
生成AI(一)—“智能讲师”口唇同步
背景:2023年是生成式AI元年,本文讲解如何利用开源项目实现语音转视频。
目的:开源项目Wav2Lip介绍、编译、应用
效果图(右下角):
适合的领域:内容创作、教育、企业培训
特点:不要求本人出镜、原声。
一、开源项目Wav2Lip介绍
地址:Wav2Lip Github仓库地址
原理:
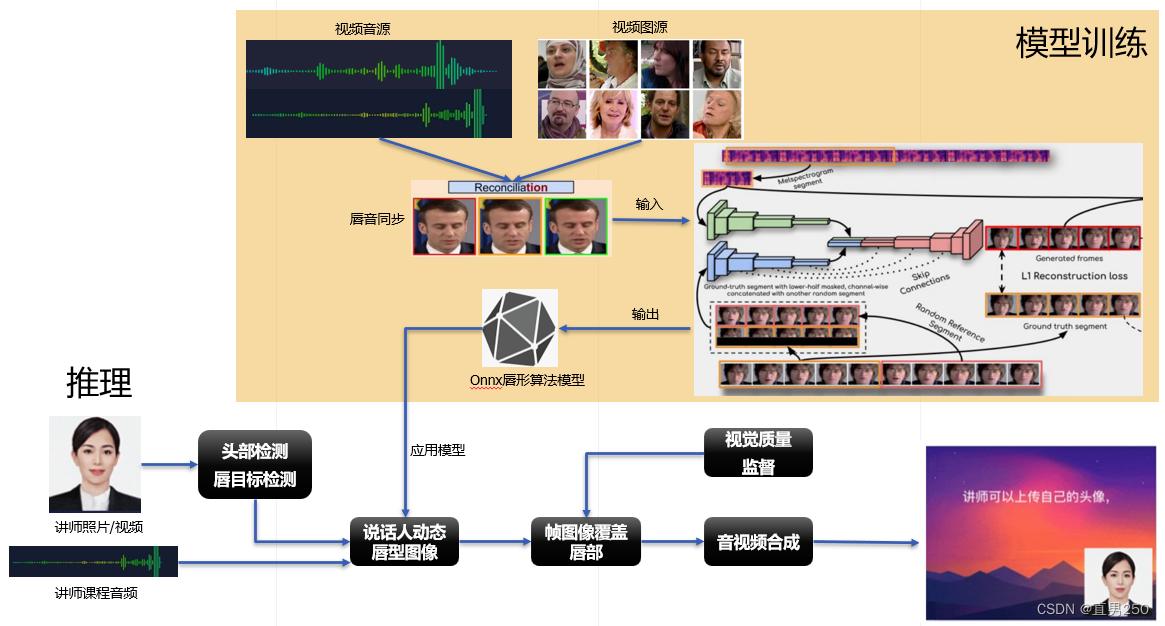
1.1 模型训练
训练数据源: LRS2 dataset
论文:Paper
特点:模型输入分为声音和图像,直接输出为唇部帧图。
1.2 代码实现
1,输入虚拟讲师的图片(或动态的视频)、语音,进行图像级别的opencv人脸识别、口唇识别。
2,输入讲者的音频原声,通过音频原声推理模型,生成动态口型。
3,通过视觉质量检查,模糊化背景重贴回原图,制作基于原图的视频动效。
4,利用ffmpeg集成音视频输出
二、项目编译
2.1 依赖安装
1,从官网下载FFmpeg
windows下载ffmpeg的EXE文件
2,配置环境变量
系统环境变量添加ffmpeg 的指向,执行ffmpeg查看是否能够识别到环境配置
c:users>ffmpeg
ffmpeg version N-104695-g86a2123a6e-20211129 Copyright (c) 2000-2021 the FFmpeg developersbuilt with gcc 10-win32 (GCC) 20210610
3,安装VSCode 最新版
4,安装Python 3.8
2.2 准备项目
1,下载项目源码,并解压。
2,下载预生成的推理模型文件Link,拷贝到:checkpoints\wav2lip_gan.pth
3,下载预生成的人脸检测推理模型文件pre-trained model ,拷贝到:face_detection\detection\sfd\s3fd.pth
4,在源码根目录创建dist文件夹,保证有如下结构
| 目录 | 子文件夹 | 文件 |
|---|---|---|
| dist | checkpoints | wav2lip_gan.pth |
| face_detection\detection\sfd | s3fd.pth | |
| results | ||
| temp |
2.3 编译项目
在VSCode中运行以下指令:
pip install -r requirements.txt
如果本机环境缺少响应的库,请补充安装即可。
依赖环境安装完成后,运行如下命令:
python inference.py --checkpoint_path --face --audio
其中,
- ckpt是wav2lip_gan.pth文件的相对路径
- video.mp4是虚拟讲师的人脸照片或视频全路径
- an-audio-source 是讲者的音频文件全路径。
三、生成EXE
必须:以管理员身份运行控制台
1,安装pipenv
cd [项目源码根目录]
pip install pipenv
2, 执行打包编译
#进入虚拟环境(上一步可省略,因为没有虚拟环境的话会自动建立一个)
pipenv shell
#安装模块
#pip install "opencv-python-headless<4.3"
pip install requests librosa==0.7.0 numpy==1.20.0 opencv-contrib-python>=4.2.0.34 opencv-python==4.1.2.30 torch==1.8.0 torchvision==0.9.0 tqdm==4.45.0 numba==0.48 face_detection
#打包的模块也要安装
pip install pyinstaller
#开始打包,依赖包因为是动态的__import__的,因此需要手动添加依赖模块hidden-import
pyinstaller -F --hidden-import face_detection.detection --hidden-import face_detection.detection.sfd inference.py
3,测试
cd dist
inference --checkpoint_path checkpoints\wav2lip_gan.pth --face D:\test\face.jpg --audio D:\test\audio.mp3
总结
通过源码编译,掌握利用生成AI,实现语音与口唇同步的方式播报视频,为其它功能集成。
可以考虑将生成的EXE文件,集成到其它应用中。
- 性能方面:
短音频要经过10S的时间,在CPU下;因写文档的条件限制,没有在GPU下进行测试。
-
效果方面:
1,卡通图像,口唇同步逼真。
2,形象佳的模特图像,口唇同步逼真。
3,笔者自创语言——胡说,口型同步逼真,没有试验猴子,估计效果也不错。
4,专业销售带有肢体语言的短视频,口唇同步逼真。
TODO:
项目源码从Python转C#,想了解转码思路,请参看之前的C# AI项目。