
软件实施面试专业技能试题
注:关于项目实施方面的资料少之又少,分享一篇很不错的面试题供参考,基本上是一些经常碰到的。
1、作为一个软件实施工程师你的职责是什么?该岗位需要具备什么样的能力?
解答:
推广公司的产品,现场为客户实施安装
熟悉公司的产品,现场对客户进行培训
2、你熟悉的远程有哪些方法?各种方法应该怎么配置? 解答:Windows:常见的QQ远程桌面,或者用QQ办公版TIM。或者采取有远程桌面功能的软件,或者其它OA办公系统。最终达到预期目标,采用远程协助达成客户需求。win10还有自带的远程桌面 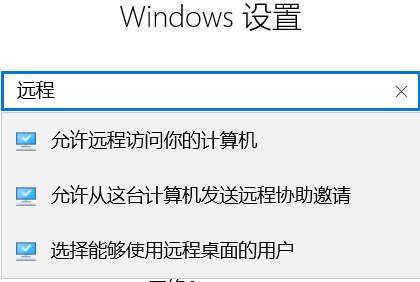
开启远程桌面协助 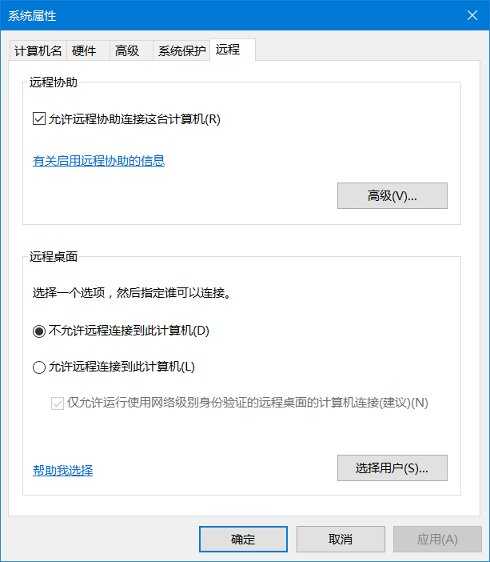
快捷键win + r打开任务输入mstsc命令打开远程桌面。
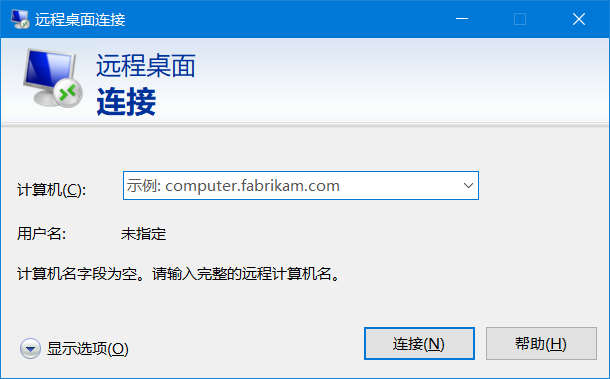 关于远程桌面补充一些个人工作中使用过的。有桌面也有服务器版,个人主要在Windows平台使用:
关于远程桌面补充一些个人工作中使用过的。有桌面也有服务器版,个人主要在Windows平台使用:
向日葵
ToDesk
TeamViewer目前个人更趋向于向日葵,更轻更快,客户下载体验友好一些。云端远程桌面,个人主要在Linux平台使用:UltraVNCVNC-Viewer(realVNC)Linux发行版操作系统使用ssh远程连接:Xshell(个人版免费使用);SecureCRT;Putty(免费);tabby(开源的多终端集合)等等,只要能实现ssh连接的终端工具。 FinalShell:这款优势带有监控cpu和内存使用情况图形化界面。文件传输工具:WinSCP-5.11.2-Setup。 
3、在你进行实施的过程中,公司制作的一款软件系统缺少某一项功能,而且公司也明确表示不会再为系统做任何的修改或添加任何的功能,而客户也坚决要求需要这一项功能!对于实施人员来说,应该怎么去合理妥善处理这个问题?解答:首先看用户要求合不合理,不合理就坚决退还需求,如果需求合理,可以申请二次开发,需要考虑公司的利益。然后综合考虑客户的重量级,对客户强调合同成本,外加某一项功能需要耗费的人力物力是需要付出额外的成本的。最后考虑第三方软件补助。4、如销售签有一外地客户,要求实施人员在客户现场一周内完成所有项目实施,而标准实施一般为期一个月,针对以上情况实施人员应该如何应对? 解答:标准实施为一个月,那就按签订的合同行事。然后考虑这个项目一周完成,在当前的人力和时间成本下是否可行。如果想加快进度可以与公司沟通,额外派人,与客户客户协商额外的劳动成本。5、在项目实施过程中,使用者对产品提出了适合自己习惯的修改意见,但多个使用者相互矛盾,应该如何去处理?解答:采用求同存异法。对于客户的意见,我们实施人员应该有自己的实施方案。当使用者意见出现不一致时候,引导客户内部意见达到统一和用户经过沟通确认后,找到切实可行的方案,双方认可并达成共识。6、系统启动后,不能连接数据库,可能是哪些方面的原因? 解答:检查网络原因;检查数据库服务是否启动;数据库文件是否被破坏;数据库端口号问题(防火墙是否放通)7、如果有一个不太懂电脑的客户,你应该采取什么样的方法去教他用公司的软件产品? 解答:首先教客户熟悉基本的电脑操作,然后参考相关文档操作,实际根据软件的复杂程度去教会客户熟悉使用公司产品。遵循由易到难,简单的可以直接教会客户熟悉运用。复杂的一步一步是jio印。也可以做其它的补足:制作ppt;图文操作文档;录制视频。8、针对于已有5年以上的客户,其产生的历史数据可以怎么处理?解答:综合考虑客户的重量级;重量级客户,提前计划,做好用户数据的备份。一切从公司的利益考虑。9、一般数据库若出现日志满了,会出现什么情况,是否还能使用? 解答:只能执行查询等读取操作。不能执行修改,备份等写操作,原因是任何写操作都要记录日志。数据库本就是需要承载读写操作的,也就是说基本上处于不能使用的状态。02 SQL实际操作题10、已知A、B两表A.id=B.AID请分别写出内外链接的sql语句,并说明区别? 解答:内连接关键字inner join on;内连接取A和B的交集公共部分。外连接关键字:left join on,right join on。外连接分左外连接和右外连接,左外连接以左表为主,右外连接以右表为主。参考下图,以数学集合的思想来思考更加清晰明了。注意:外连接是可以省略outer关键字的,例如:左外连接left outer join 简写为left join,右外连接同理,后面配合on关键字。二、SQL中的联合查询图解1、内连接内连接:inner join on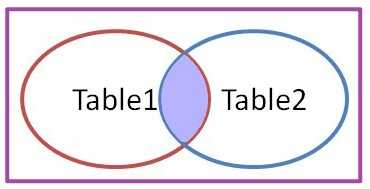 2、左外连接左外连接:省略掉了outer,下同。left join on
2、左外连接左外连接:省略掉了outer,下同。left join on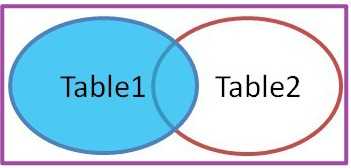 3、右外连接右外连接:right join on
3、右外连接右外连接:right join on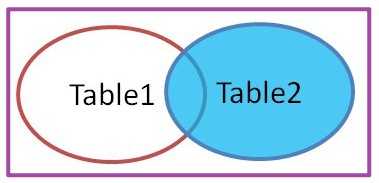 关联查询有6种,常用的两种,内连接和外连接。个人实际工作中内连接使用更多,具体视工作情况而定。这里不做详细说明,网上教程很多,可以自行参考。4、可参考资料菜鸟教程直通车:https://www.runoob.com/mysql/mysql-join.html面试了几家招软件实施的,基本上前几道笔试题是考量你的现场应变能力,后几道笔试题是考量你对SQL的运用,关联查询这方面的试题居多。软件实施一般是需要去固定的场所驻场的,需要有自己的一套方案。也需要结合现场的实际情况,灵活变通运用。这行业是需要靠长期的累积行业经验的,不是一蹴而就的。--------------------------更新后的补充--------------------------第二部分《面试进阶,实际工作篇》之前一些实际SQL操作,我直接引用了别人一些教程链接,发现在打广告就删掉了。引用菜鸟教程依旧保留,毕竟这货干净简洁。思来想去,还是自己重新补充一些,毕竟Oracle方面的教程都比较久远了。以后可能不会像这样将具体内容更新进来了,会以链接形式发自己的面经和时间工作经验总结。当然,此次更新的内容也将以单篇发布出来。官方提供的sakila和world数据库,官网下载地址已经提供,可以下载进行参考学习。sakila-db数据库包含三个文件:sakila-schema.sql:数据库表结构sakila-data.sql:数据库示例模拟数据sakila.mwb:数据库物理模型,在MySQL workbench中可以打开查看。https://downloads.mysql.com/docs/sakila-db.zip world-db数据库,表结构与data数据包含在一起:https://downloads.mysql.com/docs/world-db.zip Oracle11g安装后自带有scott用户,可以用来练习。主要用到的是EMP和DEPT表,想起了当年用Java的ssh框架写的第一个CURD的demo示例就是Oracle的这两张表,因为这两表有关联关系。EMP:员工表;DEPT:部门表;我的测试环境基于:操作系统:Windows10;数据库:MySQL8.0.28和Oracle11g;使用查询工具:MySQL8.0自带命令行以及Oracle自带的SQLplus;第三方工具SQLyog和PLSQL Developer。三、联合查询图解联合查询内连接:统计的内容是table1和table2的重合部分。inner join on左外连接:可以省略掉outer,统计的内容是以table1为主的部分。left outer join on右外连接:同样可以省略掉outer,统计的内容是以table2为主的部分。right outer join on1、联合查询1.1、MySQL中的联合查询示例inner join on:内连接right join on:右外连接left join on:左外连接MySQL中的内连接查询关键字:inner join on,只作为演示,就不执行explain执行计划去判断执行效率了。小小的建议,在测试这些个联合查询的时候,可以不用带太多的过滤条件看看三种联合查询的区别。SELECT c.
关联查询有6种,常用的两种,内连接和外连接。个人实际工作中内连接使用更多,具体视工作情况而定。这里不做详细说明,网上教程很多,可以自行参考。4、可参考资料菜鸟教程直通车:https://www.runoob.com/mysql/mysql-join.html面试了几家招软件实施的,基本上前几道笔试题是考量你的现场应变能力,后几道笔试题是考量你对SQL的运用,关联查询这方面的试题居多。软件实施一般是需要去固定的场所驻场的,需要有自己的一套方案。也需要结合现场的实际情况,灵活变通运用。这行业是需要靠长期的累积行业经验的,不是一蹴而就的。--------------------------更新后的补充--------------------------第二部分《面试进阶,实际工作篇》之前一些实际SQL操作,我直接引用了别人一些教程链接,发现在打广告就删掉了。引用菜鸟教程依旧保留,毕竟这货干净简洁。思来想去,还是自己重新补充一些,毕竟Oracle方面的教程都比较久远了。以后可能不会像这样将具体内容更新进来了,会以链接形式发自己的面经和时间工作经验总结。当然,此次更新的内容也将以单篇发布出来。官方提供的sakila和world数据库,官网下载地址已经提供,可以下载进行参考学习。sakila-db数据库包含三个文件:sakila-schema.sql:数据库表结构sakila-data.sql:数据库示例模拟数据sakila.mwb:数据库物理模型,在MySQL workbench中可以打开查看。https://downloads.mysql.com/docs/sakila-db.zip world-db数据库,表结构与data数据包含在一起:https://downloads.mysql.com/docs/world-db.zip Oracle11g安装后自带有scott用户,可以用来练习。主要用到的是EMP和DEPT表,想起了当年用Java的ssh框架写的第一个CURD的demo示例就是Oracle的这两张表,因为这两表有关联关系。EMP:员工表;DEPT:部门表;我的测试环境基于:操作系统:Windows10;数据库:MySQL8.0.28和Oracle11g;使用查询工具:MySQL8.0自带命令行以及Oracle自带的SQLplus;第三方工具SQLyog和PLSQL Developer。三、联合查询图解联合查询内连接:统计的内容是table1和table2的重合部分。inner join on左外连接:可以省略掉outer,统计的内容是以table1为主的部分。left outer join on右外连接:同样可以省略掉outer,统计的内容是以table2为主的部分。right outer join on1、联合查询1.1、MySQL中的联合查询示例inner join on:内连接right join on:右外连接left join on:左外连接MySQL中的内连接查询关键字:inner join on,只作为演示,就不执行explain执行计划去判断执行效率了。小小的建议,在测试这些个联合查询的时候,可以不用带太多的过滤条件看看三种联合查询的区别。SELECT c.ID,c.CountryCode,cl.CountryCode,cl.Language
FROM world.city c INNER JOIN world.countrylanguage cl
ON c.CountryCode=cl.CountryCode WHERE c.ID>120 AND c.ID LIMIT 0,5;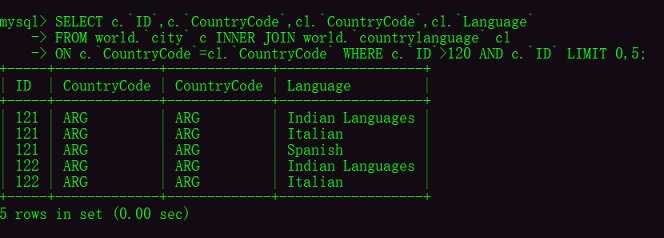 MySQL中的左外连接查询查询关键字:LEFT OUTER JOINSELECT c.
MySQL中的左外连接查询查询关键字:LEFT OUTER JOINSELECT c.ID,c.Name,c.CountryCode,cl.IsOfficial,cl.CountryCode,cl.Language
FROM world.city c LEFT OUTER JOIN world.countrylanguage cl
ON c.CountryCode=cl.CountryCode LIMIT 0,5;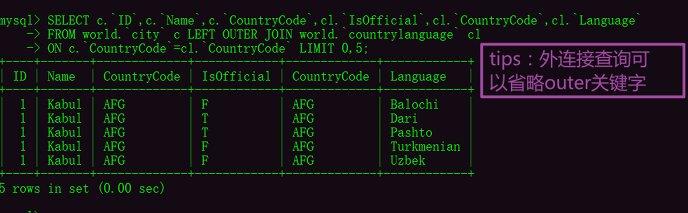 MySQL中的右外连接查询关键字:RIGHT OUTER JOINSELECT c.
MySQL中的右外连接查询关键字:RIGHT OUTER JOINSELECT c.ID,c.Name,c.CountryCode,cl.IsOfficial,cl.CountryCode,cl.Language
FROM world.city c RIGHT OUTER JOIN world.countrylanguage cl
ON c.CountryCode=cl.CountryCode LIMIT 0,5;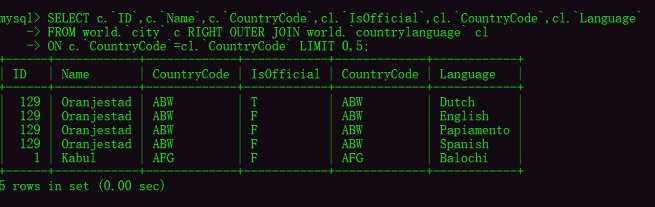 1.2、Oracle中的联合查询示例主要以SCOTT用户作为示例,查看SCOTT用户下有哪些表,这种方式需要以dba管理员身份运行SQL语句查询:ower代表了用户名,所以直接查找SCOTT用户,TABLE_NAME:代表了表名。select t.OWNER,t.TABLE_NAME,t.TABLESPACE_NAME from dba_tables t where t.OWNER=‘SCOTT’;
1.2、Oracle中的联合查询示例主要以SCOTT用户作为示例,查看SCOTT用户下有哪些表,这种方式需要以dba管理员身份运行SQL语句查询:ower代表了用户名,所以直接查找SCOTT用户,TABLE_NAME:代表了表名。select t.OWNER,t.TABLE_NAME,t.TABLESPACE_NAME from dba_tables t where t.OWNER=‘SCOTT’; Oracle中的联合查询,同样以员工表(emp)和部门表(dept)进行演示操作。Oracle中的内连接:inner join on根据部门编号进行关联查询,进行分页查询,每页显示5条数据:select e.ename,e.empno,d.deptno,d.dname from scott.emp e
Oracle中的联合查询,同样以员工表(emp)和部门表(dept)进行演示操作。Oracle中的内连接:inner join on根据部门编号进行关联查询,进行分页查询,每页显示5条数据:select e.ename,e.empno,d.deptno,d.dname from scott.emp e
inner join scott.dept d on e.deptno=d.deptno where rownum<=5; 左外连接:left outer join onselect e.ename,e.empno,d.deptno,d.dname from scott.emp e
左外连接:left outer join onselect e.ename,e.empno,d.deptno,d.dname from scott.emp e
left outer join scott.dept d on e.deptno=d.deptno where rownum<=5; 右外连接:right outer join onselect e.ename,e.empno,d.deptno,d.dname from scott.emp e
右外连接:right outer join onselect e.ename,e.empno,d.deptno,d.dname from scott.emp e
right outer join scott.dept d on e.deptno=d.deptno where rownum<=5; 全连接:full join onselect e.ename,e.empno,d.deptno,d.dname from scott.emp e
全连接:full join onselect e.ename,e.empno,d.deptno,d.dname from scott.emp e
full join scott.dept d on e.deptno=d.deptno where rownum<=5; 组合查询:unionselect e.ename,e.empno from scott.emp e where rownum<=5 union select e.ename,e.empno from scott.emp e
组合查询:unionselect e.ename,e.empno from scott.emp e where rownum<=5 union select e.ename,e.empno from scott.emp e
where e.ename like ‘%ARC%’; 组合查询:union allselect e.ename,e.empno from scott.emp e where rownum<=5 union all select e.ename,e.empno from scott.emp e
组合查询:union allselect e.ename,e.empno from scott.emp e where rownum<=5 union all select e.ename,e.empno from scott.emp e
where e.ename like ‘%ARC%’; union和union all是有区别的,我列举的例子进行了模糊匹配,没演示出来效果。使用union all后DBMS不会取消重复的行。去掉后面的like条件,使用union统计的数据为14行,使用union all统计的数据为19行,其实不难理解,all就是全部。2、分页查询2.1、MySQL的分页查询使用limit关键字tips:Windows中CMD命令窗口使用color a即可调用出黑色背景绿色字体,color f0则是快速调出白色背景黑色字体哟!护眼色:R:181 G:230 B:181示例:使用world数据库中city表进行演示分页查询,通过desc展示数据结构,尤其是配合开发进行联调的时候很常用:mysql> desc world.city;
union和union all是有区别的,我列举的例子进行了模糊匹配,没演示出来效果。使用union all后DBMS不会取消重复的行。去掉后面的like条件,使用union统计的数据为14行,使用union all统计的数据为19行,其实不难理解,all就是全部。2、分页查询2.1、MySQL的分页查询使用limit关键字tips:Windows中CMD命令窗口使用color a即可调用出黑色背景绿色字体,color f0则是快速调出白色背景黑色字体哟!护眼色:R:181 G:230 B:181示例:使用world数据库中city表进行演示分页查询,通过desc展示数据结构,尤其是配合开发进行联调的时候很常用:mysql> desc world.city;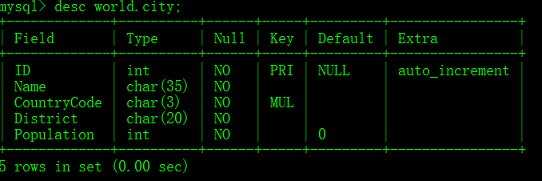 查询world数据库中的city表前5条数据:mysql> select * from city limit 0,5;
查询world数据库中的city表前5条数据:mysql> select * from city limit 0,5;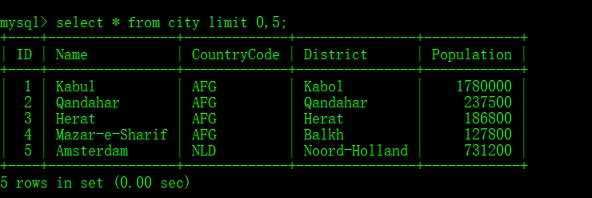 2.2、Oracle的分页查询使用rownum伪列同样使用desc关键字查询emp表结构:SQL> desc scott.emp;
2.2、Oracle的分页查询使用rownum伪列同样使用desc关键字查询emp表结构:SQL> desc scott.emp;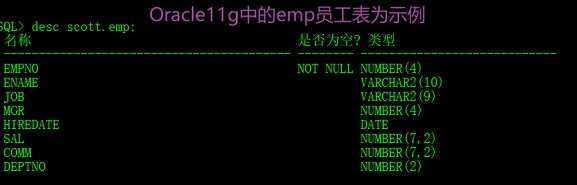 分页查询示例:使用rownum关键字进行演示Oracle中的分页查询。查询scott用户中emp(员工表)的员工empno:编号、ename:员工姓名以及伪列rowid,只查询前5条数据:SQL> select t.rowid,t.empno,t.ename from scott.emp t where rownum <=5;
分页查询示例:使用rownum关键字进行演示Oracle中的分页查询。查询scott用户中emp(员工表)的员工empno:编号、ename:员工姓名以及伪列rowid,只查询前5条数据:SQL> select t.rowid,t.empno,t.ename from scott.emp t where rownum <=5; Oracle进行分页查询常用方式一,查询第6~11数据通过嵌套子查询,使用到关键字rownum和where:-- 统计emp数据总条目数
Oracle进行分页查询常用方式一,查询第6~11数据通过嵌套子查询,使用到关键字rownum和where:-- 统计emp数据总条目数
select count() from scott.emp;
– 查询第6~11数据通过嵌套子查询,使用到关键字rownum和where
select * from (select scott.emp.empno,rownum r from scott.emp Where rownum<=11)where r>=6;Oracle进行分页查询常用方式二,先进行order by排序,再分页查询,查询第6~11数据:-- 先进行排序
select * from emp e order by e.empno Desc;
– 再进行分页
select * from (select e.,rownum r_num from(select * from scott.emp e order by e.empno desc )e)b where b.r_num between 6 and 11;四、聚合函数(Aggregate)下面所讲的函数大多数标准SQL数据库是支持的,但也要依据实际情况做测试验证,个人主要验证的是MySQL和Oracle。重点:count、sum函数在我们如果要迁移数据的时候,避免不了需要手动去统计求和对比迁移前后数据的一致性。1、常见的聚合函数介绍几个聚合函数:count函数用于统计条目数;sum函数用于求和;substr函数用于截取;avg函数用于取平均值;max函数用于取最大值;min函数用于取最小值。如下则演示同时使用多个函数,查询Oracle数据库scott用户的emp表:查询出来的结果:count统计员工总数,sum求和所有员工的薪水总额,avg统计所有员工平均薪水,substr则是截取到小数点后两位数。-- count:统计条目数,sum:求和,substr:截取,avg:取平均值
select count(), sum(t.sal), substr(avg(t.sal), 0, 7) from scott.emp t; 返回平均值avg,一般配合substr关键字去截取,通过计算保留小数点后两位。统计某公司员工的平均薪资:-- avg:取平均值
返回平均值avg,一般配合substr关键字去截取,通过计算保留小数点后两位。统计某公司员工的平均薪资:-- avg:取平均值
select avg(t.sal) from scott.emp t;
select substr(avg(t.sal), 0, 7) from scott.emp t; 返回统计行数count统计某公司员工总数:-- 统计函数count:统计emp表条目数量14
返回统计行数count统计某公司员工总数:-- 统计函数count:统计emp表条目数量14
select count() from scott.emp; 返回总数(求和)sum,sum函数一般会配合decode函数使用。上面的黑色背景看久了眼睛累,特意换了一种护眼色。字体颜色就没有特意更换,字体稍微点大了一丢丢,看的更舒服。统计某公司所有员工薪资总和:-- 求和函数sum的使用
返回总数(求和)sum,sum函数一般会配合decode函数使用。上面的黑色背景看久了眼睛累,特意换了一种护眼色。字体颜色就没有特意更换,字体稍微点大了一丢丢,看的更舒服。统计某公司所有员工薪资总和:-- 求和函数sum的使用
select sum(t.sal) from scott.emp t;
– 配合decode函数使用
select sum(decode(ename, ‘SMITH’, sal, 0)) SMITH,sum(decode(ename, ‘ALLEN’, sal, 0)) ALLEN,
sum(decode(ename, ‘WARD’, sal, 0)) WARD,sum(decode(ename, ‘JONES’, sal, 0)) JONES,
sum(decode(ename, ‘MARTIN’, sal, 0)) MARTIN,sum(decode(ename, ‘BLAKE’, sal, 0)) BLAKE,
sum(decode(ename, ‘CLARK’, sal, 0)) CLARK,sum(decode(ename, ‘SCOTT’, sal, 0)) SCOTT,
sum(decode(ename, ‘KING’, sal, 0)) KING,sum(decode(ename, ‘TURNER’, sal, 0)) TURNER
from scott.emp; tips:count函数在工作中使用的很频繁,你不清楚某张表中有多少条记录,需要统计一下再处理。返回最大值max查看员工中薪水最高的那一位:-- max函数的使用
tips:count函数在工作中使用的很频繁,你不清楚某张表中有多少条记录,需要统计一下再处理。返回最大值max查看员工中薪水最高的那一位:-- max函数的使用
select max(t.sal) from scott.emp t; 返回最小值min查看员工中薪水最低的那一位:select min(t.sal) from scott.emp t;
返回最小值min查看员工中薪水最低的那一位:select min(t.sal) from scott.emp t; Oracle中的rownum伪列统计公司员工中的最后一条记录,通过rownum实现:select t.sal from scott.emp t where rownum <=1;
Oracle中的rownum伪列统计公司员工中的最后一条记录,通过rownum实现:select t.sal from scott.emp t where rownum <=1;
select t.sal from scott.emp t where rownum <=1 order by t.sal desc; MySQL中的分页limit关键字通过limit关键字实现,根据sakila数据库中的actor(演员表)为例子返回最后三条记录,使用actor_id进行排序。注意:limit属于MySQL扩展SQL92后的语法,在其它数据库中不能通用。Oracle的分页可以通过rownum来实现,上面也介绍了。SELECT t.
MySQL中的分页limit关键字通过limit关键字实现,根据sakila数据库中的actor(演员表)为例子返回最后三条记录,使用actor_id进行排序。注意:limit属于MySQL扩展SQL92后的语法,在其它数据库中不能通用。Oracle的分页可以通过rownum来实现,上面也介绍了。SELECT t.first_name,t.actor_id FROM sakila.actor t ORDER BY t.actor_id DESC LIMIT 0,3; 2、着重掌握的函数group by函数用于分组;having函数用于过滤,对分组后内容进行过滤。group by函数配合聚合函数sum使用,查询Oracle中scott用户下的emp表。使用group by进行分组,然后统计公司各部门员工的薪资:SELECT t.deptno, SUM(t.sal) AS sals FROM scott.emp t GROUP BY t.deptno;
2、着重掌握的函数group by函数用于分组;having函数用于过滤,对分组后内容进行过滤。group by函数配合聚合函数sum使用,查询Oracle中scott用户下的emp表。使用group by进行分组,然后统计公司各部门员工的薪资:SELECT t.deptno, SUM(t.sal) AS sals FROM scott.emp t GROUP BY t.deptno; having函数区别:having和where的区别在于,having是对聚合后的结果进行条件的过滤,而where是在聚合前就对记录进行过滤。如果逻辑允许,应尽可能用where先过滤记录,由于结果集的减小,对聚合的效率明显提升。最后再依据逻辑判断是否用having再次过滤。配合聚合函数使用,Oracle中的scott用户下emp与dept表。先对部门名称进行分组,然后使用having过滤出薪水总和大于10000的部门:SELECT d.dname, SUM(e.sal) AS sals FROM scott.emp e
having函数区别:having和where的区别在于,having是对聚合后的结果进行条件的过滤,而where是在聚合前就对记录进行过滤。如果逻辑允许,应尽可能用where先过滤记录,由于结果集的减小,对聚合的效率明显提升。最后再依据逻辑判断是否用having再次过滤。配合聚合函数使用,Oracle中的scott用户下emp与dept表。先对部门名称进行分组,然后使用having过滤出薪水总和大于10000的部门:SELECT d.dname, SUM(e.sal) AS sals FROM scott.emp e
INNER JOIN scott.dept d ON e.deptno=d.deptno
WHERE e.deptno < 30 GROUP BY d.dname HAVING SUM(e.sal) > 10000; 五、SQL核心知识凡事应以实际工作场景而定。个人的以一些理解仅仅是建议,最终的应用还需结合实际应用场景。软件实施对SQL的函数、触发器和存储过程没有太高的要求,但也需要会基本的运用。在某些特殊的场景下,使用这些SQL的核心知识将有助于提高我们的工作效率。1、函数函数关键字:FUNCTION使用第三方客户端工具新建函数,会自动生成一些模板:DELIMITER −−声明关键字DELIMITERCREATE−−创建函数的关键字create/∗[DEFINER=user∣CURRENTUSER]∗/FUNCTION‘study‘.‘stunum‘()−−设置函数名称RETURNSTYPE−−返回值的类型/∗LANGUAGESQL∣[NOT]DETERMINISTIC∣CONTAINSSQL∣NOSQL∣READSSQLDATA∣MODIFIESSQLDATA∣SQLSECURITYDEFINER∣INVOKER∣COMMENT′string′∗/BEGIN−−开始业务逻辑−−业务逻辑区...END-- 声明关键字DELIMITER CREATE -- 创建函数的关键字create /*[DEFINER = { user | CURRENT_USER }]*/ FUNCTION `study`.`stu_num`() -- 设置函数名称 RETURNS TYPE -- 返回值的类型 /*LANGUAGE SQL | [NOT] DETERMINISTIC | { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA } | SQL SECURITY { DEFINER | INVOKER } | COMMENT 'string'*/ BEGIN -- 开始业务逻辑 -- {业务逻辑区...} END−−声明关键字DELIMITERCREATE−−创建函数的关键字create/∗[DEFINER=user∣CURRENTUSER]∗/FUNCTION‘study‘.‘stunum‘()−−设置函数名称RETURNSTYPE−−返回值的类型/∗LANGUAGESQL∣[NOT]DETERMINISTIC∣CONTAINSSQL∣NOSQL∣READSSQLDATA∣MODIFIESSQLDATA∣SQLSECURITYDEFINER∣INVOKER∣COMMENT′string′∗/BEGIN−−开始业务逻辑−−业务逻辑区...END – 结束标志
五、SQL核心知识凡事应以实际工作场景而定。个人的以一些理解仅仅是建议,最终的应用还需结合实际应用场景。软件实施对SQL的函数、触发器和存储过程没有太高的要求,但也需要会基本的运用。在某些特殊的场景下,使用这些SQL的核心知识将有助于提高我们的工作效率。1、函数函数关键字:FUNCTION使用第三方客户端工具新建函数,会自动生成一些模板:DELIMITER −−声明关键字DELIMITERCREATE−−创建函数的关键字create/∗[DEFINER=user∣CURRENTUSER]∗/FUNCTION‘study‘.‘stunum‘()−−设置函数名称RETURNSTYPE−−返回值的类型/∗LANGUAGESQL∣[NOT]DETERMINISTIC∣CONTAINSSQL∣NOSQL∣READSSQLDATA∣MODIFIESSQLDATA∣SQLSECURITYDEFINER∣INVOKER∣COMMENT′string′∗/BEGIN−−开始业务逻辑−−业务逻辑区...END-- 声明关键字DELIMITER CREATE -- 创建函数的关键字create /*[DEFINER = { user | CURRENT_USER }]*/ FUNCTION `study`.`stu_num`() -- 设置函数名称 RETURNS TYPE -- 返回值的类型 /*LANGUAGE SQL | [NOT] DETERMINISTIC | { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA } | SQL SECURITY { DEFINER | INVOKER } | COMMENT 'string'*/ BEGIN -- 开始业务逻辑 -- {业务逻辑区...} END−−声明关键字DELIMITERCREATE−−创建函数的关键字create/∗[DEFINER=user∣CURRENTUSER]∗/FUNCTION‘study‘.‘stunum‘()−−设置函数名称RETURNSTYPE−−返回值的类型/∗LANGUAGESQL∣[NOT]DETERMINISTIC∣CONTAINSSQL∣NOSQL∣READSSQLDATA∣MODIFIESSQLDATA∣SQLSECURITYDEFINER∣INVOKER∣COMMENT′string′∗/BEGIN−−开始业务逻辑−−业务逻辑区...END – 结束标志
DELIMITER ;2、触发器触发器关键字:TRIGGER使用第三方客户端工具新建触发器,会自动生成一些模板:DELIMITER CREATE−−创建触发器的关键字create/∗[DEFINER=user∣CURRENTUSER]∗/TRIGGER‘study‘.‘stuinsert‘BEFORE/AFTERINSERT/UPDATE/DELETEON‘study‘.‘` FOR EACH ROW BEGIN -- 使用到for each循环 -- {业务逻辑区...} ENDCREATE−−创建触发器的关键字create/∗[DEFINER=user∣CURRENTUSER]∗/TRIGGER‘study‘.‘stuinsert‘BEFORE/AFTERINSERT/UPDATE/DELETEON‘study‘.‘
DELIMITER ;3、存储过程存储过程关键字:PROCEDURE支持完整事务的存储引擎,在保证数据的完整一致性情况下,尽可能多的使用commit事务提交。利用函数和存储过程一个好的示例,在MySQL中快速生成千万级别的数据大表进行测试就可以应用到,同时还能联想到测试性能。这是勾起我们学习的动力,一个比较好的方法。使用第三方客户端工具新建存储过程,会自动生成一些模板:DELIMITER CREATE/∗[DEFINER=user∣CURRENTUSER]∗/PROCEDURE‘study‘.‘insertstudy‘()/∗LANGUAGESQL∣[NOT]DETERMINISTIC∣CONTAINSSQL∣NOSQL∣READSSQLDATA∣MODIFIESSQLDATA∣SQLSECURITYDEFINER∣INVOKER∣COMMENT′string′∗/BEGIN−−业务逻辑区...COMMIT;−−支持完整事务的存储引擎,在保证数据的完整一致性情况下,尽可能多的使用commit事务提交ENDCREATE /*[DEFINER = { user | CURRENT_USER }]*/ PROCEDURE `study`.`insert_study`() /*LANGUAGE SQL | [NOT] DETERMINISTIC | { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA } | SQL SECURITY { DEFINER | INVOKER } | COMMENT 'string'*/ BEGIN -- {业务逻辑区...} COMMIT; -- 支持完整事务的存储引擎,在保证数据的完整一致性情况下,尽可能多的使用commit事务提交 ENDCREATE/∗[DEFINER=user∣CURRENTUSER]∗/PROCEDURE‘study‘.‘insertstudy‘()/∗LANGUAGESQL∣[NOT]DETERMINISTIC∣CONTAINSSQL∣NOSQL∣READSSQLDATA∣MODIFIESSQLDATA∣SQLSECURITYDEFINER∣INVOKER∣COMMENT′string′∗/BEGIN−−业务逻辑区...COMMIT;−−支持完整事务的存储引擎,在保证数据的完整一致性情况下,尽可能多的使用commit事务提交END
DELIMITER ;4、典型的示例sakila数据库这是一个MySQL官方提供的拥有存储过程、触发器和函数示例的电影出租信息管理系统数据库。并且官方提供了EER模型,便于理解每张表之间的关联关系,可以使用MySQL workbench打开sakila.mwb进行参考学习。如果你能完整的看完这篇文档,你会发现在一开始我就提供了sakila数据库的官网下载地址。sakila数据库视图:actor_info,演员信息视图使用DESC关键字进行查看视图结构,这个关键字很实用哟。视图和表结构很像,以sakila中actor_info视图进行展示: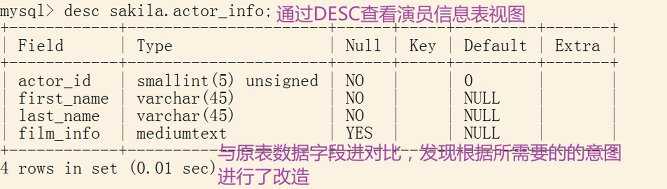 sakila数据库存储过程:film_in_stock,电影库存官方的一个示例:创建一个存储过程,声明了三个常量字段,然后分别赋值给演示字段,最后将找到的记录复制存到了p_film_count中。这里我为何说是复制呢?是因为使用到了SELECT … INTO关键字。函数、触发器和存储过程最主要的一块在BEGIN {业务逻辑区…} END这一块区域。DELIMITER USE‘sakila‘USE `sakila`USE‘sakila‘
sakila数据库存储过程:film_in_stock,电影库存官方的一个示例:创建一个存储过程,声明了三个常量字段,然后分别赋值给演示字段,最后将找到的记录复制存到了p_film_count中。这里我为何说是复制呢?是因为使用到了SELECT … INTO关键字。函数、触发器和存储过程最主要的一块在BEGIN {业务逻辑区…} END这一块区域。DELIMITER USE‘sakila‘USE `sakila`USE‘sakila‘
DROP PROCEDURE IF EXISTS film_in_stockCREATEDEFINER=‘root‘@‘READSSQLDATASQLSECURITYINVOKERBEGINSELECTinventoryidFROMinventoryWHEREfilmid=pfilmidANDstoreid=pstoreidANDinventoryinstock(inventoryid);SELECTFOUNDROWS()INTOpfilmcount;ENDCREATE DEFINER=`root`@`%` PROCEDURE `film_in_stock`(IN p_film_id INT, IN p_store_id INT, OUT p_film_count INT) READS SQL DATA SQL SECURITY INVOKER BEGIN SELECT inventory_id FROM inventory WHERE film_id = p_film_id AND store_id = p_store_id AND inventory_in_stock(inventory_id); SELECT FOUND_ROWS() INTO p_film_count; ENDCREATEDEFINER=‘root‘@‘READSSQLDATASQLSECURITYINVOKERBEGINSELECTinventoryidFROMinventoryWHEREfilmid=pfilmidANDstoreid=pstoreidANDinventoryinstock(inventoryid);SELECTFOUNDROWS()INTOpfilmcount;END
DELIMITER ;关于函数我就不列举MySQL官方提供的示例了。给出一点小小的建议,感觉对你没啥作用可以忽略掉:首先快速熟悉语法使用,对官方的示例进行解读,然后运行验证。最后,书写一些简单的示例达到熟练运用目的。不要只停留在想要执行,而是立即执行并带着思考去看待问题。多问一个为什么,思考本质。
相关内容