
transfromer-XL论文详解
Transformer-XL来自于论文《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》,Transformer-XL是对Transformer的改进或变种,主要是解决长序列的问题,其中XL表示extra long,在XLNet中就是使用Transformer-XL作为基础模块。
1.经典Transformer
在正式讨论Transformer-XL之前,我们先来看看经典的Transformer(Vanilla Transformer)是如何处理数据和训练评估模型的,如下图所示。
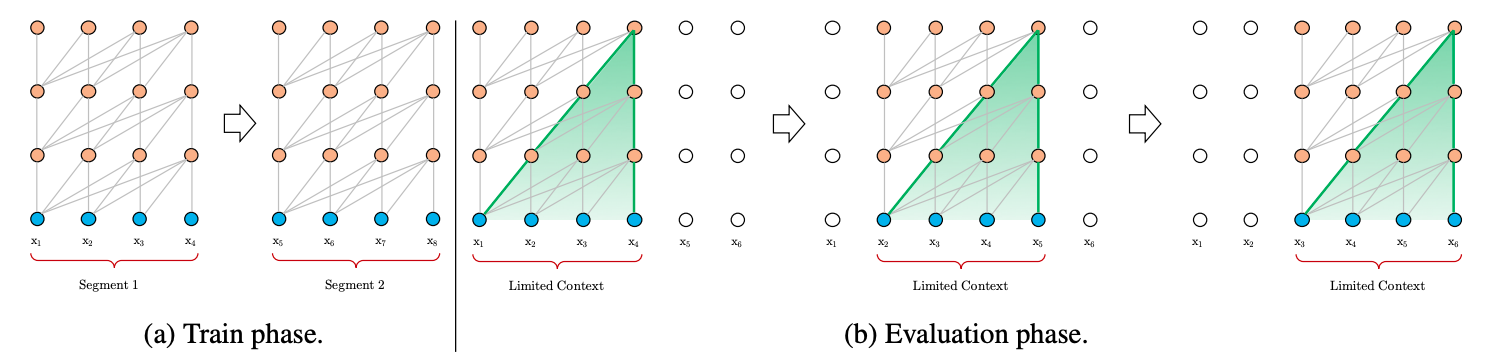
1-1 数据处理
在数据处理方面,给定一串较长的文本串,Vanilla Transformer会按照固定的长度(比如512),直接将该文本串进行划分成若干Segment。
这个处理方式不会关注文本串中语句本身的边界(比如标点或段落),这样"粗暴"的划分通常会将一句完整的话切分到两个Segment里面,导致上下文碎片化(context fragmentation)。
另外,Transformer本身能够维持的依赖长度很有可能会超出这个固定的划分长度,从而导致Transformer能够捕获的最大依赖长度不超过这个划分长度,Transformer本身达不到更好的性能。
1-2 模型训练
在模型训练方面,如图1a所示,Vanilla Transformer每次传给模型一个Segment进行训练,第1个Segment训练完成后,传入第2个Segment进行训练,然而前后的这两个Segment是没有任何联系的,也就是前后的训练是独立的。但事实是前后的Segment其实是有关联的。
1-3 模型评估
在模型评估方面,如图1b所示,Vanilla Transformer会采用同训练阶段一致的划分长度,但仅仅预测最后一个位置的token,完成之后,整个序列向后移动一个位置,预测下一个token。这个处理方式保证了模型每次预测都能使用足够长的上下文信息,也缓解了训练过程中的context framentation问题。但是每次的Segment都会重新计算,计算代价很大。
2.Transformer-XL
基于传统Transformer的不足,Transformer-XL被提出来解决这些问题。它主要提出了两个技术:Segment-Level 循环机制和相对位置编码。
- Transformer-XL能够建模更长的序列依赖,比RNN长80%,比Vanilla Transformer长450%。
- 同时具有更快的评估速度,比Vanilla Transformer快1800+倍。
- 同时在多项任务上也达到了SoTA的效果。
2-1 Segment-Level 循环机制
为了解决上面提到的问题,在Trm的基础上,Trm-XL提出了一个改进,在对当前segment进行处理的时候,缓存并利用上一个segment中所有layer的隐向量序列,而且上一个segment的所有隐向量序列只参与前向计算,不再进行反向传播,这就是所谓的segment-level Recurrence。
Transformer-XL通过引入Segment-Level recurrence mechanism来建模更长序列,这里循环机制和RNN循环机制类似,在RNN中,每个时刻的RNN单元会接收上个时刻的输出和当前时刻的输入,然后将两者融合计算得出当前时刻的输出。Transformer-XL同样是接收上个时刻的输出和当前时刻的输入,然后将两者融合计算得出当前时刻的输出。但是两者的处理单位并不相同,RNN的处理单位是一个词,Transformer-XL的处理单位是一个Segment。图2展示了Transformer-XL在训练阶段和评估阶段的Segment处理方式。
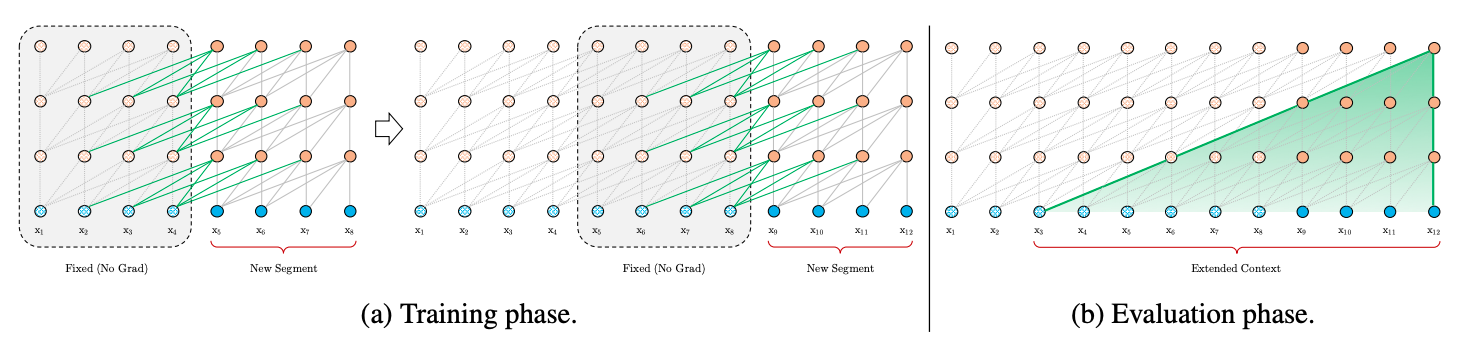 2-1-2 模型训练
2-1-2 模型训练
在模型训练阶段,如图2a所示,Transformer-XL会缓存前一个Segment的输出序列,在计算下一个Segment的输出时会使用上一个Segment的缓存信息,将前后不同Segment的信息进行融合,能够帮助模型看见更远的地方,建模更长的序列依赖能力,同时也避免了context fragmentation问题。举个例子,假设Transformer的encoder一共有4层,每个segment为500个token。根据循环机制的原理,第4层的第𝜏τ个segment输入不仅考虑了第三层encoder的第 𝜏τ个segment的输出,也考虑了第三层encoder的第𝜏−1τ−1个segment的输出;而第三层第𝜏−1τ−1个encdoer的输入,不仅考虑了第二层encoder的第𝜏−1τ−1个segment的输出,也考虑了第𝜏−2τ−2个segment的输出。也即,上下文的能接受到的长度是线性O(N*L)增加的,如这里所说的例子,虽然,一个segment是500个token,但其实在最后输出时,足足考虑了4 * 500 = 2000个token的信息!上下文碎片的问题也就自然得到了大大的缓解。
2-2-2 模型评估
在模型评估时,由于采用了循环机制,不必每次只向右移动一步了,而是可以采用同训练时候差不多的片段机制,从而大大提高了评估效率。
2-2-3
这张图上有一个点需要注意,在当前segment中,第n层的每个隐向量的计算,都是利用前一层中包括当前位置在内的,连续前L个长度的隐向量,这是在上面的公式组中没有体现出来的,也是文中没有明说的。每一个位置的隐向量,除了自己的位置,都跟前一层中前(L-1)个位置的token存在依赖关系,而且每往下走一层,依赖关系长度会增加(L-1),如图中Evaluation phase所示,所以最长的依赖关系长度是N(L-1),N是模型中layer的数量。N通常要比L小很多,比如在BERT中,N=12或者24,L=512,依赖关系长度可以近似为O(N*L)。在对长文本进行计算的时候,可以缓存上一个segment的隐向量的结果,不必重复计算,大幅提高计算效率。
上文中,我们只保存了上一个segment,实际操作的时候,可以保存尽可能多的segments,只要内存或者显存放得下。论文中的试验在训练的时候,只缓存一个segment,在预测的时候,会缓存多个segments。
2-2-4 具体实现
假设前后的两个Segment分别为:s𝜏=[𝑥𝜏,1,𝑥𝜏,2,...,𝑥𝜏,𝐿]和s𝜏+1=[𝑥𝜏+1,1,𝑥𝜏+1,2,...,𝑥𝜏+1,𝐿],其中序列长度为𝐿。另外假定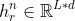 为由s𝜏计算得出的第𝑛层的状态向量,则下一个Segment s𝜏+1的第𝑛层可按照如下方式计算:
为由s𝜏计算得出的第𝑛层的状态向量,则下一个Segment s𝜏+1的第𝑛层可按照如下方式计算:
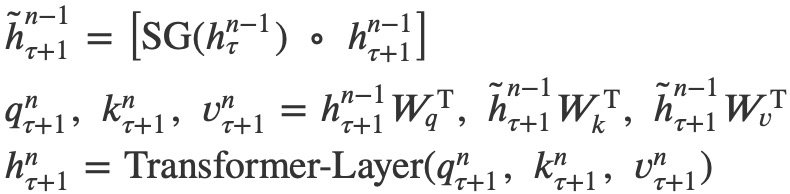
1.SG是stop-gradient的意思,![]() 表示不使用梯度,
表示不使用梯度,![]() 表示将前后两个Segment的输出向量在序列维度上进行拼接。括号内两个隐向量的维度都是𝐿∗𝑑,拼接之后的向量维度是2𝐿∗𝑑。
表示将前后两个Segment的输出向量在序列维度上进行拼接。括号内两个隐向量的维度都是𝐿∗𝑑,拼接之后的向量维度是2𝐿∗𝑑。
2.中间的公式表示获取Self-Attention计算中相应的q,k,v矩阵,3个W分别对应query,key和value的转化矩阵。其中在计算q的时候仅仅使用了当前Segment的向量,计算得到的q序列长度仍然是L。在计算𝑘k和𝑣v的时候同时使用前一个Segment和当前Segment的信息。计算出来的序列长度是2L。
3.之后的计算就是标准的Transformer计算,通过Self-Attention融合计算,得出当前Segment的输出向量序列。计算出来的第n层隐向量序列长度仍然是L,而不是2L。Trm的输出隐向量序列长度取决于query的序列长度,而不是key和value。
2-2 相对位置编码
在vanilla Trm中,为了表示序列中token的顺序关系,在模型的输入端,对每个token的输入embedding,加一个位置embedding。位置编码embedding或者采用正弦\余弦函数来生成,或者通过学习得到。
在Trm-XL中,这种方法行不通,每个segment都添加相同的位置编码,多个segments之间无法区分位置关系。举个例子,我们在计算第τ个segment的输出时,不仅考虑了上一层第τ个segment的输出作为输入,还考虑了第τ−1 个segment的输出作为输入,假设我们采用绝对位置编码,那第τ个片段和第τ−1个片段的第1个token的位置编码是一样的,但这是明显不合理的。因此,作者提出了一种相对位置编码的思想,在计算当前位置隐向量的时候,考虑与之依赖token的相对位置关系。具体操作是,在计算attention score的时候,只考虑query向量与key向量的相对位置关系,并且将这种相对位置关系,加入到每一层Trm的attention的计算中。
假设序列之中的最大相对距离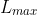 ,则我们可以定义这样的一个相对位置矩阵
,则我们可以定义这样的一个相对位置矩阵![]() ,其中𝑅𝑏Rb表示两个token之间距离是b的相对位置编码向量。注意在Transformer-XL中,相对位置编码向量不是可训练的参数,好处是预测时,可以使用比训练距离更长的位置向量。以𝑅𝑏=[𝑟𝑏,1,𝑟𝑏,2,...,𝑟𝑏,𝑑]为例,每个元素通过如下形式生成:
,其中𝑅𝑏Rb表示两个token之间距离是b的相对位置编码向量。注意在Transformer-XL中,相对位置编码向量不是可训练的参数,好处是预测时,可以使用比训练距离更长的位置向量。以𝑅𝑏=[𝑟𝑏,1,𝑟𝑏,2,...,𝑟𝑏,𝑑]为例,每个元素通过如下形式生成:
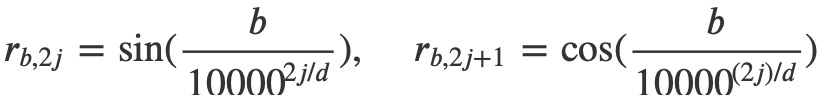
具体地,原生的Vanilla Transformer使用绝对位置编码在计算attention时,如下式所示:
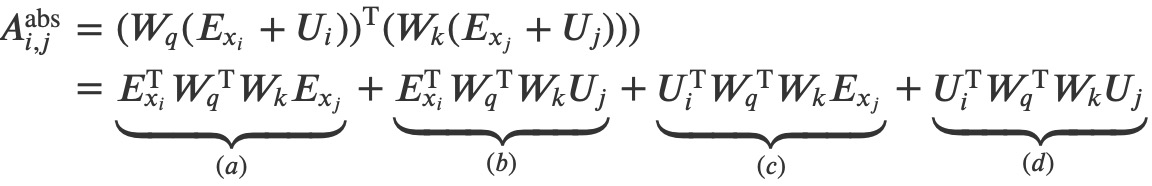
其中𝐸𝑥𝑖表示token 𝑥𝑖xi的词向量,𝑈𝑖表示其绝对位置编码。根据这个展开公式,Transformer-XL将相对位置编码信息融入其中,如下:
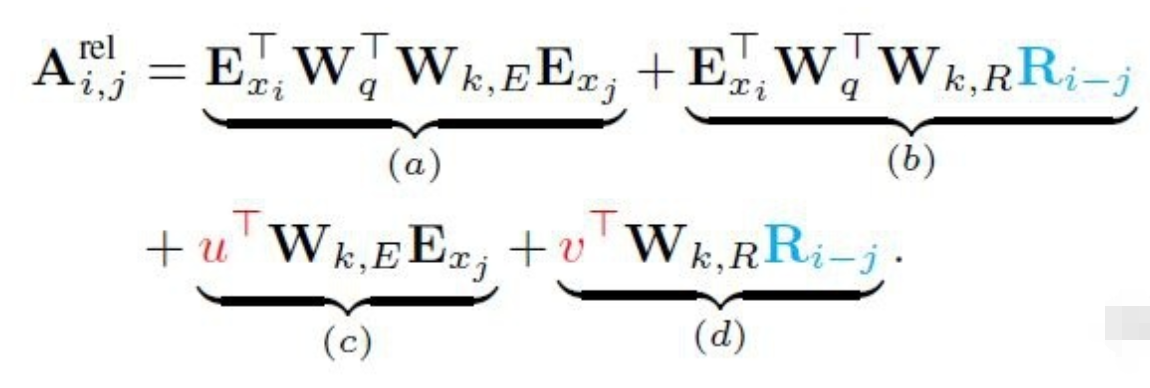
这里做了这样几处改变以融入相对位置编码:
1.在分项(b)和(d)中,使用相对位置编码𝑅𝑖−𝑗取代绝对位置编码𝑈𝑗。插一句,因为i只利用之前的序列,所以𝑖−𝑗>=0,我们所说的相对是j位置处的key/value相对于i位置处的query而言的。
2.在分项(c)和(d)中,使用可训练参数u和v取代![]() 。因为
。因为![]() 表示第𝑖个位置的query 向量,这个query向量对于其他要进行Attention的位置来说都是一样的,因此可以直接使用统一的可训练参数进行替换。
表示第𝑖个位置的query 向量,这个query向量对于其他要进行Attention的位置来说都是一样的,因此可以直接使用统一的可训练参数进行替换。
3.在所有分项中,使用![]() 计算基于内容(词向量)的key向量和基于位置的key向量。
计算基于内容(词向量)的key向量和基于位置的key向量。
式子中的每个分项分别代表的含义如下:
- (a)描述了基于内容的Attention,即没有添加原始位置编码的原始分数;
- (b)描述了内容对于每个相对位置的bias,即相对于当前内容的位置偏置;
- (c)描述了全局的内容偏置,用于衡量key的重要性;
- (d)描述了全局的位置偏置,根据query和key之间的距离调整重要性。
3.完整的Self-Attention计算过程
上边描述了Transformer-XL中的两个核心技术:Segment-Level 循环机制和相对位置编码,引入了这两项技术之后,Transformer-XL中从第n−1层到第n层完整的计算过程是这样的:
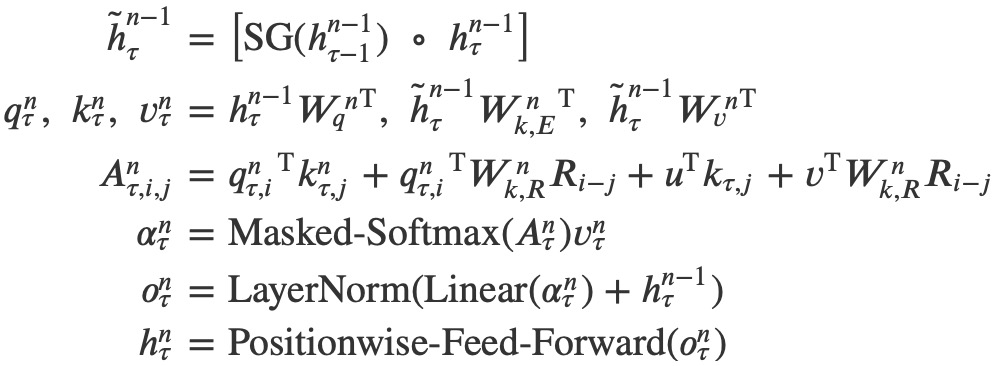
只有前3行与vanilla Trm不同,后3行是一样的。第3行公式中,计算A的时候直接采用query向量,而不再使用𝐸𝑥𝑊𝑞表示。最后需要注意的是,每一层在计算attention的时候,都要包含相对位置编码。而在vanilla Trm中,只有在输入embedding中才包含绝对位置编码,在中间层计算的时候,是不包含位置编码的。
Trm-XL为了解决长序列的问题,对上一个segment做了缓存,可供当前segment使用。
但是也带来了位置关系问题,为了解决位置问题,又打了个补丁,引入了相对位置编码。
4.总结
4-1 问题1
Transformer-XL这篇论文为什么没有被ICLR接受?不足在哪里?
主要原因是Transformer-XL并没有与当前一些基于Transformer的预训练模型,如BERT等进行对比,并没有在具体的下游任务,如分类、QA等应用进行实验。论文里只是简单提了Transformer-XL在文本生成(由于Transformer-XL是语言模型,所以应用于文本生成很自然)、无监督特征学习等都有前景,并没有给出在某些GLUE的表现,因此论文略显单薄。
4-2 问题2
为什么Transformer-XL能有效解决BERT的长度限制问题?
因为BERT在预训练的时候,就把输入长度限制在512,BERT会把1~512位置映射到一个768维的position embedding(BERT并没有用原生Transformer的三角函数位置编码),因此没有512以上的position embedding。我们当然也可以重头训练一个最大长度为1000的BERT,但会很耗资源。
Transformer-XL输入是没有position embedding的,相对位置信息是加在每层encoder的attention计算中。通过循环机制和相对位置编码,Transformer-XL理论上能接受无限长的输入。
4-3 问题3
Transformer-XL怎么应用到具体下游任务?
文本分类可以用最后一个token的输出再接一些全连接层来做分类,序列标注任务也可以用每个token的输出再接一些网络。
但由于Transformer-XL预训练是只利用了单向信息,BERT是利用了双向的上下文编码,所以可以期待对于短文本,Transformer-XL是打不过BERT的,长文本的话还有一点可能,毕竟BERT对于长文本要进行剪裁才能输入,会丢掉信息。
Reference:
https://www.cnblogs.com/zjuhaohaoxuexi/p/16387163.html