
自定义线程池以及异步模式之工作线程
自定义线程池
对于线程池ExecutorService的实现,学过JUC的都不会陌生,那么怎样去定义一个线程池呢?或者说怎样去实现一个线程池呢?这个问题相信很多人都没有想过。
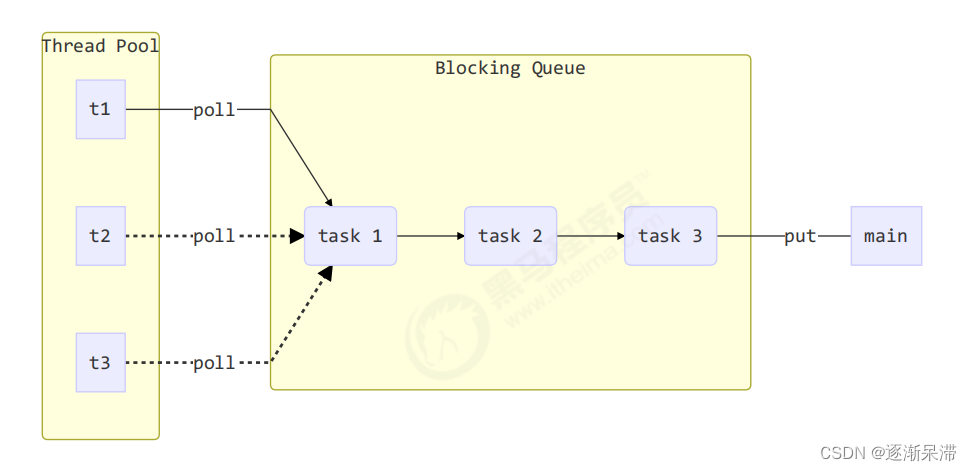
简单来说,线程池就是一个线程集合去处理一个工作阻塞队列中的任务,处理一个出队一个,下面就简单实现一个线程池。
第一步:自定义拒绝策略接口
@FunctionalInterface // 拒绝策略
interface RejectPolicy {void reject(BlockingQueue queue, T task);
}
第二步:自定义任务队列
class BlockingQueue {// 1. 任务队列private Deque queue = new ArrayDeque<>();// 2. 锁private ReentrantLock lock = new ReentrantLock();// 3. 生产者条件变量private Condition fullWaitSet = lock.newCondition();// 4. 消费者条件变量private Condition emptyWaitSet = lock.newCondition();// 5. 容量private int capcity;public BlockingQueue(int capcity) {this.capcity = capcity;}// 带超时阻塞获取public T poll(long timeout, TimeUnit unit) {lock.lock();try {// 将 timeout 统一转换为 纳秒long nanos = unit.toNanos(timeout);while (queue.isEmpty()) {try {// 返回值是剩余时间if (nanos <= 0) {return null;}nanos = emptyWaitSet.awaitNanos(nanos);} catch (InterruptedException e) {e.printStackTrace();}}T t = queue.removeFirst();fullWaitSet.signal();return t;} finally {lock.unlock();}}// 阻塞获取public T take() {lock.lock();try {while (queue.isEmpty()) {try {emptyWaitSet.await();} catch (InterruptedException e) {e.printStackTrace();}}T t = queue.removeFirst();fullWaitSet.signal();return t;} finally {lock.unlock();}}// 阻塞添加public void put(T task) {lock.lock();try {while (queue.size() == capcity) {try {log.debug("等待加入任务队列 {} ...", task);fullWaitSet.await();} catch (InterruptedException e) {e.printStackTrace();}}log.debug("加入任务队列 {}", task);queue.addLast(task);emptyWaitSet.signal();} finally {lock.unlock();}}// 带超时时间阻塞添加public boolean offer(T task, long timeout, TimeUnit timeUnit) {lock.lock();try {long nanos = timeUnit.toNanos(timeout);while (queue.size() == capcity) {try {if (nanos <= 0) {return false;}log.debug("等待加入任务队列 {} ...", task);nanos = fullWaitSet.awaitNanos(nanos);} catch (InterruptedException e) {e.printStackTrace();}}log.debug("加入任务队列 {}", task);queue.addLast(task);emptyWaitSet.signal();return true;} finally {lock.unlock();}}public int size() {lock.lock();try {return queue.size();} finally {lock.unlock();}}public void tryPut(RejectPolicy rejectPolicy, T task) {lock.lock();try {// 判断队列是否满if (queue.size() == capcity) {rejectPolicy.reject(this, task);} else { // 有空闲log.debug("加入任务队列 {}", task);queue.addLast(task);emptyWaitSet.signal();}} finally {lock.unlock();}}}
第三步:自定义线程池
class ThreadPool {// 任务队列private BlockingQueue taskQueue;// 线程集合private HashSet workers = new HashSet<>();// 核心线程数private int coreSize;// 获取任务时的超时时间private long timeout;private TimeUnit timeUnit;private RejectPolicy rejectPolicy;// 执行任务public void execute(Runnable task) {// 当任务数没有超过 coreSize 时,直接交给 worker 对象执行// 如果任务数超过 coreSize 时,加入任务队列暂存synchronized (workers) {if (workers.size() < coreSize) {Worker worker = new Worker(task);log.debug("新增 worker{}, {}", worker, task);workers.add(worker);worker.start();} else {
// taskQueue.put(task);// 1) 死等// 2) 带超时等待// 3) 让调用者放弃任务执行// 4) 让调用者抛出异常// 5) 让调用者自己执行任务taskQueue.tryPut(rejectPolicy, task);}}}public ThreadPool(int coreSize, long timeout, TimeUnit timeUnit, int queueCapcity,RejectPolicy rejectPolicy) {this.coreSize = coreSize;this.timeout = timeout;this.timeUnit = timeUnit;this.taskQueue = new BlockingQueue<>(queueCapcity);this.rejectPolicy = rejectPolicy;}class Worker extends Thread {private Runnable task;public Worker(Runnable task) {this.task = task;}@Overridepublic void run() {// 执行任务// 1) 当 task 不为空,执行任务// 2) 当 task 执行完毕,再接着从任务队列获取任务并执行// while(task != null || (task = taskQueue.take()) != null) {while (task != null || (task = taskQueue.poll(timeout, timeUnit)) != null) {try {log.debug("正在执行...{}", task);task.run();} catch (Exception e) {e.printStackTrace();} finally {task = null;}}synchronized (workers) {log.debug("worker 被移除{}", this);workers.remove(this);}}}
}
第四步:测试
public static void main(String[] args) {ThreadPool threadPool = new ThreadPool(1,1000, TimeUnit.MILLISECONDS, 1, (queue, task) -> {// 1. 死等// queue.put(task);// 2) 带超时等待// queue.offer(task, 1500, TimeUnit.MILLISECONDS);// 3) 让调用者放弃任务执行// log.debug("放弃{}", task);// 4) 让调用者抛出异常// throw new RuntimeException("任务执行失败 " + task);// 5) 让调用者自己执行任务task.run();});for (int i = 0; i < 4; i++) {int j = i;threadPool.execute(() -> {try {Thread.sleep(1000L);} catch (InterruptedException e) {e.printStackTrace();}log.debug("{}", j);});}}
以上就是实现一个简单线程池的操作。
异步模式之工作线程
1. 定义
让有限的工作线程(Worker Thread)来轮流异步处理无限多的任务。也可以将其归类为分工模式,它的典型实现就是线程池,也体现了经典设计模式中的享元模式。
例如,海底捞的服务员(线程),轮流处理每位客人的点餐(任务),如果为每位客人都配一名专属的服务员,那么成本就太高了(对比另一种多线程设计模式:Thread-Per-Message)。
注意,不同任务类型应该使用不同的线程池,这样能够避免饥饿,并能提升效率。
例如,如果一个餐馆的工人既要招呼客人(任务类型A),又要到后厨做菜(任务类型B)显然效率不咋地,分成服务员(线程池A)与厨师(线程池B)更为合理,当然你能想到更细致的分工。
2. 饥饿
固定大小线程池会有饥饿现象
- 两个工人是同一个线程池中的两个线程。
- 他们要做的事情是:为客人点餐和到后厨做菜,这是两个阶段的工作。
- 客人点餐:必须先点完餐,等菜做好,上菜,在此期间处理点餐的工人必须等待。
- 后厨做菜:没啥说的,做就是了。
- 比如工人A 处理了点餐任务,接下来它要等着 工人B 把菜做好,然后上菜,他俩也配合的蛮好。
- 但现在同时来了两个客人,这个时候工人A 和工人B 都去处理点餐了,这时没人做饭了,出现饥饿。
public class TestDeadLock {static final List MENU = Arrays.asList("地三鲜", "宫保鸡丁", "辣子鸡丁", "烤鸡翅");static Random RANDOM = new Random();static String cooking() {return MENU.get(RANDOM.nextInt(MENU.size()));}public static void main(String[] args) {ExecutorService executorService = Executors.newFixedThreadPool(2);executorService.execute(() -> {log.debug("处理点餐...");Future f = executorService.submit(() -> {log.debug("做菜");return cooking();});try {log.debug("上菜: {}", f.get());} catch (InterruptedException | ExecutionException e) {e.printStackTrace();}});/*executorService.execute(() -> {log.debug("处理点餐...");Future f = executorService.submit(() -> {log.debug("做菜");return cooking();});try {log.debug("上菜: {}", f.get());} catch (InterruptedException | ExecutionException e) {e.printStackTrace();}});*/}}
输出:
17:21:27.883 c.TestDeadLock [pool-1-thread-1] - 处理点餐...
17:21:27.891 c.TestDeadLock [pool-1-thread-2] - 做菜
17:21:27.891 c.TestDeadLock [pool-1-thread-1] - 上菜: 烤鸡翅
当注释取消后,可能的输出
17:08:41.339 c.TestDeadLock [pool-1-thread-2] - 处理点餐...
17:08:41.339 c.TestDeadLock [pool-1-thread-1] - 处理点餐...
解决方法可以增加线程池的大小,不过不是根本解决方案,还是前面提到的,不同的任务类型,采用不同的线程池,例如:
public class TestDeadLock {static final List MENU = Arrays.asList("地三鲜", "宫保鸡丁", "辣子鸡丁", "烤鸡翅");static Random RANDOM = new Random();static String cooking() {return MENU.get(RANDOM.nextInt(MENU.size()));}public static void main(String[] args) {ExecutorService waiterPool = Executors.newFixedThreadPool(1);ExecutorService cookPool = Executors.newFixedThreadPool(1);waiterPool.execute(() -> {log.debug("处理点餐...");Future f = cookPool.submit(() -> {log.debug("做菜");return cooking();});try {log.debug("上菜: {}", f.get());} catch (InterruptedException | ExecutionException e) {e.printStackTrace();}});waiterPool.execute(() -> {log.debug("处理点餐...");Future f = cookPool.submit(() -> {log.debug("做菜");return cooking();});try {log.debug("上菜: {}", f.get());} catch (InterruptedException | ExecutionException e) {e.printStackTrace();}});}}
输出:
17:25:14.626 c.TestDeadLock [pool-1-thread-1] - 处理点餐...
17:25:14.630 c.TestDeadLock [pool-2-thread-1] - 做菜
17:25:14.631 c.TestDeadLock [pool-1-thread-1] - 上菜: 地三鲜
17:25:14.632 c.TestDeadLock [pool-1-thread-1] - 处理点餐...
17:25:14.632 c.TestDeadLock [pool-2-thread-1] - 做菜
17:25:14.632 c.TestDeadLock [pool-1-thread-1] - 上菜: 辣子鸡丁
3. 创建多少线程池合适
- 过小会导致程序不能充分地利用系统资源、容易导致饥饿。
- 过大会导致更多的线程上下文切换,占用更多内存。
3.1 CPU 密集型运算
通常采用 cpu 核数 + 1 能够实现最优的 CPU 利用率,+1 是保证当线程由于页缺失故障(操作系统)或其它原因,导致暂停时,额外的这个线程就能顶上去,保证 CPU 时钟周期不被浪费。
3.2 I/O 密集型运算
CPU 不总是处于繁忙状态,例如,当你执行业务计算时,这时候会使用 CPU 资源,但当你执行 I/O 操作时、远程RPC 调用时,包括进行数据库操作时,这时候 CPU 就闲下来了,你可以利用多线程提高它的利用率。
经验公式如下:
线程数 = 核数 * 期望 CPU 利用率 * 总时间(CPU计算时间+等待时间) / CPU 计算时间
例如 4 核 CPU 计算时间是 50% ,其它等待时间是 50%,期望 cpu 被 100% 利用,套用公式
4 * 100% * 100% / 50% = 8
例如 4 核 CPU 计算时间是 10% ,其它等待时间是 90%,期望 cpu 被 100% 利用,套用公式
4 * 100% * 100% / 10% = 40
下一篇:英语基本句型