
【C++入门基础(上)】
Cross the stars over the moon to meet your better-self.

目录
1 命名空间
1.1 命名空间定义
1.2 命名空间使用
1.2.1 加命名空间名称及作用域限定符
1.2.2 使用using将命名空间中成员引入
1.2.3 使用using namespace 命名空间名称引入
2 C++输入&&输出
3 缺省参数
3.1 全缺省参数
3.2 半缺省参数
4. 函数重载
4.1 函数重载概念
4.2 名字修饰(name Mangling)
5 总结
1 命名空间
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
1.1 命名空间定义
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{}中即为命名空间的成员。
我们可以来举一些例子:
#include
#includeint rand = 1;
int main()
{printf("%d\n", rand);return 0;
} 为啥这段代码会报错呢?
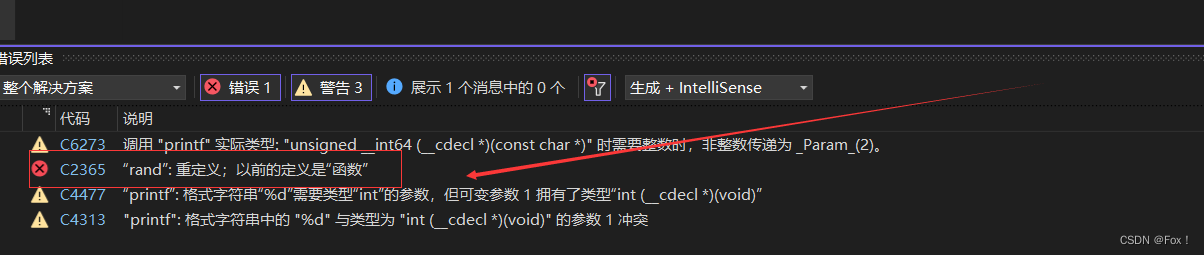
经过分析我们不难发现我们自己定义的rand与官方库里定义的rand函数冲突了,解决方法就是用命名空间来隔离我们所定义的变量或者函数:
namespace grm
{int rand = 1;
}我们发现这样就可以编译通过了。
注意:
1 命名空间中的内容,既可以定义变量,也可以定义函数;
2 命名空间可以嵌套 ;
3 同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中。像下面这两种方式都是合理的:
// 命名空间可以嵌套
namespace grm
{int a;int b;int Add(int left, int right){return left + right;}namespace N3{int c;int d;int Sub(int left, int right){return left - right;}}
}而且最后编译器会将同一个工程中相同的命名空间合并为一个命名空间。但是值得注意的是一旦命名空间中变量定义了就不可以在命名空间中修改:
这样都会导致编译器报错的。
一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中。这句话的意思简单点来说就是我们自己定义的命名空间就是一个隔离区,不会与库里面的变量或者函数发生冲突,那么应该如何使用命名空间呢?1.2 命名空间使用
1.2.1 加命名空间名称及作用域限定符
什么是作用域限定符呀?
:: (两个冒号)
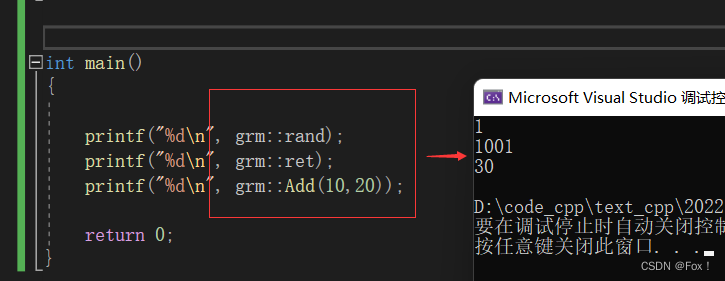
namespace grm
{int rand = 1;int ret = 1001;int Add(int x, int y){return x + y;}
}int main()
{printf("%d\n", grm::rand);printf("%d\n", grm::ret);printf("%d\n", grm::Add(10,20));return 0;
}
1.2.2 使用using将命名空间中成员引入
#include
//#includenamespace grm
{int rand = 1;int ret = 1001;int Add(int x, int y){return x + y;}
}using grm::rand;
using grm::Add;
int main()
{printf("%d\n", rand);printf("%d\n", grm::ret);printf("%d\n", Add(10,20));return 0;
} 这个时候记得把库里面的rand给屏蔽了,不然就会冲突。
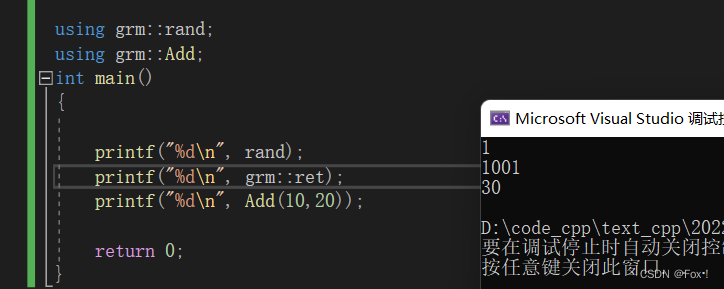
1.2.3 使用using namespace 命名空间名称引入
这种方式最为简单,但是不推荐在工程里面用,否则可能会发生命名冲突的问题,平常的代码练习可以这样做(因为代码量不会太大,一般不会冲突)
using namespace grm;
int main()
{printf("%d\n", rand);printf("%d\n", ret);printf("%d\n", Add(10,20));return 0;
}2 C++输入&&输出
#includeint main()
{int i;char c;double d;std::cin >> i >> c >> d;std::cout << i << " " << c << " " << d << std::endl;return 0;
} 说明:
1. 使用cout标准输出(控制台)和cin标准输入(键盘)时,必须包含< iostream >头文件以及std标准命名空间。 注意:早期标准库将所有功能在全局域中实现,声明在.h后缀的头文件中,使用时只需包含对应头文件即可,后来将其实现在std命名空间下,为了和C头文件区分,也为了正确使用命名空间,规定C++头文件不带.h;旧编译器(vc 6.0)中还支持格式,后续编译器已不支持,因此推荐使用 +std 的方式。 2. 使用C++输入输出更方便,不需增加数据格式控制,比如:整形--%d,字符--%c 3 其中<< 表示流插入符 >>表示流提取符。 4 endl表示换行。
但是上面老是用std::很麻烦,平常练习中我们为了轻松一点儿可以直接用
using namespace std 直接将库中所有的函数和变量都引出来,但是在工程中并不推荐这样做。
#include
using namespace std;
int main()
{int i;char c;double d;cin >> i >> c >> d;cout << i << " " << c << " " << d << endl;return 0;
} 我们发现了用cin && cout居然不用管变量的类型是啥,不像C语言还得记住整形用%d 字符用%c 等等。但是万事也不是绝对,有时用scanf && printf比用cin && cout要简单些,具体情况具体分析,一般来说,哪种方便用哪个,甚至还可以组合使用。
3 缺省参数
大家知道什么是备胎吗?

缺省参数差不多就是充当备胎这么一个角色
而缺省型参数又分为全缺省参数和半缺省参数。
3.1 全缺省参数
#include
using namespace std;int Add(int x = 10, int y = 20, int z = 30)
{return x + y + z;
}
int main()
{cout << Add(1, 2, 3) << endl;cout << Add(1, 2) << endl;cout << Add(1) << endl;cout << Add( ) << endl;return 0;
} 输出结果:
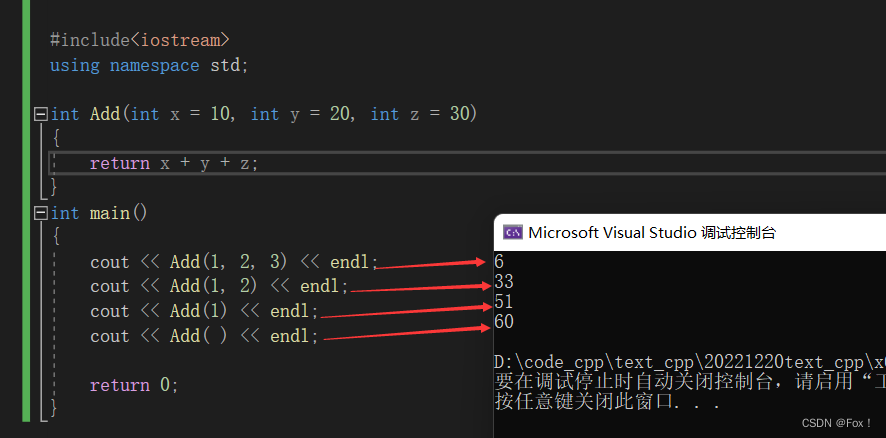
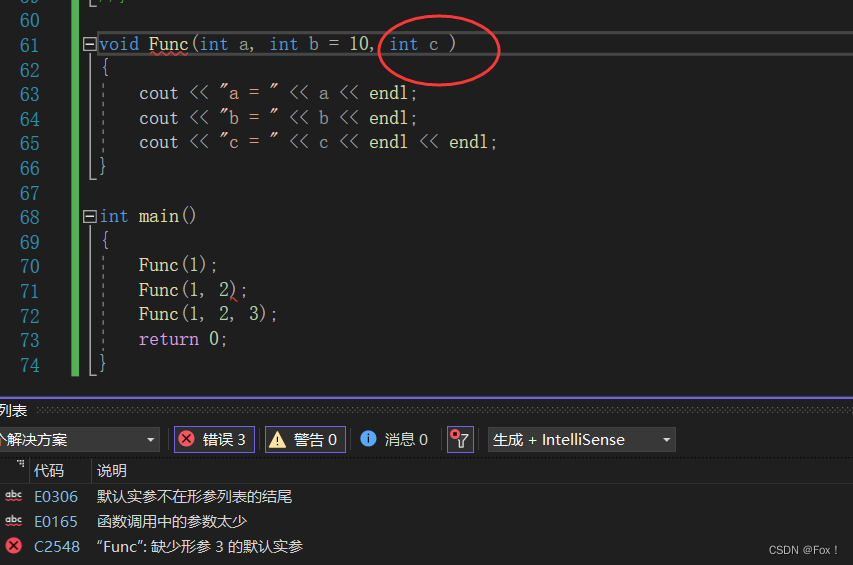
我们发现参数的接受是从左到右的。
3.2 半缺省参数
void Func(int a, int b = 10, int c = 20)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl << endl;
}int main()
{Func(1);Func(1, 2);Func(1, 2, 3);return 0;
}
2. 缺省参数不能在函数声明和定义中同时出现
我们重新定义一个Func.h的头文件,将Func的声明放进去,然后编译: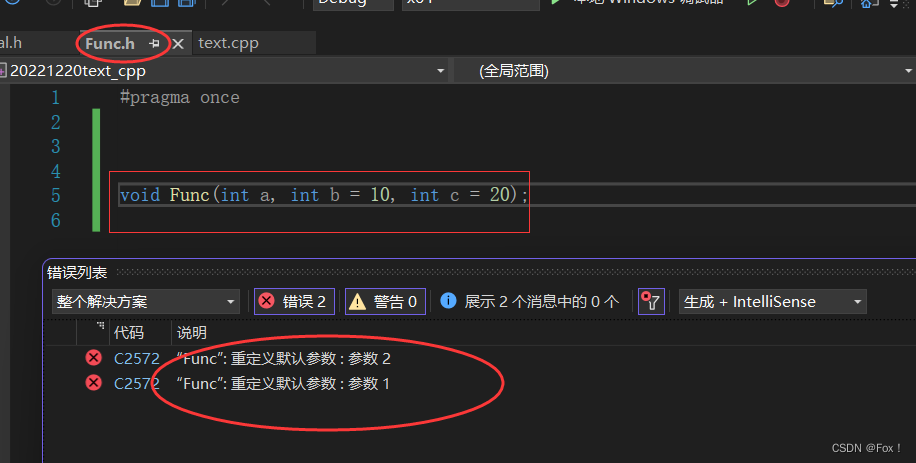
我们只需要将缺省参数放在其中一个就行了,一般是定义在声明中。
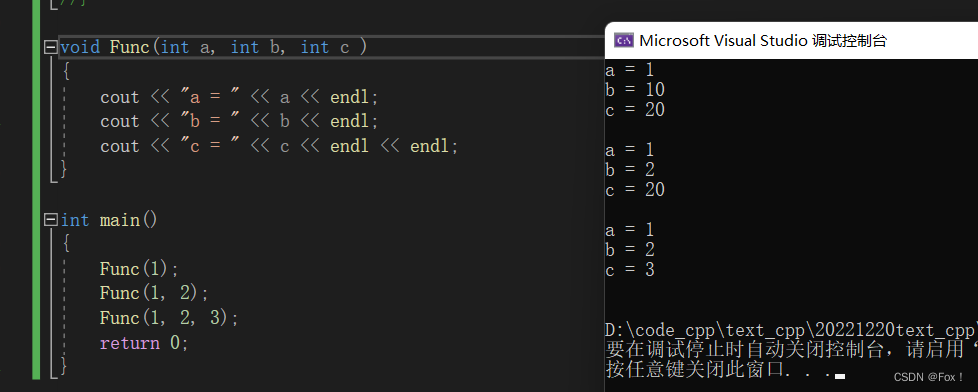
3. 缺省值必须是常量或者全局变量
4. C语言不支持(编译器不支持)
4. 函数重载
自然语言中,一个词可以有多重含义,人们可以通过上下文来判断该词真实的含义,即该词被重载了。比如:以前有一个笑话,国有两个体育项目大家根本不用看,也不用担心。一个是乒乓球,一个是男足。前者是“谁也赢不了!”,后者是“谁也赢不了!”
4.1 函数重载概念
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 顺序)必须不同,常用来处理实现功能类似数据类型不同的问题.
int Add(int left, int right)
{return left + right;
}int Add(int left, char right)
{return left + right;
}int Add(char right, int left)
{return left + right;
}int Add(char right, int left, int mid)
{return left + right + mid;
}int main()
{cout << Add(1, 2) << endl;cout << Add(1, 'a') << endl;cout << Add('a', 1) << endl;cout << Add(1, 'a', 2) << endl;return 0;
}上面这些都构成函数重载:
但是这种呢?
int Add(int left, int right)
{return left + right;
}char Add(int left, int right)
{return left + right;
}
int main()
{Add(1, 3);return 0;
}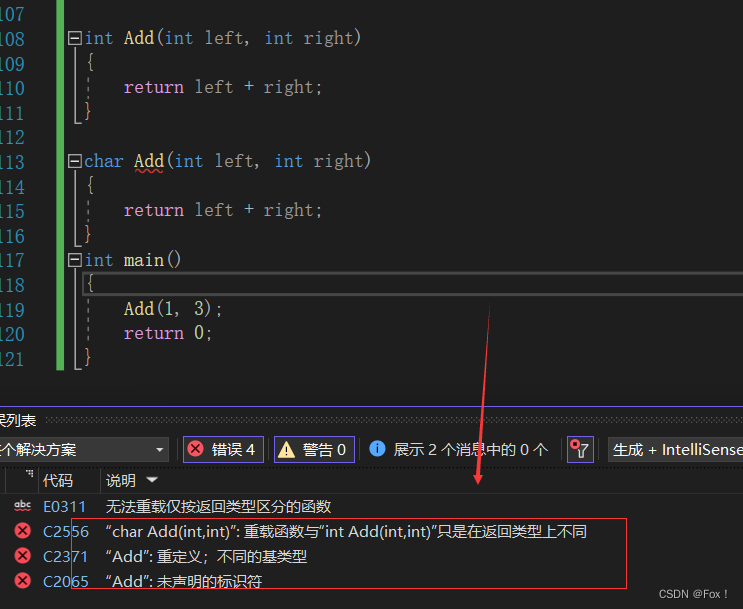
很明显,此时编译器就报了错误。注意:返回值不同不能构成重载。因为函数调用时你不知道到底要调用哪一个。
这种能构成重载吗?
void f()
{cout << "f( )" << endl;
}void f(int x = 0)
{cout << "f( x=0 )" << endl;
}我们编译一下代码发现能够跑过,说明这是构成重载的,但是如果你调用该函数带上参数还好,如果不带参数那编译器就不知道要调用哪个函数了,这是就会报错。
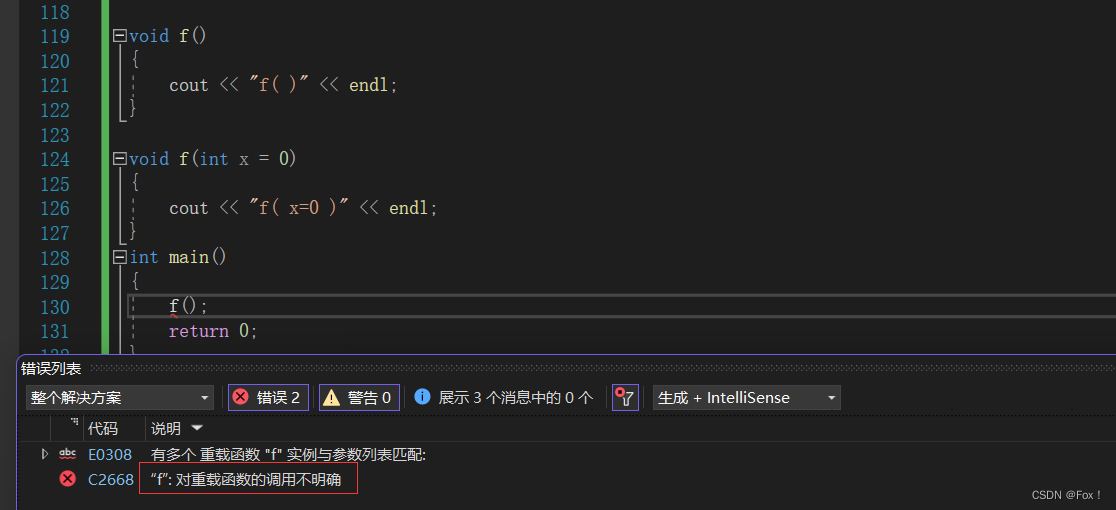
4.2 名字修饰(name Mangling)
为什么C++支持函数重载,而C语言不支持函数重载呢?
1. 实际我们的项目通常是由多个头文件和多个源文件构成,而通过我们C语言阶段学习的编译链接,我们可以知道,【当前a.cpp中调用了b.cpp中定义的Add函数时】,编译后链接前,a.o的目标文件中没有Add的函数地址,因为Add是在b.cpp中定义的,所以Add的地址在b.o中。那么怎么办呢? 2. 所以链接阶段就是专门处理这种问题,链接器看到a.o调用Add,但是没有Add的地址,就会到b.o的符号表中找Add的地址,然后链接到一起。 3. 那么链接时,面对Add函数,链接器会使用哪个名字去找呢?这里每个编译器都有自己的函数名修饰规则。 4. 由于Windows下vs的修饰规则过于复杂,而Linux下gcc的修饰规则简单易懂,下面我们使用了gcc演示了这个修饰后的名字。 5. 通过下面我们可以看出gcc的函数修饰后名字不变。而g++的函数修饰后变成【_Z+函数长度+函数名+类型首字母】。 采用C语言编译器编译后结果 :在C/C++中,一个程序要运行起来,需要经历以下几个阶段:预处理、编译、汇编、链接。
有关具体的详解可以参考我的这篇博客程序环境和预处理
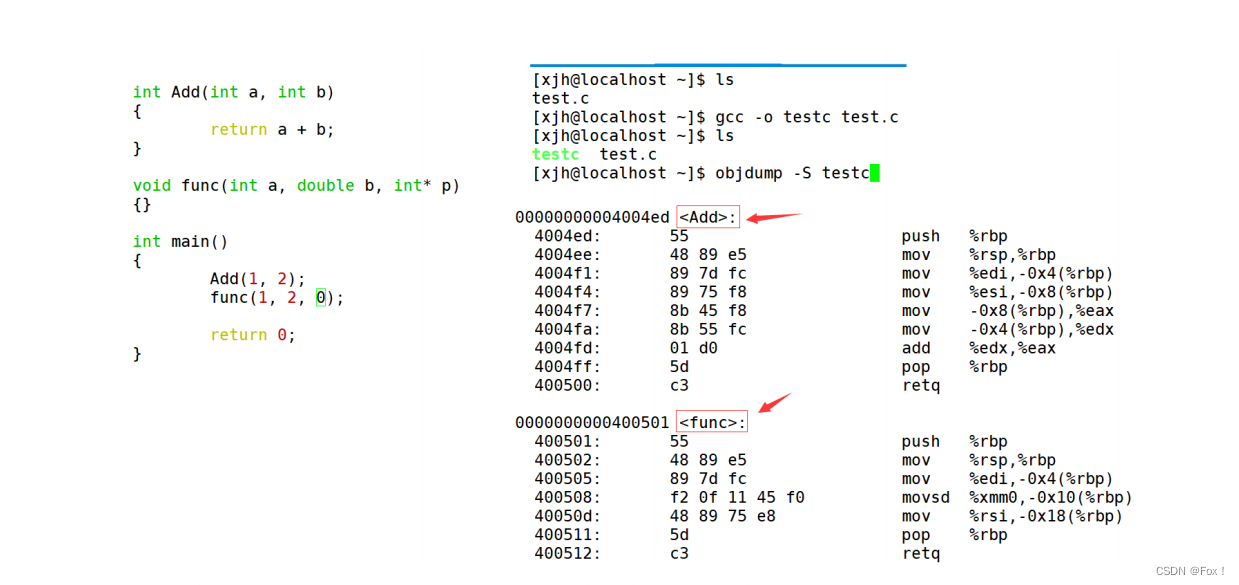 结论:在linux下,采用gcc编译完成后,函数名字的修饰没有发生改变。
采用C++编译器编译后结果 :
结论:在linux下,采用gcc编译完成后,函数名字的修饰没有发生改变。
采用C++编译器编译后结果 :
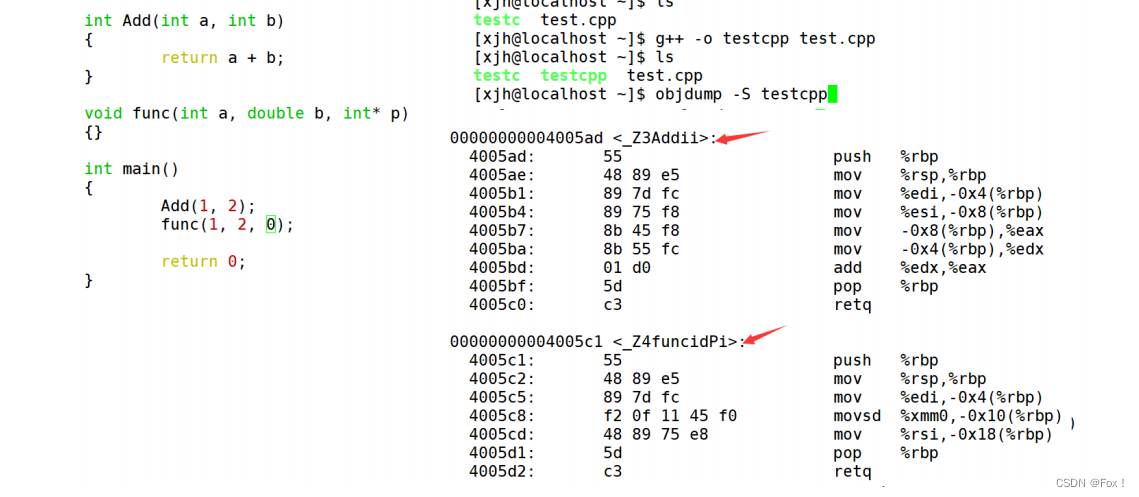 结论:在linux下,采用g++编译完成后,函数名字的修饰发生改变,编译器将函数参数类型信息
添加到修改后的名字中。
Windows下名字修饰规则 :
结论:在linux下,采用g++编译完成后,函数名字的修饰发生改变,编译器将函数参数类型信息
添加到修改后的名字中。
Windows下名字修饰规则 :
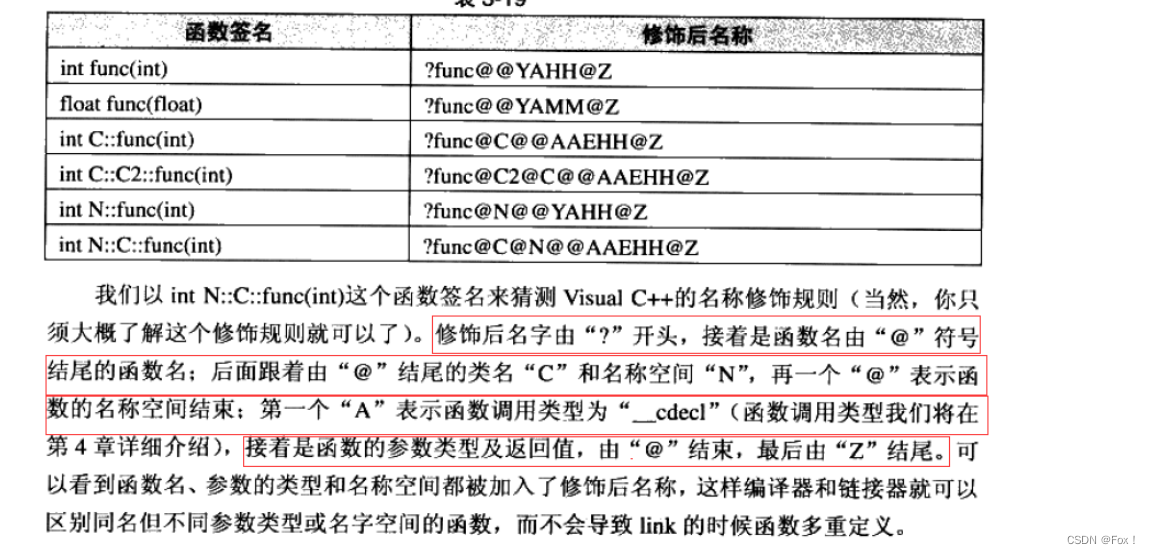
对比Linux会发现,windows下C++编译器对函数名字修饰非常诡异,但道理都是一样的。
【扩展学习:C/C++函数调用约定和名字修饰规则】
C++函数重载
C++调用约定 这里大家有兴趣了解下就好。 6. 通过这里就理解了C语言没办法支持重载,因为同名函数没办法区分。而C++是通过函数修饰规则来区分,只要参数不同,修饰出来的名字就不一样,就支持了重载。 7. 另外我们也理解了,为什么函数重载要求参数不同!而跟返回值没关系。 面试题: 1. 下面两个函数能形成函数重载吗?有问题吗或者什么情况下会出问题?void TestFunc(int a = 10)
{cout<<"void TestFunc(int)"<2. C语言中为什么不能支持函数重载?回答:很明显这两个函数是无法构成函数重载的,因为参数个数 或 类型 或 顺序是相同的,传了参数后也无法识别调用哪一个函数。
回答:因为编译的时候两个重载函数的函数名相同,符号表中会存在歧义和冲突,其次在链接时也会有冲突,因为他们都是直接用函数名去标识和查找。
3. C++中函数重载底层是怎么处理的?
回答:因为C++不是直接用函数名去标识和查找函数的,而是用函数名修饰规则,只要参数的个数,类型,顺序不同,符号表的函数就不会存在歧义和冲突了,链接时去调用两个重载函数查找地址时也是明确的。
5 总结
本文介绍了命名空间的定义和使用,C++输入输出的使用,缺省参数以及函数重载,重点讲解了函数重载是怎样实现的以及C语言不支持函数重载C++支持函数重载的原因。引用将放在下一篇博客来讲。
如果该文对你有用,能不能一键3连支持一下播主呢

上一篇:中国计算机大会CNCC【笔记】