
OCR之论文笔记TrOCR
文章目录
- TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models
- 一. 简介
- 二. TrOCR
- 2.1. Encoder
- 2.2 Decoder
- 2.3 Model Initialiaztion
- 2.4 Task Pipeline
- 2.5 Pre-training
- 2.6 Fine-tuning
- 2.7 Data Augmentation
- 三. 实验
- 3.1 Data
- 3.2 Settings
- 3.2 Results
- 3.2.1 Architecture Comparison
- 3.2.2 Ablation Experiment
- 3.2.3 SROIE Task 2
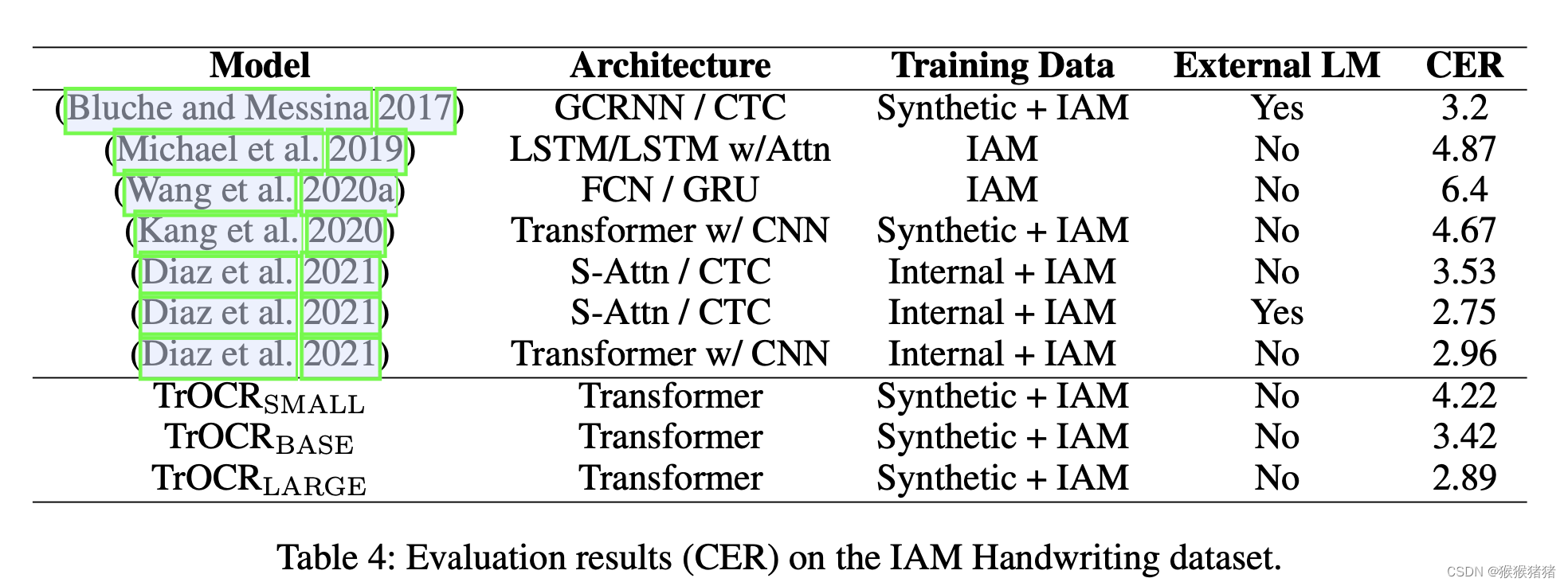
- 3.2.4 IAM Handwriting Database
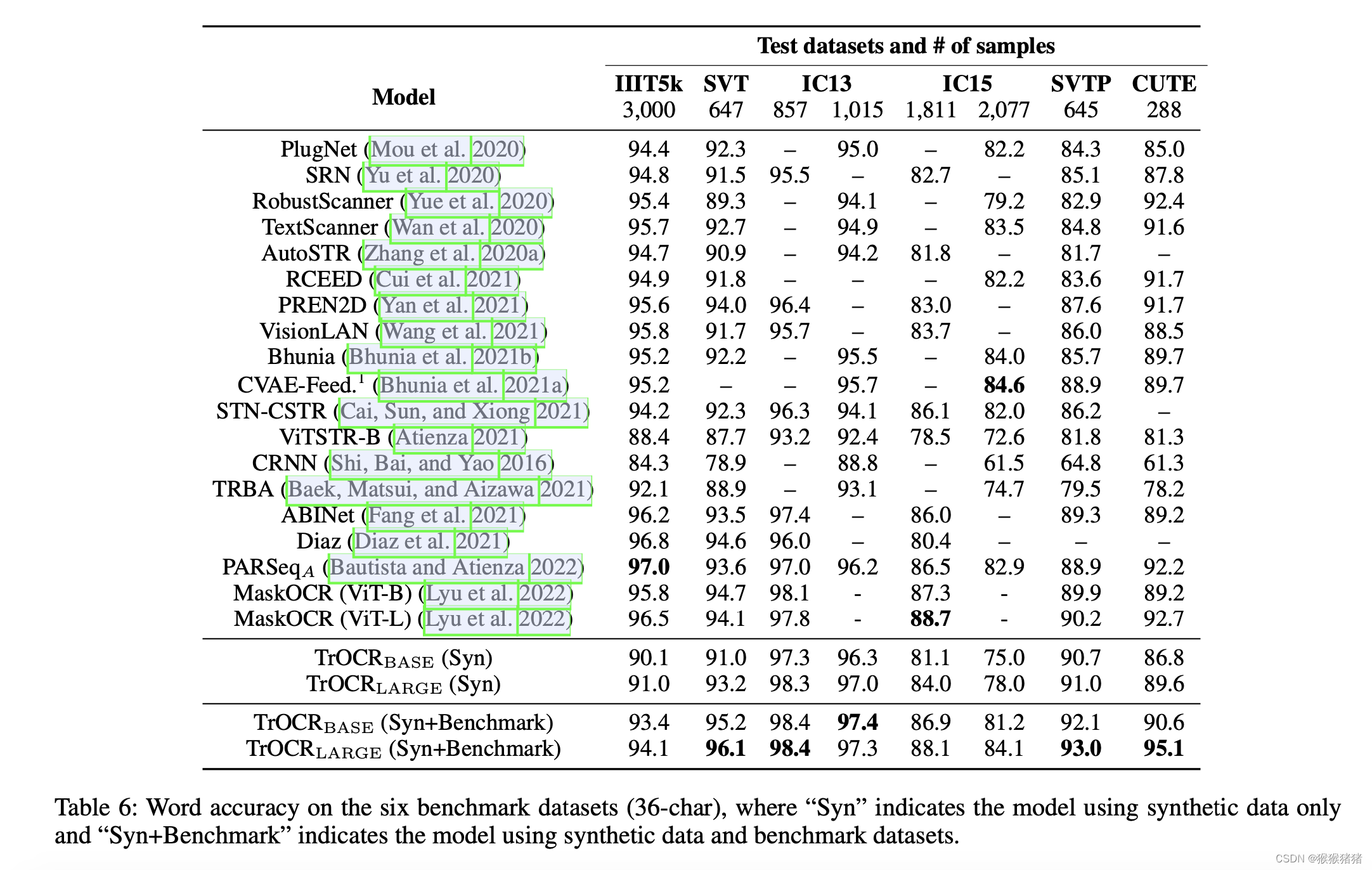
- 3.2.5 Scene Text Recognition
- 3.2.6 Inference Speed
TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models
一. 简介
发表:CVPR2022
机构:微软
代码:https://github.com/microsoft/unilm/tree/master/trocr
摘要:
Text recognition is a long standing-research problem for document digitalization. Existing approaches are usually built based on CNN for image understanding and RNN for char-level text generation. In addition, another language model is usually needed to improve the overall accuracy as a post- processing step. In this paper, we propose an end-to-end text recognition approach with pre-trained image Transformer and text Transformer models, namely TrOCR, which leverages the Transformer architecture for both image understanding and wordpiece-level text generation. The TrOCR model is simple but effective, and can be pre-trained with large-scale synthetic data and fine-tuned with human-labeled datasets. Experiments show that the TrOCR model outperforms the current state-of-the-art models on the printed, handwritten and scene text recognition tasks. The TrOCR models and code are publicly available at https://aka.ms/trocr.
Motivation:
现有的OCR方法往往基于 CNN + RNN的范式来进行建模,前者进行图像理解,后者用于字符级别的文本生成。除此之外,往往额外用一个语言模型来后处理,提高识别的准确率。本文,提出一种基于transformer的文本识别框架,将文本和图像都用transformer来建模,并且可以先在大规模人造数据上预训练,,再在人工标注的数据集上finetune。实验表明,TrOCR可以在印刷,手写和场景文本识别任务中,取得SOTA的结果。
二. TrOCR
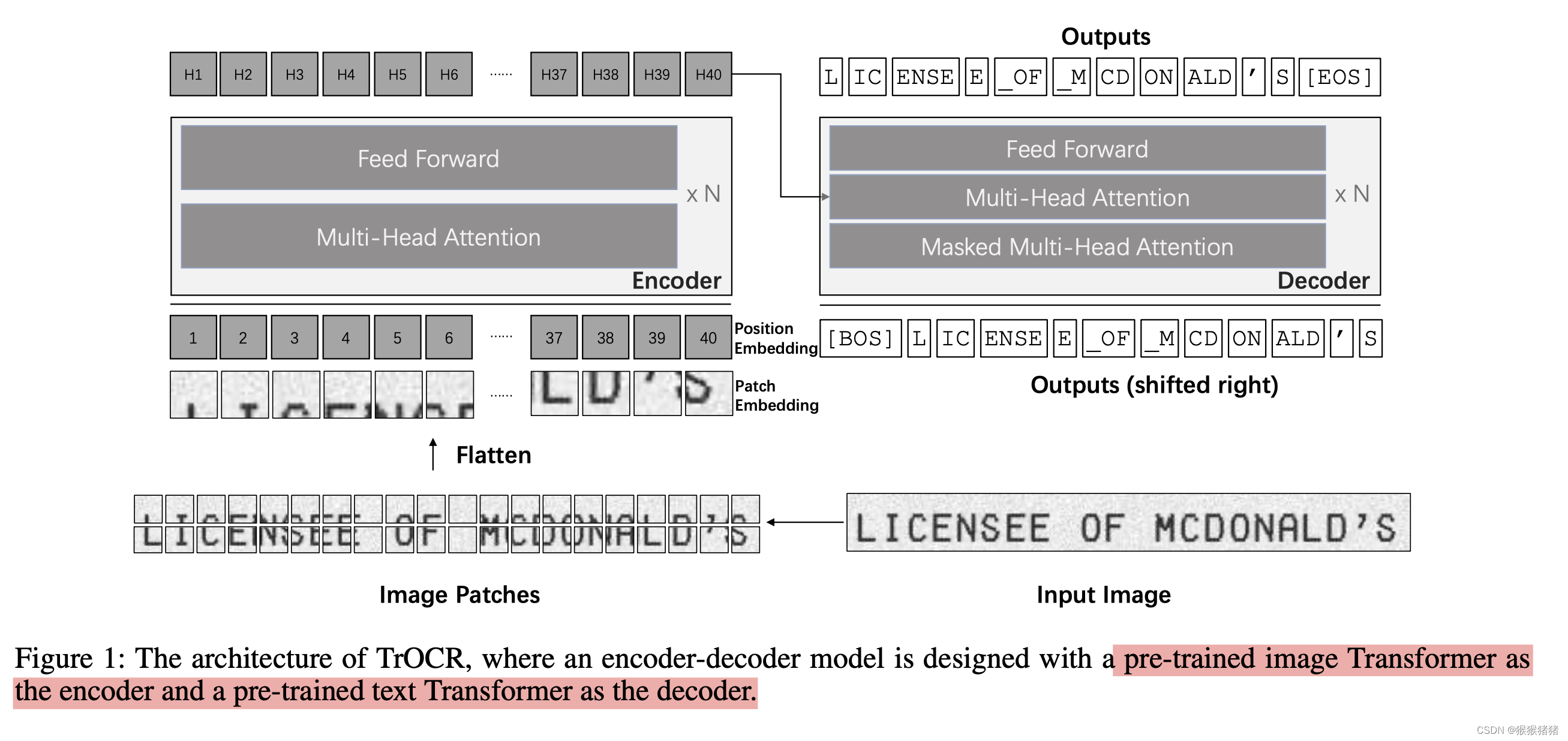
Encoder: ViT-style models
Decoder: BERT-style models
2.1. Encoder
Encoder的输入是固定尺寸(论文中是384 * 384),并且将其分解为 N 个patches,N=HW/P2N = HW / P ^2N=HW/P2,每个patch的尺寸是P∗PP * PP∗P,论文中N = 24 * 24,即每个patch的尺寸是16∗1616 * 1616∗16。然后将patch展平,过全连接,映射到D维。D就是transformer里面所有层的hidden size,默认是768。
与ViT和DeIT一样,保留了【CLS】这个特殊的token,用于图像分类任务。可以视作图像的全局特征。文中,还提到保留一种特殊的token,叫做distilation token,能够允许模型向教师模型学习。这两个特殊的token以及patches,会根据绝对位置被分配一个可以学习的位置编码(position embedding)。
Unlike the features extracted by the CNN-like network, the Transformer models have no image-specific inductive biases and process the image as a sequence of patches, which makes the model easier to pay different attention to either the whole image or the independent patches.
如何理解上面所说的归纳偏差:
CNN和Transformer是两种用于图像处理和计算机视觉任务的神经网络架构,它们在图像特定归纳偏差方面存在一些不同。
对于CNN来说,它的图像特定归纳偏差主要是基于卷积和池化操作。CNN中的卷积层通过局部感受野的方式捕捉图像的空间特征,并通过权值共享来减少参数数量。池化层则通过对特征图进行下采样来降低维度,从而提高网络的鲁棒性和计算效率。此外,CNN中的网络结构通常是层叠的,且特征图的通道数会随着网络的深度增加而增加,这些设计都是为了更好地适应图像数据的特征和结构。
相比之下,Transformer的图像特定归纳偏差主要是基于注意力机制。在Transformer中,注意力机制被用于在不同位置之间建立关联,从而能够处理不同尺度和分辨率的图像。通过自注意力机制,Transformer可以在不丢失空间信息的情况下,将图像编码成全局的特征向量。此外,Transformer的网络结构是基于自注意力层和全连接层的堆叠,这种结构可以处理变长的序列数据,因此在文本和语言等任务中也被广泛应用。
2.2 Decoder
decoder和encoder一样,也是标准的stack of identical layers的结构,有一点不同之处在于,decoder在multi-head self attetion和feed forward network之间插入了“ encoder-decoder attention",用于对encoder的输出分配不同的注意力。
在这个encoder-decoder attention中,K和V都来自encoder的输出,Q来自decoder的输入。除此之外,decoder在self attention中利用了attention masking,来防止它在训练过程中看到更多的信息,即,decoder的输出相较于decoder的输入员,往往会right shift一个位置,所以attention mask需要保证第i个位置的输出只能pay attention到之前的输出,即 decoder的hidden states然后会映射到V这个维度,其中V是词表的大小,然后用softmax来归一化,得到该hidden state输出各个字符的概率,并且用beam search来得到最终的输出。 在trocr中,文本识别任务被定义为这样的pipeline,对于输入的文本行图像,模型提出视觉特征,并且基于图像和之前产生的上下文来预测wordpiece的tokens。gt往往用【EOS】token来标识一个句子的结束。在训练的时候往往会在开头添加一个【BOS】的token来标识生成的开始,并达到shift one placed的效果。这个shifted的gt sequence会被输入decoder,它对应位置的输出被与gt sequence的交叉墒来监督。在inference的时候,decoder从【BOS】开始迭代预测,并且将产生的输出作为下一步的输入。 基于文本识别任务来进行预训练,分为两个阶段 疑问? 除了场景文本识别之外,预训练的trocr的模型,在其他下游文本识别任务中finetune。trocr的输出是基于Byte Pair Encoding (BPE)以及SentencePiece,而且不依赖于其他任何与任务无关的词表。 Byte Pair Encoding (BPE)是一种基于统计的无损数据压缩算法,它也被广泛用于自然语言处理领域中的文本编码和词汇表示。 Byte Pair Encoding(BPE)和SentencePiece都是常用于文本编码和词汇表示的算法,它们的主要区别在于以下几个方面: 算法原理:BPE是一种基于贪心算法的数据压缩算法,它通过反复合并出现频率最高的字符或字符对来构建词汇表。而SentencePiece则是基于Unigram语言模型的,它使用马尔可夫模型来学习词汇表中每个子词的概率,然后根据概率来进行分割。 六种数据增强策略被用到预训练和finetune的数据当中,随机旋转 (-10,10)度,高斯模糊,图像膨胀,图像腐蚀,下采样,下划线。对于每一个样本而言,各个增强方式以一种相同的概率被随机选择。对于场景文本识别数据集,用了之前文献的RandAug方法,其中的数据增强方式包括:inversion,扭曲,模糊,噪声,distoration,旋转等。 预训练数据集 Benchmarks TrOCR是基于Fairseq工具来写的,对于model初始化这一块,DeiT来自timm库,而BEiT和MiniLM来自微软的UniLM库,RoBERTa来自fairseq库。32张V100(32GBs)预训练,8张V100来finetune。 评价指标: 选择不同的encoder和decoder的组合,可以发现BeiT在encoder中表现最好,其次DeiT,再之后是resnet50 疑问? from scratch 这么低是什么原因? https://rrc.cvc.uab.es/?ch=13&com=evaluation&task=22.3 Model Initialiaztion
用DeiT和BeiT来初始化encoder。DeiT用ImageNet来训练,原始论文作者尝试不同的超参数和数据增强的方式,来使得数据更有效,除此之外,它们从一个非常强的图像分类器中提取知识到distilled token。而BeiT,借鉴MLM预训练任务,提出Mask Image Model任务来预训练image transformer。具体而言,每张图像,可以被视作两种view,image patches和visual tokens。用discreate VAE来将原始的图像转化为visual tokens,并且随机mask掉图像的patches,然后让模型进行复原原始的visual tokens。BeiT的图像transformer结果和DeiT一致,只不过是少了distilled token。
用RoBERTa以及MiniLM来初始化decoder,前者是在bert的基础上,探索了许多关键超参数和训练数据规模的影响,并且去除了next sentence prediction任务,而且动态改变了MLM里面的masking pattern。MiniLM是大预训练模型的压缩版,然而保留了99%的模型能力,除了在MLM中用到soft target probs和蒸馏学习之外,来引入一个教师助教,来辅助蒸馏。
但是直接加载上面两个模型到decoder有一些问题,因为encoder-decoder attention layers在原始模型中是没有的,因此采用的策略是,decoder相应的参数用RoBERTa和MiniLM来初始化,缺失的参数,随机初始化。2.4 Task Pipeline
2.5 Pre-training
是分别预训练图像encoder以及文本decoder吗?2.6 Fine-tuning
BPE的基本思想是将文本编码成一个固定大小的词汇表。它通过迭代地合并词汇表中出现频率最高的相邻字符或字符对,来不断增加词汇表的大小,直到达到预设的大小或满足停止条件为止。在每次迭代中,BPE会计算所有相邻字符或字符对的出现频率,然后将出现频率最高的字符或字符对合并成一个新的字符,并将其添加到词汇表中。这个过程会不断重复,直到词汇表达到预设大小或者满足停止条件。
通过这种方式,BPE可以生成一个小而紧凑的词汇表,并将文本编码为由词汇表中的字符或字符对组成的符号串。在自然语言处理中,BPE常用于生成单词分段(subword segmentation),即将单词分成更小的子单元,以便于语言模型处理生僻单词、未登录词和低频词等情况。在神经机器翻译和文本生成等任务中,使用BPE编码的文本能够更好地适应不同语言的语言特点,从而提高模型的性能。
应用场景:BPE主要应用于分词和子词划分等任务,而SentencePiece除了分词和子词划分外,还可以用于语音识别、OCR等领域。SentencePiece还支持多种分词算法,包括BPE、Unigram语言模型、WordPiece等。
实现方式:BPE和SentencePiece都有多种不同的实现方式,包括基于C++、Python、Java等语言的实现。其中,SentencePiece在Google的开源机器翻译框架TensorFlow和PyTorch中都有支持。
总体而言,BPE和SentencePiece都是用于文本编码和词汇表示的常用算法,具体使用哪种算法取决于具体的任务需求和数据特点。2.7 Data Augmentation
三. 实验
3.1 Data
将publily available的pdf转化为图像,并获得印刷体文本行的小图,总计684M。
通过TRDG开源库,来将5,427种手写体字体来构造手写数据集,其中语料是随机抓去自wiki,所以第二阶段的手写体预训练数据集的最终规模是17.9M,并且包括IIIT-HWS数据集。除此之外,收集了53K的真实票据数据,并用商用的OCR识别软件进行识别。也用TRDG构造了1M印刷体票据数据,对于场景文本识别而言,第二阶段预训练用到的数据集是MJSynth (MJ)和SynthText (ST),总计16M文本图像。
字体:
https://fonts.google.com/?category=Handwriting
https:// www.1001fonts.com/handwritten- fonts.html
渲染工程:
https://github.com/Belval/TextRecognitionDataGenerator
票据识别:SROIE (Scanned Receipts OCR and In- formation Extraction) dataset (Task 2) focuses on text recognition in receipt images. There are 626 receipt images and 361 receipt images in the training and test sets of SROIE.
手写识别:The IAM Handwriting Database is composed of hand- written English text, which is the most popular dataset for handwritten text recognition. We use the Aachen’s partition of the dataset3: 6,161 lines from 747 forms in the train set, 966 lines from 115 forms in the validation set and 2,915 lines from 336 forms in the test set.
场景文本识别:IIIT5K-3000, SVT-647, IC13-857, IC13-1015 , IC15-1811, IC15-2077, SVTP-645 , and CT80-288。3.2 Settings
batch_size: 2048
learning rate: 5e-5
384 * 384输入,16 * 16 patches。
The DeiTSMALL has 12 layers with 384 hidden sizes and 6 heads. Both the DeiTBASE and the BEiTBASE have 12 layers with 768 hidden sizes and 12 heads while the BEiTLARGE has 24 layers with 1024 hidden sizes and 16 heads. We use 6 layers, 256 hidden sizes and 8 attention heads for the small decoders, 512 hidden sizes for the base decoders and 12 layers, 1,024 hidden sizes and 16 heads for the large decoders.
beam size : 10
CRNN作为baseline对比:https://github.com/meijieru/crnn.pytorch
word-level pre- cision, recall and f1 score.
Character Error Rate (CER)
Word Accuracy3.2 Results
3.2.1 Architecture Comparison
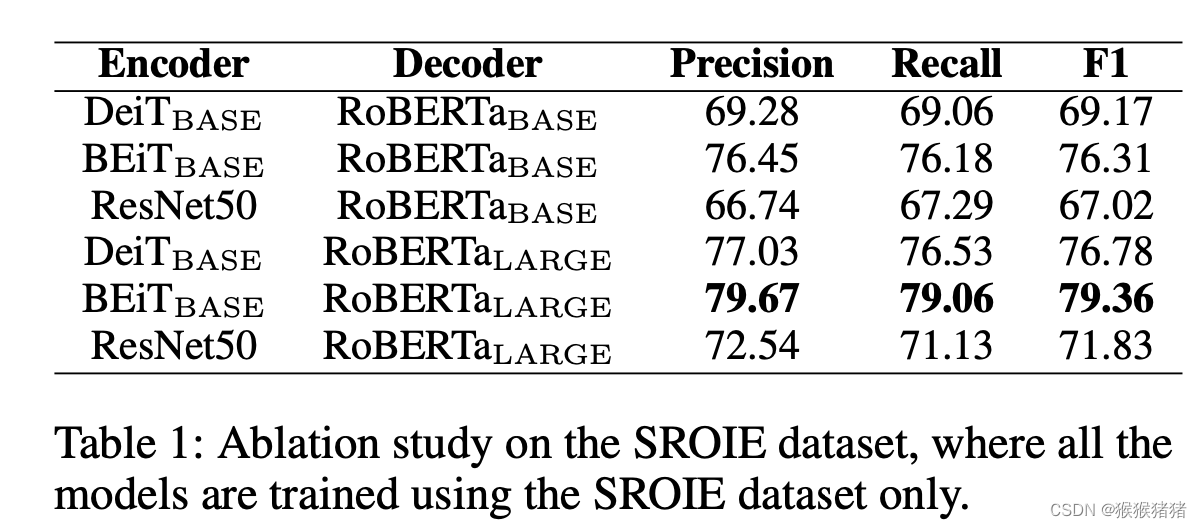
decoder的话,是roberta large表现最好。
TrOCRSMALL (total parameters=62M) consists of the encoder of DeiT SMALL and the decoder of MiniLM,
TrOCRBASE (total parameters=334M) consists of the en- coder of BEiT BASE and the decoder of RoBERTa LARGE
TrOCRLARGE (total parameters=558M) consists of the en- coder of BEiT LARGE and the decoder of RoBERTa LARGE.3.2.2 Ablation Experiment
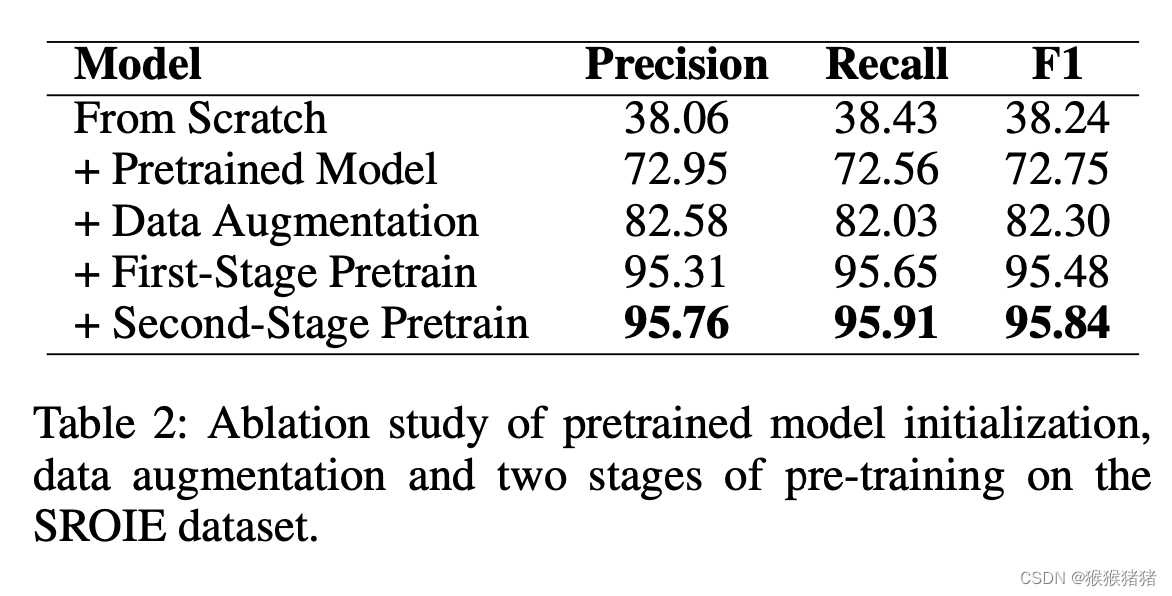
3.2.3 SROIE Task 2
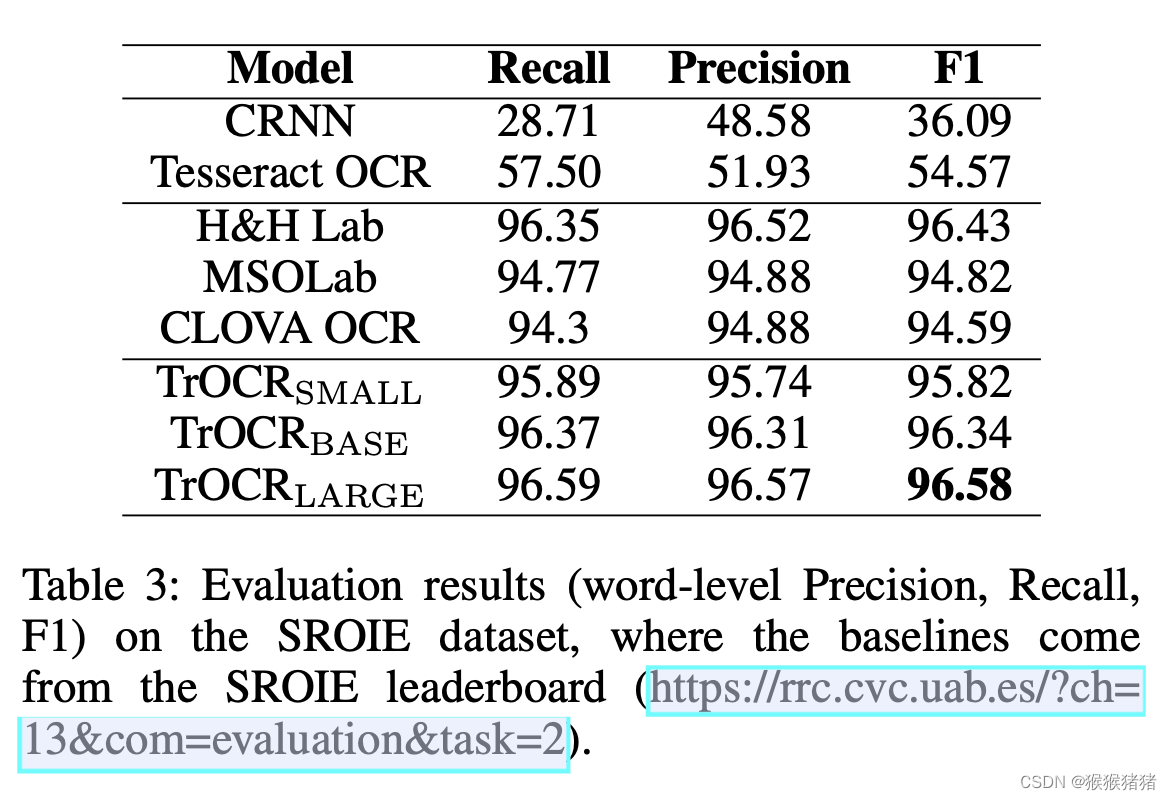 与cnn + rnn的一些方法进行对比
与cnn + rnn的一些方法进行对比
3.2.4 IAM Handwriting Database
3.2.5 Scene Text Recognition
3.2.6 Inference Speed
