/hadoop-3.3.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`启动Hadoop
[root@master flink-1.13.0]# start-dfs.sh
[root@master flink-1.13.0]# start-yarn.sh修改 flink-conf.yaml 文件
进入 conf 目录,修改 flink-conf.yaml 文件,修改以下配置,这些配置项的含义在进 行 Standalone 模式配置的时候进行过讲解,若在提交命令中不特定指明,这些配置将作为默认配置。
[root@master flink-1.13.0]# cd /opt/flink-1.13.0/conf
[root@master conf]# vim flink-conf.yamljobmanager.memory.process.size: 1600m
taskmanager.memory.process.size: 1728m
taskmanager.numberOfTaskSlots: 8
parallelism.default: 1
YARN会话模式部署
YARN 的会话模式与独立集群略有不同,需要首先申请一个 YARN 会话(YARN session) 来启动 Flink 集群。具体步骤如下:
(1)启动 Hadoop 集群,包括 HDFS 和 YARN。
(2)执行脚本命令向 YARN 集群申请资源,开启一个 YARN 会话,启动 Flink 集群。
bin/yarn-session.sh -nm test
- -d:分离模式,如果你不想让 Flink YARN 客户端一直前台运行,可以使用这个参数, 即使关掉当前对话窗口,YARN session 也可以后台运行。
- -jm(--jobManagerMemory):配置 JobManager 所需内存,默认单位 MB。
- -nm(--name):配置在 YARN UI 界面上显示的任务名。
- -qu(--queue):指定 YARN 队列名。
- -tm(--taskManager):配置每个 TaskManager 所使用内存。
YARN单作业模式部署
在 YARN 环境中,由于有了外部平台做资源调度,所以我们也可以直接向 YARN 提交一 个单独的作业,从而启动一个 Flink 集群。
执行命令提交作业:
bin/flink run -d -t yarn-per-job -c com.atguigu.wc.StreamWordCount
FlinkTutorial-1.0-SNAPSHOT.jar
可以使用命令行查看或取消作业,命令如下 :
$ ./bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
$ ./bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
YARN应用模式部署
应用模式同样非常简单,与单作业模式类似,直接执行 flink run-application 命令即可
执行命令提交作业:
bin/flink run-application -t yarn-application -c com.atguigu.wc.StreamWordCount
FlinkTutorial-1.0-SNAPSHOT.jar在命令行中查看或取消作业:
$ ./bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY
$ ./bin/flink cancel -t yarn-application
-Dyarn.application.id=application_XXXX_YY 也可以通过 yarn.provided.lib.dirs 配置选项指定位置,将 jar 上传到远程:
./bin/flink run-application -t yarn-application
-Dyarn.provided.lib.dirs="hdfs://myhdfs/my-remote-flink-dist-dir"
hdfs://myhdfs/jars/my-application.jar