
喜马拉雅基于 HybridBackend 的深度学习模型训练优化实践
喜马拉雅作者:李超、陶云、许晨昱、胡文俊、张争光、赵云鹏、张玉静
喜马拉雅AI云借助阿里云提供的HybridBackend开源框架,实现了其推荐模型在 GPU 上的高效训练。
业务介绍
推荐场景是喜马拉雅app的重要应用之一,它广泛应用于热点、猜你喜欢、私人FM、首页信息流、发现页推荐、每日必听等模块。这些模块都依赖于喜马拉雅AI云,这是一套从数据、特征、模型到服务的全流程一站式算法工具平台。
推荐服务的一个核心诉求是能快速捕捉和反映用户不断变化的兴趣和当前热点,这就要求模型能在短时间内,以可控的成本完成对海量用户数据的训练。使用GPU等高性能硬件来加速模型训练已经成为CV, NLP等领域的行业标准;在使用稀疏训练数据的推荐场景下,国内外的各大厂商也在积极转向使用高性能GPU来替代传统的CPU训练集群,以提升训练的效率。

喜马拉雅AI云借助阿里云机器学习平台PAI的开源框架HybridBackend,实现了其推荐模型在 GPU 上的高效训练。在加速训练的同时, HybridBackend 框架高度易用,帮助其算法团队提升了开发效率。
问题与挑战
随着推荐业务的底层训练硬件逐渐从CPU向GPU转变,我们在生产实践中发现传统的训练方式存在严重的计算资源利用率不足的问题。经过调查与分析,我们发现计算资源利用不足主要来自于稀疏数据访问和分布式训练两方面:
-
稀疏数据访问:我们使用经典机器学习中常用的 libsvm 数据格式来存储数据,将多个特征合并成一个稀疏字符串表达。在训练时,训练节点从远端的存储(如 OSS)上下载字符串,并从字符串中切分出多个特征输入,然后再喂入对应的 Embedding Table。在特征维度爆炸性增长的情况下,拼接字符串的数据量很大,导致数据读取严重受制于网络带宽;同时切分字符串也造成了 CPU 资源的消耗。
-
分布式训练:我们尝试过多种分布式训练方式。起初,我们使用 keras+horovod 实现多GPU分布式训练,但在具体使用过程中发现有不少问题,比如出现加速不稳定、模型指标恶化等现象。后来,我们自研实现了一版基于参数服务器(PS)的分布式训练框架,通过内部的 xcache 服务实现 embedding 存储管理并进行线上同步,并使用自研的pspull和pspush算子进行embedding表的更新,一定程度上解决了分布式训练的效率问题。但在进一步增大训练数据量时发现,引入的 ps 算子因为频繁的 IO 交互成为了训练速度的瓶颈,降低了GPU设备利用率,同时 xcache 服务存储变长embedding 的支持成本很高,限制了算法工程师的优化空间。
HybridBackend
我们在调研如何解决上述问题和探索未来技术发展空间时发现了阿里云正在推广的开源框架 HybridBackend,该框架对稀疏模型训练过程中的数据访问、稀疏计算以及分布式训练都进行了深度优化(见图1),并提供了简单易用的接口。令人惊喜的是,这个框架兼容性很强,可以支持 TensorFlow、DeepRec 等多种训练框架,可以很好地满足我们服务不同业务客户的需求。此外,相关的架构和系统设计已经以论文形式在ICDE2022会议上公开,并且在Github上开源了主要功能,可以直接以pip方式安装。

HybridBackend的基本功能模块
图2 描述了在我司模型训练任务中落地 HybridBackend 的全景示意图。蓝色框代表了 HybridBackend 参与或加速了的流程部分。可以看到基本涵盖了全部模型训练流程, 下面重点介绍在数据读取和分布式训练上的优化成果。
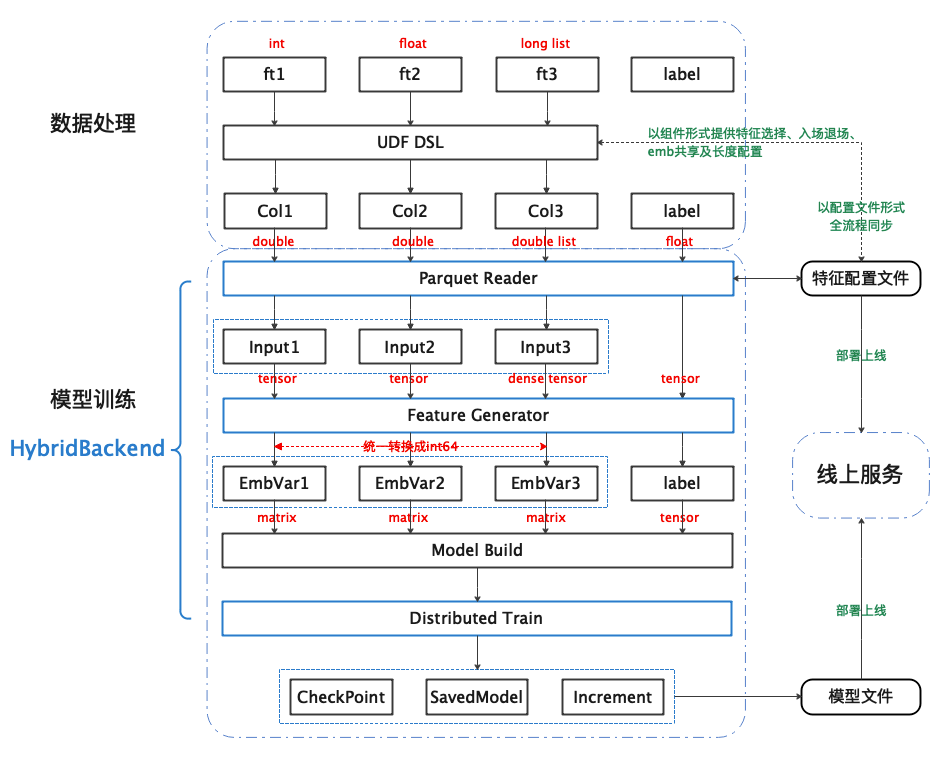
HybridBackend在喜马拉雅业务流程中的落地
稀疏数据访问优化
HybridBackend 提供了 hb.data.Dataset 接口 ,通过支持如 Parquet 这样的列存数据格式,可以极大加速稀疏数据的访问。如表1所示,HybridBackend 框架稀疏数据读取性能远高于其他实现。
| 文件格式 | 文件大小(MB) | 框架 | 线程数 | 耗时(ms) |
|---|---|---|---|---|
| CSV | 11062.61 | TensorFlow | 1 | 8858.38 |
| Parquet (SNAPPY) | 3346.10 | TensorFlow I/O | 1 | 103056.17 |
| Parquet (SNAPPY) | 3346.10 | HybridBackend | 1 | 397.88 |
| Parquet (SNAPPY) | 3346.10 | HybridBackend | 20 | 21.67 |
在我们的实际应用中,HybridBackend 稀疏数据访问功能中的一些功能效果显著:
- 数据列选择性解析:我们将需要原有的类libsvm格式切换成宽表格式,其中每列对应一个特征。HybridBackend 可以支持在读取 Parquet 文件时只读取选择的字段,并将字段数据解析成 TensorFlow 所需要的格式,如自动将 list 类型的数据转换为 SparseTensor,或将 list 类型的数据进行填充截断后转换为 Tensor,满足了我们数据加载的多种需要。
- 数据读取并行度设置:HybridBackend 可以通过设置num_parallel_reads 参数来调整读不同文件的并行度,通过设置num_parallel_parser_calls 参数来调整读文件中不同列的并行度。通过并行读取,在充分利用机器 CPU 资源的同时,加速了数据读取的性能。
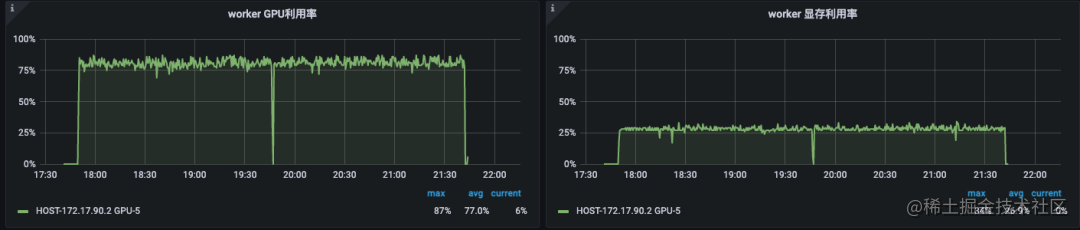
在使用 HybridBackend 后,数据访问不再是我们的训练瓶颈。单卡训练的 GPU 平均利用率提升了 3x 以上,业务模型的训练周期显著缩短。
分布式训练优化
HybridBackend 提供了混合并行训练模式(如图3),每张 GPU 都会存储全部的稠密参数和部分的稀疏参数,并使用可以利用 NVLink 的 NCCL 通信协议来代替传统 PS 训练方式所使用的 RPC 协议。
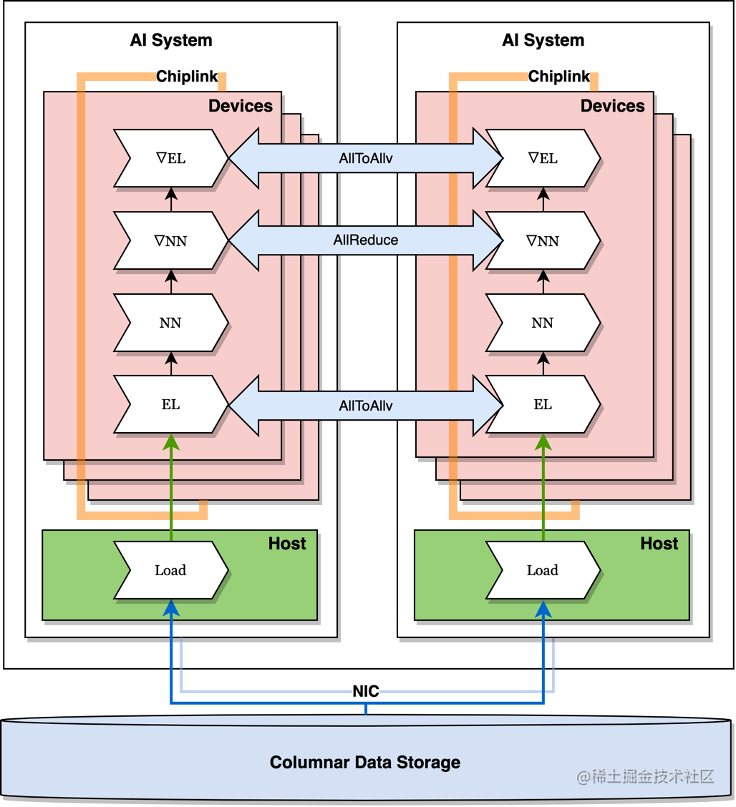
HybridBackend提供的混合并行训练模式
根据我们对未来一段时间内模型特征维度和大小的预估,以及我们对训练速度的需求,我们采用了 HybridBackend 混合并行方式进行训练,有效地提高了训练速度和 GPU 利用率。
我们还与 HybridBackend 社区的开发者协同工作,促进了 HybridBackend 对 Keras Model API 的支持,使我们能够在 Keras Model API 下利用 HybridBackend 进行混合并行,并实现模型热启等重要功能。这些功能极大地降低了使用成本。
总体收益
整体流程改造完毕之后,我们在推荐场景中,单机多卡训练 GPU 平均利用率提升了1.4x 以上(视具体模型不同),训练环节整体耗时减少50%以上。目前我们已经在使用了 Tensorflow 和 DeepRec 的模型中全量推广基于 HybridBackend 的训练方案。
未来规划
喜马拉雅 AI 云平台目前覆盖了喜马拉雅多个app的推荐、广告、搜索推荐等核心业务场景,以及画像产出、数据分析、BI数据生成等定制化开发场景。我们也在探索后续与 HybridBackend 社区的一些合作,以便更好地满足业务需求:
● 算子优化:HybridBackend支持了embedding lookup 过程中的各种算子的融合优化。我们会尝试通过这种方式提升模型在线推理的性能。
● PyTorch支持:NLP 搜推场景中有用 Pytorch 进行训练和部署的需求。我们需要HybridBackend能够支持该场景的实现。
● 超大型分布式训练:我们的模型训练级别达到了百亿样本十亿特征维度。随着算法复杂度的提升,我们需要支持更大的数据量和更高的维度的训练。
鸣谢
在合作共建阶段,我们得到了 HybridBackend 社区 陈浪石、袁满等的技术支持,他们技术高超、服务周到、响应及时。帮助我们快速完成了深度学习模型的训练流程优化,为我们的业务指标和算法优化空间带来了明显的提升。在此表示衷心的感谢!
HybridBackend 社区
欢迎在 GitHub 上 star 和提 issue,也可以直接在钉钉群中联系 HybridBackend 社区。
GitHub 地址:
https://github.com/alibaba/HybridBackend
上一篇:web前端-微信小程序开发学习